该系列是上海AI Lab举行的书生 浦语大模型训练营的相关笔记部分。
该笔记是第六节课,学习大语言模型智能体的基本概念,以及Lagent的使用。
0. 智能体
在大型语言模型(LLM)的上下文中,智能体(agent)通常指的是一个能够与用户或其他智能体交互并执行任务的程序或系统。智能体可以是简单的聊天机器人,也可以是复杂的自动化系统,它们能够理解自然语言输入,并据此做出决策或采取行动。
智能体在LLM中的应用通常包括:
- 对话系统:智能体通过与用户的对话来提供信息、解答问题或执行特定的任务,如客户服务聊天机器人。
- 虚拟助手:智能体作为个人助理,帮助用户管理日程、设置提醒、搜索信息等。
- 推荐系统:智能体根据用户的偏好和历史行为提供个性化推荐,如电影、音乐或商品推荐。
- 自动化工具:智能体在特定领域内执行自动化任务,如数据分析、报告生成或软件测试。
- 决策支持系统:智能体分析大量数据,提供见解和建议,帮助人类做出更明智的决策。
在构建智能体时,LLM可以作为核心组件,提供对自然语言的理解和处理能力。智能体通常还包括其他模块,如决策逻辑、记忆系统、学习算法和执行机制,以实现特定的功能和应用。智能体的设计和开发是一个跨学科领域,涉及自然语言处理、机器学习、软件工程和用户体验设计等多个方面。
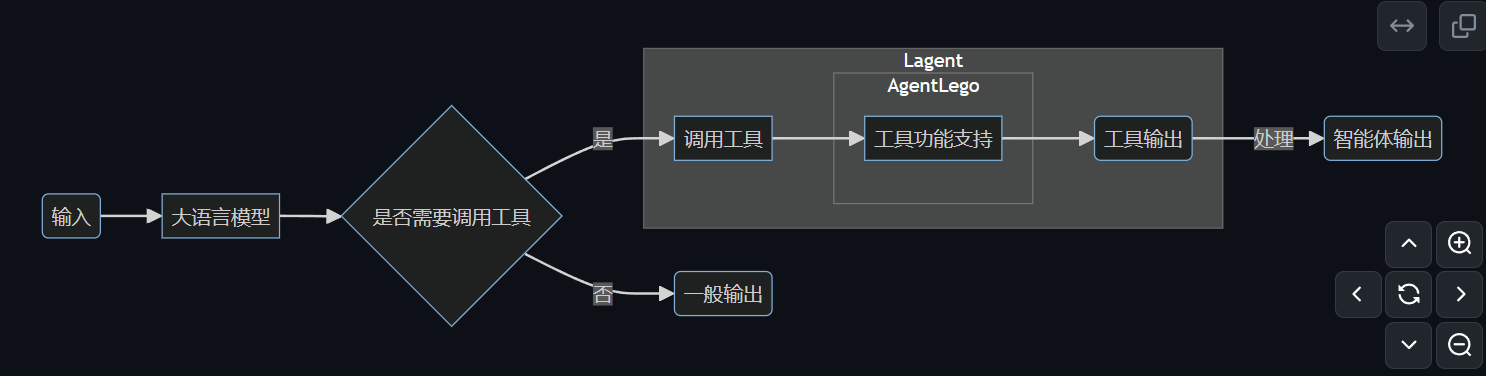
本节课要学习的Lagent是一个轻量化的搭建智能体的工具,其支持arxiv检索、ppt、python解释器等各种工具。而AgentLego 是一个提供了多种开源工具 API 的多模态工具包,旨在像是乐高积木一样,让用户可以快速简便地拓展自定义工具,从而组装出自己的智能体。二者的关系如下图:可以看出,AgentLego负责具体的功能支持,而Lagent是将工具支持与调用工具、输出封装在了一起。
1. 实战:Lagent Web Demo(基础作业)
首先创建开发机,GPU选择30% * A100, 镜像选择CUDA12.2
然后我们先创建本课程的目录,并安装环境:
mkdir -p /root/agentstudio-conda -t agent -o pytorch-2.1.2conda activate agent
然后,我们需要安装Lagent和AgentLego的代码并安装lmdeploy以方便后续的server部署:
cd /root/agentgit clone https://gitee.com/internlm/lagent.git
cd lagent && git checkout 581d9fb && pip install -e . && cd ..
