多语言向量模型训练时,有一个棘手问题 -- 语言鸿沟(Language Gap)。简单来说,就是不同语言中表达相同含义的短语,它们的向量却可能相距甚远,无法有效对齐。
理想情况下,一段文本及其不同语言的翻译版本,应该具有高度近似的向量表示。这样,我们才能像处理单语言文本一样,无缝地进行跨语言分析和应用。
然而现实情况确是,模型在训练过程中容易关注原文的表层语言特征,形成一种“语义鸿沟”,导致跨语言任务性能受损。
为了更好地理解和解决“语言鸿沟”问题,我们用 jina-xlm-roberta 模型和最新的 jina-embeddings-v3进行了一系列实验,来评估模型对同一种语言内的释义以及跨语言翻译的语义对齐能力,以及不同训练条件下语义相似文本的向量聚类情况。
本文将详细介绍我们的实验结果和分析,并分享我们对跨语言语义对齐的思考和 insights。
语言鸿沟:多语言模型的棘手挑战
训练文本向量模型,通常要经历两个核心阶段:
1. 掩码语言建模(Masked Language Modeling, MLM)
在预训练阶段,我们会使用大量文本数据,并随机遮盖一些 Token,然后训练模型来通过其余的 Token 预测 masked 的 Token。
这个过程就像做“填空题”,帮助模型学习训练数据中的一种或多种语言的模式,包括语法规则、词汇含义以及现实世界中一些语言习惯等。
2. 对比学习(Contrastive Learning)
预训练完成后,我们会用一些精心挑选或者半自动构建的数据集,继续训练模型。这里的目标是让语义相似的文本向量靠得更近,同时(可选地)将语义不相似的文本向量推得更远。
这个过程有点像“连连看”,训练时可以使用成对、三元组甚至更大规模的文本组合,前提是得知道或者能可靠地估计它们的语义相似性。
对比学习阶段可能还会分成好几个子阶段,而且训练策略也很多,目前学术界还没有定论说哪种方法最好,新的研究成果也层出不穷。
