鸿蒙项目云捐助第十九讲云捐助百度智能名片识别
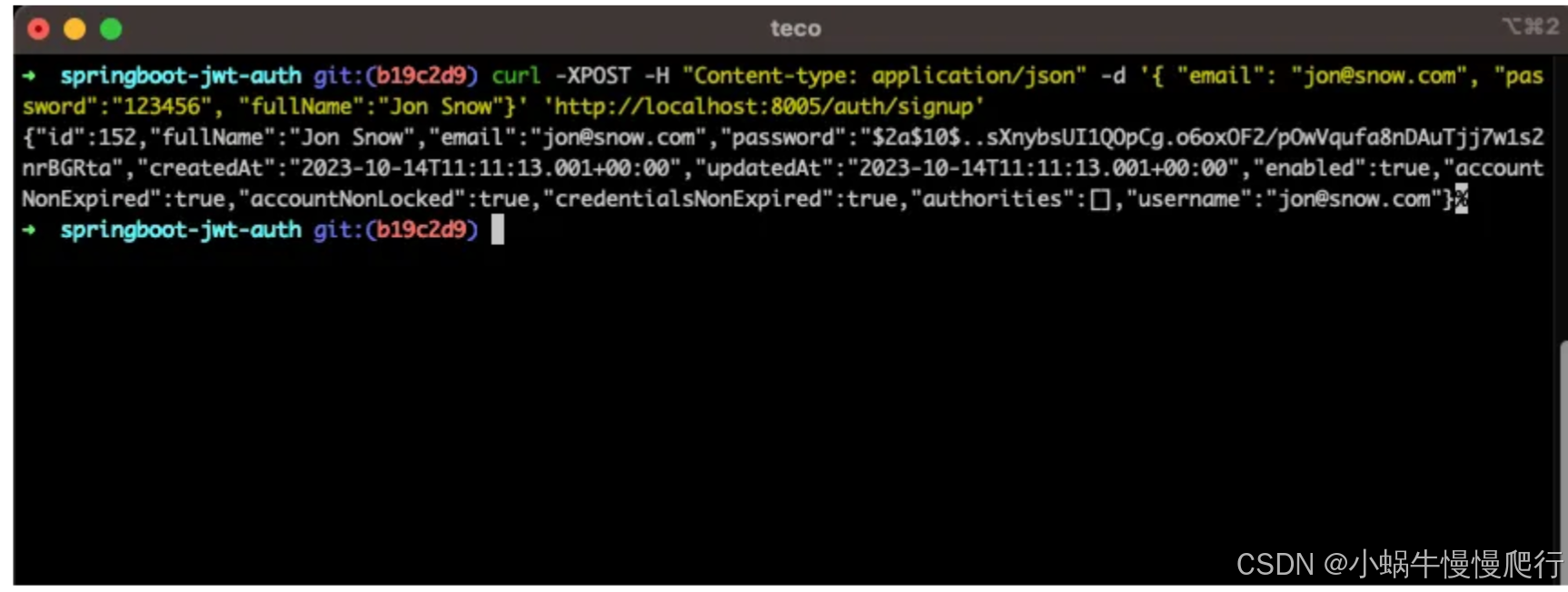
在鸿蒙云捐助项目中添加智能元素,这里实现鸿蒙云捐助的名片识别功能,用户只需要上传一张名片,就可以识别出地址和名字,根据地址和名字进行真实信息的确认。
首先找到OCR的名片识别接口,这个接口在百度AI的百度云中。

这里进入到的百度智能云平台的文字识别选项。在文字识别的文档中心中输入“名片”可以找到“名片识别”的接口。接口中可以看到名片识别的文档,如下图所示。

在这个文档中可以得知上传OCR名片的请求地址,在这个地址需要上传base64编码的图片,在上传图片时一定要在百度智能云平台做鉴权,做过鉴权后可以拼接出一个access_token的请求token值,把这个token值放在请求的地址中,使用post方式提交请求并携带base64编码的图片,这里注意一定要携带headers头文件,头文件中指定content-type的值是application/x-www-form-urlencoded。这样才可以获取到名片的地址。
在进行开发工作之前,需要在百度智能云中开通“名片识别”的服务,这里首先需要进入百度智能云文字识别的应用列表页面,如下图所示。

点击左侧的应用列表,可以看到“创建应用”的对话框,这里使用“名片识别”的服务就需要先创建一个应用。如下图所示。

在图示的页面中点击“创建应用”,这里输入应用名称,然后选择免费的文字识别服务,这里“名片识别”是免费的服务,在服务方面选择“名片识别”,如下图所示。

选择“名片识别”服务后,下面还有“应用归属”方面的设置信息,如下图所示。

这里将应用归属设置为“个人”,并且在应用描述中描述此应用的具体作用“这是一个识别卡片的demo应用”。输入信息后,点击下面的“立即创建”按钮完成应用的创建。创建后的效果如下图所示。

完成应用创建后,回到应用列表的页面,可以看到刚才创建的应用,并且能够看到应用的API key和secrent Key,这两个key在开发中都需要使用,如下图所示。