git clone https://gitee.com/internlm/agentlego.git
cd agentlego && git checkout 7769e0d && pip install -e . && cd ..pip install lmdeploy==0.3.0
此外,我们需要把tutorial clone下来,因为要用到里面的代码:
git clone -b camp2 https://gitee.com/internlm/Tutorial.git
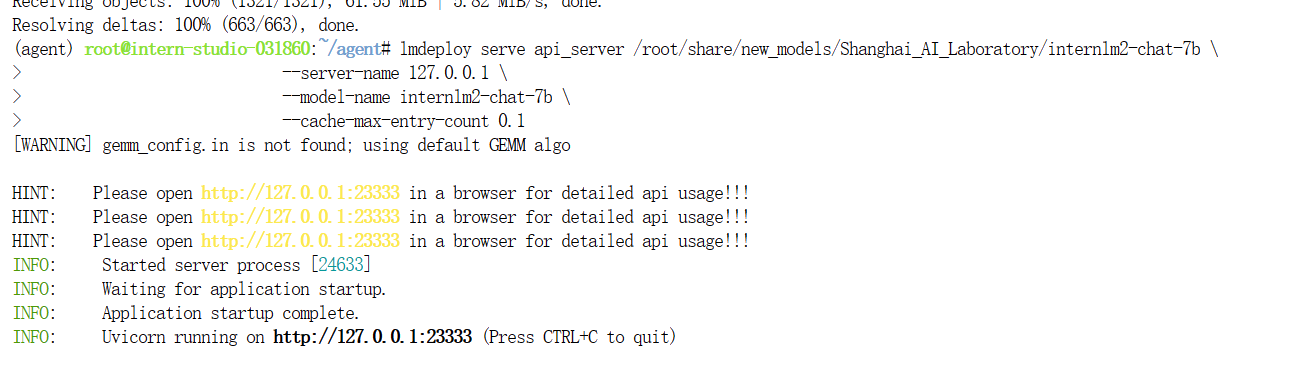
在上一节课,我们已经学习了LMDeploy的一些用法,在此我们需要开启API接口的api server:
conda activate agent
lmdeploy serve api_server /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-7b \--server-name 127.0.0.1 \--model-name internlm2-chat-7b \--cache-max-entry-count 0.1
新建Terminal,启动Lagent Web Demo:
conda activate agent
cd /root/agent/lagent/examples
streamlit run internlm2_agent_web_demo.py --server.address 127.0.0.1 --server.port 7860
当这两个都准备好后(以下界面),然后打开Windows powershell,ssh连接:

ssh -CNg -L 7860:127.0.0.1:7860 -L 23333:127.0.0.1:23333 root@ssh.intern-ai.org.cn -p 45459
随后访问http://localhost:7860/, 然后将模型IP选择为127.0.0.1:23333以便和lmdeploy开启的apiserver联动,然后插件选择ArxivSearch:
输入问题请帮我搜索 InternLM2 Technical Report, 结果如下:
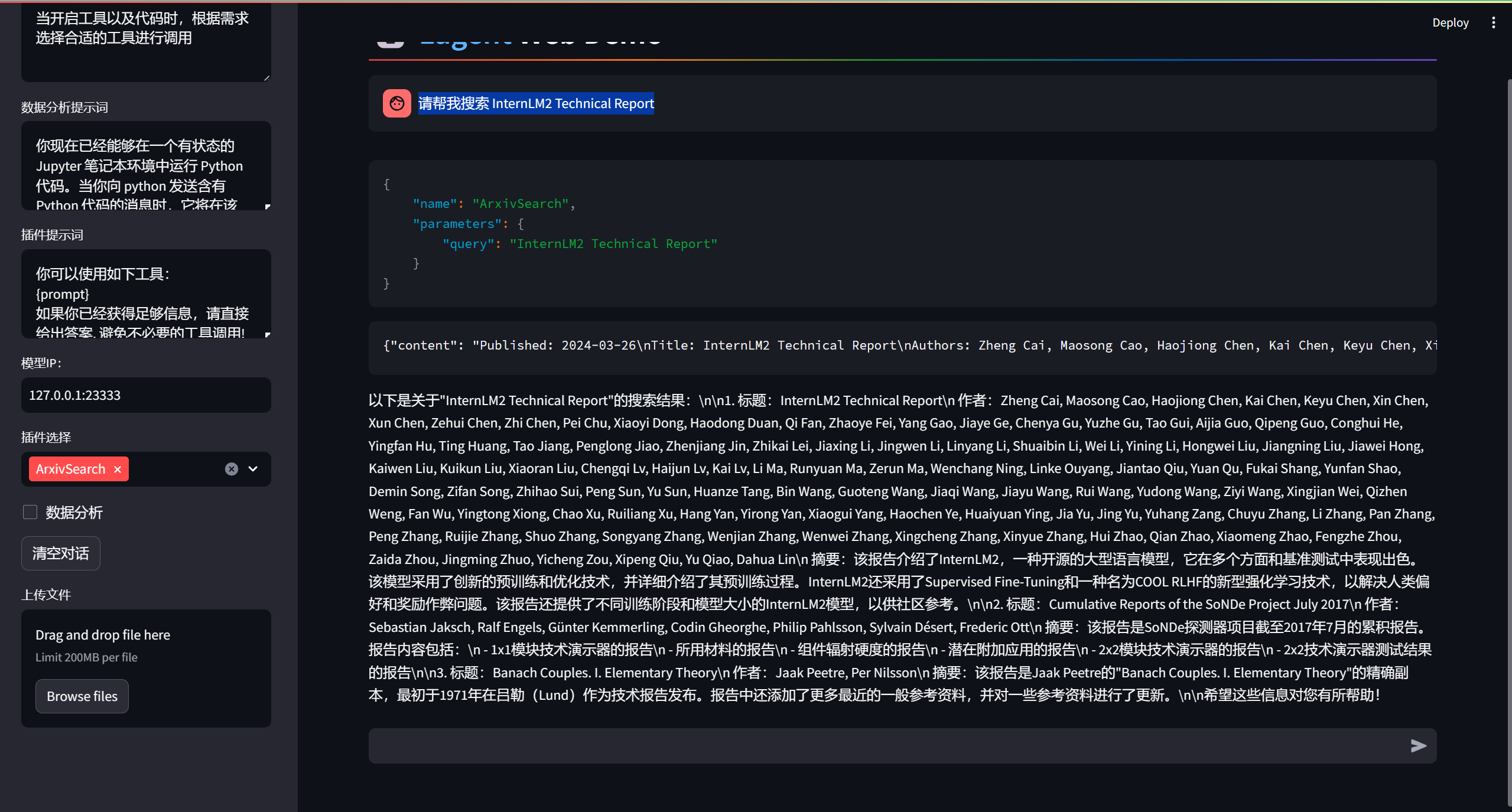
可以看到搜索结果是正确的。
2. 实战:AgentLego Demo(基础作业)
首先下载demo文件:
cd /root/agent
