一、Source
Data Sources 是什么呢?就字面意思其实就可以知道:数据来源。
Flink 做为一款流式计算框架,它可用来做批处理,也可以用来做流处理,这个 Data Sources 就是数据的来源地。
flink在批/流处理中常见的source主要有两大类。
l 预定义Source
基于本地集合的source(Collection-based-source)
基于文件的source(File-based-source)
基于网络套接字(socketTextStream)
l 自定义Source

预定义Source演示
Collection [测试]--本地集合Source
在flink最常见的创建DataStream方式有四种:
l 使用env.fromElements(),这种方式也支持Tuple,自定义对象等复合形式。
注意:类型要一致,不一致可以用Object接收,但是使用会报错,比如:env.fromElements("haha", 1);
![]()
源码注释中有写:

l 使用env.fromCollection(),这种方式支持多种Collection的具体类型,如List,Set,Queue
l 使用env.generateSequence()方法创建基于Sequence的DataStream --已经废弃了
l 使用env.fromSequence()方法创建基于开始和结束的DataStream
一般用于学习测试时编造数据时使用
1.env.fromElements(可变参数);
2.env.fromColletion(各种集合);
3.env.fromSequence(开始,结束);
package com.bigdata.source;import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;public class _01YuDingYiSource {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 各种获取数据的SourceDataStreamSource<String> dataStreamSource = env.fromElements("hello world txt", "hello nihao kongniqiwa");dataStreamSource.print();DataStreamSource<Tuple2<String, Integer>> elements = env.fromElements(Tuple2.of("张三", 18),Tuple2.of("lisi", 18),Tuple2.of("wangwu", 18));elements.print();// 有一个方法,可以直接将数组变为集合 复习一下数组和集合以及一些非常常见的APIString[] arr = {"hello","world"};System.out.println(arr.length);System.out.println(Arrays.toString(arr));List<String> list = Arrays.asList(arr);System.out.println(list);env.fromElements(Arrays.asList(arr),Arrays.asList(arr),Arrays.asList(arr)).print();// 