Lagent & AgentLego 智能体应用搭建——作业
- 一、基础作业
- 1.1、前期准备
- 1.1.1、 配置基本环境
- 1.1.2、安装 Lagent 和 AgentLego
- 1.1.3、安装其他依赖
- 1.1.4、安装 Tutorial
- 1.2、完成 Lagent Web Demo 使用
- 1.2.1、启动服务端
- 1.2.2、建立命令行客户端
- 1.2.3、使用 Lagent Web Demo
- 1.3、完成 AgentLego 直接使用部分
- 1.3.1、下载 demo 文件
- 1.3.2、安装 mim
- 1.3.3、使用目标检测工具
- 二、进阶作业
- 2.1、完成 AgentLego WebUI 使用
- 2.1.1、修改文件
- 2.1.2、启动服务器
- 2.1.3、建立客户端
- 2.1.4、使用 AgentLego WebUI
- 2.1.4.1、配置 Agent
- 2.1.4.2、配置 Tools
- 2.1.4.3、使用结果
- 2.2、使用 Lagent 实现自定义工具并完成调用
- 2.2.1、创建工具文件
- 2.2.2、获取 API KEY
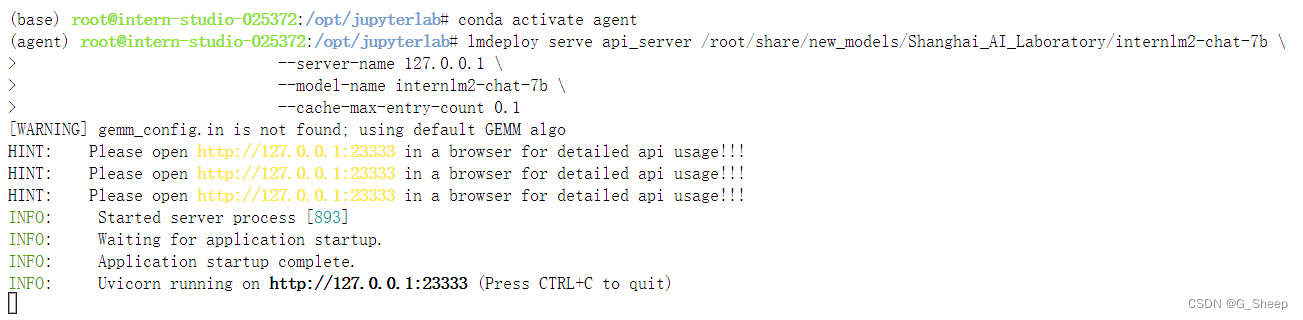
- 2.2.3、启动服务器
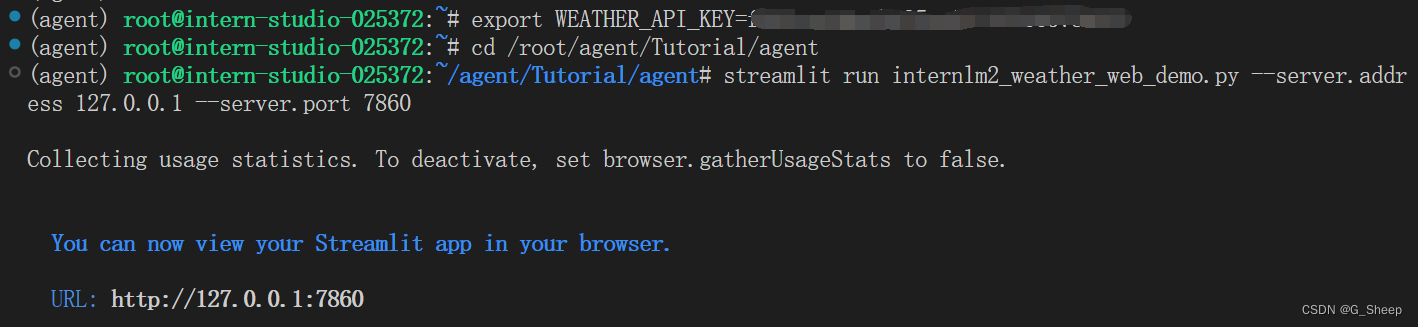
- 2.2.4、建立客户端
- 2.2.5、体验自定义工具
- 2.3、使用 AgentLego 实现自定义工具并完成调用
- 2.3.1、创建工具文件
- 2.3.2、注册新工具
- 2.3.3、启动服务器
- 2.3.4、建立客户端
- 2.3.5、设置 Agent
- 2.3.6、设置 Tools
- 2.3.7、使用结果