要想搞明白语言鸿沟是怎么产生的,该怎么弥合它,就得深入研究这两个阶段分别起了什么作用,以及它们之间是怎么互相影响的。
掩码语言预训练:跨语言对齐的起点
文本向量模型的一些跨语言能力是在预训练期间获得的。同源词和借用词的存在,让模型能够从海量的文本数据中学习到一些跨语言语义对齐的知识。
举个例子,英语单词 banana 和法语单词 banane,还有德语 Banane 拼写非常接近,而且出现的频率也都很高。所以向量模型很容易就能发现,在不同的语言里,长得像“banan-”的单词,它们的分布模式都很相似。
利用这些信息,模型就能在一定程度上学会:即使有些单词在不同语言里长得不太一样,但它们的意思可能很接近,甚至还能摸索出一些语法结构是怎么翻译的。
不过,这种学习过程是隐式的,没有明确的指导和监督。
为了看看 jina-xlm-roberta 模型,也就是 jina-embeddings-v3 的预训练主干模型,到底从掩码语言预训练中学到了多少跨语言等效性的知识,我们做了个实验。
我们选了一组英语文本,把它们翻译成德语、荷兰语、简体中文和日语,然后用 UMAP 可视化它们的向量表示,结果如下图所示,灰色线条将非英语文本连接到它们翻译的源英语文本。
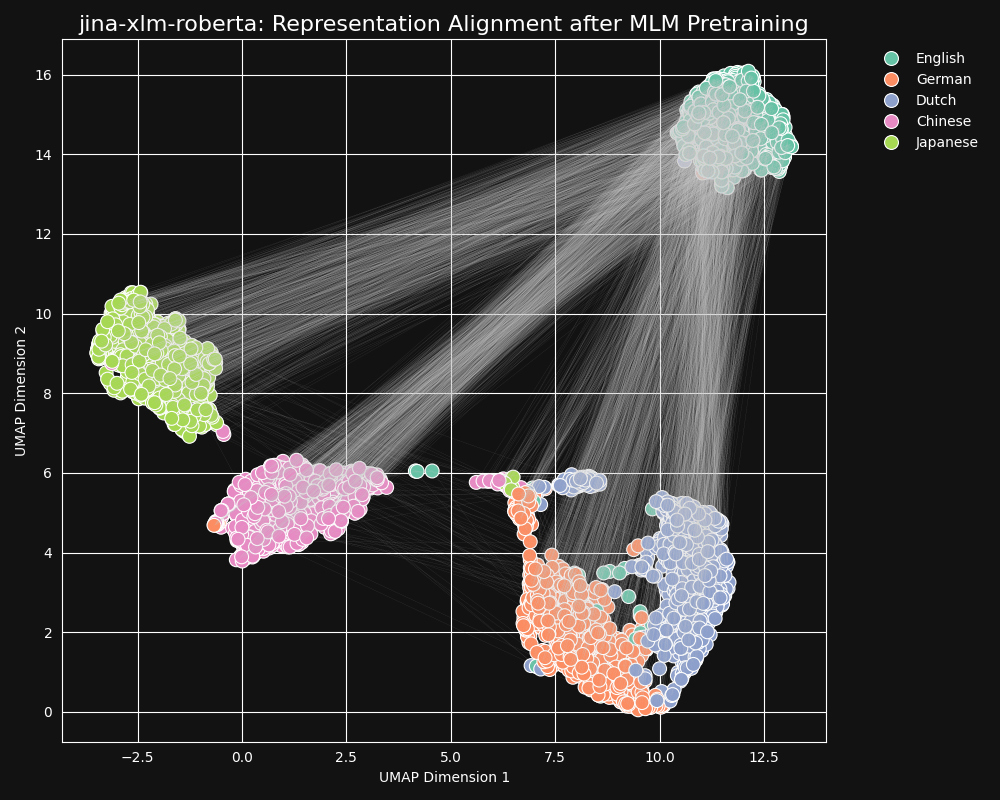
可以看到,jina-xlm-roberta 模型会把同一种语言的句子向量紧紧地聚在一起。
当然,这毕竟是把高维空间的分布投影到二维的结果,因此也存在以下可能性:比如,某个德语文本可能是某个英语文本的最佳翻译,但在所有德语文本中,它和英语源文本的向量距离是最小的。但这也说明了,这句英语文本的向量,可能比语义相同或相近的德语文本的向量,更接近其他的英语文本。
另外,我们还能注意到,德语和荷兰语的聚类比其他语言对更紧密。这很正常,毕竟这两种语言关系比较近,相似度很高,有时候甚至可以部分互通。
