Diffusion_Models_with_Transformers%09CVPR2023_0">Scalable Diffusion Models with Transformers CVPR2023
Abstract
idea
将UNet架构用Transformer代替。并且分析其可扩展性。
并且实验证明通过增加transformer的宽度和深度,有效降低FID
我们最大的DiT-XL/2模型在classconditional ImageNet 512、512和256、256基准上的性能优于所有先前的扩散模型,在后者上实现了2.27的最先进FID。
Related Work
本文的相关工作,作者分别介绍了一下Transformer和Unet结构
Transformer
UNet架构
在评估图像生成文献中的架构复杂性时,通常的做法是使用参数计数。一般来说,参数计数不能很好地代表图像模型的复杂性,因为它们不能考虑图像分辨率等对性能有显著影响的因素。
相反,本文中的大部分分析都是通过计算的视角进行的。
这使我们与架构设计文献保持一致,在这些文献中,失败被广泛用于衡量复杂性。在实践中,黄金度量标准将取决于特定的应用程序场景。改进扩散模型的开创性工作与us-there最为相关,他们分析了U-Net架构类的可扩展性属性。在本文中,我们主要关注变压器类。
Diffusion_Transformers_36">Diffusion Transformers
Diffusion formulation
前向扩散过程是将x0逐步加噪
q(xt|x0)是已知的
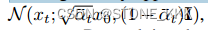
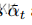
是一个超参数
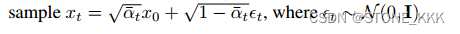
根据t,x0求xt的过程也叫做采样
关于后验p也就是神经网络需要进行预测的内容
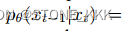
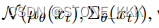
逆向过程是用x0的对数似然的变分下界来训练。
该模型可以使用预测的噪声(xt)与实际抽样的高斯噪声(Lsimple)之间的简单均方误差进行训练
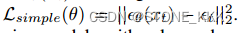
Classifier-free guidance
条件扩散模型将额外的信息作为输入,例如类标签c
此条件下,反向网络需要学习p(xt-1|xt,xc)
LDM
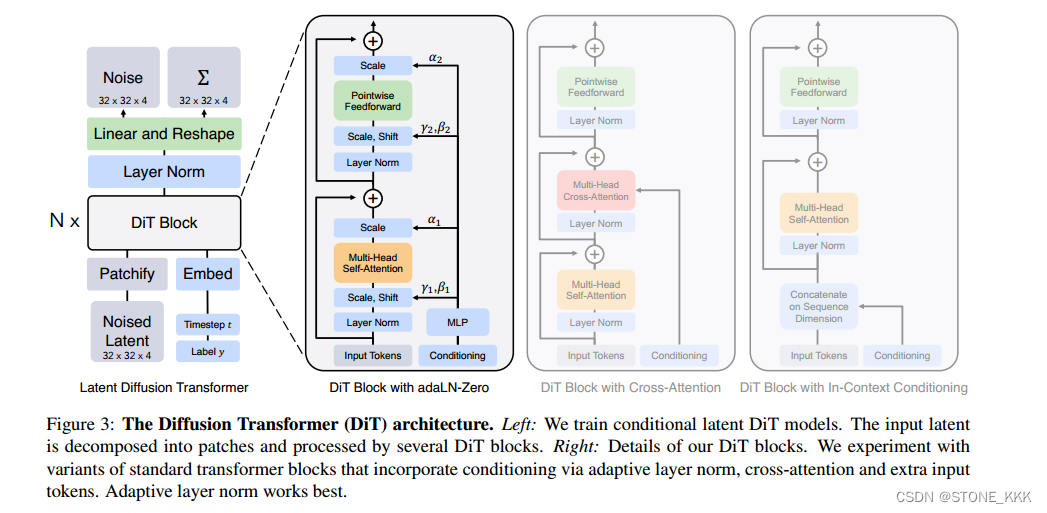
Diffusion_Transformer_Design_Space_86">3.2Diffusion Transformer Design Space
他的目的是将transformer用在潜空间中;
DiT也是在Vit基础上进行的
接下来就是描述Dit的forward部分
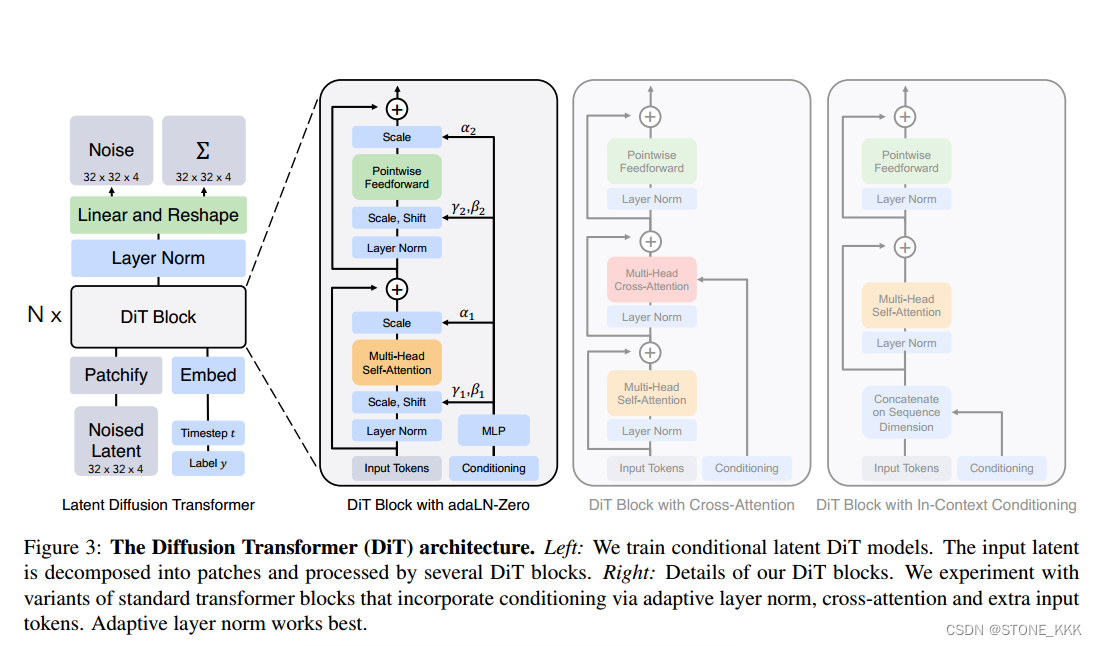
总体来说作者的模型是一种混合模型
使用现成的卷积VAE和基于Transformer的DDPMS