第二种加载数据的方式// Collection 的子接口只有 Set 和 ListArrayList<String> list1 = new ArrayList<>();list1.add("python");list1.add("scala");list1.add("java");DataStreamSource<String> ds1 = env.fromCollection(list1);DataStreamSource<String> ds2 = env.fromCollection(Arrays.asList(arr));// 第三种DataStreamSource<Long> ds3 = env.fromSequence(1, 100);ds3.print();// execute 下面的代码不运行,所以,这句话要放在最后。env.execute("获取预定义的Source");}
}
补充内容:可以在代码中指定并行度
l 指定全局并行度:
env.setParallelism(12);
l 获得全局并行度:
env.getParallelism();
指定算子设置并行度:
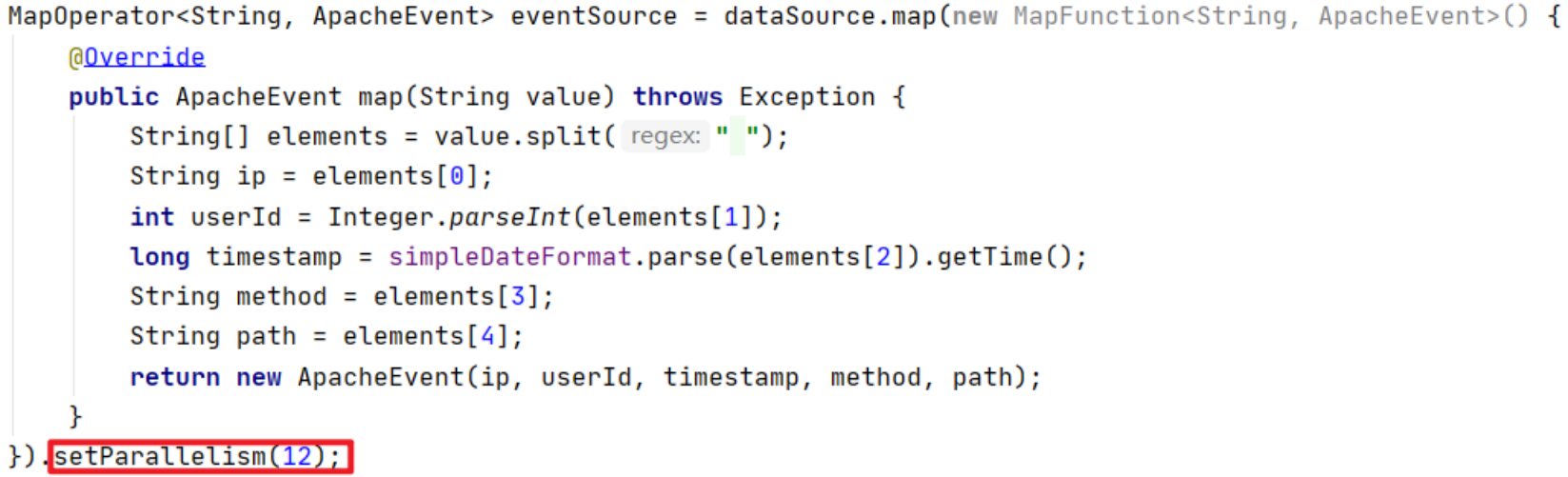
获取指定算子并行度:
eventSource.getParallelism();
本地文件的案例:
package com.bigdata.source;import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import java.io.File;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;public class _02YuDingYiSource {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 获取并行度System.out.println(env.getParallelism());// 讲第二种Source File类型的// 给了一个相对路径,说路径不对,怎么办?// 相对路径,转绝对路径File file = new File("datas/wc.txt");File file2 = new File("./");System.out.println(file.getAbsoluteFile());System.out.println(file2.getAbsoluteFile());DataStreamSource<String> ds1 = env.readTextFile("datas/wc.txt");ds1.print();// 还可以获取hdfs路径上的数据DataStreamSource<String> ds2 = env.readTextFile("hdfs://bigdata01:9820/home/a.txt");ds2.print();// execute 下面的代码不运行,所以,这句话要放在最后。env.execute("获取预定义的Source");}
}Socket [测试]