日语使用大量的汉字,其中很多汉字与中文相同,并且两种语言中都有许多词汇由一个或多个汉字构成。从 MLM 的角度来看,这种字符层面的相似性,与荷兰语和德语在词语拼写上的相似性类似。
为了更直观地说明这种“语言鸿沟”,我们可以简化场景,只考虑两种语言,每种语言各选取两句进行分析:

由于 MLM 预训练会很自然地把文本按照语言聚类,“我的狗是蓝色的”和“我的猫是红色的”这两句英语句子就会聚在一起,远离它们的德语翻译。
这和我们之前的技术博客里讨论的 模态鸿沟(Modality Gap) 不太一样,我们认为这主要是由语言之间的表面相似性和差异性造成的:比如拼写相似,印刷体里用了相同的字符序列,还有形态和句法结构的相似性 (比如常用的词序和构词方式)。
模态鸿沟的技术博客:https://jina.ai/news/the-what-and-why-of-text-image-modality-gap-in-clip-models/
总而言之,虽然模型在 MLM 预训练阶段学到了一些跨语言等效性的知识,但这还远远不够,不足以克服它按照语言聚类文本的强烈倾向。这就留下了一个巨大的语言鸿沟,需要我们想办法去跨越。
对比学习:弥合语言鸿沟的关键
理想情况下,我们希望向量模型能够忽略文本的语言差异,专注于捕捉其语义含义,就像下图这样:

在这样的模型中,文本不会因为语言不同而产生聚类。换句话说,无论文本使用何种语言,只要语义相似,它们的向量表示就应该非常接近;反之,即使文本使用同一种语言,如果语义差异很大,它们的向量表示也应该相距甚远。
很可惜,光靠 MLM 预训练是做不到这一点的。所以,我们得请出 对比学习 ,进一步提升文本向量中蕴含的语义信息。
对比学习用的是什么呢?用的是一些文本对和文本三元组,我们事先知道它们的意思是相似还是不同,或者哪一对比另一对更相似。在训练过程中,我们会不断调整模型的参数,让它能够准确地反映这些文本对和三元组之间的语义关系。
