基于深度学习的在线小分子Kinome选择性预测平台的Python实现详解
本文将详细介绍如何使用Python实现KinomeProDL,一个基于深度学习的多任务神经网络模型,用于预测小分子对激酶的选择性谱。我们将从环境搭建、数据获取与处理、模型构建与训练、模型评估与应用等方面,逐步深入,力求每一个细节都考虑到。
目录
- 环境准备
- 数据获取与准备
- 2.1 获取ChEMBL数据库内容
- 2.2 数据清洗与预处理
- 2.3 分子表示转换
- 模型构建
- 3.1 消息传递神经网络(MPNN)实现
- 3.2 多任务学习架构设计
- 模型训练
- 4.1 损失函数与优化器选择
- 4.2 训练流程与超参数设置
- 模型评估
- 5.1 评估指标计算
- 5.2 模型性能可视化
- 模型应用
- 6.1 新化合物预测
- 6.2 模型微调与特定激酶预测
- 总结
1. 环境准备
在开始之前,确保您的计算环境中安装了以下主要库和工具:
- Python:版本3.7或以上
- Anaconda:推荐使用Anaconda进行包管理
- RDKit:用于化学信息学处理
- PyTorch:用于深度学习模型的构建和训练
- PyTorch Geometric:用于图神经网络(GNN)的实现
- scikit-learn:用于模型评估
- pandas、numpy、matplotlib:用于数据处理和可视化
安装步骤
-
安装Anaconda
从Anaconda官方网站下载并安装适用于您操作系统的Anaconda版本。
-
创建虚拟环境
conda create -n kinome_env python=3.8 conda activate kinome_env -
安装RDKit
conda install -c conda-forge rdkit -
安装PyTorch
conda install pytorch torchvision torchaudio cpuonly -c pytorch -
安装PyTorch Geometric
根据PyTorch Geometric官方网站的安装指南,执行以下命令:
pip install torch-scatter -f https://data.pyg.org/whl/torch-1.10.0+cpu.html pip install torch-sparse -f https://data.pyg.org/whl/torch-1.10.0+cpu.html pip install torch-geometric -
安装其他依赖库
conda install scikit-learn pandas numpy matplotlib
2. 数据获取与准备
2.1 获取ChEMBL数据库内容
ChEMBL是一个大型的生物活性化合物数据库,包含了丰富的化合物与靶点的活性数据。我们需要从ChEMBL中获取针对激酶的活性数据。
2.1.1 注册并获取ChEMBL数据
- 前往ChEMBL官方网站。
- 注册一个免费账户,以便访问更多数据。
- 下载最新版本的ChEMBL数据库(如ChEMBL27)。
2.1.2 使用ChEMBL数据库的API
ChEMBL提供了RESTful API,可以通过编程方式获取数据。
python">import requests
import pandas as pd# 定义API基础URL
base_url = 'https://www.ebi.ac.uk/chembl/api/data/'# 获取激酶的ChEMBL IDs
# 这里我们以获取所有激酶类靶点为例
target_url = base_url + 'target.json?target_type=SINGLE%20PROTEIN&protein_classification__protein_classification_id=493'# 获取所有激酶靶点
targets = []
while target_url:response = requests.get(target_url)data = response.json()targets.extend(data['targets'])target_url = data['page_meta']['next']# 提取激酶的ChEMBL IDs
kinase_ids = [target['target_chembl_id'] for target in targets]
2.1.3 获取激酶活性数据
python"># 初始化空的DataFrame
activity_data = pd.DataFrame()# 遍历所有激酶ID,获取对应的活性数据
for kinase_id in kinase_ids:activity_url = base_url + f'activity.json?target_chembl_id={kinase_id}&activity_type=IC50'while activity_url:response = requests.get(activity_url)data = response.json()if 'activities' in data:activities = pd.DataFrame(data['activities'])activity_data = pd.concat([activity_data, activities], ignore_index=True)activity_url = data['page_meta']['next']
注意:由于数据量大,以上过程可能需要较长时间,建议将数据保存为本地文件以供后续使用。
