1.课程目标和课程内容介绍


2.数仓维度建模设计








3.数仓为什么要分层


4.数仓分层思想和作用



下面是阿里的一种分层方式



5.数仓中表的种类和同步策略



6.数仓中表字段介绍以及表关系梳理



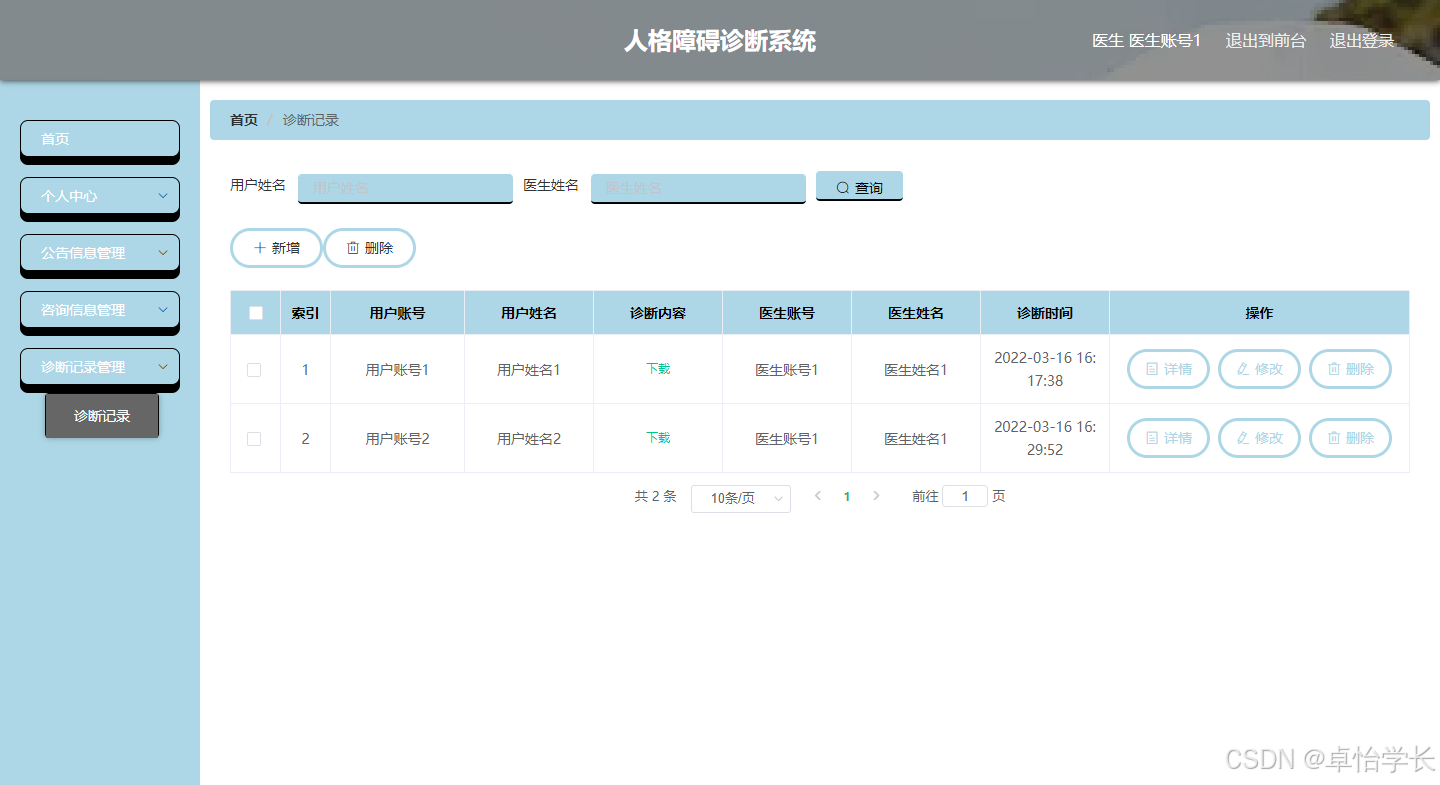
订单表itcast_orders

订单明细表 itcast_order_goods