我们的对比学习数据集涵盖了 30 种语言,不过超过 97% 的文本对和三元组都只用了一种语言,只有不到 3% 涉及跨语言的文本对或三元组。
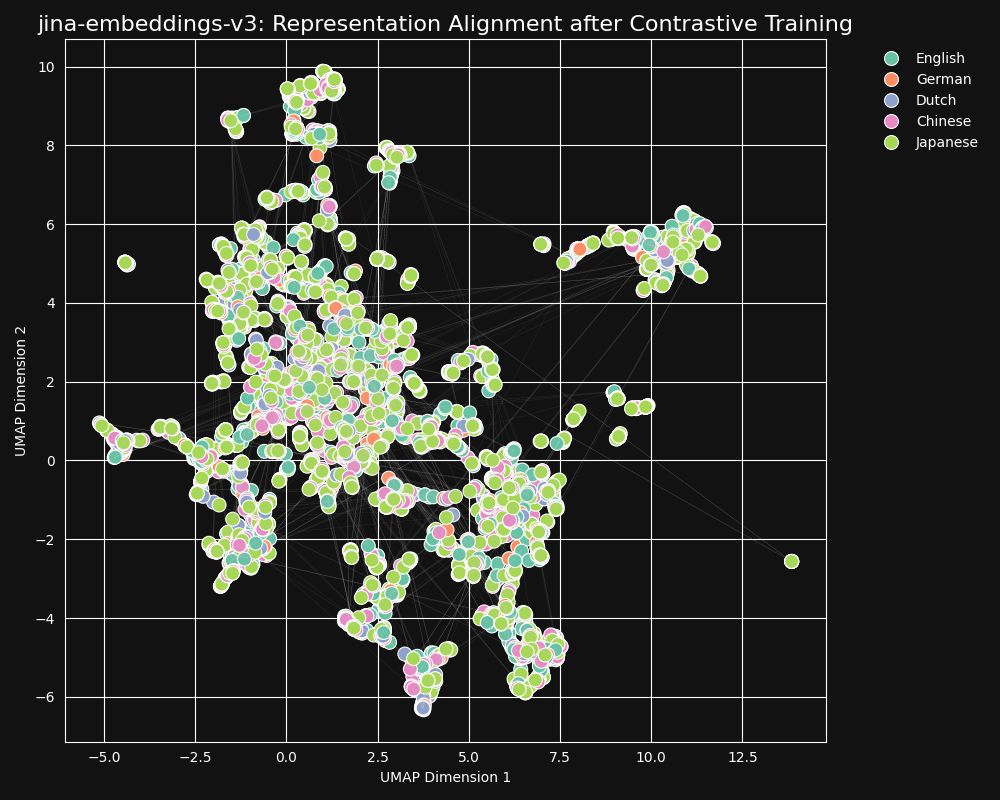
但这区区 3% 的数据,却发挥了巨大的作用:经过对比学习训练的向量模型,几乎看不到语言聚类的现象了,而且不管文本是什么语言,只要语义相似,它们的向量就会很接近,就像jina-embeddings-v3向量的 UMAP 投影展示的这样:
为了更直观地展示对比学习的效果,我们用 jina-xlm-roberta 和 jina-embeddings-v3 在 STS17 数据集上生成的向量,计算了它们的 Spearman 相关性。
Spearman 相关性是用来衡量两个有序列表之间一致性的指标。 它很适合用来比较不同的向量模型,或者把向量模型和人工评价的结果进行比较。因为具体的得分数值并不重要,重要的是哪些文本排在前面,哪些文本排在后面,这个顺序是不是一致。
下面的图表展示了不同语言的翻译文本,它们在语义相似度排名上的 Spearman 相关性。我们的做法是,先选一组英语句子,然后计算它们和某个参考句子的向量相似度,并按照从最相似到最不相似排序。接着,我们把所有这些句子翻译成另一种语言,再重复一遍排序的过程。
如果跨语言向量模型足够完美,那么这两种语言得到的排序结果应该完全一样,Spearman 相关性就会是 1.0。
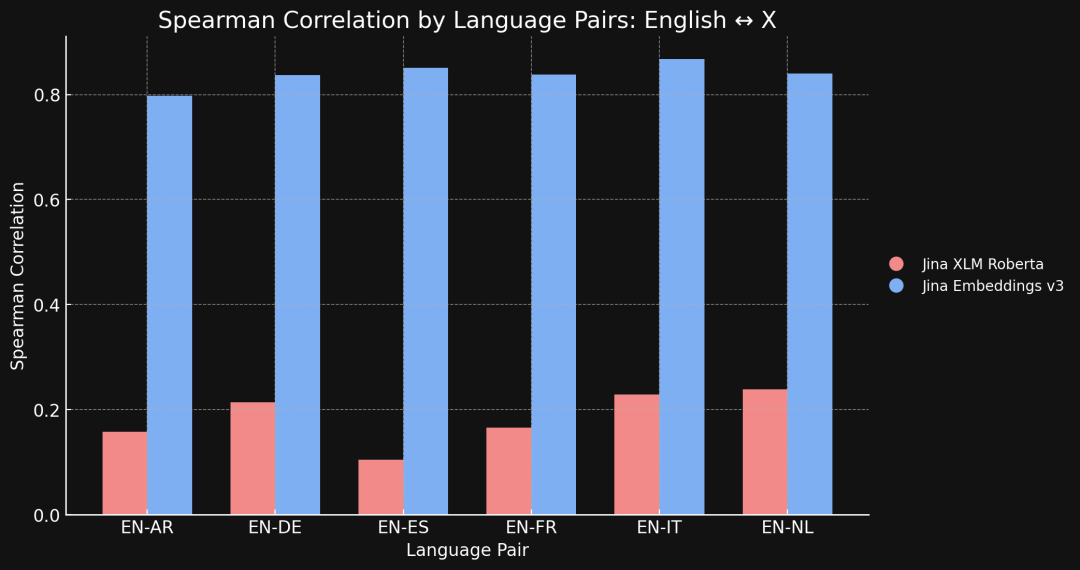
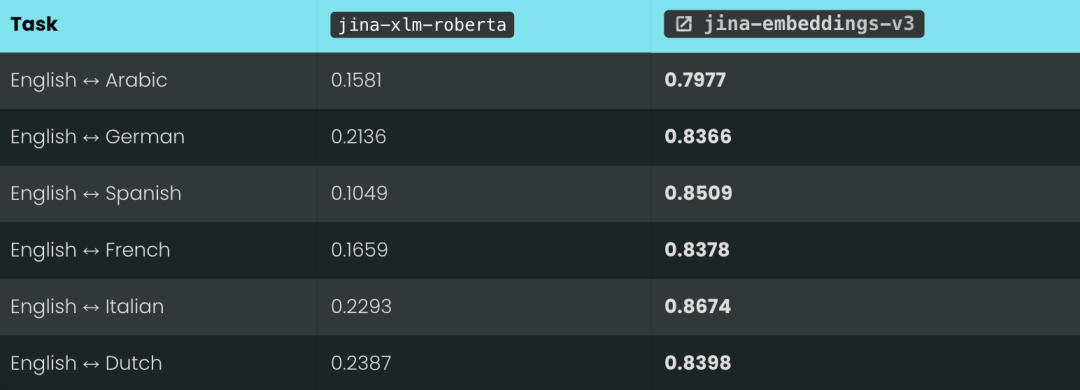
以上是我们用 jina-xlm-roberta 和 jina-embeddings-v3比较英语和 STS17 基准测试中其他六种语言的结果。
从这些结果可以看出,对比学习带来的提升是巨大的。 虽然 jina-embeddings-v3 模型的训练数据里只有 3% 的跨语言数据,但它已经学到了足够多的跨语言语义知识,几乎完全消除了预训练阶段遗留下来的语言鸿沟。
