文章目录
1链表的再次介绍
在计算机科学中,链表是一种常见的数据结构,它通过节点之间的指针连接来存储数据。链表有许多变种,其中双向循环链表因其独特的结构而备受关注。今天,我们将通过C语言实现一个双向循环链表,并探讨其核心操作。无论你是数据结构的新手,还是想巩固基础的老手,这篇文章都将为你提供实用的知识和代码示例。
链接: 单链表介绍
2为什么选择双向循环链表?
双向循环链表是一种特殊的链表,它的每个节点都有两个指针:一个指向前一个节点,另一个指向后一个节点。与单向链表不同,双向链表可以从任意一个节点向前或向后遍历。而循环链表的特点是其尾节点指向头节点,形成一个闭环。这种结构在某些场景下非常有用,比如实现高效的队列或缓存机制。
3代码实现:从初始化到销毁
1. 定义链表节点
首先,我们需要定义链表节点的结构。每个节点包含三个部分:
data:存储节点的数据。
next:指向下一个节点的指针。
prev:指向前一个节点的指针。
typedef int LTDataType;typedef struct ListNode
{struct ListNode* next;struct ListNode* prev;LTDataType data;
} LTNode;
2. 初始化链表
链表的初始化是创建一个头节点,并将其next和prev指针指向自己,形成一个空的双向循环链表。
LTNode* BuyListNode(LTDataType x)
{LTNode* New = (LTNode*)malloc(sizeof(LTNode));if (New == NULL){perror("malloc");exit(-1);}New->next = NULL;New->prev = NULL;New->data = x;return New;
}
LTNode* LTInit()
{LTNode* phead = BuyListNode(-1); // 创建头节点phead->next = phead;phead->prev = phead;return phead;
}
3. 插入和删除节点
在双向循环链表中,插入和删除节点是非常高效的操作。我们可以在任意位置插入或删除节点,只需调整相邻节点的指针即可。
插入节点
void LTInsert(LTNode* pos, LTDataType x)
{assert(pos);LTNode* prev = pos->prev;LTNode* new = BuyListNode(x);prev->next = new;new->prev = prev;new->next = pos;pos->prev = new;
}
删除节点
void LTErase(LTNode* pos)
{assert(pos);LTNode* prev = pos->prev;LTNode* next = pos->next;prev->next = next;next->prev = prev;free(pos);
}
4. 链表的其他操作
我们还实现了一些常见的链表操作,如LTPushBack(在链表尾部插入节点)、LTPopBack(删除链表尾部节点)、LTPushFront(在链表头部插入节点)和LTPopFront(删除链表头部节点)。这些操作都依赖于LTInsert和LTErase函数。
void LTPushBack(LTNode* phead, LTDataType x)
{assert(phead);LTInsert(phead, x);
}void LTPopBack(LTNode* phead)
{assert(phead);LTErase(phead->prev);
}void LTPushFront(LTNode* phead, LTDataType x)
{assert(phead);LTInsert(phead->next, x);
}void LTPopFront(LTNode* phead)
{assert(phead);LTErase(phead->next);
}
5. 打印链表和判断链表是否为空
为了方便调试和观察链表的状态,我们实现了LTPrint函数来打印链表中的所有节点数据。此外,LTEmpty函数用于判断链表是否为空。
void LTPrint(LTNode* phead)
{assert(phead);LTNode* cur = phead->next;printf("<=phead=>");while (cur != phead){printf("%d<=>", cur->data);cur = cur->next;}puts("");
}bool LTEmpty(LTNode* phead)
{assert(phead);return phead == phead->next;
}
6. 销毁链表
在使用完链表后,我们需要释放所有节点的内存,避免内存泄漏。
void LTDestroy(LTNode* phead)
{assert(phead);LTNode* cur = phead->next;while (cur != phead){LTNode* next = cur->next;free(cur);cur = next;}free(phead);
}
4测试代码
为了验证我们的双向循环链表实现是否正确,我们编写了一个简单的测试函数Test1。在这个函数中,我们进行了多次插入、删除操作,并打印链表的状态。
void Test1()
{LTNode* phead = LTInit();LTPushBack(phead, 2);LTPushBack(phead, 1);LTPushFront(phead, 5);LTPrint(phead);LTInsert(phead->next, 6);LTInsert(phead->next, 6);LTPushFront(phead, 6);LTPrint(phead);LTPopBack(phead);LTPopBack(phead);LTPopFront(phead);LTErase(phead->next);LTPrint(phead);LTPushBack(phead, 4);LTPushBack(phead, 3);LTPushBack(phead, 2);LTPushBack(phead, 1);LTPrint(phead);printf("%d\n", LTEmpty(phead));LTDestroy(phead);phead = LTInit();printf("%d\n", LTEmpty(phead));
}int main()
{Test1();return 0;
}
5链表种类介绍


