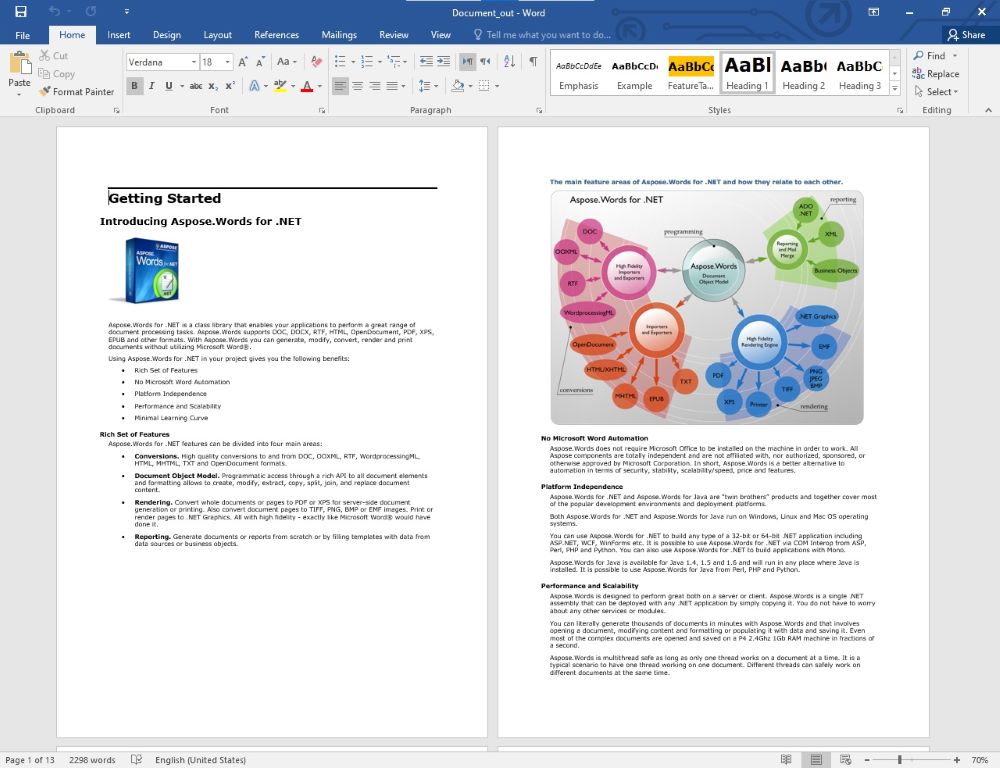
首先,MongoDB中获取某列的最大值通常是通过聚合框架中的$group和$max操作符来完成的。那在Spring Data中,应该怎么构建这个聚合查询呢?
首先,可能需要创建一个Aggregation对象,里面包含分组和求最大值的步骤。比如,使用Aggregation.group()来分组,然后指定要计算最大值的字段。不过,分组的时候可能需要一个空的分组键,因为是要全局的最大值,而不是按某个字段分组的最大值。所以,应该是Aggregation.group().max("fieldName").as("maxField")。
然后,用mongoTemplate的aggregate方法执行这个聚合操作。返回的结果应该是一个包含maxField的文档。可能需要将结果转换为一个自定义的类,或者直接使用Document类来获取值。例如,如果字段名是"price",那么结果中的字段名可能是"maxPrice",需要对应起来。
另外,还要注意如果集合中没有文档的话,结果可能会是null或者0,可能需要处理这种情况。或者,用户可能想要在某个特定条件下的最大值,这时候需要先添加一个$match阶段到聚合管道中。
还有,可能需要考虑性能问题,比如是否有索引支持该字段的最大值查询。不过,对于简单的最大值查询,MongoDB的聚合应该可以处理得比较快,特别是如果该字段有索引的话。
总结一下步骤应该是这样的:
1. 创建分组阶段,使用$group操作符,分组键为空,计算最大值。
2. 如果有其他条件,比如筛选某些文档,先添加$match阶段。
3. 使用mongoTemplate执行聚合,将各阶段组合成Aggregation对象。
4. 处理结果,提取最大值。
可能还需要考虑返回的数据类型,比如如果是数值类型,可能需要转换为Double或者Integer等。此外,确保字段名称正确,避免拼写错误。
另外,有没有其他方法可以获取最大值?比如用find查询然后排序取第一条?不过这样效率可能不高,尤其是数据量大的时候。聚合方法应该是更优的选择。
比如,用户可能尝试这样的代码:
Aggregation aggregation = Aggregation.newAggregation(
Aggregation.group().max("field").as("maxValue")
);
AggregationResults<Document> result = mongoTemplate.aggregate(aggregation, "collectionName", Document.class);
Double maxValue = result.getUniqueMappedResult().getDouble("maxValue");
不过需要注意,如果结果为空,getUniqueMappedResult()可能返回null,需要处理空指针异常。
或者,使用投影的方式?或者是否有其他更简便的方法?