python">activity_data.to_csv('kinase_activity_data.csv', index=False)
2.2 数据清洗与预处理
2.2.1 读取数据
python">import pandas as pd# 读取之前保存的活性数据
data = pd.read_csv('kinase_activity_data.csv')
2.2.2 数据筛选
- 选择标准化的生物活性数据:确保选择的是标准化的IC50值,单位为nM。
- 过滤不可信的数据:移除数据可信度低的数据。
python"># 只保留标准化的IC50数据,单位为nM
data = data[data['standard_type'] == 'IC50']
data = data[data['standard_units'] == 'nM']# 移除缺失值
data = data.dropna(subset=['canonical_smiles', 'standard_value'])# 转换标准值为浮点型
data['standard_value'] = data['standard_value'].astype(float)
2.2.3 去重与统一
- 去重:移除重复的化合物-靶点对。
- 统一SMILES表示:确保SMILES字符串的一致性。
python"># 去重
data = data.drop_duplicates(subset=['molecule_chembl_id', 'target_chembl_id'])# 统一SMILES表示,使用RDKit规范化
from rdkit import Chemdef canonicalize_smiles(smiles):mol = Chem.MolFromSmiles(smiles)if mol:return Chem.MolToSmiles(mol)else:return Nonedata['canonical_smiles'] = data['canonical_smiles'].apply(canonicalize_smiles)
data = data.dropna(subset=['canonical_smiles'])
2.2.4 定义活性阈值并标注
- 活性标注:将IC50值转换为活性标签,通常设置一个阈值,如1000 nM,低于此值为活性(1),高于此值为非活性(0)。
python"># 定义活性阈值
activity_threshold = 1000 # nM# 标注活性
data['activity_label'] = data['standard_value'].apply(lambda x: 1 if x <= activity_threshold else 0)
2.2.5 构建化合物-激酶矩阵
- 获取所有独立的化合物和激酶列表。
python">compounds = data['canonical_smiles'].unique()
kinases = data['target_chembl_id'].unique()
- 构建标签矩阵:行表示化合物,列表示激酶,元素为活性标签。
python">import numpy as npcompound_to_index = {smiles: idx for idx, smiles in enumerate(compounds)}
kinase_to_index = {kinase: idx for idx, kinase in enumerate(kinases)}labels = np.zeros((len(compounds), len(kinases)), dtype=int)for _, row in data.iterrows():c_idx = compound_to_index[row['canonical_smiles']]k_idx = kinase_to_index[row['target_chembl_id']]labels[c_idx, k_idx] = row['activity_label']
2.2.6 创建数据集DataFrame
python">dataset = pd.DataFrame({'smiles': compounds,'labels': list(labels)
})
2.3 分子表示转换
使用RDKit将SMILES转换为分子对象,并构建图表示,以供图神经网络使用。
2.3.1 定义原子和键的特征提取函数
python">from rdkit.Chem import rdchemdef get_atom_features(atom):features = []features.append(atom.GetAtomicNum()) # 原子序数features.append(atom.GetDegree()) # 度数features.append(atom.GetFormalCharge()) # 形式电荷features.append(int(atom.GetChiralTag())) # 手性标签features.append(int(atom.GetHybridization())) # 杂化方式features.append(int(atom.GetIsAromatic())) # 芳香性return featuresdef get_bond_features(bond):features = []features.append(int(bond.GetBondTypeAsDouble())) # 键类型features.append(int(bond.GetIsConjugated())) # 共轭性features.append(int(bond.IsInRing())) # 是否在环中features.append(int(bond.GetStereo())) # 立体化学信息return features
