R小盐准备介绍R语言机器学习与预测模型的学习笔记, 快来收藏关注【科研私家菜】
01 机器学习的可解释性
对于集成学习方法,效果虽好,但一直无法解决可解释性的问题。我们知道一个xgboost或lightgbm模型,是由N棵树组成,所以对于特定的一个样本,我们无法知道这个样本的特征值是如何影响最终结果。虽说“不管白猫黑猫,抓住耗子的就是好猫”,但在具体任务中,我们还是希望能够获得样本每个特征与其结果之间的关系,特别是针对模型误分的那些样本,如果能够从特征和结果的角度进行分析,对于提高模型效果或是分析异常样本,是非常有帮助的。但是,其可解释性相对困难。
对于集成树模型来说,当做分类任务时,模型输出的是一个概率值。前文提到,SHAP是SHapley Additive exPlanations的缩写,即沙普利加和解释,因此SHAP实际是将输出值归因到每一个特征的shapely值上,换句话说,就是计算每一个特征的shapley值,依此来衡量特征对最终输出值的影响。
其原理及推到公式不再赘述。。。
02 SHAP的R语言实现
SHAP(SHapley Additive exPlanations)
library(tidyverse)
library(xgboost)
library(caret)
library(dplyr)
source("shap.R")bike <- read.csv("../shap-values-master/bike.csv",header = T)bike_2=select(bike, -days_since_2011, -cnt, -yr)bike_dmy = dummyVars(" ~ .", data = bike_2, fullRank=T)
bike_x = predict(bike_dmy, newdata = bike_2)## Create the xgboost model
model_bike = xgboost(data = bike_x, nround = 10, objective="reg:linear",label= bike$cnt) ## Calculate shap values
shap_result_bike = shap.score.rank(xgb_model = model_bike, X_train =bike_x,shap_approx = F)# `shap_approx` comes from `approxcontrib` from xgboost documentation.
# Faster but less accurate if true. Read more: help(xgboost)## Plot var importance based on SHAP
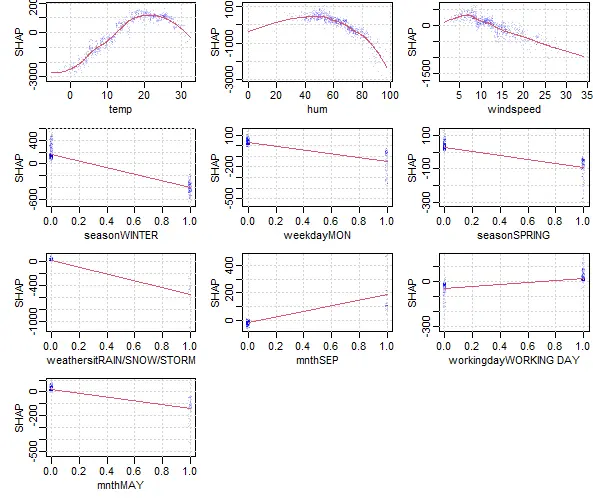
var_importance(shap_result_bike, top_n=15)## Prepare data for top N variables
shap_long_bike = shap.prep(shap = shap_result_bike,X_train = bike_x , top_n = 10)## Plot shap overall metrics
plot.shap.summary(data_long = shap_long_bike)##
xgb.plot.shap(data = bike_x, # input datamodel = model_bike, # xgboost modelfeatures = names(shap_result_bike$mean_shap_score[1:10]), # only top 10 varn_col = 3, # layout optionplot_loess = T # add red line to plot)效果如下:


03 SHAP R语言示例
data("iris")
X1 = as.matrix(iris[,-5])
mod1 = xgboost::xgboost(data = X1, label = iris$Species, gamma = 0, eta = 1,lambda = 0, nrounds = 1, verbose = FALSE)# shap.values(model, X_dataset) returns the SHAP
# data matrix and ranked features by mean|SHAP|
shap_values <- shap.values(xgb_model = mod1, X_train = X1)
shap_values$mean_shap_score
shap_values_iris <- shap_values$shap_score# shap.prep() returns the long-format SHAP data from either model or
shap_long_iris <- shap.prep(xgb_model = mod1, X_train = X1)
# is the same as: using given shap_contrib
shap_long_iris <- shap.prep(shap_contrib = shap_values_iris, X_train = X1)# **SHAP summary plot**
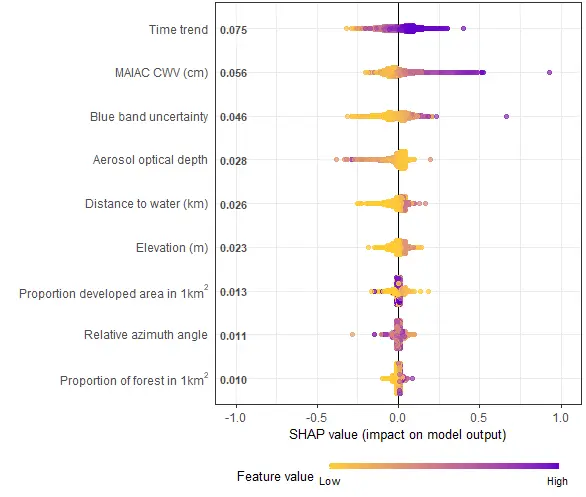
shap.plot.summary(shap_long_iris, scientific = TRUE)
shap.plot.summary(shap_long_iris, x_bound = 1.5, dilute = 10)# Alternatives options to make the same plot:
# option 1: from the xgboost model
shap.plot.summary.wrap1(mod1, X = as.matrix(iris[,-5]), top_n = 3)# option 2: supply a self-made SHAP values dataset
# (e.g. sometimes as output from cross-validation)
shap.plot.summary.wrap2(shap_score = shap_values_iris, X = X1, top_n = 3)
效果如下:


关注R小盐,关注科研私家菜(VX_GZH: SciPrivate),有问题请联系R小盐。让我们一起来学习 R语言机器学习与临床预测模型
© 著作权归作者所有,转载或内容合作请联系作者

喜欢的朋友记得点赞、收藏、关注哦!!!