socketTextStream(String hostname, int port) 方法是一个非并行的Source,该方法需要传入两个参数,第一个是指定的IP地址或主机名,第二个是端口号,即从指定的Socket读取数据创建DataStream。该方法还有多个重载的方法,其中一个是socketTextStream(String hostname, int port, String delimiter, long maxRetry),这个重载的方法可以指定行分隔符和最大重新连接次数。这两个参数,默认行分隔符是”\n”,最大重新连接次数为0。
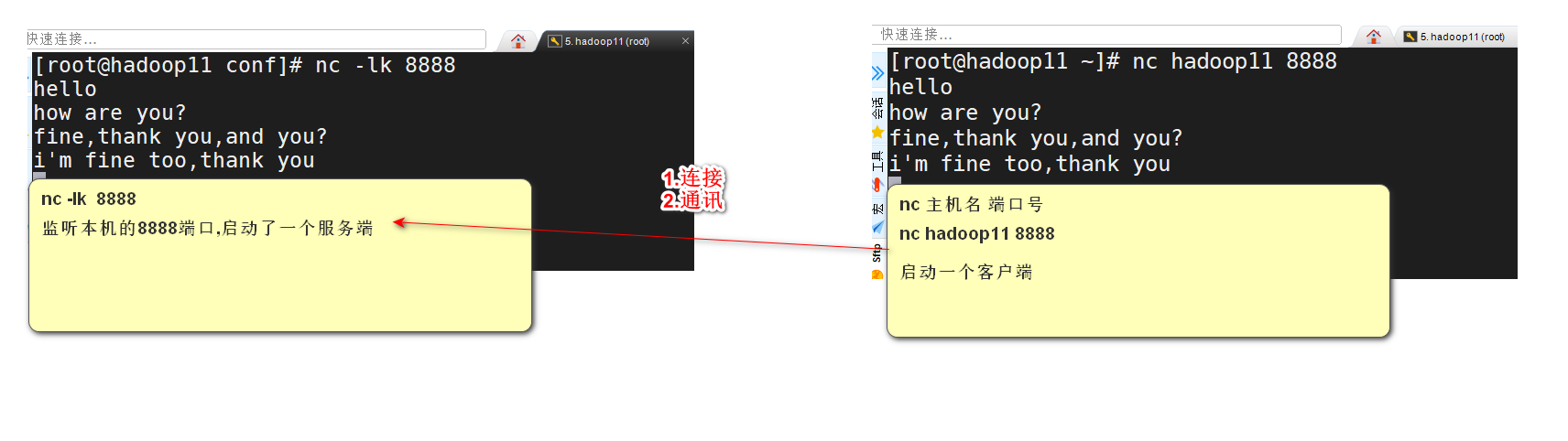
提示:
如果使用socketTextStream读取数据,在启动Flink程序之前,必须先启动一个Socket服务,为了方便,Mac或Linux用户可以在命令行终端输入nc -lk 8888启动一个Socket服务并在命令行中向该Socket服务发送数据。Windows用户可以在百度中搜索windows安装netcat命令。
yum install -y nc
nc -lk 8888 --向8888端口发送消息,这个命令先运行,如果先运行java程序,会报错!如果是windows平台:nc -lp 8888

代码演示:
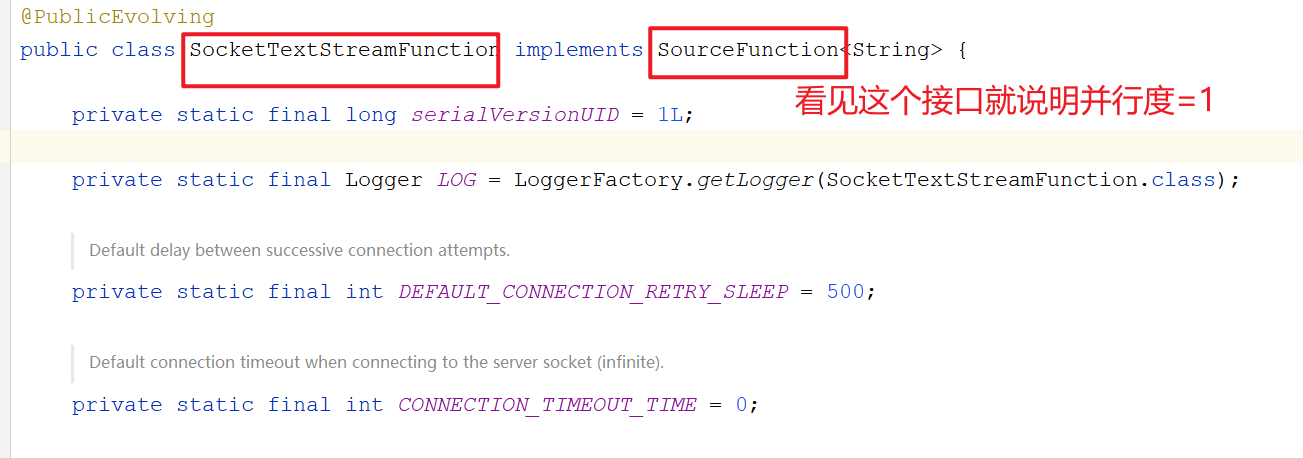
//socketTextStream创建的DataStream,不论怎样,并行度永远是1
public class StreamSocketSource {public static void main(String[] args) throws Exception {//local模式默认的并行度是当前机器的逻辑核的数量StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();int parallelism0 = env.getParallelism();System.out.println("执行环境默认的并行度:" + parallelism0);DataStreamSource<String> lines = env.socketTextStream("localhost", 8888);//获取DataStream的并行度int parallelism = lines.getParallelism();System.out.println("SocketSource的并行度:" + parallelism);SingleOutputStreamOperator<String> words = lines.flatMap(new FlatMapFunction<String, String>() {@Overridepublic void flatMap(String line, Collector<String> collector) throws Exception {String[] words = line.split(" ");for (String word : words) {collector.collect(word);}}});int parallelism2 = words.getParallelism();System.out.println("调用完FlatMap后DataStream的并行度:" + parallelism2);words.print();env.execute();}
}
以下用于演示:统计socket中的 单词数量,体会流式计算的魅力!