2.3.2 构建分子图数据对象
python">import torch
from torch_geometric.data import Datadef mol_to_graph_data_obj(smiles):mol = Chem.MolFromSmiles(smiles)if mol is None:return Nonemol = Chem.AddHs(mol)# 获取原子特征atom_features_list = []for atom in mol.GetAtoms():atom_feature = get_atom_features(atom)atom_features_list.append(atom_feature)x = torch.tensor(atom_features_list, dtype=torch.float)# 获取边(键)信息edge_index = []edge_attr_list = []for bond in mol.GetBonds():start = bond.GetBeginAtomIdx()end = bond.GetEndAtomIdx()edge_index.append([start, end])edge_index.append([end, start]) # 无向图bond_feature = get_bond_features(bond)edge_attr_list.append(bond_feature)edge_attr_list.append(bond_feature)edge_index = torch.tensor(edge_index, dtype=torch.long).t().contiguous()edge_attr = torch.tensor(edge_attr_list, dtype=torch.float)data = Data(x=x, edge_index=edge_index, edge_attr=edge_attr)return data
2.3.3 将所有化合物转换为图数据对象
python">graph_data_list = []
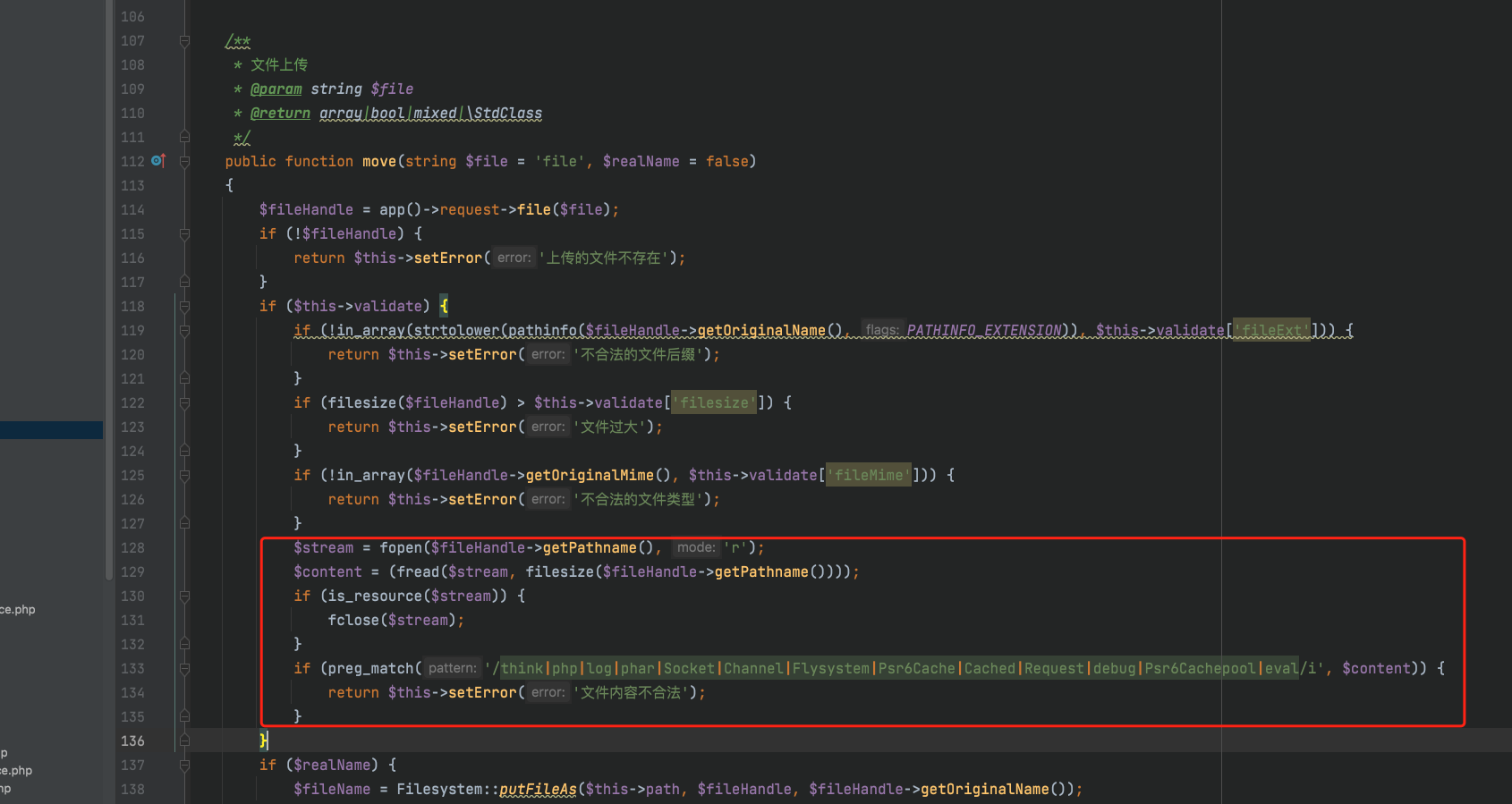
for idx, row in dataset.iterrows():graph_data = mol_to_graph_data_obj(row['smiles'])if graph_data is not None:graph_data.y = torch.tensor(row['labels'], dtype=torch.float)graph_data_list.append(graph_data)
3. 模型构建
3.1 消息传递神经网络(MPNN)实现
使用PyTorch Geometric实现消息传递神经网络(MPNN)。MPNN的核心在于消息传递和更新函数。
3.1.1 定义MPNN层
python">import torch.nn as nn
from torch_geometric.nn import MessagePassing
from torch_geometric.utils import add_self_loopsclass MPNNLayer(MessagePassing):def __init__(self, in_channels, out_channels):super(MPNNLayer, self).__init__(aggr='add') # 使用加法聚合self.linear = nn.Linear(in_channels, out_channels)self.edge_linear = nn.Linear(edge_attr_dim, out_channels)self.activation = nn.ReLU()def forward(self, x, edge_index, edge_attr):# 添加自环edge_index, _ = add_self_loops(edge_index, num_nodes=x.size(0))return self.propagate(edge_index, x=x, edge_attr=edge_attr)def message(self, x_j, edge_attr):# 消息函数,考虑边的特征msg = self.linear(x_j) + self.edge_linear(edge_attr)return self.activation(msg)def update(self, aggr_out):# 更新函数return aggr_out
注意:edge_attr_dim需要根据边特征的维度设置。
3.2 多任务学习架构设计
3.2.1 定义KinomeProDL模型
