htmlHtmlRAG_1">html检索的提升:HtmlRAG
之前在现实的工作场景中也做过很多次RAG,不过那会我的做法大多数是对数据进行结构化,例如做成json或者yaml文件存放进数据库里面。比如我现在有一个Word文档需要处理,那我就会按照一级标题,二级标题,正文这些类别来归类,具体流程可以参照下图:
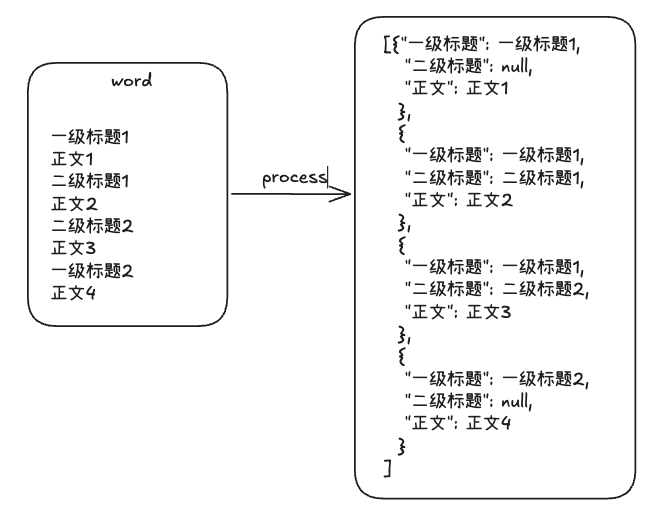
如果遇上文本较长的段落,我会写一个函数来分割整个文本,先将其分成句子级别,然后再将句子重新拼接,超过指定长度就重新拼接一个新的句子,最后再将分割组合完成之后的段落和各级标题再做对应。这种方式就是平时比较常见的文本分块。我这种方式有一种缺点,就是有丢失上下文信息的隐患,不过保持住了结构上的信息。
而今天要讲的这个是关于如何在RAG系统中使用HTML格式的知识,而不是传统的纯文本格式。作者认为HTML格式能够更好地保留结构和语义信息,从而提高生成的质量。这也验证了我之前一直提到过的,结构化数据很重要!这篇论文其实就是在讲怎么清洗html。
论文链接:https://arxiv.org/pdf/2411.02959
论文的核心思想
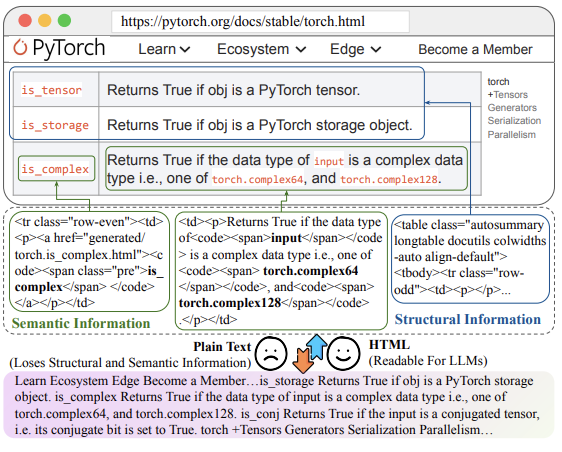
传统的RAG系统通过结合检索和生成模型,能够显著提高LLM的生成能力和答案质量。但是上下文长度限制和噪音过滤是限制RAG系统的两个问题。这篇论文提出的HtmlRAG方法通过使用HTML格式的知识,目的是保留更多的结构和语义信息,进一步提高RAG系统的性能。
-
\1. HTML vs 纯文本:
-
\2. HTML的挑战:
-
- • 作者也提到,HTML文档通常包含大量的标签、JavaScript和CSS,这些内容会增加输入的token数量,并且带来噪音。为了解决这个问题,作者提出了HTML清洗、压缩和修剪策略,以减少HTML的长度,同时尽量保留有用的信息。
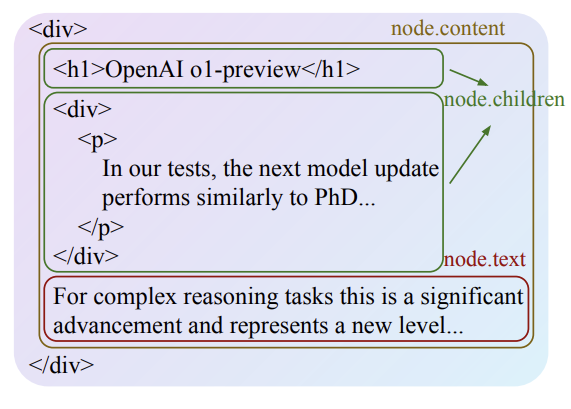
具体方法就是下面这般:
-
\1. HTML清洗:
• 去除CSS、JavaScript和注释。例如清除掉下面这些东西:
<style>body { font-family: Arial, sans-serif; }
</style>
<script>function example() { alert('Hello!'); }
</script>
<!-- 注释 -->
-
• 清理冗长的HTML标签属性。例如,将以下内容:
<div class="example" id="main" style="color: red;"> -
简化为:
<div class="example" id="main"> -
• 合并多层嵌套的标签,去除空标签。
-
\2. 块树构建:

-
• 将HTML文档通过Beautiful Soup解析成DOM树,然后构建一个块树,这些树包含了许多结构信息。块树的粒度可以调整,以适应不同的修剪需求。
-
• 块树中的每个块是一个可以修剪的单位,块的大小由最大词数(maxWords)控制。
-
假设我们有以下HTML文档:
<!DOCTYPE html>
<html>
<body><div><h1>Title</h1><p>This is a paragraph.</p><p>This is another paragraph.</p></div><div><h2>Subtitle</h2><p>This is a subparagraph.</p></div>
</body>
</html>
- 经过块树构建后,块树结构如下:
Block 1: <div><h1>Title</h1><p>This is a paragraph.</p><p>This is another paragraph.</p></div>
Block 2: <div><h2>Subtitle</h2><p>This is a subparagraph.</p></div>
-
整体构建流程如下:

-
-
\3. 基于嵌入的块修剪:
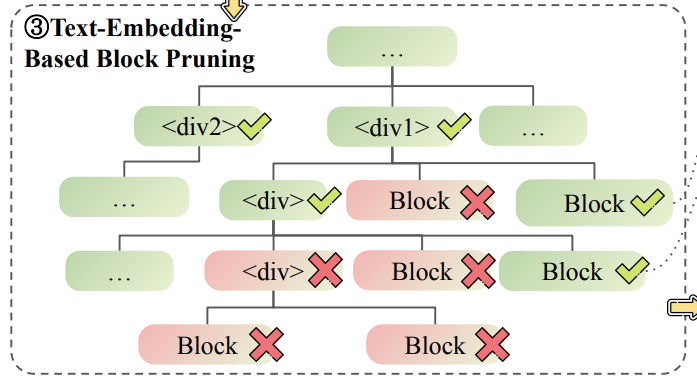
-
• 使用嵌入模型计算每个块与用户查询的相关性得分。
-
• 贪心算法删除得分低的块,直到HTML文档的长度满足上下文窗口的要求。
-
仍然用上面的例子,由于在前面已经做了数据清洗,留下的信息中除了保留文档结构之外,还大大降低了上下文压力,清洗掉了绝大部分噪音。我们有以下的块树:
- Block 1: <div><h1>Title</h1><p>This is a paragraph.</p><p>This is another paragraph.</p></div>
- Block 2: <div><h2>Subtitle</h2><p>This is a subparagraph.</p></div>
-
用户查询为“Tell me about the title”。嵌入模型计算得分如下:
-
- • Block 1: 0.9
- • Block 2: 0.3
- 贪心算法会删除Block 2,因为它的得分较低。
-
-
\4. 基于生成模型的细粒度块修剪:
-
- • 使用生成模型进一步修剪块树,生成模型能够处理更长的上下文,并且不局限于一次处理一个块。
- • 生成模型计算每个块的得分,然后使用贪心算法删除得分低的块。
-
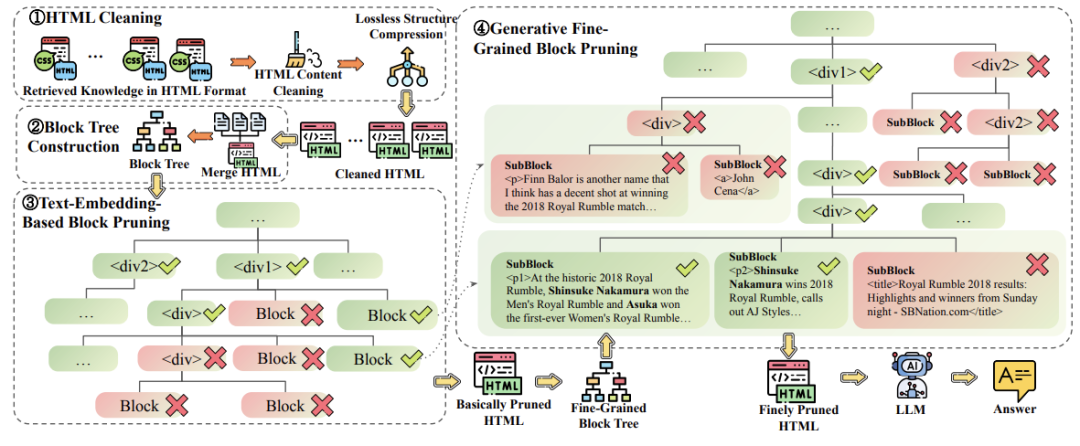
-
论文里也给出了这里用生成模型的提示词:
-

实验结果
- • 作者在六个QA数据集上进行了实验,结果显示使用HTML格式的知识比纯文本格式的知识效果更好。
- • 他们还进行了消融实验,验证了每个组件(如块树构建、嵌入模型修剪、生成模型修剪)的有效性。
这篇论文提出的方法确实有道理,因为HTML格式能够保留更多的结构和语义信息,这对于理解复杂文档非常有帮助。不过,HTML清洗和修剪的过程可能会比较复杂(毕竟不同的页面有不同的结构是吧),所以需要精细的调整,得到一个通用的清洗过程才能达到最佳效果,这里不需要将所有噪音都精确地清洗掉,这是不现实的。
另外,虽然作者提到现代LLM在预训练阶段已经接触过HTML文档,但不同LLM的能力可能有所不同,所以这个方法的效果可能会因LLM的选择而有所差异。总的来说,这是一个有趣且有潜力的研究方向,值得进一步探索和优化。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。