-
MySQL 索引
- 概念与类型
- MySQL 索引是一种数据结构,用于快速查找数据库中的数据。它就像一本书的目录,通过索引可以快速定位到需要的数据行,而不必全表扫描。主要的索引类型包括 B - Tree 索引(默认索引类型)、哈希索引、全文索引等。
- B - Tree 索引是最常用的索引类型,它将数据存储在平衡树结构中。对于范围查询(如
WHERE column BETWEEN value1 AND value2)和排序操作(如ORDER BY column)非常有效。例如,在一个包含用户信息的表中,如果经常根据用户年龄进行查询,在年龄列创建 B - Tree 索引可以提高查询速度。 - 哈希索引是基于哈希表实现的,它的特点是查找速度非常快,适用于等值查询(如
WHERE column = value)。但是哈希索引不支持范围查询和排序操作。 - 全文索引主要用于对文本内容进行搜索,例如在文章内容列创建全文索引,可以方便地进行关键词搜索。
- 性能分析
- 效率分析
- 索引的选择性:索引的效率与索引列的选择性密切相关。选择性是指索引列中不同值的数量与表行数的比例。选择性越高,索引效率越高。例如,在一个性别列(只有男、女两个值)上建立索引,选择性较低,可能对查询性能的提升有限;而在一个唯一标识列(如用户 ID)上建立索引,选择性高,能很好地提高查询效率。
- 索引覆盖查询:如果一个查询所需的列都包含在索引中,那么可以直接从索引中获取数据,而不必访问表数据,这种情况称为索引覆盖查询。索引覆盖查询的效率非常高,因为避免了额外的数据读取操作。
- 源码分析(简单示例)
- MySQL 的索引实现代码主要在存储引擎层。以 InnoDB 存储引擎为例,B - Tree 索引的构建和维护涉及到复杂的算法。在插入数据时,会根据索引列的值通过比较和平衡操作将新节点插入到 B - Tree 中。在查询时,通过从根节点开始,沿着树的分支比较索引列的值,直到找到匹配的叶子节点来定位数据行。
- 概念与类型
-
MongoDB 索引
- 概念与类型
- MongoDB 索引也是用于提高查询性能的数据结构。它支持多种索引类型,如单字段索引、复合字段索引、全文索引、地理空间索引等。
- 单字段索引是对单个字段创建的索引,用于加速对该字段的查询。例如,在一个存储产品信息的集合中,对产品名称字段创建单字段索引,可以加快根据产品名称查找产品的速度。
- 复合字段索引是对多个字段创建的索引,适用于经常需要同时根据多个字段进行查询的情况。例如,在一个订单集合中,对(用户 ID,订单日期)创建复合字段索引,可以方便地查询某个用户在特定日期的订单。
- 全文索引用于对文本字段进行全文搜索,地理空间索引则用于处理地理空间数据相关的查询。
- 性能分析
- 查询性能提升:在适当的字段上创建索引可以大大提高 MongoDB 的查询性能。对于大型数据集,索引可以将查询时间从数秒甚至更长缩短到毫秒级别。例如,在一个包含数百万篇文章的集合中,对文章标题字段创建索引后,根据标题进行模糊搜索的速度会明显加快。
- 写入性能影响:和 MySQL 类似,MongoDB 创建索引后会对写入操作产生一定的性能影响。每次写入操作都可能导致索引的更新,尤其是在高并发写入的情况下,可能会导致写入性能下降。
- 效率分析
- 索引使用策略:MongoDB 在执行查询时会自动选择是否使用索引。它会根据查询条件和索引的匹配程度来决定。如果查询条件能够很好地利用现有索引,查询效率会很高。例如,一个精确匹配索引字段的查询会比一个不能利用索引的模糊查询效率高得多。
- 索引内存占用:MongoDB 索引会占用一定的内存空间。对于大型索引,可能需要足够的内存来保证索引的高效使用。如果内存不足,可能会导致索引频繁地从磁盘读取,从而降低查询性能。
- 源码分析(简单示例)
- MongoDB 的索引构建和查询处理代码主要在其核心存储模块中。在索引构建时,会根据索引类型和字段数据类型将数据组织成相应的索引结构。例如,对于 B - Tree 索引(MongoDB 内部部分索引基于 B - Tree 结构),会将索引数据按照一定的顺序插入到树结构中。在查询时,通过遍历索引结构来查找匹配的数据。
- 概念与类型
-
Redis 索引
- 概念与特殊之处
- 性能分析
- 读写性能极高:Redis 的读写性能非常高,因为它的数据存储在内存中。对于简单的键 - 值操作,如获取、设置一个键的值,时间复杂度可以达到 O (1)。在实际应用中,Redis 可以处理每秒数十万甚至更高的读写请求。
- 复杂查询的局限性:由于 Redis 没有像 MySQL 和 MongoDB 那样完整的索引体系,对于复杂的多条件查询(如同时根据多个字段进行筛选和排序)相对比较困难,效率可能较低。
- 效率分析
- 数据结构优化:Redis 通过对数据结构的优化来提高效率。例如,哈希表的冲突处理机制(如链地址法)保证了在有一定数据冲突的情况下,仍然能够快速地查找数据。跳表通过多层索引结构实现了高效的范围查询和排序,其时间复杂度可以达到 O (logN)。
- 内存使用效率:Redis 的内存使用效率较高,它通过一些内存优化策略,如压缩列表(用于存储小的列表或哈希)等,来减少内存占用。但是,在存储大量数据时,仍然需要合理规划内存使用,以避免内存不足。
- 源码分析(简单示例)
- 在 Redis 源码中,哈希表的实现主要包括哈希函数的定义、节点的存储结构和插入 / 查找 / 删除操作的实现。例如,哈希函数用于将键映射到哈希表的某个桶中,在插入一个新的键 - 值对时,会先计算键的哈希值,然后将值存储到对应的桶中。跳表的源码则涉及到节点的层次结构、插入和删除节点时的索引更新等操作,以保证跳表的有序性和高效性。
-
对比分析
- 查询性能对比
- 简单等值查询:Redis 在简单的键 - 值查询上性能最优,时间复杂度接近 O (1)。MySQL 的哈希索引在等值查询上也很快,B - Tree 索引稍慢一些。MongoDB 在单字段等值查询上如果有合适的索引,性能也较好。
- 范围查询和排序:MySQL 的 B - Tree 索引在范围查询和排序操作上表现出色,因为其索引结构本身就是为这些操作优化的。MongoDB 的复合字段索引和有序集合(基于跳表的部分)也能较好地处理范围查询和排序。Redis 的跳表在有序集合的范围查询和排序上有一定优势,但对于复杂的多表关联范围查询等情况,不如 MySQL 和 MongoDB。
- 写入性能对比
- 一般来说,Redis 写入性能最高,因为它主要是简单的内存操作。MySQL 和 MongoDB 在写入时都需要考虑索引更新的成本,相对而言,MySQL 由于其事务机制等因素,在高并发写入复杂数据结构时可能会更复杂一些,写入性能可能会受到更多影响。MongoDB 在写入性能上也会因为索引更新而下降,但在一些简单的插入场景下,其无模式(Schema - less)的特点可能会使其写入相对灵活一些。
- 数据结构和索引适用性对比
- MySQL 适合存储结构化数据,其索引适用于各种复杂的关系型查询,如多表联合查询、子查询等。MongoDB 适用于存储半结构化和非结构化数据,其索引可以根据不同的数据类型(如文档中的字段)灵活创建,对于文档内的嵌套字段等也能较好地处理。Redis 主要适用于缓存、快速读写的简单数据结构场景,其数据结构(哈希、跳表等)更侧重于内存中的高效存储和快速访问。
- 内存使用对比
- Redis 全部数据存储在内存中,所以对内存要求较高,但通过一些优化策略可以有效利用内存。MySQL 索引也会占用一定的内存空间,并且如果查询频繁地使用索引覆盖查询等情况,也需要足够的内存来缓存索引数据。MongoDB 索引同样会占用内存,而且其存储的数据可能具有更高的灵活性和多变性,在内存管理上需要考虑数据的动态增长和索引的更新。
- 查询性能对比
详细介绍MySQL、Mongo、Redis等数据库的索引
server/2024/11/14 9:33:43/
相关文章