英语为主的训练数据:其他语言的表现如何?
我们用 89 种语言训练了jina-embeddings-v3,重点关注了 30 种使用频率很高的语言。虽然我们想方设法构建了一个规模很大的多语言训练数据集,但英语还是占了对比学习数据的近一半。
跟英语数据庞大的规模相比,其他语言的数据量就显得捉襟见肘了,即便是那些在全球范围内广泛使用、文本资料也很丰富的语言。
考虑到英语数据在训练数据中占据主导地位,我们不禁要问:这是否会导致英语文本的向量表示比其他语言文本的向量表示更一致?
为了探究这个问题,我们又设计了一项实验。
我们构建了一个 parallel-sentences 的数据集,包含 1000 个英语文本对,每一对由一个“前提”文本和一个“蕴含”文本组成,其中“蕴含”文本的含义可以由“前提”文本推断出来。
比如,下表的第一行。这两句话的意思不能说完全一样,但至少它们是逻辑上兼容的,可以用来描述同一个场景,只不过信息量略有不同。

然后,我们用 GPT-4o 把这些文本对翻译成了五种语言:德语、荷兰语、简体中文、繁体中文和日语。翻译完之后,我们还专门人工检查了一遍,保证翻译质量过关。
接下来,我们用 jina-embeddings-v3 对每个文本对进行编码,并计算它们之间的余弦相似度。下图和表格展示了每种语言的余弦相似度得分分布,以及平均相似度:
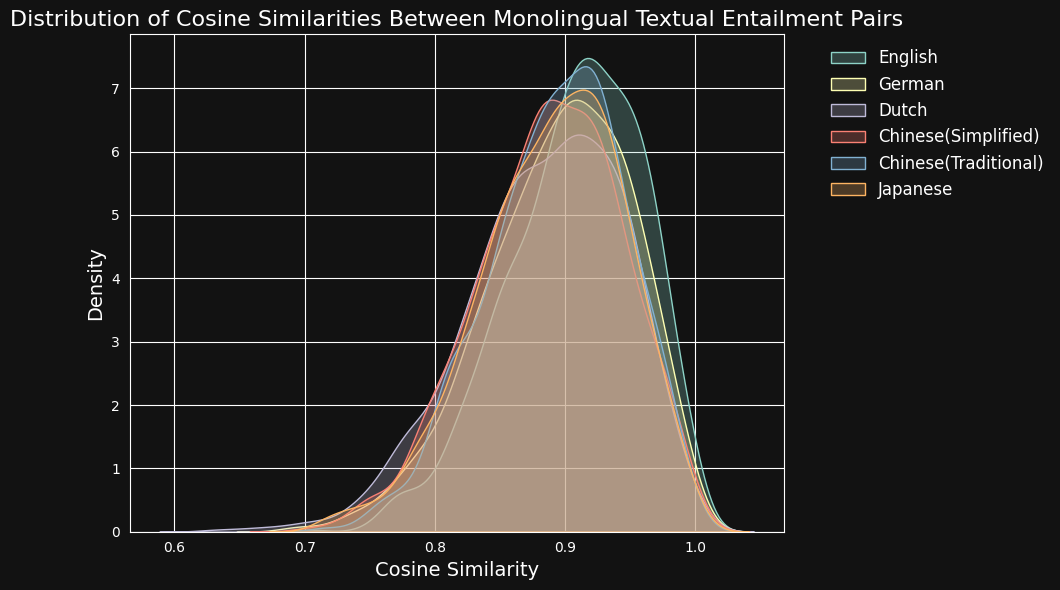
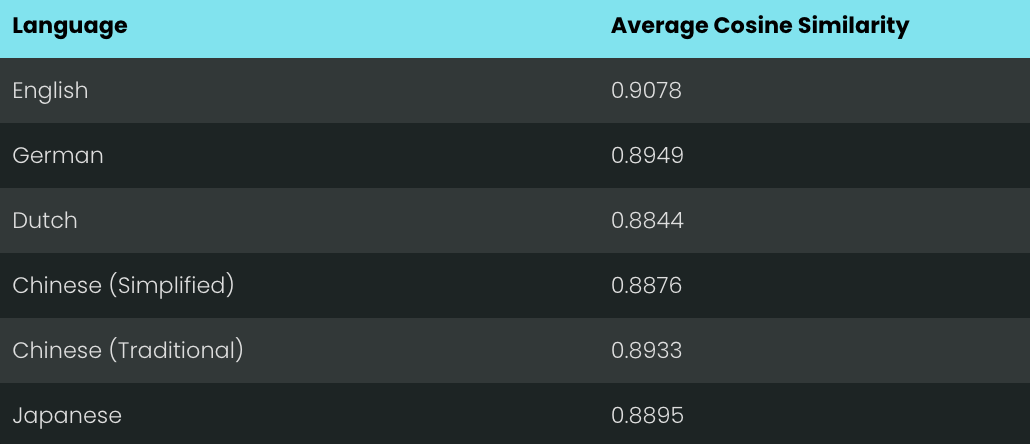
尽管英语在训练数据中占据较大比例,但 jina-embeddings-v3 在识别德语、荷兰语、日语和两种中文的语义相似性方面,表现与英语基本持平。
超越英语中心:构建更公平的多语言向量模型
在跨语言表示对齐的研究中,大家通常都会关注那些包含英语的语言对。从理论上讲,这种做法可能会掩盖一些关键信息。模型可能只关注于将所有语言的表示都与英语对齐,而忽略了其他语言对之间的对齐情况。