wget http://download.openmmlab.com/agentlego/road.jpg在本例子中,我们采用目标检测工具,具体是MMDetection。我们进行安装:
conda activate agent
pip install openmim==0.3.9
mim install mmdet==3.3.0
然后编写代码:
vim /root/agent/direct_use.py
插入以下代码:
import reimport cv2
from agentlego.apis import load_tool# load tool
tool = load_tool('ObjectDetection', device='cuda') # 加载目标检测工具# apply tool
visualization = tool('/root/agent/road.jpg') # 推理
print(visualization)# visualize
image = cv2.imread('/root/agent/road.jpg')preds = visualization.split('\n')
pattern = r'(\w+) \((\d+), (\d+), (\d+), (\d+)\), score (\d+)'for pred in preds: # 绘制边界框name, x1, y1, x2, y2, score = re.match(pattern, pred).groups()x1, y1, x2, y2, score = int(x1), int(y1), int(x2), int(y2), int(score)cv2.rectangle(image, (x1, y1), (x2, y2), (0, 255, 0), 1)cv2.putText(image, f'{name} {score}', (x1, y1), cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 255, 0), 1)cv2.imwrite('/root/agent/road_detection_direct.jpg', image)
运行:
python /root/agent/direct_use.py
推理结果:


可以看到检测效果还是不错的。
3. AgentLego WebUI (进阶作业)
上面我们只是尝试了单独运行AgentLego中的目标检测工具的结果,那么如何将其和LLM结合起来呢?