python">class KinomeProDLModel(nn.Module):def __init__(self, num_node_features, num_edge_features, num_tasks, hidden_dim=128, num_layers=3):super(KinomeProDLModel, self).__init__()self.num_layers = num_layersself.convs = nn.ModuleList()self.convs.append(MPNNLayer(num_node_features, hidden_dim))for _ in range(num_layers - 1):self.convs.append(MPNNLayer(hidden_dim, hidden_dim))self.global_pool = nn.Sequential(nn.Linear(hidden_dim, hidden_dim),nn.ReLU(),nn.Dropout(0.2))self.output_layer = nn.Linear(hidden_dim, num_tasks)def forward(self, data):x, edge_index, edge_attr = data.x, data.edge_index, data.edge_attrfor conv in self.convs:x = conv(x, edge_index, edge_attr)# 全局池化x = torch.mean(x, dim=0)x = self.global_pool(x)out = self.output_layer(x)return out
3.2.2 参数说明
num_node_features:节点特征的维度。num_edge_features:边特征的维度。num_tasks:激酶的数量,即多任务的数量。hidden_dim:隐藏层维度,可调整。num_layers:MPNN的层数,可调整。
4. 模型训练
4.1 损失函数与优化器选择
4.1.1 损失函数
由于这是一个多任务的二分类问题,使用nn.BCEWithLogitsLoss作为损失函数。
python">criterion = nn.BCEWithLogitsLoss()
4.1.2 优化器
使用Adam优化器,学习率设置为0.001,可根据需要调整。
python">optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
4.2 训练流程与超参数设置
4.2.1 数据集划分
将数据集划分为训练集、验证集和测试集,常用比例为8:1:1。
python">from sklearn.model_selection import train_test_splittrain_data, temp_data = train_test_split(graph_data_list, test_size=0.2, random_state=42)
val_data, test_data = train_test_split(temp_data, test_size=0.5, random_state=42)
4.2.2 创建数据加载器
python">from torch_geometric.loader import DataLoaderbatch_size = 32train_loader = DataLoader(train_data, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_data, batch_size=batch_size)
test_loader = DataLoader(test_data, batch_size=batch_size)
4.2.3 模型实例化
python">num_node_features = graph_data_list[0].x.shape[1]
num_edge_features = graph_data_list[0].edge_attr.shape[1]
num_tasks = labels.shape[1]model = KinomeProDLModel(num_node_features, num_edge_features, num_tasks)
4.2.4 训练过程
python">import torchdevice = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model.to(device)num_epochs = 50 # 可根据需要调整best_val_loss = float('inf')for epoch in range(1, num_epochs + 1):# 训练模式model.train()total_loss = 0for batch in train_loader:batch = batch.to(device)optimizer.zero_grad()out = model(batch)loss = criterion(out, batch.y)loss.backward()optimizer.step()total_loss += loss.item() * batch.num_graphsavg_loss = total_loss / len(train_loader.dataset)# 验证模式model.eval()val_loss = 0with torch.no_grad():for batch in val_loader:batch = batch.to(device)out = model(batch)loss = criterion(out, batch.y)val_loss += loss.item() * batch.num_graphsavg_val_loss = val_loss / len(val_loader.dataset)print(f'Epoch {epoch}, Training Loss: {avg_loss:.4f}, Validation Loss: {avg_val_loss:.4f}')# 保存最佳模型if avg_val_loss < best_val_loss:best_val_loss = avg_val_losstorch.save(model.state_dict(), 'best_model.pt')