也可以说,DiT仅在DDPM方面做优化
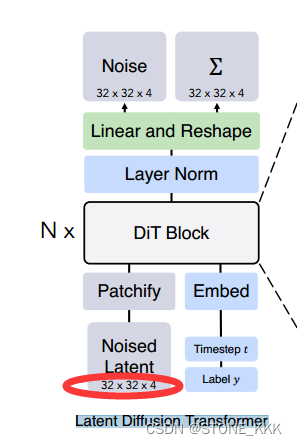
VAE的编码器对img进行压缩后 --> Z–>Noised Latent
关于Dit的输入规范
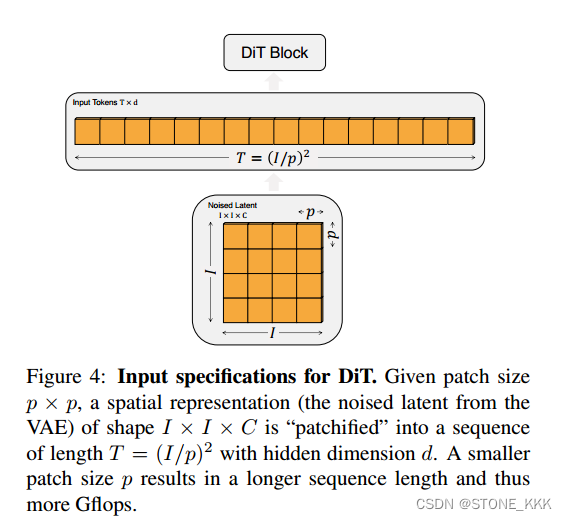
**输入前的Z是32,32,4 I,I,C表示
patch size p,p
最终得到的序列长度为I/p * I/p ,dim dim是自己初始化随机设置即可
Patchify
img大小256,256,3
Z大小32,32,4
它将空间输入转换成T个符号的序列,每个符号都是d维的,
位置编码使用正余弦版本
关于位置编码,RetNet使用旋转空间编码能否优化?
关于patch大小设置
T为序列token长度**