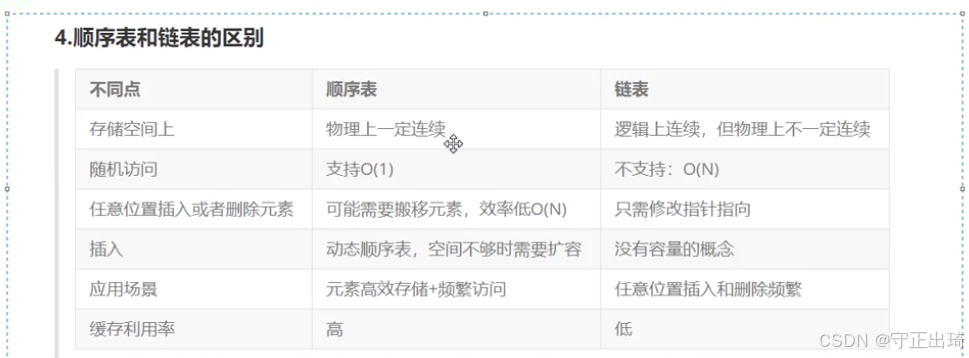
6链表与顺序表的区别
7存储金字塔

这张图片展示了计算机存储体系的层级结构,通常被称为存储金字塔(Memory Hierarchy)。它描述了不同层级的存储设备从最快速但成本最高到最慢但成本最低的分布情况。每一层级的存储设备都具有不同的访问速度和成本,它们相互配合,以实现性能和成本的最佳平衡。
存储金字塔层级介绍:
L0: 寄存器
位于金字塔的顶端,是CPU内部的寄存器,提供最快的数据访问速度。
寄存器的数量有限,因此它们用于存储最频繁访问的数据。
L1: 高速缓存(SRAM)
位于寄存器下方,是CPU的一级缓存,使用静态随机存取存储器(SRAM)。
L1缓存分为两个部分:L1指令缓存(L1-I)和L1数据缓存(L1-D),分别用于存储指令和数据。
L2: 高速缓存(SRAM)
二级缓存通常集成在CPU芯片上,或者在某些设计中位于CPU芯片附近。
L2缓存比L1缓存大,但访问速度稍慢。
L3: 高速缓存(SRAM)
三级缓存是更大但速度较慢的缓存层级,通常位于CPU芯片外。
L3缓存为多个核心共享,用于减少核心之间的数据访问延迟。
L4: 主存(DRAM)
主存储器,即动态随机存取存储器(DRAM),是计算机的主要内存。
与缓存相比,主存的访问速度较慢,但容量更大,成本更低。
L5: 本地二级存储(本地磁盘)
本地磁盘,如硬盘驱动器(HDD)或固态硬盘(SSD),用于长期存储数据。
访问速度比主存慢得多,但存储容量更大,成本更低。
L6: 远程二级存储
远程存储,如分布式文件系统、网络附加存储(NAS)或Web服务器,提供更大的存储空间。
访问速度最慢,但可以提供几乎无限的存储容量。
缓存利用率与局部性原理:
缓存利用率:指的是缓存中存储的数据被访问的频率。高缓存利用率意味着更多的数据访问可以直接从缓存中获取,从而提高系统性能。
局部性原理:包括时间局部性和空间局部性。时间局部性指的是最近访问过的数据很可能在不久的将来再次被访问;空间局部性指的是如果一个数据被访问,那么它附近的数据也很可能被访问。缓存的设计就是基于这些原理,以提高缓存利用率。
8书籍推荐《深入理解计算机系统》
链接: 书籍介绍
9新年快乐,代码相伴
在这个充满希望的新年里,愿你的代码之旅充满乐趣和挑战。无论是探索数据结构的奥秘,还是深入理解计算机系统的运行机制,都希望你能收获满满。让我们一起在代码的世界里,继续探索、学习和成长,用代码书写属于自己的精彩篇章。

![[权限提升] Windows 提权 维持 — 系统错误配置提权 - Trusted Service Paths 提权](https://i-blog.csdnimg.cn/direct/a72a333483134a1d98c5e68e64756ac7.jpeg)