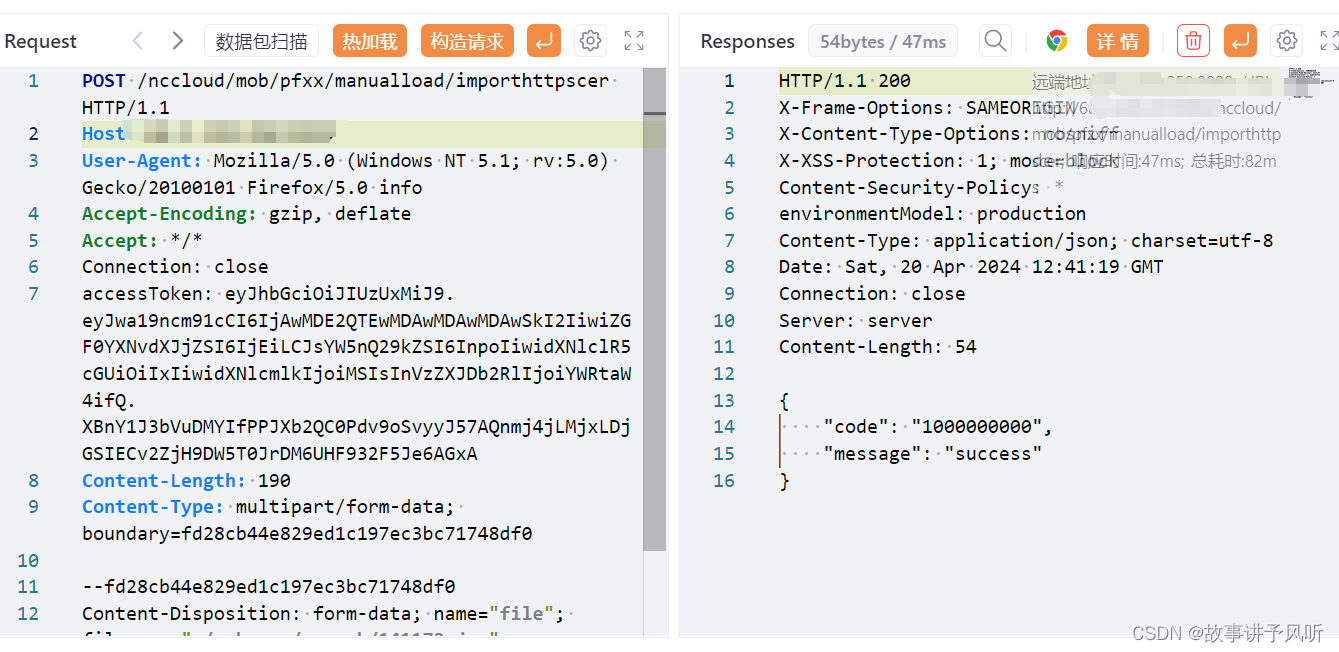
详细视频:Lagent & AgentLego 智能体应用搭建
详细文档:看这里
一、基础作业
1.1、前期准备
1.1.1、 配置基本环境

1.1.2、安装 Lagent 和 AgentLego
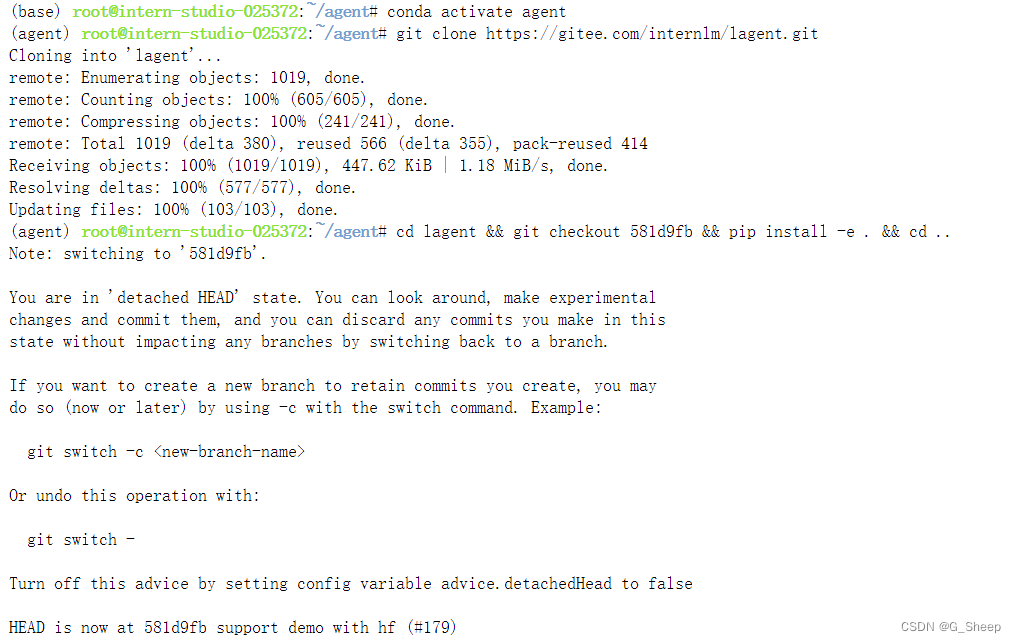
使用 git checkout 安装指定版本并 pip install -e . 安装所需要的包。
1.1.3、安装其他依赖
1.1.4、安装 Tutorial
1.2、完成 Lagent Web Demo 使用
1.2.1、启动服务端
1.2.2、建立命令行客户端
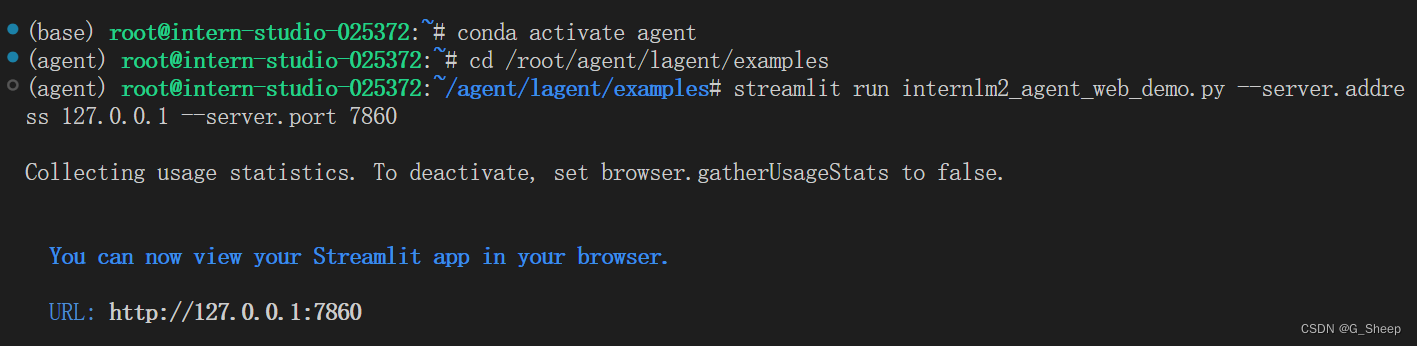
