分布式跟踪系列
CAT
cat monitor 分布式监控 CAT-是什么?
cat monitor-02-分布式监控 CAT埋点
cat monitor-03-深度剖析开源分布式监控CAT
cat monitor-04-cat 服务端部署实战
cat monitor-05-cat 客户端集成实战
cat monitor-06-cat 消息存储
skywalking
监控-skywalking-01-APM 监控入门介绍
监控-skywalking-02-深入学习 skywalking 的实现原理的一些问题
监控-skywalking-03-深入浅出介绍全链路跟踪
监控-skywalking-04-字节码增强原理
监控-skywalking-05-in action 实战笔记
监控-skywalking-06-SkyWalking on the way 全链路追踪系统的建设与实践
其他
开源分布式系统追踪-00-overview
开源分布式系统追踪-01-Zipkin-01-入门介绍
开源分布式系统追踪 02-pinpoint-01-入门介绍
开源分布式系统追踪-03-CNCF jaeger-01-入门介绍
Zipkin
Zipkin 是一种分布式跟踪系统。它有助于收集解决微服务架构中的延迟问题所需的时序数据。它管理这些数据的收集和查找。
Zipkin的设计基于Google Dapper论文。
应用程序用于向Zipkin报告时序数据。
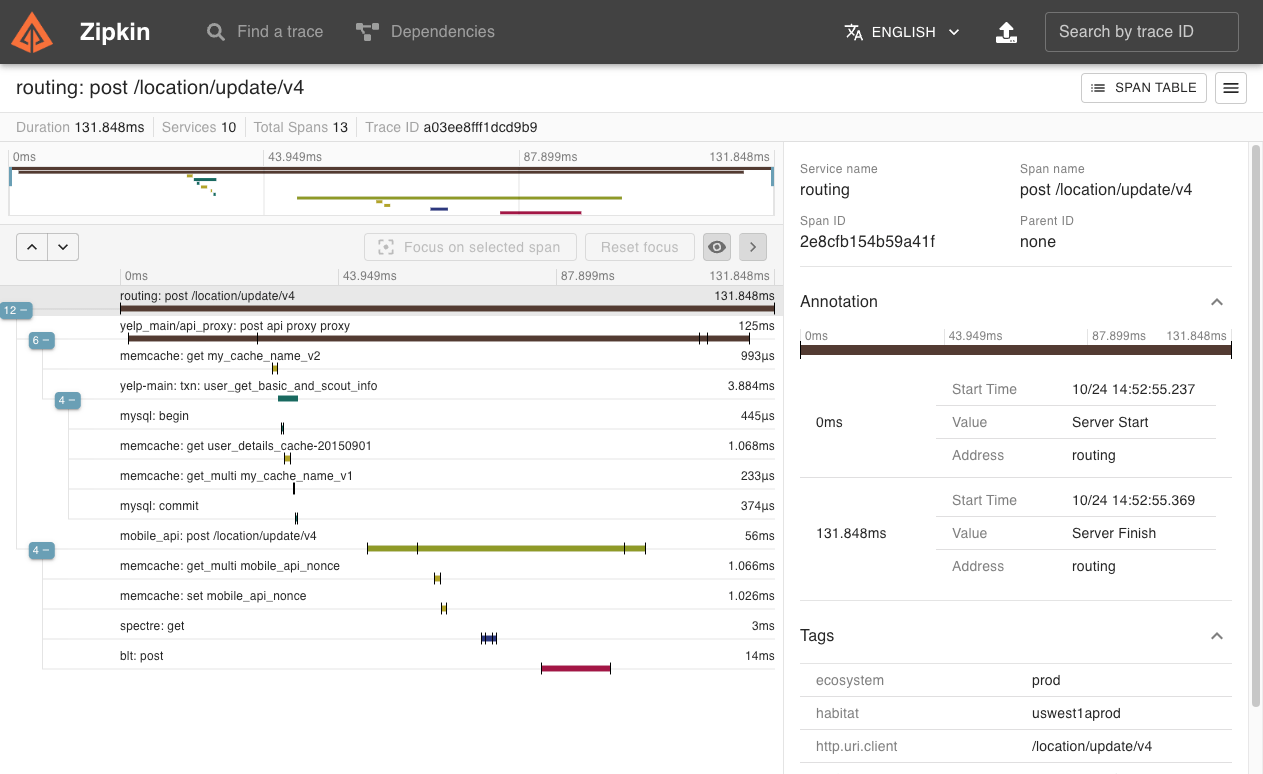
Zipkin UI还提供了一个依赖关系图,显示了每个应用程序通过的跟踪请求数。如果要解决延迟问题或错误,可以根据应用程序,跟踪长度,注释或时间戳对所有跟踪进行筛选或排序。选择跟踪后,您可以看到每个跨度所需的总跟踪时间百分比,从而可以识别问题应用程序。
快速开始
在本节中,我们将逐步构建并启动Zipkin实例,以便在本地检查Zipkin。
有三个选项:使用Java,Docker或从源代码运行。
如果您熟悉Docker,这是首选的方法。如果您不熟悉Docker,请尝试通过Java或源代码运行。
无论您如何启动Zipkin,请浏览 http://your_host:9411 以查找跟踪!