4.2.5 超参数设置
- 学习率(
lr):初始值为0.001,可根据训练情况调整。 - 批量大小(
batch_size):常用32或64,可根据显存大小调整。 - 隐藏层维度(
hidden_dim):128或256,维度越高模型复杂度越高。 - 模型层数(
num_layers):3到5层,一般来说,层数越多,模型的表达能力越强,但也更容易过拟合。 - 训练轮数(
num_epochs):根据验证集的表现决定,一般在10到100之间。
5. 模型评估
5.1 评估指标计算
5.1.1 在测试集上评估模型
python">model.load_state_dict(torch.load('best_model.pt'))
model.eval()all_preds = []
all_labels = []with torch.no_grad():for batch in test_loader:batch = batch.to(device)out = model(batch)preds = torch.sigmoid(out).cpu().numpy()labels = batch.y.cpu().numpy()all_preds.append(preds)all_labels.append(labels)all_preds = np.concatenate(all_preds, axis=0)
all_labels = np.concatenate(all_labels, axis=0)
5.1.2 计算AUROC和AUPRC
python">from sklearn.metrics import roc_auc_score, average_precision_scoreauroc_list = []
auprc_list = []for i in range(num_tasks):y_true = all_labels[:, i]y_score = all_preds[:, i]if np.sum(y_true) > 0 and np.sum(y_true) < len(y_true): # 确保正负样本都有auroc = roc_auc_score(y_true, y_score)auprc = average_precision_score(y_true, y_score)else:auroc = Noneauprc = Noneauroc_list.append(auroc)auprc_list.append(auprc)print(f'Kinase {i+1}, AUROC: {auroc}, AUPRC: {auprc}')
5.2 模型性能可视化
5.2.1 绘制ROC曲线
python">import matplotlib.pyplot as plt
from sklearn.metrics import roc_curve, auc# 选择一个激酶,例如第一个
kinase_idx = 0
y_true = all_labels[:, kinase_idx]
y_score = all_preds[:, kinase_idx]fpr, tpr, _ = roc_curve(y_true, y_score)
roc_auc = auc(fpr, tpr)plt.figure()
plt.plot(fpr, tpr, color='darkorange', lw=2, label=f'ROC curve (area = {roc_auc:.2f})')
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title(f'ROC Curve for Kinase {kinase_idx+1}')
plt.legend(loc='lower right')
plt.show()
5.2.2 绘制Precision-Recall曲线
python">from sklearn.metrics import precision_recall_curveprecision, recall, _ = precision_recall_curve(y_true, y_score)
auprc = average_precision_score(y_true, y_score)plt.figure()
plt.step(recall, precision, where='post', label=f'AP = {auprc:.2f}')
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.title(f'Precision-Recall Curve for Kinase {kinase_idx+1}')
plt.legend(loc='lower left')
plt.show()
6. 模型应用
6.1 新化合物预测
使用训练好的模型对新化合物进行激酶选择性预测。
6.1.1 定义预测函数