首先,我们需要配置一下/root/agent/agentlego/webui/modules/agents/lagent_agent.py文件,将LLM改成7B(原本代码中是20B):
vim /root/agent/agentlego/webui/modules/agents/lagent_agent.py
改为:

之后,跟第一项作业一样,我们需要启动LMDeploy的api server:
lmdeploy serve api_server /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-7b \--server-name 127.0.0.1 \--model-name internlm2-chat-7b \--cache-max-entry-count 0.1
然后,新建terminal,启动 AgentLego WebUI:
conda activate agent
cd /root/agent/agentlego/webui
python one_click.py
等待两个完全启动后,在本地的PowerShell运行:
ssh -CNg -L 7860:127.0.0.1:7860 -L 23333:127.0.0.1:23333 root@ssh.intern-ai.org.cn -p 45459
然后打开 http://localhost:7860
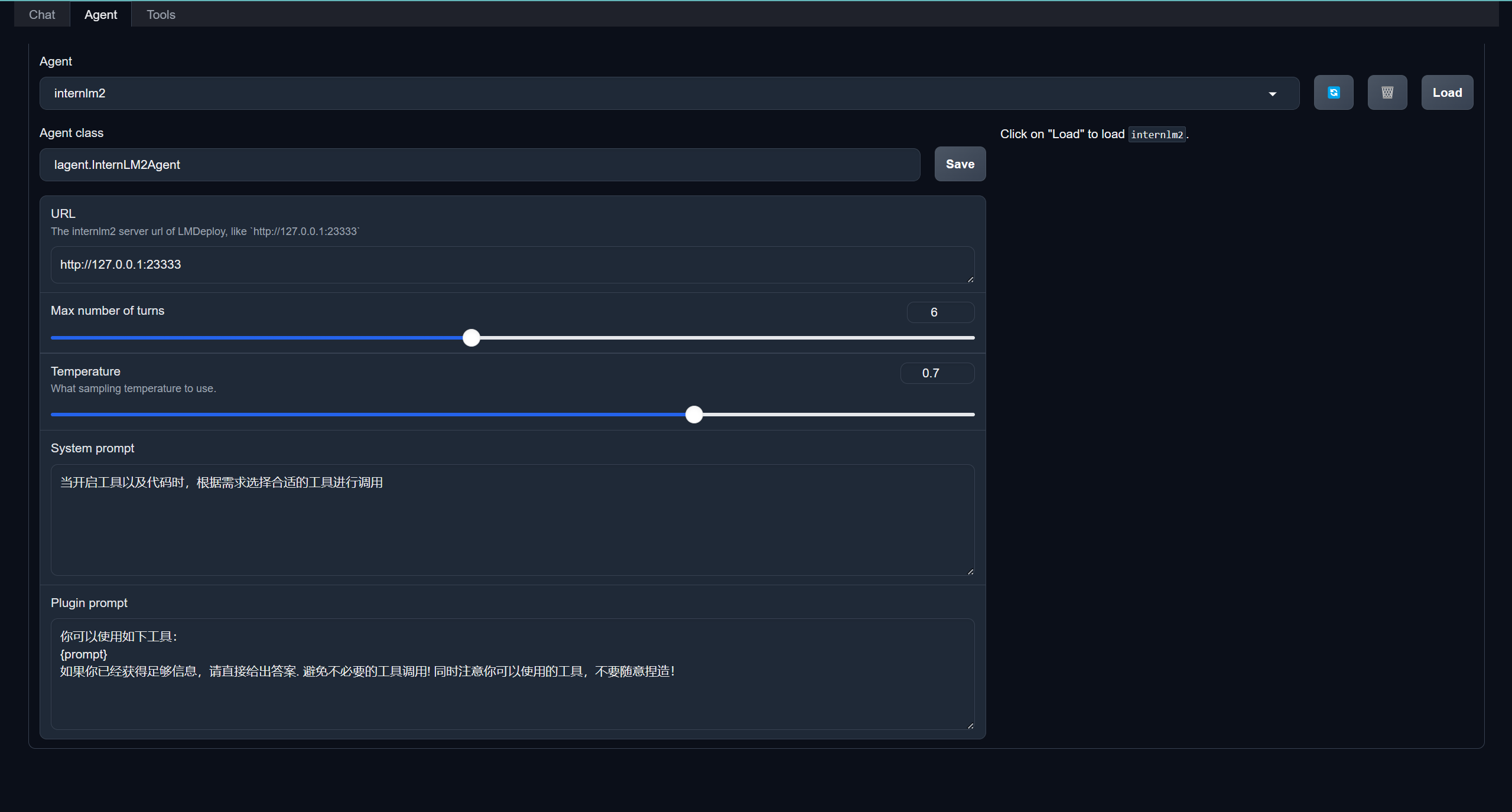
按如图所示配置,和LMDeploy联动:
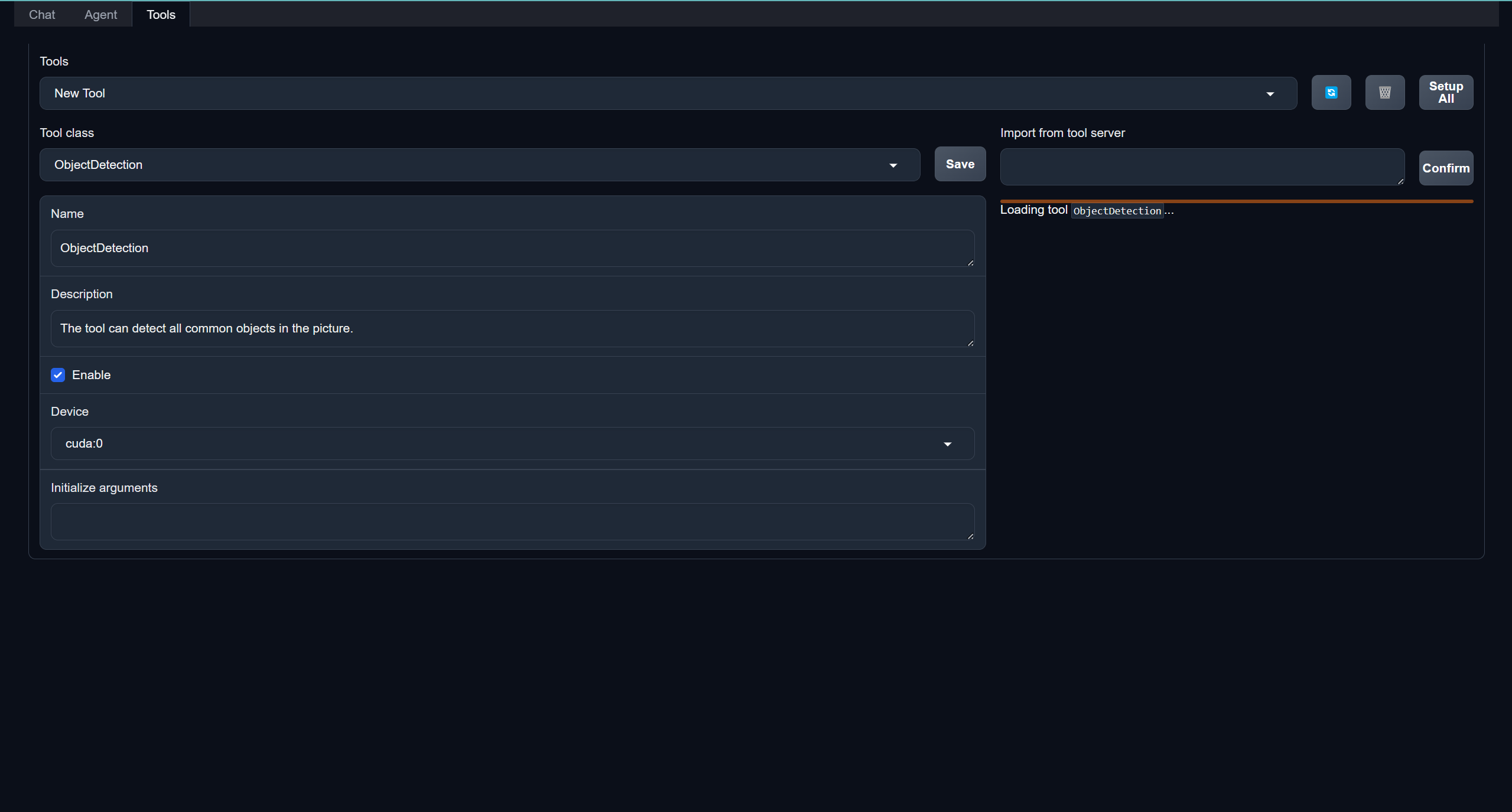