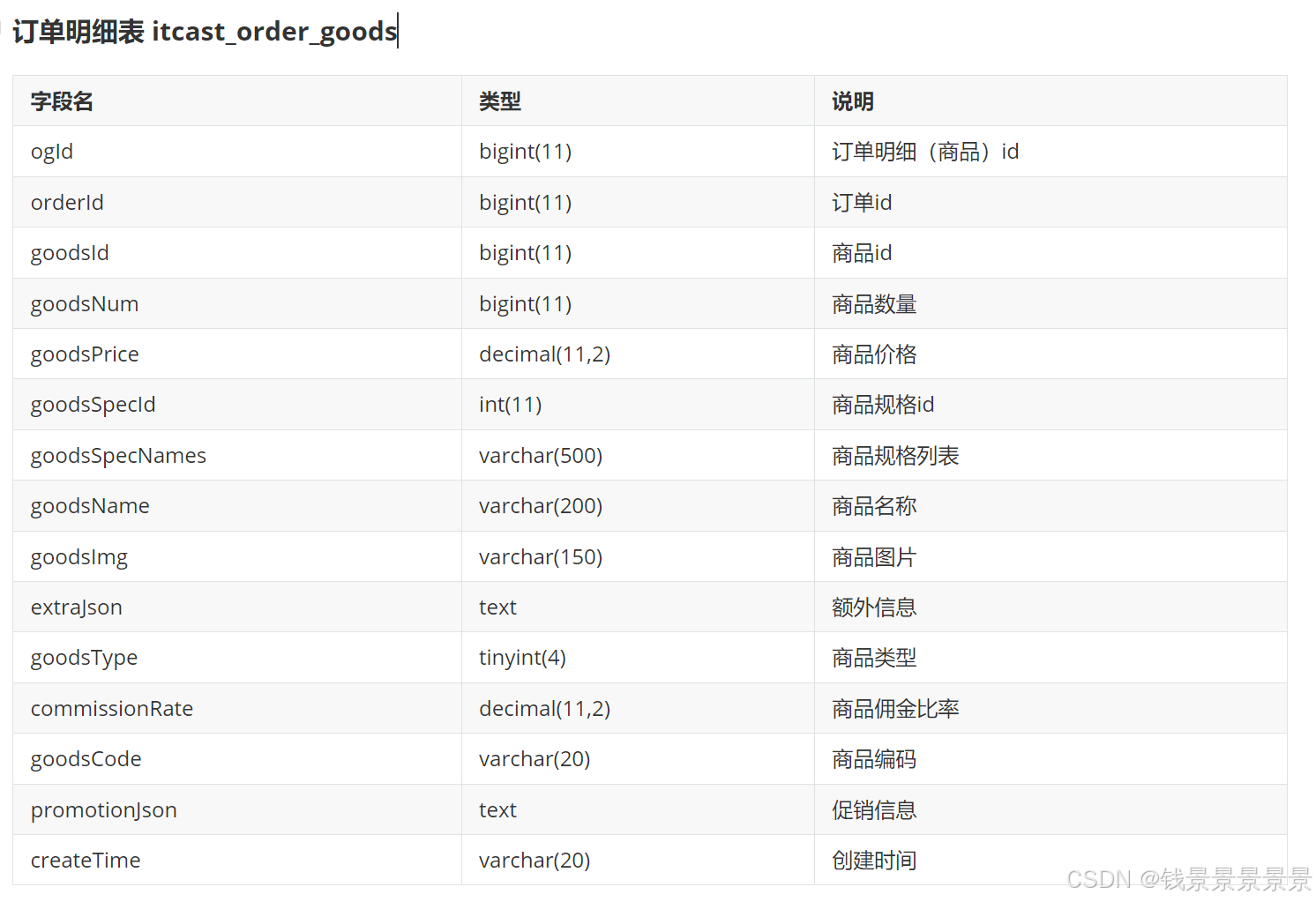
商品信息表 itcast_goods
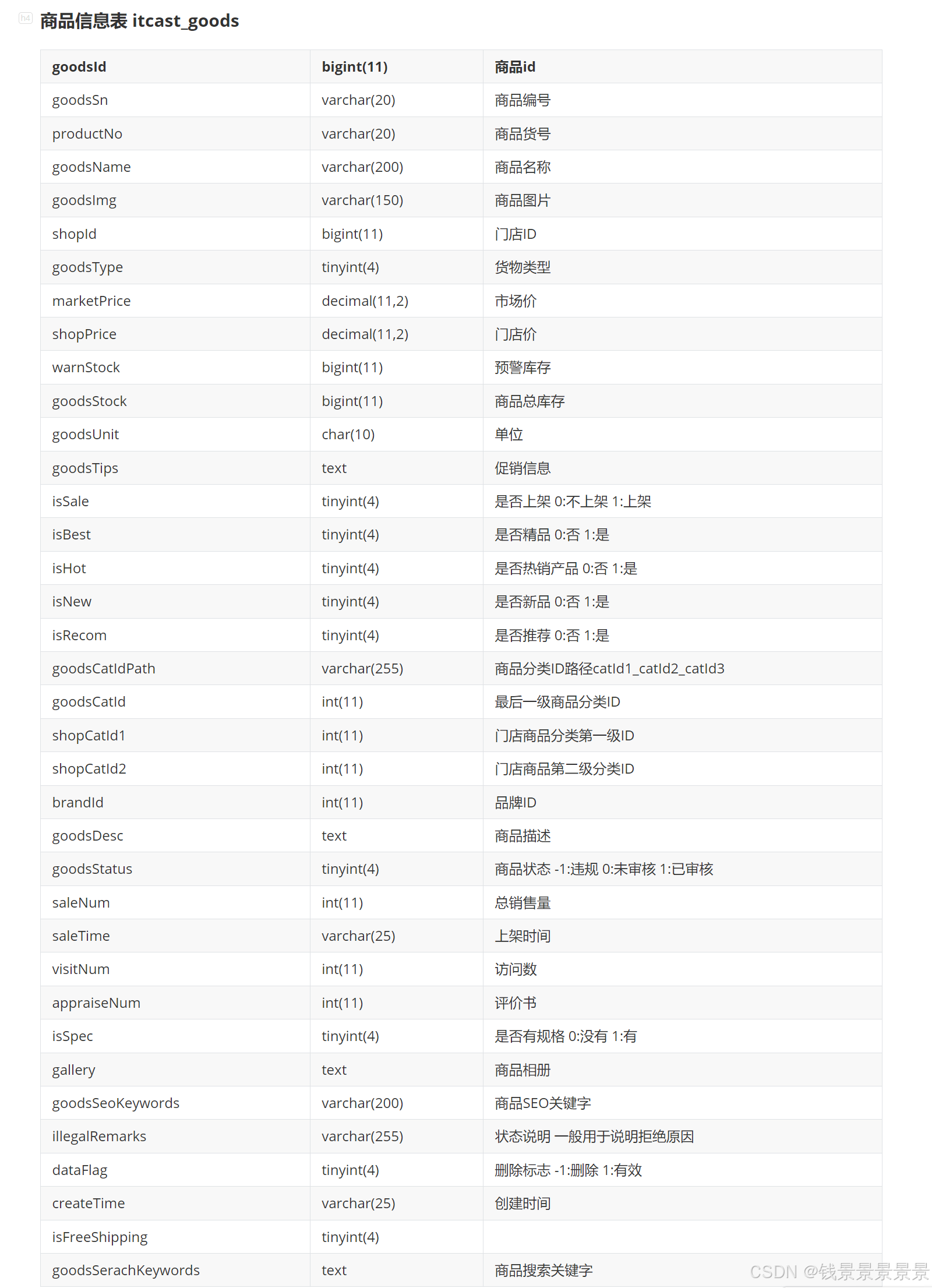
店铺表 itcast_shops