为了研究这个问题,我们用 parallel-sentences 数据集做了一些实验,重点关注那些超越英语的双语对,看看它们的对齐情况如何。
下表展示了不同语言对之间,对应文本的余弦相似度分布——这些文本都是从同一个英语源文本翻译过来的。
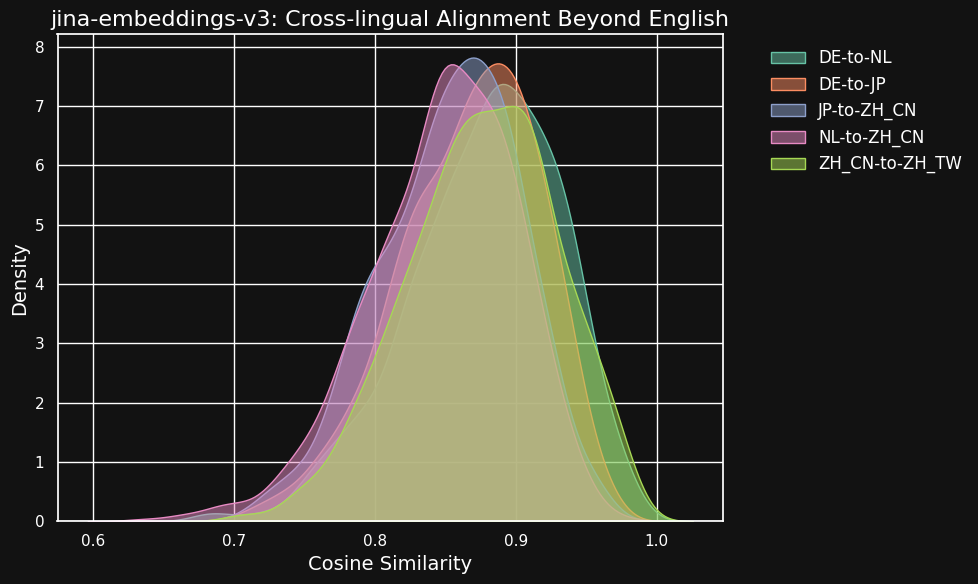
理想情况下,所有语言对的余弦相似度都应该是 1,这意味着它们的语义向量是完全相同的。
当然,现实中不可能达到这么完美的效果,但我们希望一个好的模型,至少在处理翻译文本对的时候,能够给出很高的余弦相似度。

可以看到,虽然不同语言之间的相似度得分比同一种语言内部兼容文本的相似度得分略低一些,但仍然很高。荷兰语/德语翻译对的余弦相似度,几乎和德语内部兼容文本的余弦相似度一样高。
这其实也不奇怪,毕竟德语和荷兰语属于同源语系(coganate)。同样的道理,我们这里测试的简体和繁体中文,其实也不能算是两种不同的语言,只是同一种语言在书写风格上略有差异而已。
但你也能看到,即使是像荷兰语和中文、德语和日语这样差异很大的语言对,在处理语义等价的文本时,仍然表现出了很强的相似性。
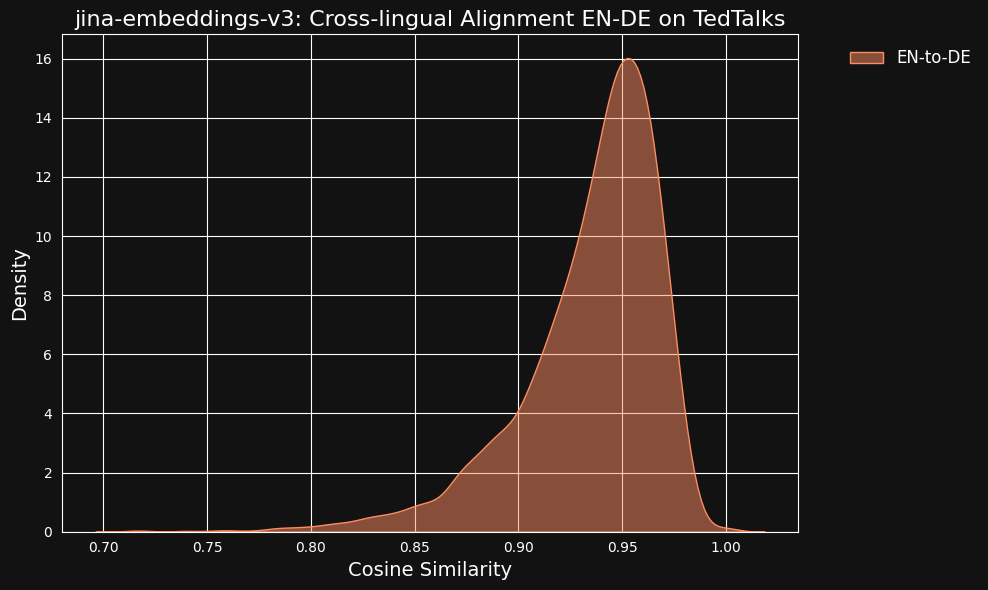
我们也想过,这些超高的相似度值,会不会是 ChatGPT 翻译带来的副作用。为了验证这一点,我们下载了 TED 演讲的人工翻译字幕 (英语和德语),然后检查了一下对齐的翻译句子是不是也具有这么高的相关性。
结果发现,人工翻译字幕的相关性比机器翻译的结果还要高,如下图所示。
跨语言数据是提升跨语言性能的关键因素吗?
前面我们看到,语言鸿沟弥合了,跨语言性能也提升了,这效果看起来跟训练数据里专门用来做跨语言对齐的那一小部分数据不太匹配啊。毕竟只有 3% 的对比学习数据是专门用来教模型如何在不同语言之间建立联系的。
