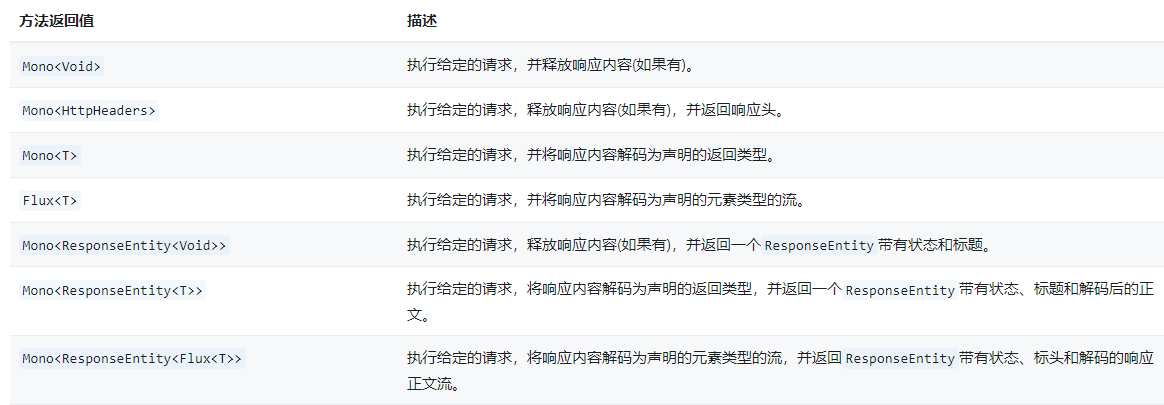
通过仔细查看和优化执行计划和基础数据库架构,可以显著提高Azure Synapse Dedicated SQL Pool中的查询性能。SQL语句的每个部分都对应执行计划中的具体步骤。
执行计划中的步骤和对应的SQL查询部分:
-
扫描操作:
- SQL 语句:** 'FROM ’ 或 'JOIN
’
- 执行计划:执行计划以 Scan 运算符开头,该运算符可以是 聚集索引扫描、表扫描或 分段表扫描(适用于分布式表)。
- 描述: 数据库扫描相关表(或索引)以查找与查询条件匹配的数据。
- 优化提示: 确保表以最佳方式分布(例如,对于大型表进行哈希分布),以避免在大型分布式环境中效率低下的全表扫描。
- SQL 语句:** 'FROM ’ 或 'JOIN
-
筛选操作:
- SQL 语句:** 'WHERE ’
- 执行计划: 这对应于 过滤器 运算符。
- 描述:查询引擎应用 WHERE 子句中指定的过滤条件,以减少扫描返回的数据。
- 优化提示: 确保 ‘WHERE’ 子句中的谓词尽可能具有选择性。对经常筛选的列进行索引或分区可以加快此过程。
-
Join 操作:
- SQL 语句:** ‘JOIN’ (例如,‘INNER JOIN’, ‘LEFT JOIN’)
- 执行计划:执行计划可能包括 Hash Join、Merge Join 或 Nested Loops Join。
- 描述: 联接用于根据相关列合并两个或多个表中的行。
- 哈希联接 通常用于大型数据集。
- 在对数据进行排序时使用 Merge Join 。
- 嵌套循环连接 用于小型数据集或一侧非常小时。
- 优化提示: 考虑 join 顺序,如果可能,请在 join 之前过滤数据。此外,请确保表分布适当,以最大程度地减少数据移动。
-
排序操作:
- SQL 语句:** 'ORDER BY ’
- 执行计划: 这对应于 Sort 运算符。
- 描述: 根据 ‘ORDER BY’ 子句中提到的列对数据进行排序。
- 优化提示: 避免在大型数据集中进行不必要的排序。如果需要排序,请考虑在已排序的列上使用索引。
-
聚合:
- SQL 语句:‘GROUP BY’, ‘COUNT()’, ‘SUM()’, ‘AVG()’ 等。
- 执行计划:这对应于 聚合 运算符。
- 描述:根据分组条件对数据进行聚合。此操作需要数据随机排序,并且在分布式系统中可能很昂贵。
- 优化提示: 如果可能,请预先聚合数据,或使用索引视图来加速聚合。
-
Projection操作:
- SQL 语句:** 'SELECT ’
- 执行计划:这与 Project** 运算符相对应。
- 描述:从结果集中选择特定列,并丢弃其他列。
- 优化提示: 将所选列限制为仅查询所需的列,以减少 I/O 并提高性能。
-
Exchange/Distribution:
- SQL 语句:通常隐式,例如在联接、聚合或大型扫描期间。
- 执行计划: 这对应于 Exchange 运算符,它表示跨分配的数据移动。
- 描述: 来自不同节点的数据需要在系统内进行 shuffle 以进行 join 和 aggregation 等操作,这可能会导致延迟。
- 优化提示: 优化表分布(例如,在 Join 键上对大型表进行哈希分配)以最大限度地减少数据移动。
- Segmented Table Scans(适用于分布式表):
- SQL 语句:** ‘FROM <distributed_table>’
- 执行计划: 这对应于 Segmented Table Scans。
- 描述: 一种用于分布式表的特殊扫描运算符,其中数据跨分布单元(或节点)划分为多个段。
- 优化提示: 确保数据分布均匀,避免倾斜。仔细考虑 hash distribution 键,以优化并行处理并减少数据随机排序。
Azure Synapse Dedicated SQL Pool的关键优化策略:
-
表分布优化:
- 为每个表选择合适的分配方法:
- 哈希分配:用于键上频繁联接的大型事实表。
- 循环分配: 对于较小、不经常联接的表或不存在自然键的情况非常有用。
- 复制的表:可以在所有分配之间复制小型查找表,以消除联接期间移动数据的需要。
- 为每个表选择合适的分配方法:
-
索引:
- 对于大型表,请确保使用适当的聚集列存储索引进行高效的数据检索。
- 对于经常筛选或联接的列,应考虑使用非聚集索引。
-
分区:
- 根据频繁筛选或查询的列对大型表进行分区,以最大限度地降低扫描成本。
- 分区修剪:确保在查询执行期间修剪分区以提高性能。
-
列存储索引:
- 使用 聚集列存储索引 来提高大型数据集的扫描和聚合性能。
- 它们减少了 I/O 并提高了压缩率,这可以显著加快涉及大量数据的查询速度。
-
最大限度地减少数据移动:
- 通过仔细选择联接条件、分布并确保最大限度地减少数据随机排序,减少数据移动的需求。
- 与需要在节点之间重新分配数据的哈希联接相比,广播联接(当一个表较小且被复制时)可能非常有效。
-
优化查询模式:
- 避免复杂子查询:将具有多个子查询的查询重构为联接或 CTE(公用表表达式)。
- 限制不必要的列:避免使用 ‘SELECT *’,只请求必要的列。
- 提前筛选:尽早在查询中应用筛选条件,以减少后期处理的数据量。
-
批量查询和并行度:
- 将大型查询划分为较小的批次,以实现更好的并行性。
- 使用与查询模式一致的 分布和分区 策略来减少争用并改进并行处理。
-
物化视图或索引视图:
- 预先计算并存储在 具体化视图 中常用的聚合或联接,以加快检索速度。
-
避免数据偏差:
- 确保大型表均匀分布,以防止热点(需要处理的数据比其他节点多的节点)。