商品分类表 itcast_goods_cats

组织结构表 itcast_org

订单退货表 itcast_order_refunds

用户表 itcast_users

用户收货地址表 itcast_user_address

支付方式表 itcast_payments

7.项目环境初始化
导入MySQL模拟数据



将SQL文件上传到Linux

登入MySQL并执行命令

已经上传成功

hive分层说明

登入hive,创建表



创建ods层数据表







因为后面要用spark执行,spark对我们的Parquet和Snappy是执行的最好的
粘贴过来执行



数据采集



这里的命令可以帮我们对hive分区表进行一个修复

将小于${dt}(默认时间点)之前的当做全量要采集的数据,直接采集过来

我们打开kettle看一下








这里的${dt}是我们的默认命名参数
我们双击转换的空白处,看一下


上面的三张表是使用${dt}限制的
其余的表都是全量采集
比如


下面看一下字段选择

里面的每一个时间字段都要指定格式

下面看一下字段选择


这里我们要指定路径,
我们要写数据到hive表,使用表输出的方式太慢
我们直接将数据文件生成到hdfs路径上,这个路径就是我们的某一张hive表对应的路径

要指定hadoop cluster的连接

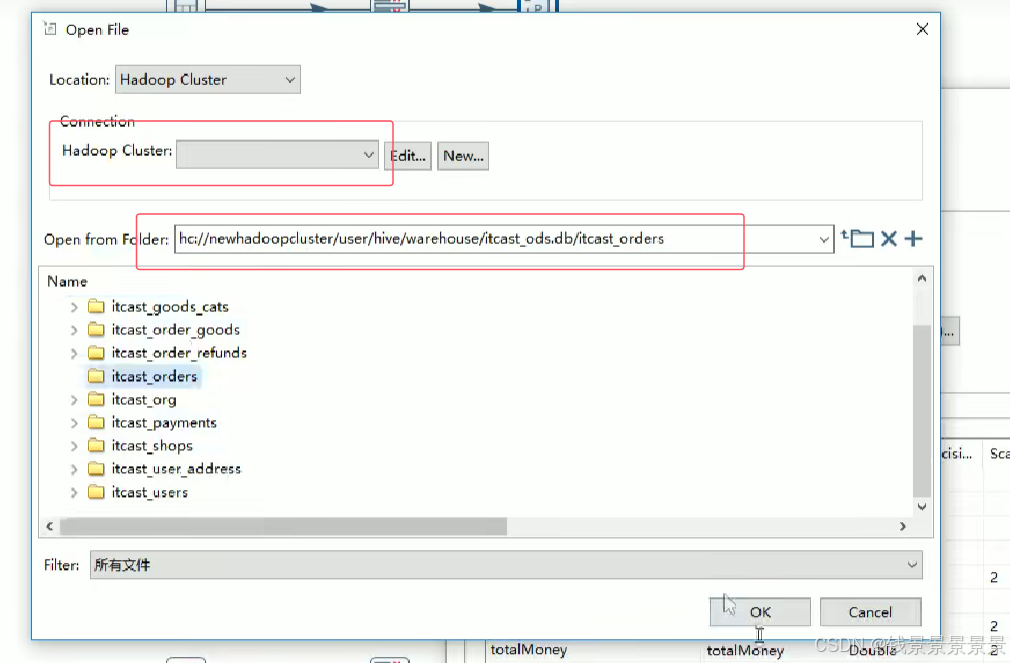
由于我们全是分区表,所以我们要加上分区文件的路径


所有的date类型要改成utf-8,date后面会出现问题
因为我们前面已经指定了格式
这里我们就按照字符串的形式写进去

==================================================================================================================================================

