文章目录
- 1. Word Embedding
- 2. Position Embedding
- 3. python 代码
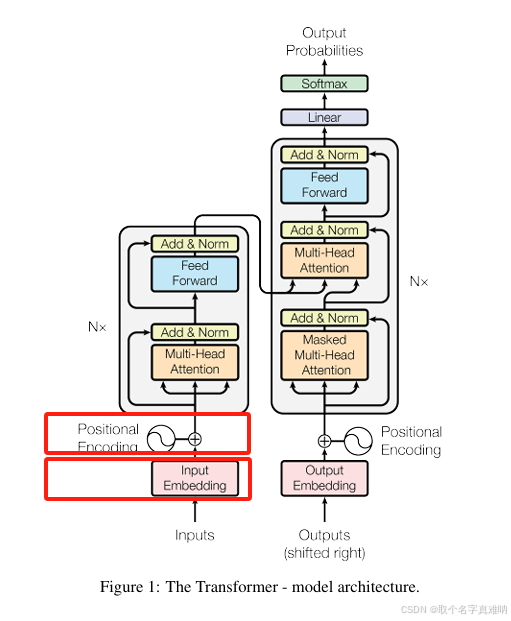
1. Word Embedding
根据矩阵序列实现在nn.Embedding中抽取制定的行作为词向量,长度不同时,自动填充到统一长度
2. Position Embedding
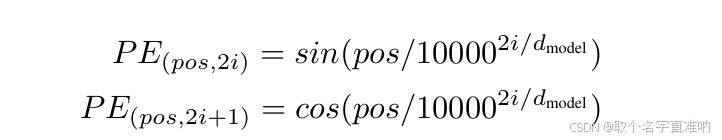
python__6">3. python 代码
python">import torch
import torch.nn as nn
import torch.nn.functional as F
torch.manual_seed(22323)
torch.set_printoptions(precision=3, sci_mode=False)# 1. step1: get index sequence matrix
# 1. input = torch.Tensor([2,4])
# 2. output = torch.Tensor([[1,2,0,0,0]
# [3,2,5,4,0]])
# 1. src_seq,---> (batch_size,len
class PositionEmbeddings(nn.Module):def __init__(self, max_len, max_dim):super(PositionEmbeddings, self).__init__()self.max_len1 = max_lenself.max_dim = max_dimself.embedding = nn.Embedding(self.max_len1, self.max_dim)def forward(self, x):row_ones = torch.ones((1, self.max_dim)).to(torch.float)print(f"row_ones.shape=\n{row_ones.shape}")print(f"row_ones=\n{row_ones}")row_pos = torch.arange(self.max_len1).reshape((-1, 1)).to(torch.float)print(f"row_pos=\n{row_pos}")pos_mat = row_pos @ row_onesprint(f"pos_mat=\n{pos_mat}")column_ones = torch.ones((self.max_len1, 1)).to(torch.float)print(f"column_ones=\n{column_ones}")sin_arange = torch.arange(self.max_dim).reshape((1, -1)).to(torch.float)sin_arange[:, 1::2] = 0i2_dmodel = sin_arange / self.max_dimprint(f"i2_dmodel={i2_dmodel}")power = 10000sin_power_i2_dmodel = torch.pow(power, i2_dmodel)sin_pos_power_mat = column_ones @ sin_power_i2_dmodelprint(f"sin_pos_power_mat=\n{sin_pos_power_mat}")sin_mat = torch.sin(pos_mat / sin_pos_power_mat)sin_mat[:, 1::2] = 0print(f"sin_mat=\n{sin_mat}")cos_arange = torch.arange(self.max_dim).reshape((1, -1)).to(torch.float)cos_arange[:, 0::2] = 0cos_i2_dmodel = cos_arange / self.max_dimprint(f"cos_i2_dmodel={cos_i2_dmodel}")power = 10000cos_power_i2_dmodel = torch.pow(power, cos_i2_dmodel)cos_pos_power_mat = column_ones @ cos_power_i2_dmodelprint(f"cos_pos_power_mat=\n{cos_pos_power_mat}")cos_mat = torch.cos(pos_mat / cos_pos_power_mat)print(f"cos_mat=\n{cos_mat}")cos_mat[:, 0::2] = 0print(f"sin_mat=\n{sin_mat}")print(f"cos_mat=\n{cos_mat}")pe_mat = sin_mat + cos_matprint(f"pe_mat=\n{pe_mat}")pe_embedding = nn.Embedding(self.max_len1, self.max_dim)pe_embedding.weight = nn.Parameter(pe_mat, requires_grad=False)print(f"pe_embedding=\n{pe_embedding.weight}")ouput = pe_embedding(x)return ouputclass CreateIndexMatrix(nn.Module):def __init__(self, max_len, max_dim):super(CreateIndexMatrix, self).