所以,我们忍不住又做了个测试,看看跨语言数据到底有没有起到作用。
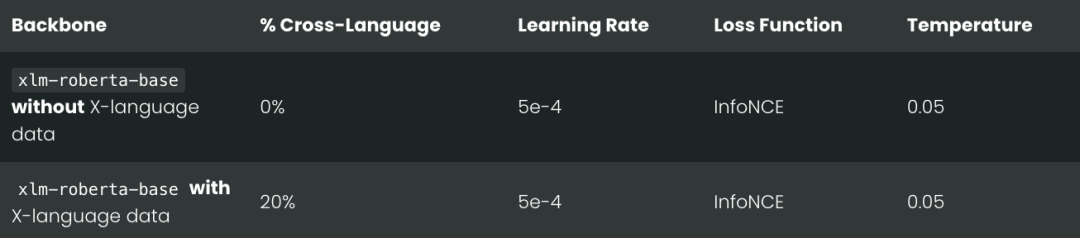
如果完全不用跨语言数据,从头开始重新训练 jina-embeddings-v3,那成本就太高了,不现实。所以,我们选择在xlm-roberta-base 模型基础上,使用了部分 jina-embeddings-v3 的训练数据,进行了对比学习训练。
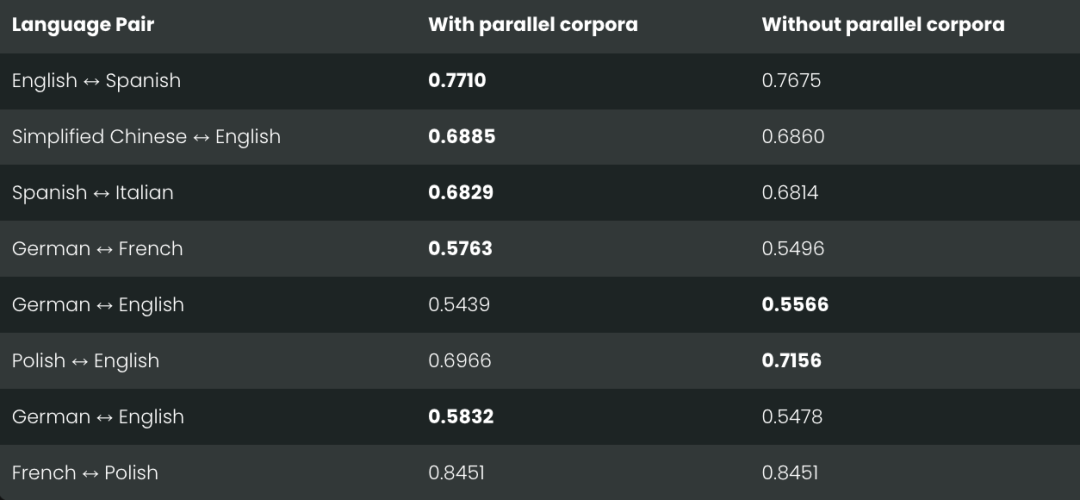
我们特意调整了跨语言数据的比例,设计了两种情况:一种是完全不使用跨语言数据,另一种是 20% 的文本对是跨语言的。具体的训练参数可以看下表:
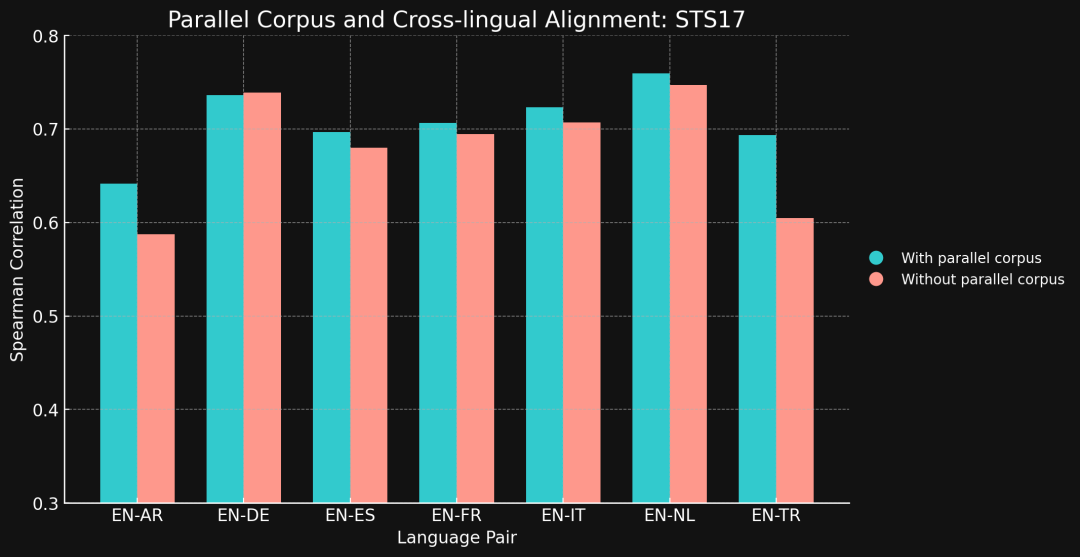
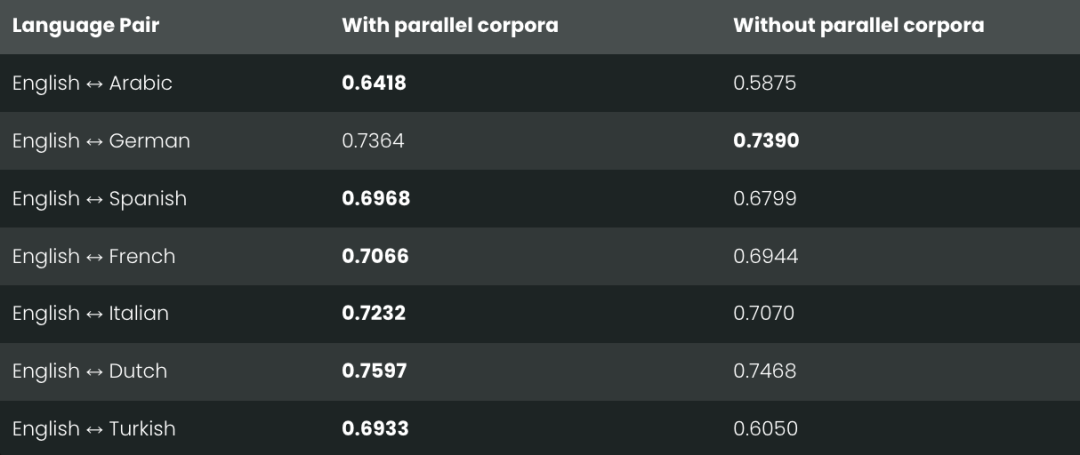
训练完之后,我们用 MTEB 里的 STS17 和 STS22 基准测试 和 Spearman 相关性来评估这两个模型的跨语言性能。结果如下:
STS17
STS22
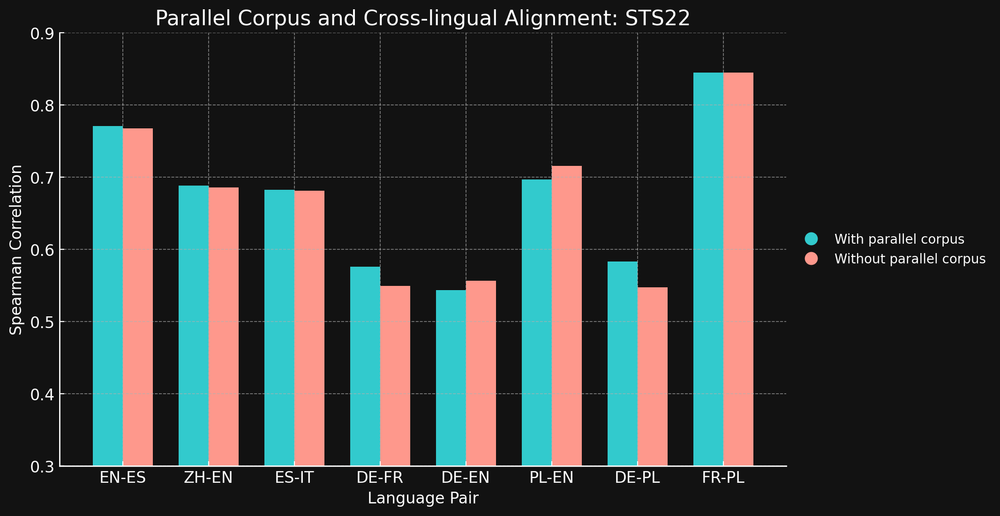
出乎我们意料的是,对于大多数测试的语言对,跨语言数据并没有显著提升模型的性能。
那这是否意味着跨语言数据并不重要呢?
我们认为,目前还不能下定论。
首先,本次实验的训练数据集规模相对较小, 这一结论未必适用于更大规模的数据集和更复杂的模型。但至少,我们的实验结果表明,专门的跨语言训练数据带来的性能增益,可能并没有我们预期的那么大。
其次,我们需要关注低资源语言的情况。例如,STS17 基准测试中包含英语/阿拉伯语和英语/土耳其语这两种语言对,而这两种语言在我们的训练数据中占比极低 (分别只有 1.7% 和 1.8%)。事实上,XML-RoBERTa 模型的预训练数据中,阿拉伯语和土耳其语也分别仅占 2.25% 和 2.32%,远低于其他测试语言。