上面设置结束后,我们就可以执行我们的作业

我们再去hive表里面验证一下



8.缓慢变化维问题以及常见解决方案






9.商品案例-每日全量采集方案





10.每日全量案例实现
MySQL&Hive初始化 
先创建库




上面表创建成功





增量导入12月20日数据







这里主要是帮我们添加一个分区(如果分区不存在,就添加)
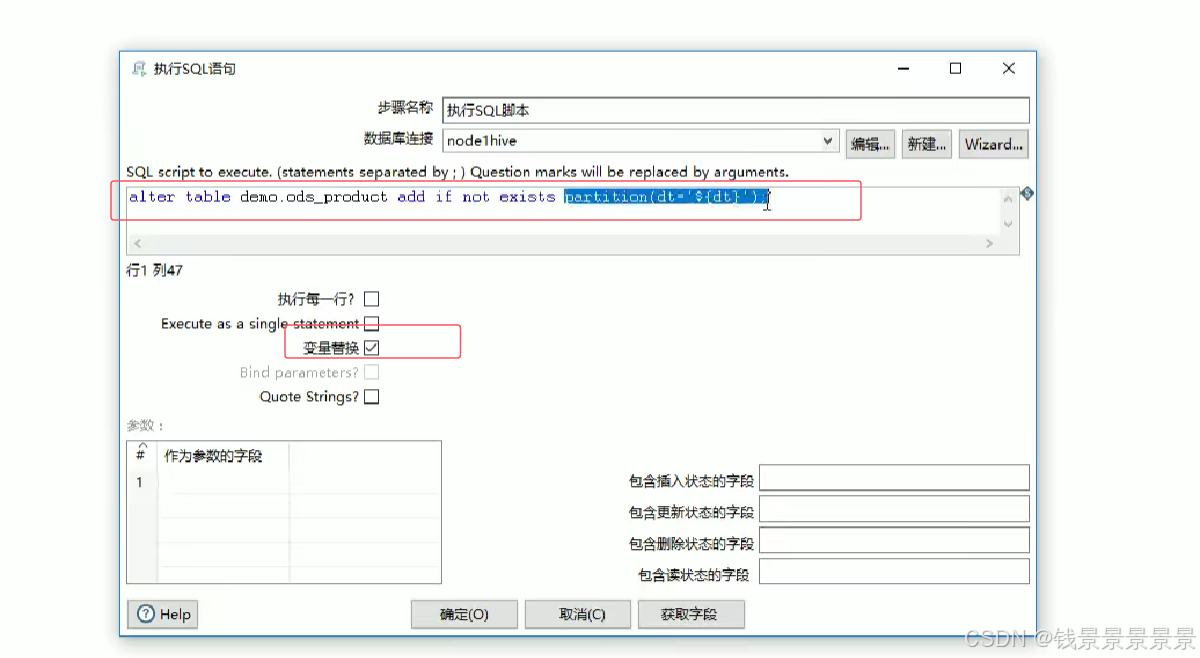





最后双击空白处
调整转换命名参数

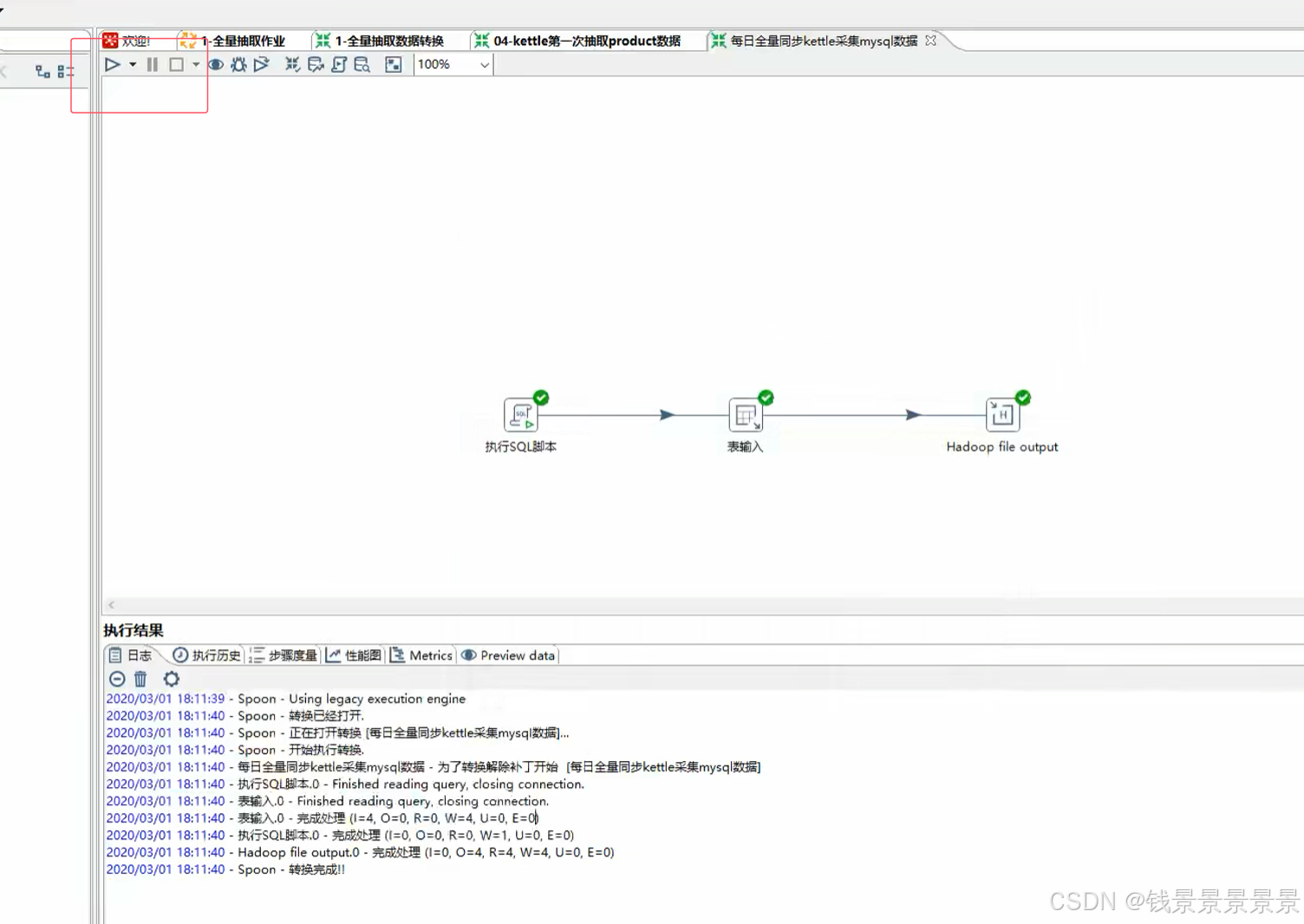

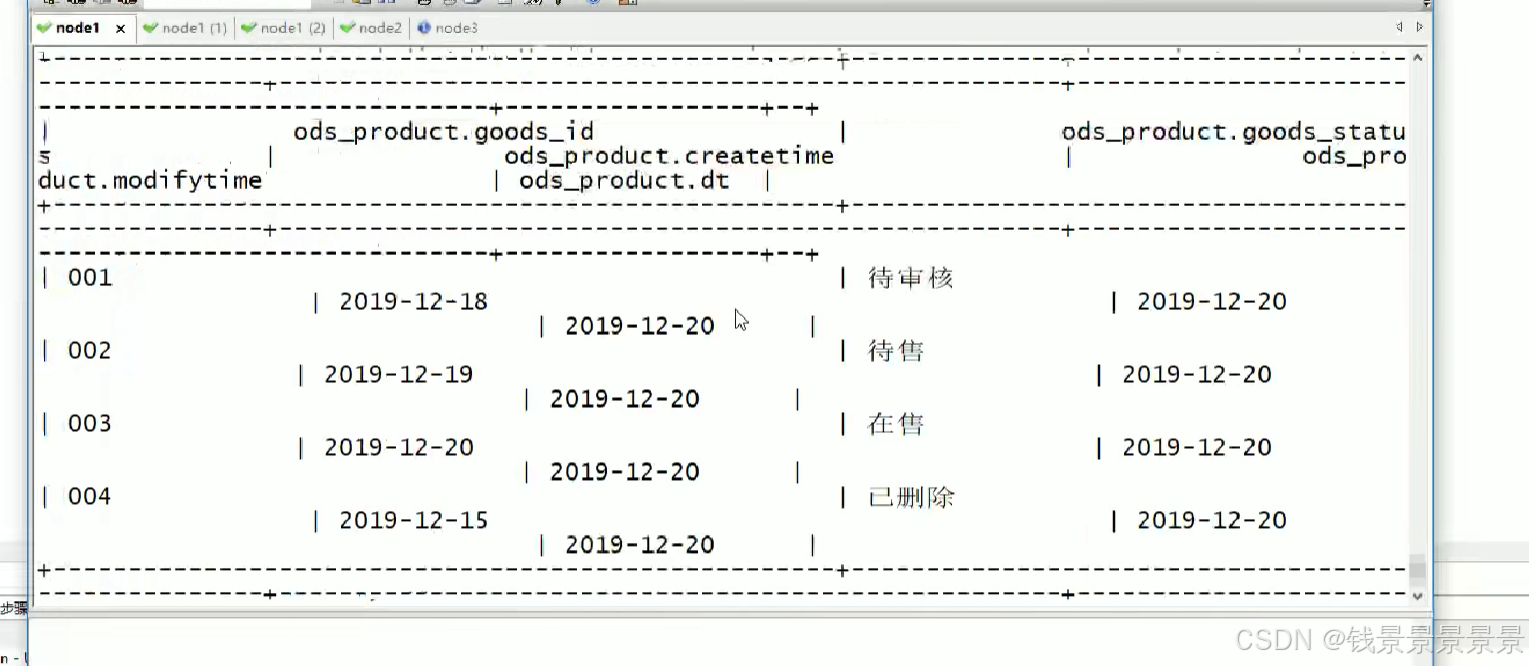
上面已经成功导入hive的ods层了,已经查询到
下面再将数据导入维度表,导入dw层