__init__()self.max_len = max_lenself.max_dim = max_dimself.result_matrix = torch.zeros((self.max_len, self.max_dim))def forward(self, x):my_x = xmy_num = torch.numel(my_x)# my_seq = [F.pad(torch.randint(1, self.max_len, (L,)),(0,self.max_dim-L)) for L in my_x]# my_seq = [torch.unsqueeze(F.pad(torch.randint(1, self.max_len, (L,)), (0, self.max_dim - L)), dim=0) for L in# my_x]my_seq = torch.cat([torch.unsqueeze(F.pad(torch.randint(1, self.max_len, (L,)), (0, self.max_dim - L)), dim=0) for L inmy_x], dim=0)# print(f"my_seq=\n{my_seq}")return my_seqif __name__ == "__main__":run_code = 0src_len = torch.Tensor([2.0, 4.0]).to(torch.int32)tgt_len = torch.Tensor([4.0, 3.0]).to(torch.int32)print(f"src_len={src_len}")print(f"tgt_len={tgt_len}")print(torch.numel(src_len))src_max_len = 5src_max_dim = 8tgt_max_len = 5tgt_max_dim = 5my_matrix_src = CreateIndexMatrix(src_max_len, src_max_dim)my_matrix_tgt = CreateIndexMatrix(src_max_len, src_max_dim)word_seq_src = my_matrix_src(src_len)word_seq_tgt = my_matrix_src(tgt_len)print(f"word_seq_src=\n{word_seq_src}")print(f"word_seq_tgt=\n{word_seq_tgt}")src_embedding_table = nn.Embedding(src_max_len + 1, src_max_dim)print(f"src_embedding_table.weight=\n{src_embedding_table.weight}")src_word_embedding = src_embedding_table(word_seq_src)print(f"word_seq_src=\n{word_seq_src}")print(f"src_word_embedding=\n{src_word_embedding}")tgt_embedding_table = nn.Embedding(tgt_max_len + 1, tgt_max_dim)tgt_word_embedding = tgt_embedding_table(word_seq_tgt)print(f"word_seq_tgt=\n{word_seq_tgt}")print(f"tgt_word_embedding=\n{tgt_word_embedding}")my_pos_matrix = PositionEmbeddings(src_max_len, src_max_dim)print(my_pos_matrix(word_seq_src))
- 结果
python">src_len=tensor([2, 4], dtype=torch.int32)
tgt_len=tensor([4, 3], dtype=torch.int32)
2
word_seq_src=
tensor([[3, 1, 0, 0, 0, 0, 0, 0],[3, 2, 4, 3, 0, 0, 0, 0]])
word_seq_tgt=
tensor([[4, 1, 3, 3, 0, 0, 0, 0],[1, 1, 2, 0, 0, 0, 0, 0]])
src_embedding_table.weight=
Parameter containing:
tensor([[ 0.991, 0.168, -0.281, 0.527, 0.648, -0.331, -0.017, 0.029],[ 2.050, 0.348, -0.532, 1.540, -0.233, 0.176, -0.937, 0.500],[-1.087, -1.750, 1.535, -2.043, -3.229, 0.235, 1.206, -0.232],[-0.558, 0.061, -0.617, -0.523, -0.559, 0.301, -2.089, 0.562],[-0.278, 0.040, 1.628, 0.283, 0.157, 0.165, 1.659, -0.328],[-0.430, 1.530, 1.793, 0.976, -0.355, 0.060, -0.010, 0.525]],requires_grad=True)
word_seq_src=
tensor([[3, 1, 0, 0, 0, 0, 0, 0],[3, 2, 4, 3, 0, 0, 0, 0]])