另外,如果用户使用的是Spring Data MongoDB的较高版本,是否有更简洁的写法?比如通过MongoTemplate的find方法结合sort和limit,但这样可能不如聚合高效。
例如:
Query query = new Query().with(Sort.by(Sort.Direction.DESC, "field")).limit(1);
Document maxDocument = mongoTemplate.findOne(query, Document.class, "collectionName");
Double maxValue = maxDocument.getDouble("field");
这种方法可能更直观,但需要确保查询使用了正确的索引,否则在大型集合中可能较慢。
不过,根据MongoDB的文档,使用聚合的$max更高效,因为它可以直接从索引中获取最大值,而不用扫描整个集合。特别是如果该字段有一个索引,$max操作符可以利用索引来快速找到最大值。
所以,可能还是推荐使用聚合的方式。用户需要根据具体情况选择方法。
现在,具体到代码实现,可能需要示例代码来演示这两种方法。然后比较它们的优缺点,并指出可能的注意事项,比如处理空结果,字段名称匹配等。
在Spring Data MongoDB中,使用mongoTemplate获取某列的最大值可以通过聚合框架或排序查询实现。以下是两种方法的详细说明:
方法一:使用聚合框架(推荐)
通过$group和$max操作符直接计算最大值,适合大数据集且性能更优。
java
复制
import org.springframework.data.mongodb.core.MongoTemplate; import org.springframework.data.mongodb.core.aggregation.Aggregation; import org.springframework.data.mongodb.core.aggregation.AggregationResults; import org.springframework.data.mongodb.core.aggregation.GroupOperation; import org.bson.Document;public class MongoExample {private final MongoTemplate mongoTemplate;public MongoExample(MongoTemplate mongoTemplate) {this.mongoTemplate = mongoTemplate;}public Double getMaxValue(String fieldName, String collectionName) {// 构建聚合操作:按字段取最大值GroupOperation groupOp = Aggregation.group().max(fieldName).as("maxValue");Aggregation aggregation = Aggregation.newAggregation(groupOp);// 执行聚合查询AggregationResults<Document> results = mongoTemplate.aggregate(aggregation, collectionName, Document.class);// 提取结果(处理可能的空值)Document resultDoc = results.getUniqueMappedResult();return (resultDoc != null) ? resultDoc.getDouble("maxValue") : null;} }
说明:
-
Aggregation.group()不指定分组键,表示全局统计。 -
max(fieldName).as("maxValue")将目标字段的最大值命名为maxValue。 -
使用
results.getUniqueMappedResult()获取唯一结果,处理可能的空集合情况。
方法二:排序查询
通过倒序排序并限制返回第一条记录,适合简单场景或小数据集。
java
复制
import org.springframework.data.mongodb.core.query.Query; import org.springframework.data.domain.Sort; import org.bson.Document;public Double getMaxValueBySort(String fieldName, String collectionName) {// 构建查询:按字段倒序,取第一条Query query = new Query().with(Sort.by(Sort.Direction.DESC, fieldName)).limit(1);Document maxDoc = mongoTemplate.findOne(query, Document.class, collectionName);return (maxDoc != null) ? maxDoc.getDouble(fieldName) : null; }
说明:
-
使用
Sort.by(Sort.Direction.DESC, fieldName)对目标字段降序排列。 -
limit(1)确保只返回最大值所在的文档。 -
需要确保目标字段有索引以提高查询效率。
使用示例
java
复制
Double maxPrice = getMaxValue("price", "products");
System.out.println("最大价格: " + maxPrice);
注意事项
-
空集合处理:若集合为空或字段不存在,两种方法均可能返回
null,建议添加空值检查。 -
索引优化:为目标字段(如
price)添加索引可大幅提升性能,尤其是方法二。 -
数据类型:确保字段类型与返回值匹配(如
Double、Integer等),必要时进行类型转换。 -
聚合扩展性:若需附加条件(如过滤部分文档),可在聚合前添加
$match阶段:java
复制
Aggregation.newAggregation(Aggregation.match(Criteria.where("category").is("Electronics")), // 添加筛选条件groupOp );
总结
-
聚合方法更高效,直接计算最大值,适合复杂统计或大数据场景。
-
排序方法更简洁,适合简单需求,但需依赖索引优化性能。
根据实际场景选择最合适的方法。