Docker
Docker Zipkin项目能够构建docker镜像,提供脚本和docker-compose.yml,用于启动预构建的图像。
- 拉取镜像
docker pull openzipkin/zipkin最快的开始是直接运行最新的图像:
docker run -d -p 9411:9411 openzipkin/zipkinjava">java
jdk8+ 以上安装,直接运行:
curl -sSL https://zipkin.io/quickstart.sh | bash -s
java -jar zipkin.jar使用源码编译运行
# get the latest source
git clone https://github.com/openzipkin/zipkin
cd zipkin
# Build the server and also make its dependencies
./mvnw -DskipTests --also-make -pl zipkin-server clean install
# Run the server
java -jar ./zipkin-server/target/zipkin-server-*exec.jarArchitecture
概览
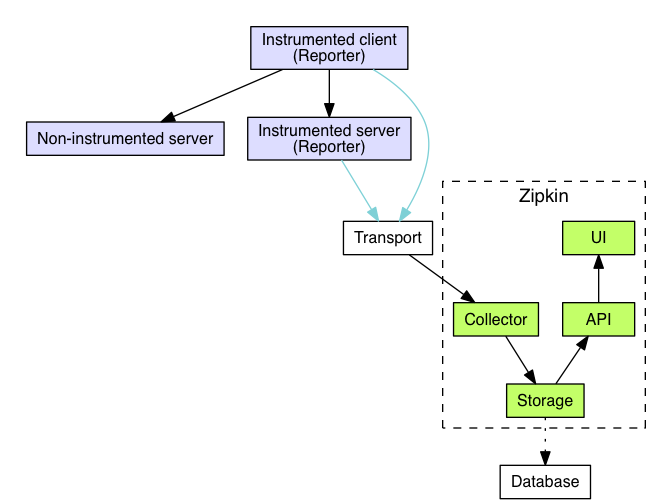
跟踪器存在于您的应用程序中,并记录有关发生的操作的时间和元数据。他们经常使用库,因此它们的使用对用户是透明的。
例如,检测的Web服务器记录何时收到请求以及何时发送响应。收集的跟踪数据称为Span。
编写仪器是为了安全生产并且开销很小。出于这个原因,它们只在带内传播ID,告诉接收器正在进行跟踪。 Zipkin带外报告已完成的跨度,类似于应用程序异步报告度量标准的方式。
例如,在跟踪操作并且需要发出传出的http请求时,会添加一些标头来传播ID。标头不用于发送操作名称等详细信息。
将数据发送到Zipkin的检测应用程序中的组件称为Reporter。记者通过几种传输之一将跟踪数据发送到Zipkin收集器,这些收集器将跟踪数据保存到存储中。稍后,API会查询存储以向UI提供数据。
这是描述此流程的图表:
要查看您的平台是否已存在检测库,请参阅现有仪器列表。
Example Flow
如概述中所述,标识符是带内发送的,详细信息是带外发送给Zipkin的。
在这两种情况下,跟踪检测都负责创建有效的跟踪并正确呈现它们。
例如,跟踪器确保它在带内(下游)和带外(与Zipkin异步)发送的数据之间的奇偶校验。
这是一个示例序列的http跟踪,其中用户代码调用资源/ foo。
这导致单个跨度,在用户代码收到http响应后异步发送到Zipkin。
┌─────────────┐ ┌───────────────────────┐ ┌─────────────┐ ┌──────────────────┐
│ User Code │ │ Trace Instrumentation │ │ Http Client │ │ Zipkin Collector │