然后在tools页面指定Object Detection工具:
回到chat,底部的工具选择Object Detection,然后上传一张图片,提示它检测图中的目标,效果如下:
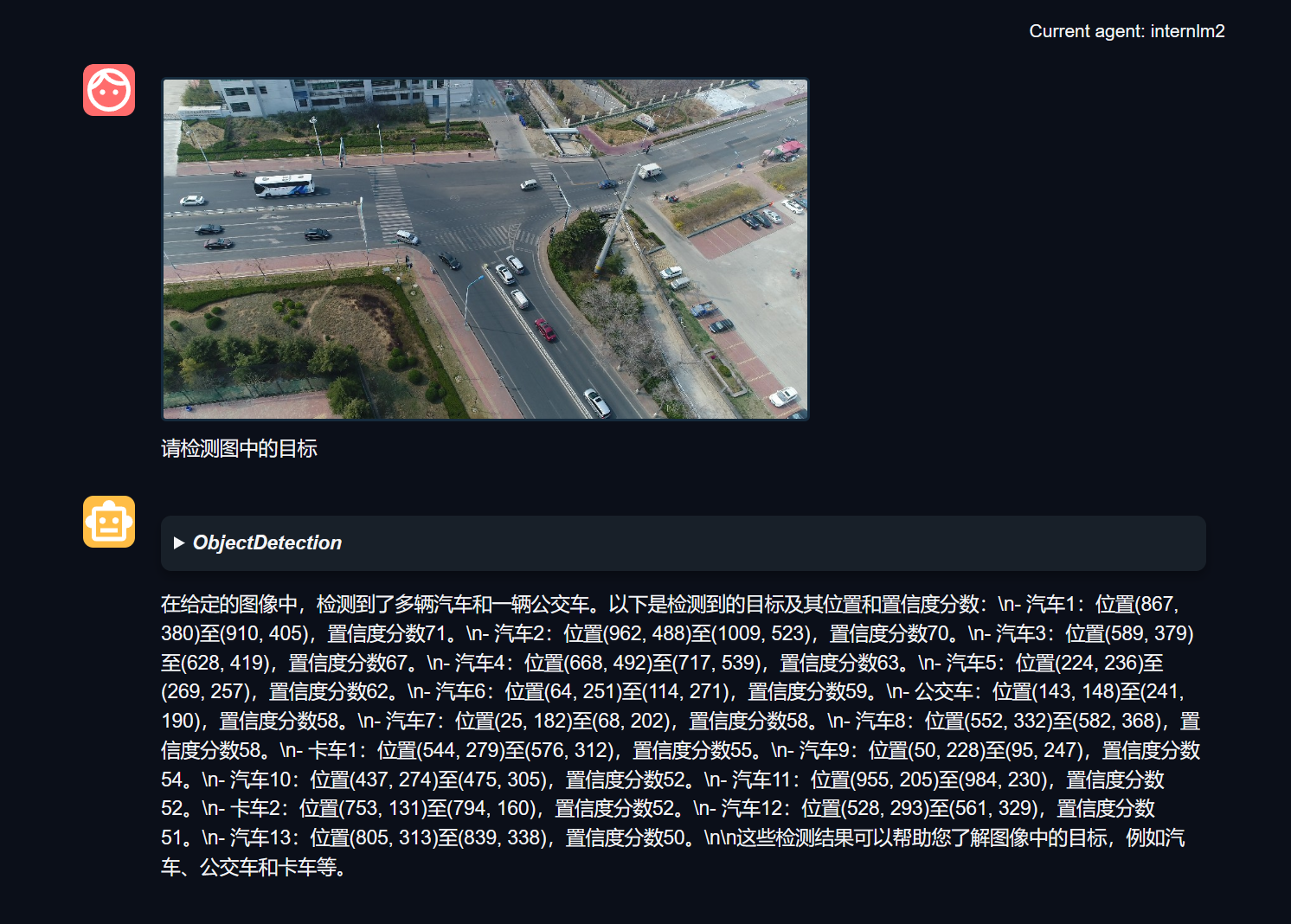
还是非常不错的~。
4. AgentLego 实现自定义工具(进阶作业)
AgentLego的文档地址:https://agentlego.readthedocs.io/zh-cn/latest/modules/tool.html.
要实现自定义工具主要有以下几个步骤(第三步是可选的):
- 继承 BaseTool 类
- 修改 default_desc 属性(工具功能描述)
- 如有需要,重载 setup 方法(重型模块延迟加载)
- 重载 apply 方法(工具功能实现)
下面我们实现一个调用 MagicMaker 的 API 以实现图像生成的工具。
新建我们的工具代码:
vim /root/agent/agentlego/agentlego/tools/magicmaker_image_generation.py
插入:
import json
import requestsimport numpy as npfrom agentlego.types import Annotated, ImageIO, Info
from agentlego.utils import require