百度智能云的工作准备好后,这里进行鸿蒙功能的开发,在阅读文档时了解实现OCR智能识别需要用post方式上传图片,图片base64编码比较大,只能使用post方式,鸿蒙使用post方式请求数据时,最好的方式是使用模块axios第三方异步模块。这里通过鸿蒙DevEco Studio的Terminal安装axios的模块。

安装成功后,这里可以看到axios安装的版本信息是2.2.4。
这里需要把axios的版本2.2.4放在鸿蒙项目的oh-package.json5文件中。如下图所有所示。

添加axios的版本后,点击左上角的Sync同步一下这个文件。

当这里的符号变成绿色的对号表示同步更新结束,如下图所示。

这里可以在component文件夹建立MyMindSporeObject的组件,在组件中修改标题名称为“名片地址识别”。

这里在布局中加入Image 组件,用来显示从相册中选择的图片,对于相同的地址this.myurl就是从相册中获取的地址,这个地址在最初的时候赋值为空,初始化语句@State myurl:string=""表示的就是初始化的空值。在Image图片组件的下面就是Button按钮,Button按钮的作用是“打开相册”的功能按钮。其功能和布局代码如下图所示。

这里打开相册的onClick事件中首先调用picker模块中的PhotoSelectOption的实际化方法,这是相册选择的选项设置,设置了maxSelectNumber的最大选择图片的数量,然后new实例化picker模块中PhotoViewPicker()的相册选择实例,实例化相册选择后,调用select 方法选择相册中的文件,这里需要await异步,因为相册选择需要等待用户选择图片才可以进行显示,用户选择图片后执行到promise返回的then方法,在then方法中将全局地址myurl记录当前的相册地址,相册选择后返回的数据是一个json数据,在json数据中, photoUris的选项中存储的是文件地址,这里是一个数组,数据的第一项索引为0值。即调用数组的索引0值即可获取相册中选择的图片地址。
接下来布局文件中需要加入“提取名片信息”的功能按钮,也就是进行百度大模型OCR的识别。在识别逻辑中前期需要进行base4编码的转换,这里面还需要在导入模块处加入util工具包的导入。如下图所示。

导入工具包后,这里我们为按钮“提取名片信息”添加onClick事件,事件中调用工具包util的Base64Helper工具进行图片的base64转码。代码如下图所示。

代码在onClick方法中先使用fileIo模块异步打开相册路径this.myurl中的文件,这里打开模式为OpenMode.READ_ONLY只读方式,然后读取的内容需要到缓冲区内,这里就定义一个ArrayBuffer,ArrayBuffer大小指定为配置文件中的常量,这里是4096000,相当于是4M的缓存空间数组,然后通过fileIo模块的readSync异步读取文件到ArrayBuffer的缓存数组中,接下来实例化util模块的Base64Helper工具类,调用encodeToStringSync的方法将读入缓存的图片数据转成base64编码。完成图片的base64转码后就需要调用百度大模型的OCR功能,这里首先获取百度大模型的access_token的token值。
根据文档要求,需要通过http请求htts://api.baidubce.com/oauth/2.0/token?grant_type=client_credentials的地址,这里传入client_id的值,其值就是百度OCR接入应用的api_key,再传入client_secret的值,这个值就是百度OCR接入应用的secrent_key,代码如下图所示。

这里就通过http.createHttp()方法建立http请求,并在请求地址中将百度OCR应用的api_key和secret_key传入,获取百度OCR应用的access_token值。请求成功后打印token代码如下图所示。

这里打印结果为百度Access Token接口返回的JSON数据中result中的access_token值,使用这个值继续请求百度OCR端口,并上传OCR图片的base64编码值。这里再次发送请求使用axios的模块,首先导入模块,代码如下图所示。

继续请求需要使用axios的post方法进行请求。根据百度文档,必须具备的参数如下图所示。

这里还要读取一个axios中post的源码,了解一下post的参数,如下图所示。

在源码中指出,这里post方法第一个参数请求数据的类型,第二个参数是返回数据的类型,第三个是设置。根据百度的上传要求,需要定义一个上传的接口,把base64的image定义成接口,如下图所示。

在使用axios的post方法还需要设置输出类型,这里根据一切皆对象,把输出类型设置为object。如下图所示。

这里调用axios.post方法第一个输入参数为接口MyImage,第二个参数是返回的类型,总体是AxiosResponse,其中的元素类型是object对象,第三个参数这里设置为null。这里把百度接口的参数放在post的方法中,如下图所示。

这里的newurl就是百度OCR识别的地址,params参数中加入image的base64编码图片,headers中指明请求的头文件。其返回结果是Promise,因此可以用then方法来接收返回值。如下图所示。

这里接收内容并转化成JSON数据输出。代码完成后,需要在main_pages中添加该页面组件,这样页面组件就可以进行预览,如下图所示在main_pages中加入页面的代码。

加入页面后点击右上角的“Sync Now”直到显示对号为止。如下图所示。

对于应用,需要模拟器启动后显示该页面进行调试。这里通过修改EntryAbility调整启动页面,如下图所示。

启动模拟器,运行后点击按钮进行数据解析,显示结果如下图所示。

这里解析之后可以通过设置全局变量获取名片中的地址,姓名和电话,代码如下图所示。

在OCR解析名片成功后,分别获取名片中的地址,电话和姓名,代码如下图所示。

这里运行后,点击解析可以看到解析后的名片内容