src_word_embedding=
tensor([[[-0.558, 0.061, -0.617, -0.523, -0.559, 0.301, -2.089, 0.562],[ 2.050, 0.348, -0.532, 1.540, -0.233, 0.176, -0.937, 0.500],[ 0.991, 0.168, -0.281, 0.527, 0.648, -0.331, -0.017, 0.029],[ 0.991, 0.168, -0.281, 0.527, 0.648, -0.331, -0.017, 0.029],[ 0.991, 0.168, -0.281, 0.527, 0.648, -0.331, -0.017, 0.029],[ 0.991, 0.168, -0.281, 0.527, 0.648, -0.331, -0.017, 0.029],[ 0.991, 0.168, -0.281, 0.527, 0.648, -0.331, -0.017, 0.029],[ 0.991, 0.168, -0.281, 0.527, 0.648, -0.331, -0.017, 0.029]],[[-0.558, 0.061, -0.617, -0.523, -0.559, 0.301, -2.089, 0.562],[-1.087, -1.750, 1.535, -2.043, -3.229, 0.235, 1.206, -0.232],[-0.278, 0.040, 1.628, 0.283, 0.157, 0.165, 1.659, -0.328],[-0.558, 0.061, -0.617, -0.523, -0.559, 0.301, -2.089, 0.562],[ 0.991, 0.168, -0.281, 0.527, 0.648, -0.331, -0.017, 0.029],[ 0.991, 0.168, -0.281, 0.527, 0.648, -0.331, -0.017, 0.029],[ 0.991, 0.168, -0.281, 0.527, 0.648, -0.331, -0.017, 0.029],[ 0.991, 0.168, -0.281, 0.527, 0.648, -0.331, -0.017, 0.029]]],grad_fn=<EmbeddingBackward0>)
word_seq_tgt=
tensor([[4, 1, 3, 3, 0, 0, 0, 0],[1, 1, 2, 0, 0, 0, 0, 0]])
tgt_word_embedding=
tensor([[[ 0.491, -0.151, 1.233, 1.313, 2.073],[-1.523, 2.063, -2.640, -1.130, -0.148],[ 0.402, -0.654, -0.677, -0.934, -0.158],[ 0.402, -0.654, -0.677, -0.934, -0.158],[-0.165, 1.398, -1.070, 0.093, 1.199],[-0.165, 1.398, -1.070, 0.093, 1.199],[-0.165, 1.398, -1.070, 0.093, 1.199],[-0.165, 1.398, -1.070, 0.093, 1.199]],[[-1.523, 2.063, -2.640, -1.130, -0.148],[-1.523, 2.063, -2.640, -1.130, -0.148],[ 1.009, 0.027, -1.191, -1.281, 0.358],[-0.165, 1.398, -1.070, 0.093, 1.199],[-0.165, 1.398, -1.070, 0.093, 1.199],[-0.165, 1.398, -1.070, 0.093, 1.199],[-0.165, 1.398, -1.070, 0.093, 1.199],[-0.165, 1.398, -1.070, 0.093, 1.199]]],grad_fn=<EmbeddingBackward0>)
row_ones.shape=
torch.Size([1, 8])
row_ones=
tensor([[1., 1., 1., 1., 1., 1., 1., 1.]])
row_pos=
tensor([[0.],[1.],[2.],[3.],[4.]])
pos_mat=
tensor([[0., 0., 0., 0., 0., 0., 0., 0.],[1., 1., 1., 1., 1., 1., 1., 1.],[2., 2., 2., 2., 2., 2., 2., 2.],[3., 3., 3., 3., 3., 3., 3., 3.],[4., 4., 4., 4., 4., 4., 4., 4.]])
column_ones=
tensor([[1.],[1.],[1.],[1.],[1.]])
i2_dmodel=tensor([[0.000, 0.000, 0.250, 0.000, 0.500, 0.000, 0.750, 0.000]])
sin_pos_power_mat=
tensor([[ 1., 1., 10., 1., 100., 1., 1000., 1.],[ 1., 1., 10., 1., 100., 1., 1000., 1.],[ 1., 1., 10., 1., 100., 1., 1000., 1.],[ 1., 1., 10., 1., 100., 1., 1000., 1.],[ 1., 1., 10., 1., 100., 1., 1000., 1.]])