from .base import BaseToolclass MagicMakerImageGeneration(BaseTool): # 第一步 继承BaseTool类default_desc = ('This tool can call the api of magicmaker to ''generate an image according to the given keywords.') # 第二部 修改属性styles_option = ['dongman', # 动漫'guofeng', # 国风'xieshi', # 写实'youhua', # 油画'manghe', # 盲盒]aspect_ratio_options = ['16:9', '4:3', '3:2', '1:1','2:3', '3:4', '9:16']@require('opencv-python')def __init__(self,style='guofeng',aspect_ratio='4:3'):super().__init__()if style in self.styles_option:self.style = styleelse:raise ValueError(f'The style must be one of {self.styles_option}')if aspect_ratio in self.aspect_ratio_options:self.aspect_ratio = aspect_ratioelse:raise ValueError(f'The aspect ratio must be one of {aspect_ratio}')def apply(self,keywords: Annotated[str,Info('A series of Chinese keywords separated by comma.')]) -> ImageIO: # 第四步 重载apply方法import cv2# 调用OpenXLab中的MagicMaker生成图片response = requests.post(url='https://magicmaker.openxlab.org.cn/gw/edit-anything/api/v1/bff/sd/generate',data=json.dumps({"official": True,"prompt": keywords,"style": self.style,"poseT": False,"aspectRatio": self.aspect_ratio}),headers={'content-type': 'application/json'})image_url = response.json()['data']['imgUrl']image_response = requests.get(image_url)image = cv2.cvtColor(cv2.imdecode(np.frombuffer(image_response.content, np.uint8), cv2.IMREAD_COLOR),cv2.COLOR_BGR2RGB)return ImageIO(image)
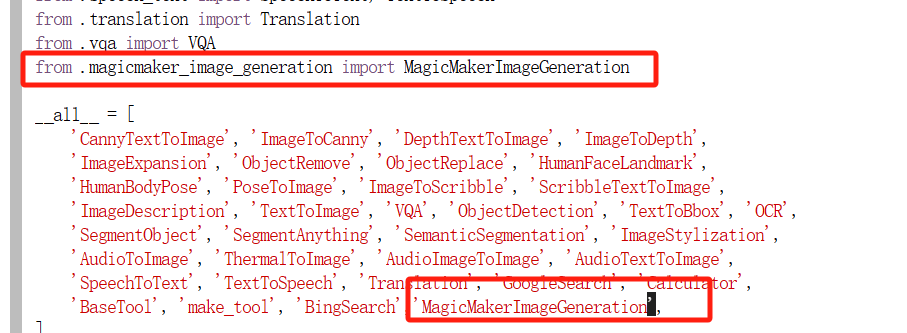
下一步,和MMDetection中我们自定义model一样,需要把自定义的模块注册一下。