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;public class SourceDemo02_Socket {public static void main(String[] args) throws Exception {//TODO 1.env-准备环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);//TODO 2.source-加载数据DataStream<String> socketDS = env.socketTextStream("bigdata01", 8889);//TODO 3.transformation-数据转换处理//3.1对每一行数据进行分割并压扁DataStream<String> wordsDS = socketDS.flatMap(new FlatMapFunction<String, String>() {@Overridepublic void flatMap(String value, Collector<String> out) throws Exception {String[] words = value.split(" ");for (String word : words) {out.collect(word);}}});//3.2每个单词记为<单词,1>DataStream<Tuple2<String, Integer>> wordAndOneDS = wordsDS.map(new MapFunction<String, Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> map(String value) throws Exception {return Tuple2.of(value, 1);}});//3.3分组KeyedStream<Tuple2<String, Integer>, String> keyedDS = wordAndOneDS.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {@Overridepublic String getKey(Tuple2<String, Integer> value) throws Exception {return value.f0;}});//3.4聚合SingleOutputStreamOperator<Tuple2<String, Integer>> result = keyedDS.sum(1);//TODO 4.sink-数据输出result.print();//TODO 5.execute-执行env.execute();}
}通过在代码中打印并行度,可以发现 socketTextStream 获取到的dataStream,并行度为1。
自定义数据源 [了解]
SourceFunction:非并行数据源(并行度只能=1) --接口
RichSourceFunction:多功能非并行数据源(并行度只能=1) --类
ParallelSourceFunction:并行数据源(并行度能够>=1) --接口
RichParallelSourceFunction:多功能并行数据源(并行度能够>=1) --类 【建议使用的】
Rich 字样代表富有,在编程中,富有代表可以调用的方法很多,功能很全的意思。
package com.bigdata.day02;import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.ParallelSourceFunction;
import org.apache.flink.streaming.api.functions.source.RichParallelSourceFunction;
import org.apache.flink.streaming.api.functions.source.RichSourceFunction;
import org.apache.flink.streaming.api.functions.source.SourceFunction;import java.util.Random;
import java.util.UUID;/*** 需求: 每隔1秒随机生成一条订单信息(订单ID、用户ID、订单金额、时间戳)* 要求:* - 随机生成订单ID(UUID)* - 随机生成用户ID(0-2)* - 随机生成订单金额(0-100)* - 时间戳为当前系统时间*/@Data // set get toString
@AllArgsConstructor
@NoArgsConstructor
class OrderInfo{private String orderId;private int uid;private int money;private long timeStamp;
}
// class MySource extends RichSourceFunction<OrderInfo> {
//class MySource extends RichParallelSourceFunction<OrderInfo> {
class MySource implements SourceFunction<OrderInfo> {boolean flag = true;@Overridepublic void run(SourceContext ctx) throws Exception {// 源源不断的产生数据Random random = new Random();while(flag){OrderInfo orderInfo = new OrderInfo();orderInfo.setOrderId(UUID.randomUUID().toString());orderInfo.setUid(random.nextInt(3));orderInfo.setMoney(random.nextInt(101));orderInfo.setTimeStamp(System.currentTimeMillis());ctx.collect(orderInfo);Thread.sleep(1000);// 间隔1s}}// source 停止之前需要干点啥@Overridepublic void cancel() {flag = false;}
}
public class CustomSource {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(2);// 将自定义的数据源放入到env中DataStreamSource dataStreamSource = env.addSource(new MySource())/*.setParallelism(1)*/;System.out.println(dataStreamSource.getParallelism());dataStreamSource.print();env.execute();}}通过ParallelSourceFunction创建可并行Source
/*** 自定义多并行度Source*/
public class CustomerSourceWithParallelDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStreamSource<String> mySource = env.addSource(new MySource()).setParallelism(6);mySource.print();env.execute();}public static class MySource implements ParallelSourceFunction<String> {@Overridepublic void run(SourceContext<String> ctx) throws Exception {ctx.collect(UUID.randomUUID().toString());/*如果不设置无限循环可以看出,设置了多少并行度就打印出多少条数据*/}@Overridepublic void cancel() {}}
