点一下关注吧!!!非常感谢!!持续更新!!!
Java篇开始了!
目前开始更新 MyBatis,一起深入浅出!
目前已经更新到了:
- Hadoop(已更完)
- HDFS(已更完)
- MapReduce(已更完)
- Hive(已更完)
- Flume(已更完)
- Sqoop(已更完)
- Zookeeper(已更完)
- HBase(已更完)
- Redis (已更完)
- Kafka(已更完)
- Spark(已更完)
- Flink(已更完)
- ClickHouse(已更完)
- Kudu(已更完)
- Druid(已更完)
- Kylin(已更完)
- Elasticsearch(已更完)
- DataX(已更完)
- Tez(已更完)
- 数据挖掘(已更完)
- Prometheus(已更完)
- Grafana(已更完)
- 离线数仓(正在更新…)
章节内容
上节我们完成了如下的内容:
- 需求分析 指标口径
- 日志数据采集 taildir source HDFS Sink Agent Flume
- 优化配置

Flume的优化配置
Flume 是一种分布式、可靠且高效的数据收集、聚合和传输系统,广泛应用于大数据生态系统中。为了提升 Flume 的性能和稳定性,优化配置至关重要。
使用如下的指令,启动Agent进行测试:
flume-ng agent --conf-file /opt/wzk/flume-conf/flume-log2hdfs1.conf -name a1 -Dflum
e.roog.logger=INFO,console
启动后的截图如下所示:

查看刚才的Flume窗口:

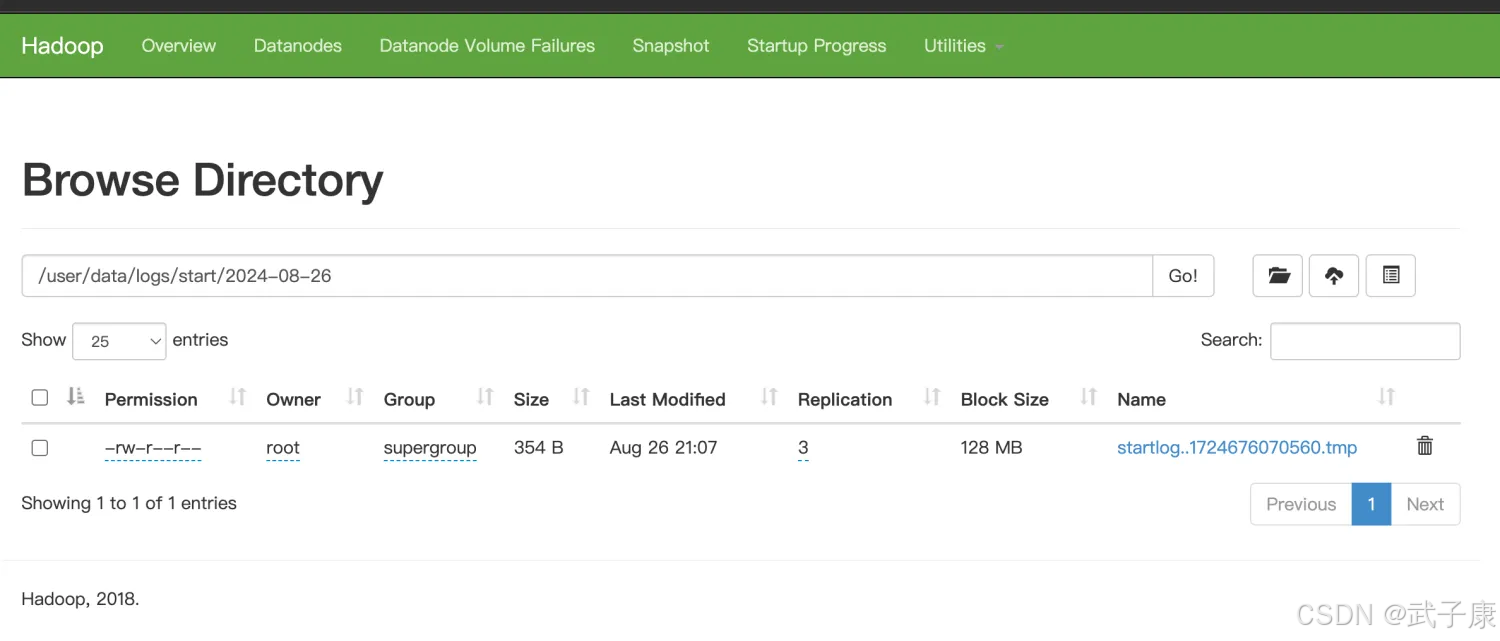
查看HDFS的内容:
批量处理
- 参数:batchSize
- 作用:控制 Flume 在批量传输时每次传输的事件数量。
配置建议: - Source 到 Channel:根据 Source 的吞吐量和 Channel 的吞吐能力调整,推荐值为 100-1000。
- Channel 到 Sink:根据 Sink 的处理能力和目标系统的写入性能调整,推荐值为 500-5000。
压缩传输
- 参数:compressionType
- 作用:对事件进行压缩后传输,减少网络带宽消耗。
- 支持的压缩类型:gzip、snappy、lz4 等。
- 配置建议:根据目标系统是否支持解压缩功能选择合适的压缩类型。
Source 优化
Taildir Source
- 参数:batchSize 和 fileHeader
- batchSize:设置单次从文件中读取的事件数量。
- fileHeader:是否在事件头部添加文件名,推荐开启以便于后续处理。
Kafka Source
- 参数:kafka.consumer.timeout.ms 和 fetch.message.max.bytes
- kafka.consumer.timeout.ms:设置 Kafka 消费者读取数据的超时时间,通常为 100-500ms。
- fetch.message.max.bytes:设置每次读取的最大消息大小,默认值通常为 1MB,可以根据业务场景适当调整。
Channel 优化
Memory Channel
- 参数:capacity 和 transactionCapacity
- capacity:Channel 中允许的最大事件数。
- transactionCapacity:单次事务中允许的最大事件数。
File Channel
- 参数:checkpointDir 和 dataDirs
- checkpointDir:存储 Channel 状态的目录。
- dataDirs:存储事件数据的目录,建议设置多个磁盘路径以提升 IO 性能。
- 配置建议:确保磁盘 IO 性能足够,避免瓶颈。
Flume报错解决
向 logs 目录中存放入日志文件,此时如果出现OOM的日志,是因为缺省情况下FlumeJVM的最大分配20M,这个值太小,需要调整。
我这里直接放入:
vim /opt/wzk/logs/start/test.log2020-07-30 14:18:47.339 [main] INFO com.ecommerce.AppStart - {"app_active":{"name":"app_active","json":{"entry":"1","action":"1","error_code":"0"},"time":1596111888529},"attr":{"area":"泰安","uid":"2F10092A9","app_v":"1.1.13","event_type":"common","device_id":"1FB872-9A1009","os_type":"4.7.3","channel":"DK","language":"chinese","brand":"iphone-9"}}解决方案:
在 $FLUME_HOME/conf/flume-env.sh 中增加以下内容:
export JAVA_OPTS="-Xms4000m -Xmx4000m -
Dcom.sun.management.jmxremote"
# 要想使配置文件生效,还要在命令行中指定配置文件目录
flume-ng agent --conf flume-1.9/conf --conf-file flume-log2hdfs1.conf -name a1 -Dflume.root.logger=INFO,consoleflume-ng agent --conf-file flume-log2hdfs1.conf -name a1 -Dflume.root.logger=INFO,console
Flume内存参数设置及优化:
- 根据日志数据量大小,JVM堆一般要设置为4G或者更高
- -Xms -Xmx最好设置一致,减少内存抖动带来的性能影响
自定义拦截器
前面FlumeAgent的配置使用了本地时间,可能导致数据存放的路径不正确。要解决上面的问题就需要使用自定义拦截器。
Agent用于测试自定义拦截器,source => logger sink
flumetest1.conf
# a1是agent的名称。source、channel、sink的名称分别为:r1 c1 k1
a1.sources = r1
a1.channels = c1
a1.sinks = k1
# source
a1.sources.r1.type = netcat
a1.sources.r1.bind = h122.wzk.icu
a1.sources.r1.port = 9999
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = icu.wzk.CustomerInterceptor$Builder
# channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 10000
a1.channels.c1.transactionCapacity = 100
# sink
a1.sinks.k1.type = logger
# source、channel、sink之间的关系
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
自定义拦截器原理
自定义拦截器的原理:
- 自定义拦截器要集成 Flume 的 Interceptor
- Event 分为 header 和 body (接收的字符串)
- 获取 header 和 body
- 从 body 中 获取 time,并将时间戳转换为字符串 yyyy-MM-dd
- 将转换后的字符串放置到header中
自定义拦截器实现
自定义拦截器的实现:
- 获取event的header
- 获取event的body
- 解析body获取json串
- 解析json串获取时间戳
- 将时间戳转换为字符串 yyyy-MM-dd
- 将转换后的字符串放置header中
- 返回event
导入依赖
<dependencies><dependency><groupId>org.apache.flume</groupId><artifactId>flume-ng-core</artifactId><version>1.9.0</version><scope>provided</scope></dependency><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.1.23</version></dependency>
</dependencies>
编写代码
package icu.wzk;import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;import java.nio.charset.StandardCharsets;
import java.time.Instant;
import java.time.LocalDateTime;
import java.time.ZoneId;
import java.time.format.DateTimeFormatter;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;public class CustomerInterceptor implements Interceptor {@Overridepublic void initialize() {}@Overridepublic Event intercept(Event event) {// 这里是逐条处理String eventBody = new String(event.getBody(), StandardCharsets.UTF_8);// 获取Event的HeaderMap<String, String> headerMap = event.getHeaders();// 解析Body获取JSON字符串String[] bodyArr = eventBody.split("\\s+");try {String jsonStr = bodyArr[6];// 解析JSON字符串获取时间戳JSONObject jsonObject = JSON.parseObject(jsonStr);String timestampStr = jsonObject.getJSONObject("app_active").getString("time");// 将时间戳转换字符串 yyyy-MM-dd// 将字符串转换为Longlong timestampLong = Long.parseLong(timestampStr);DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd");Instant instant = Instant.ofEpochMilli(timestampLong);LocalDateTime localDateTime = LocalDateTime.ofInstant(instant, ZoneId.systemDefault());String date = formatter.format(localDateTime);// 将转换后的字符串放置header中headerMap.put("logtime", date);event.setHeaders(headerMap);} catch (Exception e) {headerMap.put("logtime", "Unknown");event.setHeaders(headerMap);}return event;}@Overridepublic List<Event> intercept(List<Event> list) {List<Event> lstEvent = new ArrayList<>();for (Event event : list) {Event outEvent = intercept(event);if (outEvent != null) {lstEvent.add(outEvent);}}return lstEvent;}@Overridepublic void close() {}public static class Builder implements Interceptor.Builder {@Overridepublic Interceptor build() {return new CustomerInterceptor();}@Overridepublic void configure(Context context) {}}}