sin_mat=
tensor([[ 0.000, 0.000, 0.000, 0.000, 0.000, 0.000, 0.000, 0.000],[ 0.841, 0.000, 0.100, 0.000, 0.010, 0.000, 0.001, 0.000],[ 0.909, 0.000, 0.199, 0.000, 0.020, 0.000, 0.002, 0.000],[ 0.141, 0.000, 0.296, 0.000, 0.030, 0.000, 0.003, 0.000],[-0.757, 0.000, 0.389, 0.000, 0.040, 0.000, 0.004, 0.000]])
cos_i2_dmodel=tensor([[0.000, 0.125, 0.000, 0.375, 0.000, 0.625, 0.000, 0.875]])
cos_pos_power_mat=
tensor([[ 1.000, 3.162, 1.000, 31.623, 1.000, 316.228,1.000, 3162.278],[ 1.000, 3.162, 1.000, 31.623, 1.000, 316.228,1.000, 3162.278],[ 1.000, 3.162, 1.000, 31.623, 1.000, 316.228,1.000, 3162.278],[ 1.000, 3.162, 1.000, 31.623, 1.000, 316.228,1.000, 3162.278],[ 1.000, 3.162, 1.000, 31.623, 1.000, 316.228,1.000, 3162.278]])
cos_mat=
tensor([[ 1.000, 1.000, 1.000, 1.000, 1.000, 1.000, 1.000, 1.000],[ 0.540, 0.950, 0.540, 1.000, 0.540, 1.000, 0.540, 1.000],[-0.416, 0.807, -0.416, 0.998, -0.416, 1.000, -0.416, 1.000],[-0.990, 0.583, -0.990, 0.996, -0.990, 1.000, -0.990, 1.000],[-0.654, 0.301, -0.654, 0.992, -0.654, 1.000, -0.654, 1.000]])
sin_mat=
tensor([[ 0.000, 0.000, 0.000, 0.000, 0.000, 0.000, 0.000, 0.000],[ 0.841, 0.000, 0.100, 0.000, 0.010, 0.000, 0.001, 0.000],[ 0.909, 0.000, 0.199, 0.000, 0.020, 0.000, 0.002, 0.000],[ 0.141, 0.000, 0.296, 0.000, 0.030, 0.000, 0.003, 0.000],[-0.757, 0.000, 0.389, 0.000, 0.040, 0.000, 0.004, 0.000]])
cos_mat=
tensor([[0.000, 1.000, 0.000, 1.000, 0.000, 1.000, 0.000, 1.000],[0.000, 0.950, 0.000, 1.000, 0.000, 1.000, 0.000, 1.000],[0.000, 0.807, 0.000, 0.998, 0.000, 1.000, 0.000, 1.000],[0.000, 0.583, 0.000, 0.996, 0.000, 1.000, 0.000, 1.000],[0.000, 0.301, 0.000, 0.992, 0.000, 1.000, 0.000, 1.000]])
pe_mat=
tensor([[ 0.000, 1.000, 0.000, 1.000, 0.000, 1.000,0.000, 1.000],[ 0.841, 0.950, 0.100, 1.000, 0.010, 1.000,0.001, 1.000],[ 0.909, 0.807, 0.199, 0.998, 0.020, 1.000,0.002, 1.000],[ 0.141, 0.583, 0.296, 0.996, 0.030, 1.000,0.003, 1.000],[ -0.757, 0.301, 0.389, 0.992, 0.040, 1.000,0.004, 1.000]])
pe_embedding=
Parameter containing:
tensor([[ 0.000, 1.000, 0.000, 1.000, 0.000, 1.000,0.000, 1.000],[ 0.841, 0.950, 0.100, 1.000, 0.010, 1.000,0.001, 1.000],[ 0.909, 0.807, 0.199, 0.998, 0.020, 1.000,0.002, 1.000],[ 0.141, 0.583, 0.296, 0.996, 0.030, 1.000,0.003, 1.000],[ -0.757, 0.301, 0.389, 0.992, 0.040, 1.000,0.004, 1.000]])
tensor([[[ 0.141, 0.583, 0.296, 0.996, 0.030,1.000, 0.003, 1.000],[ 0.841, 0.950, 0.100, 1.000, 0.010,1.000, 0.001, 1.000],[ 0.000, 1.000, 0.000, 1.000, 0.000,1.000, 0.000, 1.000],[ 0.000, 1.000, 0.000, 1.000, 0.000,1.000, 0.000, 1.000],[ 0.000, 1.000, 0.000, 1.000, 0.000,1.000, 0.000, 1.000],[ 0.000, 1.000, 0.000, 1.000, 0.000,1.000, 0.000, 1.000],[ 0.000, 1.000, 0.000, 1.000, 0.000,1.000, 0.000, 1.000],[ 0.000, 1.000, 0.000, 1.000, 0.000,1.000, 0.000, 1.000]],[[ 0.141, 0.583, 0.296, 0.996, 0.030,1.000, 0.003, 1.000],[ 0.909, 0.807, 0.199, 0.998, 0.020,1.000, 0.002, 1.000],[ -0.757, 0.301, 0.389, 0.992, 0.040,1.000, 0.004, 1.000],[ 0.141, 0.583, 0.296, 0.996, 0.030,1.000, 0.003, 1.000],[ 0.000, 1.000, 0.000, 1.000, 0.000,1.000, 0.000, 1.000],[ 0.000, 1.000, 0.000, 1.000, 0.000,1.000, 0.000, 1.000],[ 0.000, 1.000, 0.000, 1.000, 0.000,1.000, 0.000, 1.000],[ 0.000, 1.000, 0.000, 1.000, 0.000,1.000, 0.000, 1.000]]])