增量导入12月21日数据






运行之后是将数据存储到了ods的12月21号的分区
我们查看一下





如果我们查询的时候没有指定分区,应该有10条数据


增量导入12月22日数据





11.拉链表技术介绍



12.拉链表技术实现-第一次导入数据到拉链表

MySQL&Hive表初始化






这里的表不是分区表了,用一张大表构建



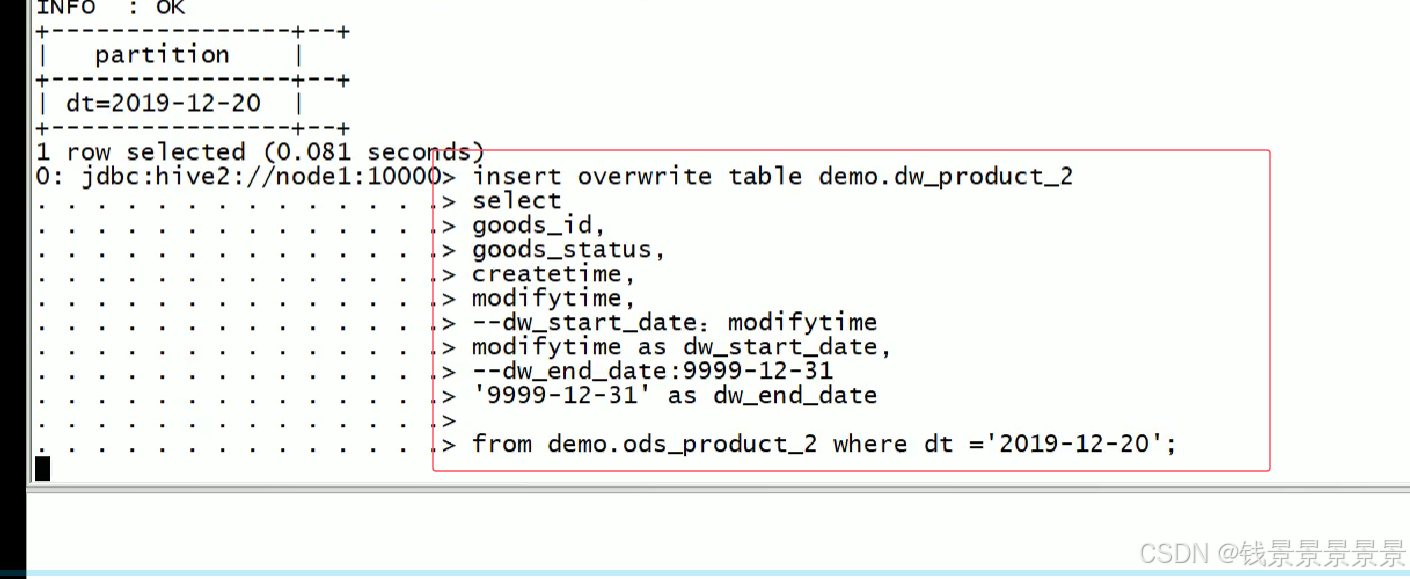
全量导入2019年12月20日数据




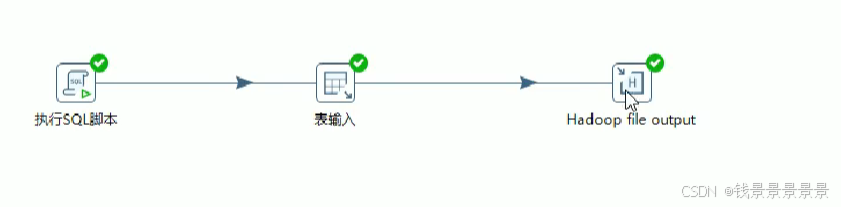







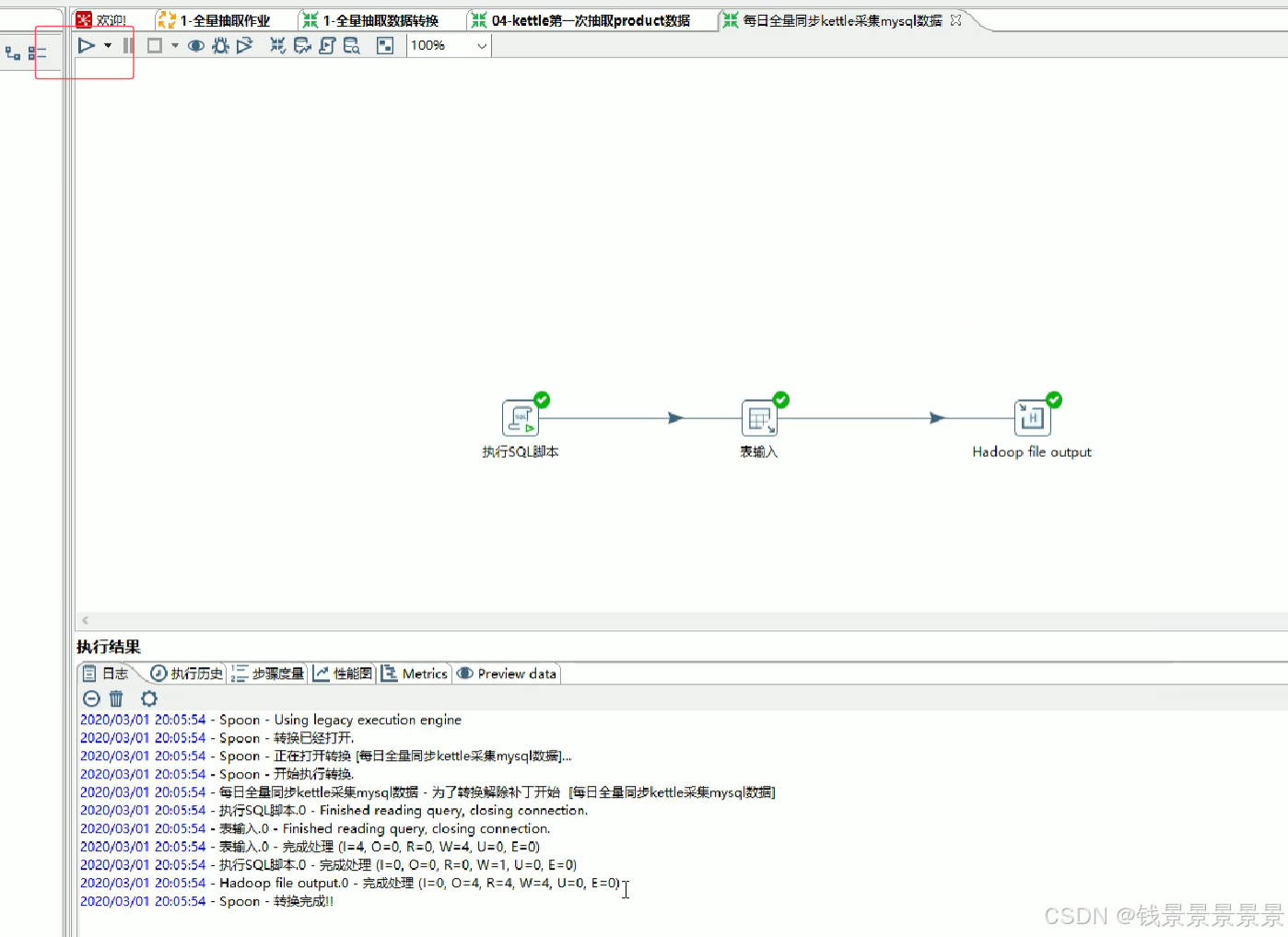




13.拉链表技术实现-历史数据更新
增量导入2019年12月21日数据
MySQL数据库导入12月21日数据(6条数据)



这里我们总共要采集001、005、006三条数据
他们的modifytime的字段一定是21号的

使用Kettle开发增量同步MySQL数据到Hive ods层表




这里首先执行的SQL语句是hive进行操作的



这里的SQL操作就是根据modifytime字段,找出新增或者更新的数据






编写SQL处理dw层历史数据,重新计算之前的dw_end_date









=============================

注意:这里很重要,因为有可能我们的表经过多次更新
但我们只需要修改最近一次的更新的那一条数据
14.拉链表技术实现-新增数据插入以及合并


最后的效果