p减半,T大四倍
对model计算效率影响巨大,改变p对下游参数计数没有任何显著影响
P设计遵从2,4,8
Gflops一种计算资源的表述

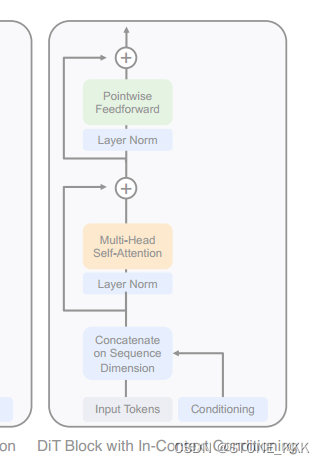

使用标记t和c两个额外的输入到seq,最为vit的cls,

可以理解为cls为2 length-two
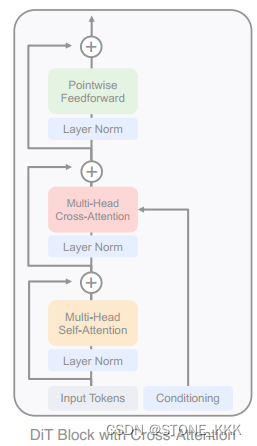

交叉注意力机制多15的Gflops
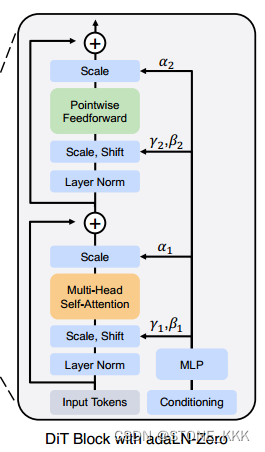

adaLN可以取代Transformer中的层归一化层
随着自适应归一化层在gan和UNet骨干扩散模型中的广泛使用,我们探索用自适应层范数(adaLN)取代变压器块中的标准层范数层。我们不是直接学习维度尺度和移位参数$和%,而是从t和c的嵌入向量的总和中回归它们。在我们探索的三个块设计中,adaLN添加的Gflops最少,因此计算效率最高。
它也是唯一一种限制于将相同函数应用于所有令牌的条件调节机制。
adaLN-Zero block
ResNets 验证:将每个残差块初始化恒等函数是有益的
例如,Goyal等人发现,在监督学习设置下,对每个块中的最终批范数尺度因子$进行零初始化可以加速大规模训练[13]。
其他改进,将γ,β用于回归缩放参数
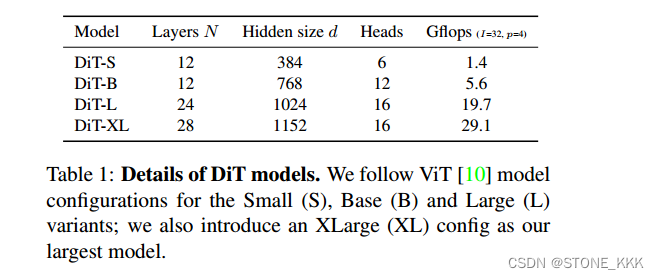
模型的尺寸。我们采用一系列N个DiT块,每个块在隐藏维度大小d处运行。在ViT之后,我们使用标准变压器配置,共同缩放N, d和注意头[10,63]。具体来说,我们使用四种配置:DiT-S、DiT-B、DiT-L和DiT-XL。它们涵盖了广泛的模型大小和触发器分配,从0.3到118.6 Gflops,允许我们衡量缩放性能。