└─────────────┘ └───────────────────────┘ └─────────────┘ └──────────────────┘│ │ │ │┌─────────┐│ ──┤GET /foo ├─▶ │ ────┐ │ │└─────────┘ │ record tags│ │ ◀───┘ │ │────┐│ │ │ add trace headers │ │◀───┘│ │ ────┐ │ ││ record timestamp│ │ ◀───┘ │ │┌─────────────────┐│ │ ──┤GET /foo ├─▶ │ ││X-B3-TraceId: aa │ ────┐│ │ │X-B3-SpanId: 6b │ │ │ │└─────────────────┘ │ invoke│ │ │ │ request │││ │ │ │ │┌────────┐ ◀───┘│ │ ◀─────┤200 OK ├─────── │ │────┐ └────────┘│ │ │ record duration │ │┌────────┐ ◀───┘│ ◀──┤200 OK ├── │ │ │└────────┘ ┌────────────────────────────────┐│ │ ──┤ asynchronously report span ├────▶ ││ ││{ ││ "traceId": "aa", ││ "id": "6b", ││ "name": "get", ││ "timestamp": 1483945573944000,││ "duration": 386000, ││ "annotations": [ ││--snip-- │└────────────────────────────────┘运输
必须将从仪表化库中发送的跨度从被跟踪的服务传输到Zipkin收集器。有三种主要传输方式:HTTP,Kafka和Scribe。
组件
Zipkin有4个组件:
集电极
存储
搜索
网页用户界面
Zipkin收藏家
一旦跟踪数据到达Zipkin收集器守护程序,它就会被Zipkin收集器验证,存储和索引以供查找。
存储 Zipkin最初是为了在Cassandra上存储数据而构建的,因为Cassandra是可扩展的,具有灵活的模式,并且在Twitter中大量使用。但是,我们使这个组件可插拔。除了Cassandra,我们原生支持ElasticSearch和MySQL。其他后端可能会作为第三方扩展提供。
Zipkin查询服务 一旦数据被存储和索引,我们需要一种方法来提取它。查询守护程序提供了一个简单的JSON API,用于查找和检索跟踪。此API的主要使用者是Web UI。
Web UI 我们创建了一个GUI,它为查看跟踪提供了一个很好的界面。 Web UI提供了一种基于服务,时间和注释查看跟踪的方法。注意:UI中没有内置身份验证!
Data Model
请注意,此页面已过期。请查看Zipkin Api文档,该文档详细说明了模型中的字段,直到此页面更新为止。
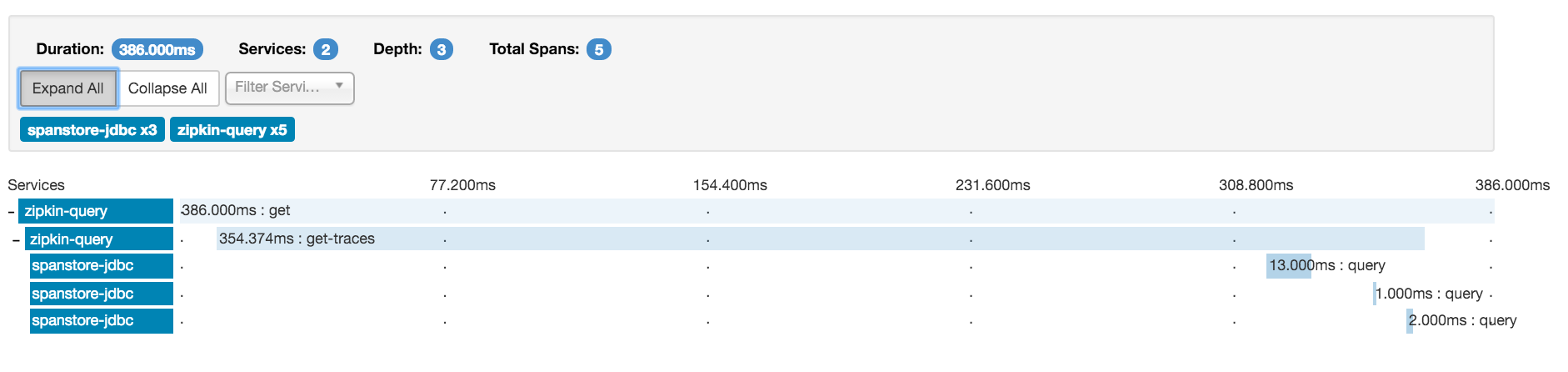
为了说明Zipkin显示的跟踪数据,让我们将它与Zipkin数据模型中的等效信息联系起来。
通过比较这些,我们看到了
入站和出站请求的跨度不同
包含cs的跨度可以记录它们的去向
当目标协议不是Zipkin检测时,例如MySQL,这会有所帮助。 首先,我们看到Zipkin跟踪查看器中显示的一条跟踪:
检测库
这是一个高级主题。在进一步阅读之前,您可能需要检查平台的检测库是否已存在。
如果没有,如果你想创建一个仪器库,首先要做的事情;跳过Zipkin Gitter聊天频道,告诉我们。我们非常乐意为您提供帮助。
instrumenting
参考资料
Zipkin