简介
Apache Kafka是一个高性能、低延迟的分布式流处理平台,广泛用于构建实时数据管道和流式应用。本文将指导你如何在Ubuntu 22.04系统上快速部署Apache Kafka,让你体验到Kafka在处理大规模实时数据流方面的强大能力。通过本教程,你将学会如何安装、配置Kafka及其依赖的Zookeeper服务,并进行基本的测试以确保部署成功。
功能特点简介
Apache Kafka的核心优势在于其高吞吐量和分布式、容错的特性,使其成为处理大规模实时数据流的理想选择。以下是Kafka的一些独特卖点:
- 高吞吐量:Kafka能够处理高吞吐量的数据流,满足大数据时代的需求。
- 低延迟:即使在高负载下,Kafka也能保持低延迟的数据传输。
- 分布式架构:Kafka的分布式架构支持数据的分布式存储和处理,提高了系统的可扩展性和可靠性。
- 容错机制:Kafka内置的复制和分区机制,确保了数据的高可用性和持久性。
接下来,我将一步一步教大家如何进行安装和部署!!
准备工作
服务器准备
必要前提:
- 一个充满求知欲的大脑。
- 一台 Linux 服务器(推荐腾讯云、阿里云或雨云等)。
我将以 雨云 为例,带大家创建一台自己的云服务器,以便学习本篇文章的内容。
注册链接: https://rainyun.ivwv.site
创建雨云服务器
以下步骤仅供参考,请根据实际需求选择配置。
- 点击 云产品 → 云服务器 → 立即购买。
- 选择距离你较近的区域,以保证低延迟。
- 按照自己需求选择配置,选择Ubuntu 22.04 版本,按照自己需求是否预装Docker。
- 最后按照提示进行购买。
- 购买后等待机器部署完毕,点击刚刚创建好的服务器,进入管理面板,找到远程连接相关信息。
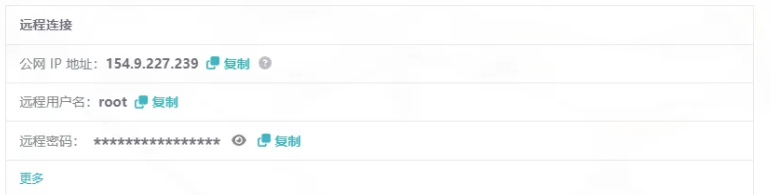
- 我们使用
PowerShell进行SSH远程连接到服务器,Win+R打开运行窗口,输入powershell后点击确定。

- 到此为止,我们的云服务器就远程连接上了。
开始部署
1. 更新系统
首先,更新你的包列表并升级系统包到最新版本。
sudo apt update -y
2. 安装Java
Kafka需要Java环境来运行。安装Ubuntu仓库中最新版本的OpenJDK。
sudo apt install openjdk-21-jdk -y
3. 创建Kafka用户
出于安全考虑,建议为Kafka创建一个专用用户。
sudo useradd -m -s /bin/bash kafka
sudo passwd kafka
切换到Kafka用户:
sudo su - kafka
4. 下载并解压Kafka
从Apache Kafka官方下载页面下载最新稳定版本的Kafka。
wget https://downloads.apache.org/kafka/3.7.0/kafka_2.13-3.7.0.tgz
tar -xzf kafka_2.13-3.7.0.tgz
mv kafka_2.13-3.7.0 kafka
5. 配置Kafka
Kafka需要Zookeeper,它随Kafka一起提供,用于开发和测试目的。在生产环境中,你应该设置一个专用的Zookeeper集群。
配置Zookeeper
创建Zookeeper的数据目录:
mkdir -p ~/kafka/data/zookeeper
编辑Zookeeper配置文件:
nano ~/kafka/config/zookeeper.properties
更新dataDir属性指向新数据目录:
dataDir=/home/kafka/kafka/data/zookeeper
配置Kafka Broker
创建Kafka的数据目录:
mkdir -p ~/kafka/data/kafka
编辑Kafka配置文件:
nano ~/kafka/config/server.properties
更新以下属性:
log.dirs=/home/kafka/kafka/data/kafka
zookeeper.connect=localhost:2181
6. 启动Zookeeper和Kafka
打开两个终端会话:一个用于Zookeeper,另一个用于Kafka。确保你在两个会话中都以Kafka用户身份登录。
启动Zookeeper
~/kafka/bin/zookeeper-server-start.sh ~/kafka/config/zookeeper.properties
启动Kafka
在第二个终端会话中,启动Kafka:
~/kafka/bin/kafka-server-start.sh ~/kafka/config/server.properties
7. 测试安装
创建Topic
在新的终端会话中,以Kafka用户身份登录,创建一个测试Topic:
~/kafka/bin/kafka-topics.sh --create --topic test --bootstrap-server localhost:9092 --partitions 1 --replication-factor 1
列出Topics
验证Topic是否创建:
~/kafka/bin/kafka-topics.sh --list --bootstrap-server localhost:9092
生产消息
启动一个Kafka生产者:
~/kafka/bin/kafka-console-producer.sh --topic test --bootstrap-server localhost:9092
输入几条消息并按Enter键:
Hello Kafka
This is a test message
消费消息
打开另一个终端会话,启动一个Kafka消费者:
~/kafka/bin/kafka-console-consumer.sh --topic test --from-beginning --bootstrap-server localhost:9092
你应该能看到你在生产者终端输入的消息。
8. 设置SELinux为Enforcing(可选)
如果你已启用SELinux,请按照以下步骤操作。为了启动Kafka和Zookeeper服务,我们需要将SELinux设置为Enforcing。否则,我们将面临“Permission Denied”错误。
sudo setenforce 0
9. 将Kafka设置为Systemd服务
为了确保Kafka和Zookeeper在启动时自动启动,你可以将它们设置为systemd服务。
创建Zookeeper的systemd服务文件:
sudo nano /etc/systemd/system/zookeeper.service
添加以下内容:
[Unit]
Description=Apache Zookeeper server
Documentation=http://zookeeper.apache.org
After=network.target
[Service]
Type=simple
User=kafka
ExecStart=/home/kafka/kafka/bin/zookeeper-server-start.sh /home/kafka/kafka/config/zookeeper.properties
ExecStop=/home/kafka/kafka/bin/zookeeper-server-stop.sh
Restart=on-abnormal
[Install]
WantedBy=multi-user.target
创建Kafka的systemd服务文件:
sudo nano /etc/systemd/system/kafka.service
添加以下内容:
[Unit]
Description=Apache Kafka server
Documentation=http://kafka.apache.org/documentation.html
After=network.target zookeeper.service
[Service]
Type=simple
User=kafka
ExecStart=/home/kafka/kafka/bin/kafka-server-start.sh /home/kafka/kafka/config/server.properties
ExecStop=/home/kafka/kafka/bin/kafka-server-stop.sh
Restart=on-abnormal
[Install]
WantedBy=multi-user.target
启动并启用服务:
重新加载systemd以应用新的服务文件:
sudo systemctl daemon-reload
启动并启用Zookeeper:
sudo systemctl start zookeeper
sudo systemctl enable zookeeper
启动并启用Kafka:
sudo systemctl start kafka
sudo systemctl enable kafka
结论
你已经成功地在Ubuntu 22.04上安装了Apache Kafka。你可以创建主题、生产和消费消息,并将Kafka和Zookeeper作为systemd服务进行管理。这个设置为你构建实时数据管道和流式应用提供了一个坚实的基础。
如需进一步配置和调整,请参考官方Kafka文档。
相关链接
雨云 - 新一代云服务提供商: https://rainyun.ivwv.site
我的博客:https://blog.ivwv.site