设计模式之适配器模式(从多个MQ消息体中,抽取指定字段值场景)
前言 工作到3年左右很大一部分程序员都想提升自己的技术栈,开始尝试去阅读一些源码,例如Spring、Mybaits、Dubbo等,但读着读着发现越来越难懂,一会从这过来一会跑到那去。甚至怀疑自己技术太差,慢慢也就不愿意再触碰这…

aspose如何获取PPT放映页“切换”的“持续时间”值
aspose如何获取PPT放映页“切换”的“持续时间”值 项目场景问题描述问题1:从官方文档和资料查阅发现并没有对切换的持续时间进行处理的方法问题2:aspose的依赖包中,所有的关键对象都进行了混淆处理 解决方案1、找到ppt切换的持续时间对应的混…

修改msyql用户密码及更新mysql密码策略
查看mysql中初始的密码策略
SHOW VARIABLES LIKE validate_password% 2. 修改默认密码策略 -- 0 或者 LOW 只验证长度-- 1 或者 MEDIUM 验证长度、数字、大小写、特殊字符-- 2 或者 STRONG 验证长度、数字、大小写、特殊字符、字典文件set global validate_password.policy0;…
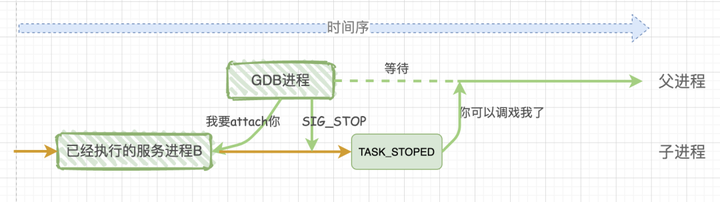
深入探索GDB调试技巧及其底层实现原理
本文分为两个大模块,第一部分记录下本人常用到的GDB的调试方法和技巧,第二部分则尝试分析GDB调试的底层原理。
一、GDB调试
要让程序能被调试,首先得编译成debug版本,当然release版本的也能通过导入符号表来实现调试,…

vue3+ant design vue实现表单校验记录清空
1、情景:假设在弹窗中存在表单校验,当触发后,弹出校验提示信息之后关闭弹窗,然后重新打开弹窗会发现原校验记录信息依旧存在,此时就需要清空。
2、代码
<a-modal v-model:open"open" title"心愿形…
【数据结构】【线性表】单链表4—单链表的建立(附C语言源码)
单链表的建立
单链表的建立其实就是一个结点插入的过程,首先构建链表的结点结构体,并进行初始化,然后再不断插入结点,我们需要解决的问题是:
用什么插入方式?在哪个位置插入?程序如何设计&…
做的图表配色太丑,怎么办?
在进行数据可视化的时候,小伙伴经常为配色烦恼,不会配色,导致做出 可视化图表不够“闪瞎”老板的双眼。 有没有配色模板能直接使用呢? 我把自己经常用的配色网站整理好啦,解决大家可视化配色难题。 一、配色模板网站 …