在/root/agent/agentlego/agentlego/tools/__init__.py中,添加刚刚定义的MagicMakerImageGeneration类:
跟上面一样,我们在两个terminal中分别启动LMDeploy的api server和AgentLego的Web Demo:
lmdeploy serve api_server /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-7b \--server-name 127.0.0.1 \--model-name internlm2-chat-7b \--cache-max-entry-count 0.1cd /root/agent/agentlego/webui
python one_click.py
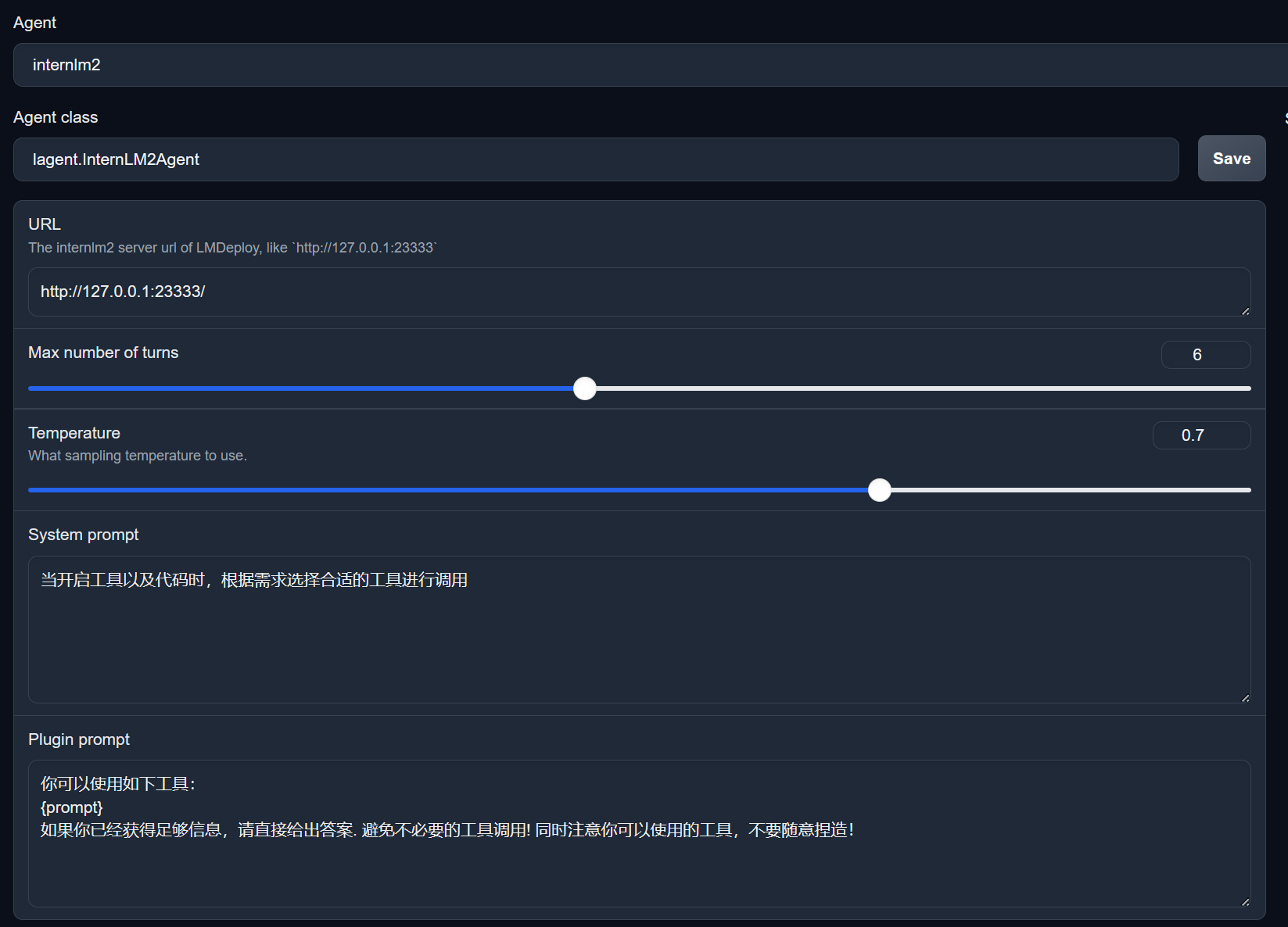
本地的PowerShell:
ssh -CNg -L 7860:127.0.0.1:7860 -L 23333:127.0.0.1:23333 root@ssh.intern-ai.org.cn -p 45459
然后如图配置:

输入prompt:请生成一幅印象派风格的画,效果如下:
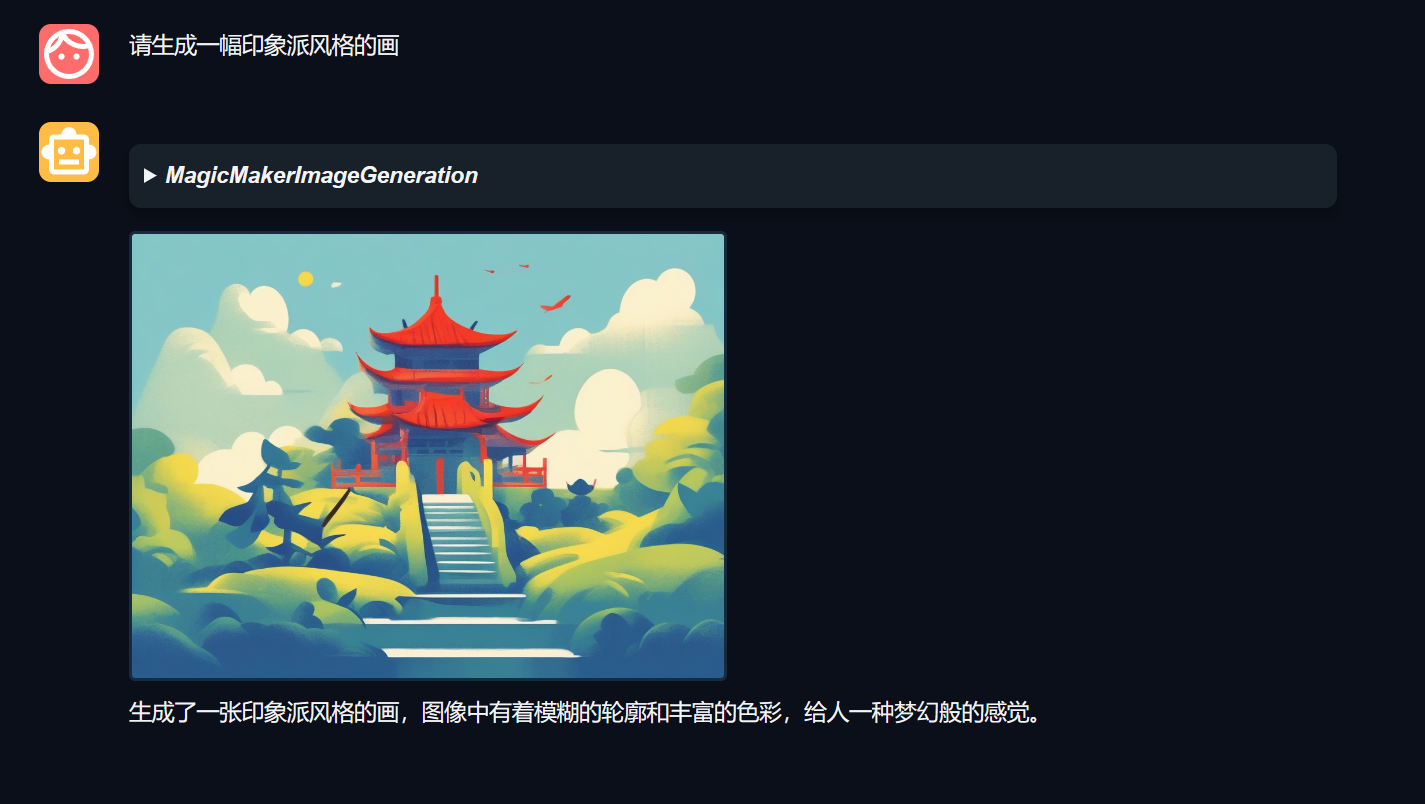
呃,效果还可以~



![Redis集合[持续更新]](https://img-blog.csdnimg.cn/img_convert/3e662e81235cf3e798d531d15fe67c77.png)