}如果代码换成ParallelSourceFunction,每次生成12个数据,假如是12核数的话。
总结:Rich富函数总结 ctrl + o
Rich 类型的Source可以比非Rich的多出有:- open方法,实例化的时候会执行一次,多个并行度会执行多次的哦(因为是多个实例了)- close方法,销毁实例的时候会执行一次,多个并行度会执行多次的哦- getRuntimeContext 方法可以获得当前的Runtime对象(底层API)/*** 自定义一个RichParallelSourceFunction的实现*/
public class CustomerRichSourceWithParallelDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStreamSource<String> mySource = env.addSource(new MySource()).setParallelism(6);mySource.print();env.execute();}/*Rich 类型的Source可以比非Rich的多出有:- open方法,实例化的时候会执行一次,多个并行度会执行多次的哦(因为是多个实例了)- close方法,销毁实例的时候会执行一次,多个并行度会执行多次的哦- getRuntime方法可以获得当前的Runtime对象(底层API)*/public static class MySource extends RichParallelSourceFunction<String> {@Overridepublic void open(Configuration parameters) throws Exception {super.open(parameters);System.out.println("open......");}@Overridepublic void close() throws Exception {super.close();System.out.println("close......");}@Overridepublic void run(SourceContext<String> ctx) throws Exception {ctx.collect(UUID.randomUUID().toString());}@Overridepublic void cancel() {}}
}Kafka Source [重要] --从kafka中读取数据
https://nightlies.apache.org/flink/flink-docs-release-1.13/zh/docs/connectors/datastream/kafka/
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka_2.11</artifactId><version>${flink.version}</version>
</dependency>关于kafka的复习:
zk的启动:
[root@bigdata01 app]# zk.sh start
---------- bigdata01 ----------
Starting zookeeper ... STARTED
---------- bigdata02 ----------
Starting zookeeper ... STARTED
---------- bigdata03 ----------
Starting zookeeper ... STARTED
[root@bigdata01 app]# zk.sh status
---------- bigdata01 ----------
Mode: follower
---------- bigdata02 ----------
Mode: leader
---------- bigdata03 ----------
Mode: followerkafka的启动:
kf.sh startkafka的可视化界面(选做):
./kafkaUI.sh start
http://bigdata01:8889
如何创建一个topic:
可以通过界面创建,也可以通过命令创建
bin/kafka-topics.sh --bootstrap-server bigdata01:9092 --create --partitions 1 --replication-factor 3 --topic first
控制台生产者:
bin/kafka-console-producer.sh --bootstrap-server bigdata01:9092 --topic first
控制台消费者:
bin/kafka-console-consumer.sh --bootstrap-server bigdata01:9092 --topic first 创建一个topic1 这个主题:
cd /opt/installs/kafka3/bin/kafka-topics.sh --bootstrap-server bigdata01:9092 --create --partitions 1 --replication-factor 3 --topic topic1通过控制台向topic1发送消息:
bin/kafka-console-producer.sh --bootstrap-server bigdata01:9092 --topic topic1package com.bigdata.day02;import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;import java.util.Properties;public class KafkaSource {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();Properties properties = new Properties();properties.setProperty("bootstrap.servers", "bigdata01:9092");properties.setProperty("group.id", "g1");FlinkKafkaConsumer<String> kafkaSource = new FlinkKafkaConsumer<String>("topic1",new SimpleStringSchema(),properties);DataStreamSource<String> dataStreamSource = env.addSource(kafkaSource);// 以下代码跟flink消费kakfa数据没关系,仅仅是将需求搞的复杂一点而已// 返回true 的数据就保留下来,返回false 直接丢弃dataStreamSource.filter(new FilterFunction<String>() {@Overridepublic boolean filter(String word) throws Exception {// 查看单词中是否包含success 字样return word.contains("success");}}).print();env.execute();}
}