python">def predict_new_compounds(smiles_list, model):model.eval()predictions = {}for smiles in smiles_list:graph_data = mol_to_graph_data_obj(smiles)if graph_data is None:print(f'Invalid SMILES: {smiles}')continuegraph_data = graph_data.to(device)with torch.no_grad():out = model(graph_data)preds = torch.sigmoid(out).cpu().numpy()predictions[smiles] = predsreturn predictions
6.1.2 输入新化合物进行预测
python">new_smiles_list = ['CCOC(=O)C1=CC=CC=C1', # 示例SMILES'CCN(CC)CCOC(=O)C1=CC=CC=C1'
]predictions = predict_new_compounds(new_smiles_list, model)# 输出预测结果
for smiles, preds in predictions.items():print(f'Predictions for {smiles}:')for i, score in enumerate(preds):print(f' Kinase {i+1}: {score:.4f}')
6.2 模型微调与特定激酶预测
如果您有特定激酶的私有数据,可以对模型进行微调,以提高对该激酶的预测精度。
6.2.1 准备私有数据
假设您有针对特定激酶的新数据,格式与之前的数据相同。
python"># 读取私有数据
private_data = pd.read_csv('private_kinase_data.csv')# 预处理步骤与之前相同
# ...# 将私有数据转换为图数据对象
private_graph_data_list = []
for idx, row in private_data.iterrows():graph_data = mol_to_graph_data_obj(row['smiles'])if graph_data is not None:graph_data.y = torch.tensor(row['labels'], dtype=torch.float)private_graph_data_list.append(graph_data)
6.2.2 微调模型
python">private_loader = DataLoader(private_graph_data_list, batch_size=batch_size, shuffle=True)# 使用较小的学习率进行微调
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)fine_tune_epochs = 10for epoch in range(1, fine_tune_epochs + 1):model.train()total_loss = 0for batch in private_loader:batch = batch.to(device)optimizer.zero_grad()out = model(batch)loss = criterion(out, batch.y)loss.backward()optimizer.step()total_loss += loss.item() * batch.num_graphsavg_loss = total_loss / len(private_loader.dataset)print(f'Fine-tuning Epoch {epoch}, Loss: {avg_loss:.4f}')
6.2.3 验证微调效果
使用微调后的模型在验证集或新的测试集上评估性能,以验证微调效果。
7. 总结
本文详细介绍了如何使用Python实现基于深度学习的在线小分子Kinome选择性预测平台——KinomeProDL。我们从环境准备开始,逐步深入到数据获取、数据预处理、模型构建、模型训练、模型评估和模型应用。
- 数据获取与处理:通过ChEMBL数据库获取大量的激酶活性数据,并进行了严格的数据清洗和预处理,为模型训练提供了高质量的数据基础。
- 模型构建:采用消息传递神经网络(MPNN)和多任务学习架构,构建了能够同时预测多个激酶活性的小分子图神经网络模型。
- 模型训练与评估:详细介绍了模型的训练流程,包括损失函数、优化器、超参数设置等,并使用了AUROC和AUPRC等指标对模型进行了全面评估。
- 模型应用:展示了如何使用训练好的模型对新化合物进行预测,以及如何通过微调提高模型在特定激酶上的预测精度。
通过本文的详细讲解,希望能够帮助您全面理解并实现KinomeProDL模型,为激酶抑制剂的发现和优化提供强有力的工具。
后续工作建议:
- 数据扩展:可以整合更多的公开数据集,如BindingDB、PubChem BioAssay等,进一步丰富训练数据。
- 模型优化:尝试使用更先进的图神经网络模型,如GAT、GraphSAGE等,提升模型性能。
- 特征工程:引入更丰富的原子和分子特征,如分子指纹、物化性质等,增强模型的表达能力。
- 部署应用:将模型部署为Web服务或集成到虚拟筛选平台,实现实际的药物筛选应用。
参考文献:
- ChEMBL Database: https://www.ebi.ac.uk/chembl/
- PyTorch Geometric Documentation: https://pytorch-geometric.readthedocs.io/en/latest/
- RDKit Documentation: https://www.rdkit.org/docs/