但有趣的是,在我们测试的所有语言对中,只有 英语/阿拉伯语 和 英语/土耳其语 这两个低资源语言对在使用跨语言数据训练后性能得到了显著提升。
基于上述观察,我们推测:对于那些在训练数据中占比很低,但又十分重要的语言来说,专门的跨语言训练数据可能会发挥更大的作用。
当然,这一推测还需要更多研究来验证。跨语言数据在对比学习中的作用和有效性,也是 Jina AI 目前正在积极研究的方向之一。
结论
传统的语言预训练方法,比如掩码语言建模,都会导致“语言鸿沟”现象 —— 即使语义相近,不同语言的文本在向量空间中的距离也可能比预期更大。而我们的研究表明,Jina Embeddings 采用的对比学习方法能够有效地缩小甚至弥合这种鸿沟,实现高质量的跨语言语义对齐。
对比学习为何如此有效?目前,我们对此机制的理解尚不完全透彻。虽然我们在对比学习中使用了少量跨语言文本对,但它们对最终结果的影响程度仍需进一步探究。我们尝试在更严格的条件下进行实验,以期获得更确切的结论,但目前尚未得到明确的答案。
尽管如此,有一点是毋庸置疑的:jina-embeddings-v3 已经成功跨越了预训练带来的语言鸿沟,拥有强大的跨语言能力,成为了多语言应用的强大工具。如果你需要一款能够在多种语言上表现出色的向量模型,jina-embeddings-v3 绝对值得一试。
你可以通过多种方式体验jina-embeddings-v3的强大功能:
在官网 https://jina.ai/ 我们提供了一百万免费 Token 额度,方便你快速上手。
AWS 和 Azure:
jina-embeddings-v3已集成到 AWS 和 Azure 平台,方便你进行部署和使用。
此外,jina-embeddings-v3采用 CC BY-NC 4.0 许可协议,如果您需要其他平台上使用,或将其部署到您的公司内部,欢迎随时联系我们:https://jina.ai/contact-sales