在此期间同时映射端口,就可以打开 127.0.0.1:7860 网页使用 Lagent Web Demo。
注意:前几次的作业都没说,这里注意一下,一定要输入网址并打开,不要使用 terminal 窗口这边跳出的网址,点进去是能打开,但会出现样式丢失的情况。
1.2.3、使用 Lagent Web Demo
对于 attention 改进这方面有了解的话,一定都知道 Rethinking Attention with Performers 这篇文章,所以我也想测试能不能搜寻的到。
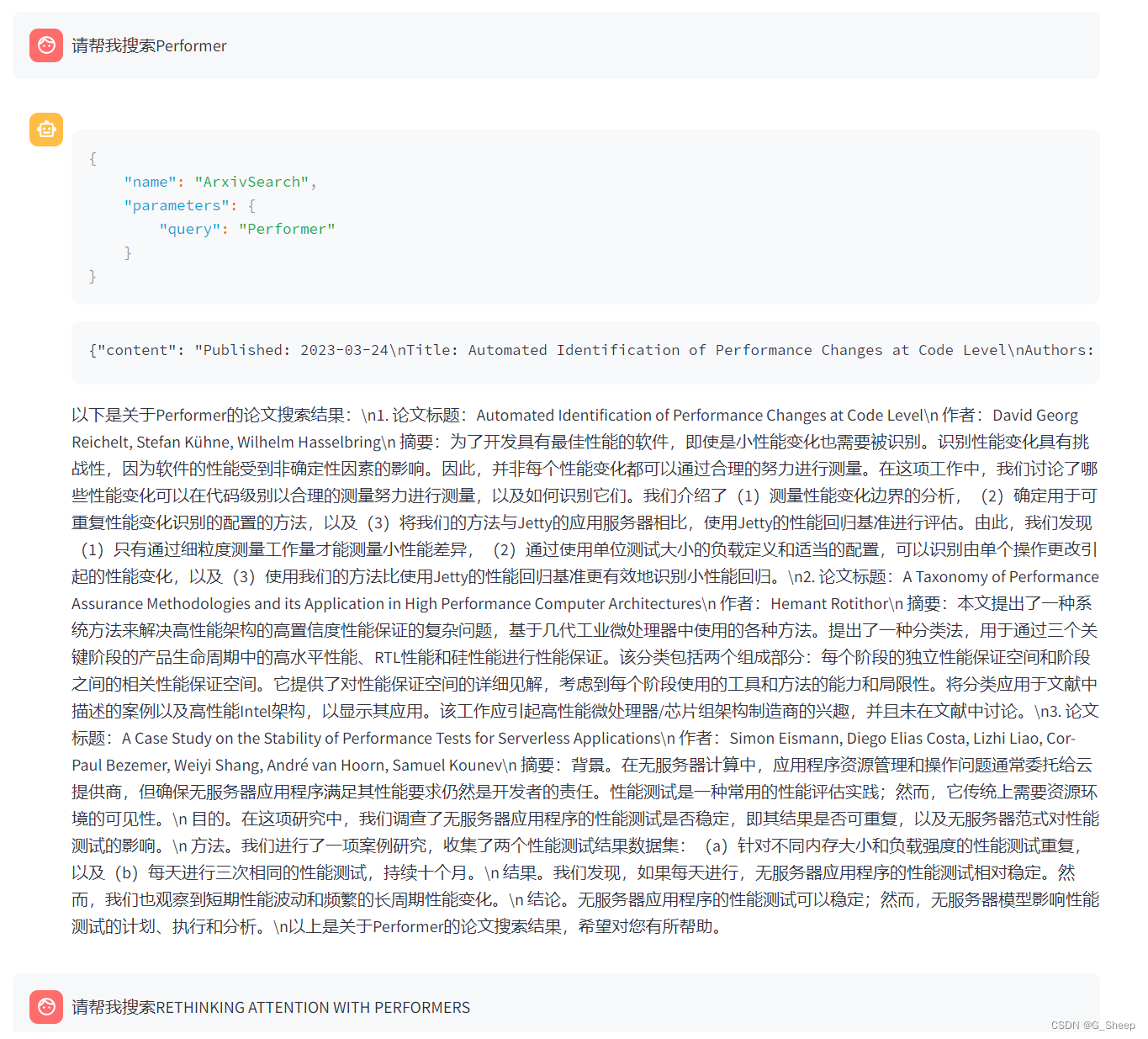
第一次搜索结果是没有我想要的这篇文章的,我觉得也是,可能是我表示的不太清楚,一个 Performer 太笼统了,所以我试着直接搜索名字。
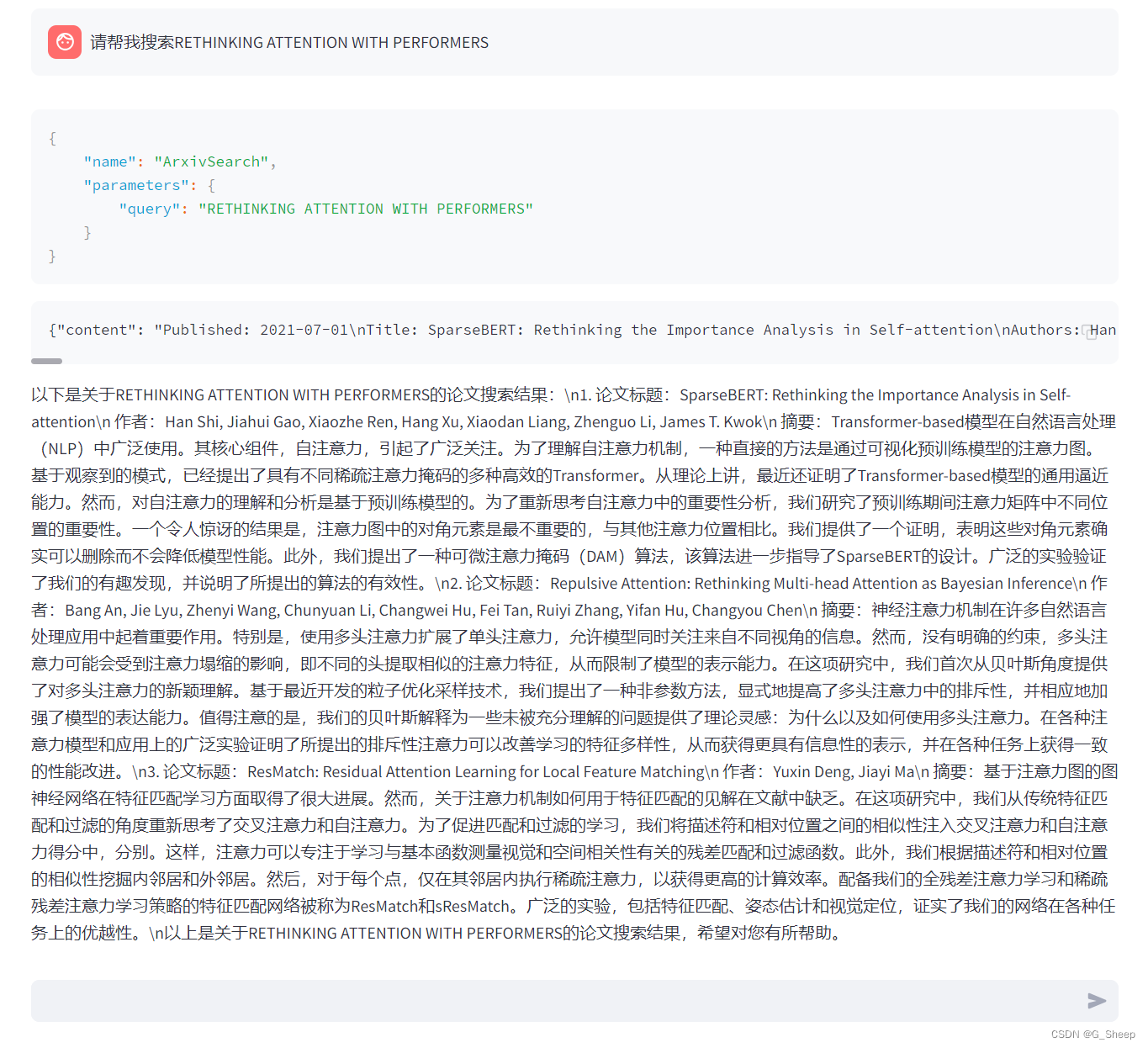
结果还是没有搜寻到我想要的文章,我就觉得有点不对劲了,然后我想是不是因为区分大小写,于是又搜寻了一遍。

这次是确实不理解了,我已经给出了非常详细的名字,严格控制间距和大小写,但依然给出了不相关的答案。不死心,又试了教程的案例。
黑人脸。。。what can i say? 就很奇怪,搜索 internlm 相关文章就直接有了,我随便一个其他的就是没有,然后我又搜了一次。

不知道出了什么问题。。。
1.3、完成 AgentLego 直接使用部分
1.3.1、下载 demo 文件

1.3.2、安装 mim
AgentLego 所实现的目标检测工具是基于 mmdet (MMDetection) 算法库中的 RTMDet-Large 模型,因此我们首先安装 mim,然后通过 mim 工具来安装 mmdet。这一步所需时间可能会较长,请耐心等待。

安装过程中会报错,但是不用理会,后面能够正常使用。
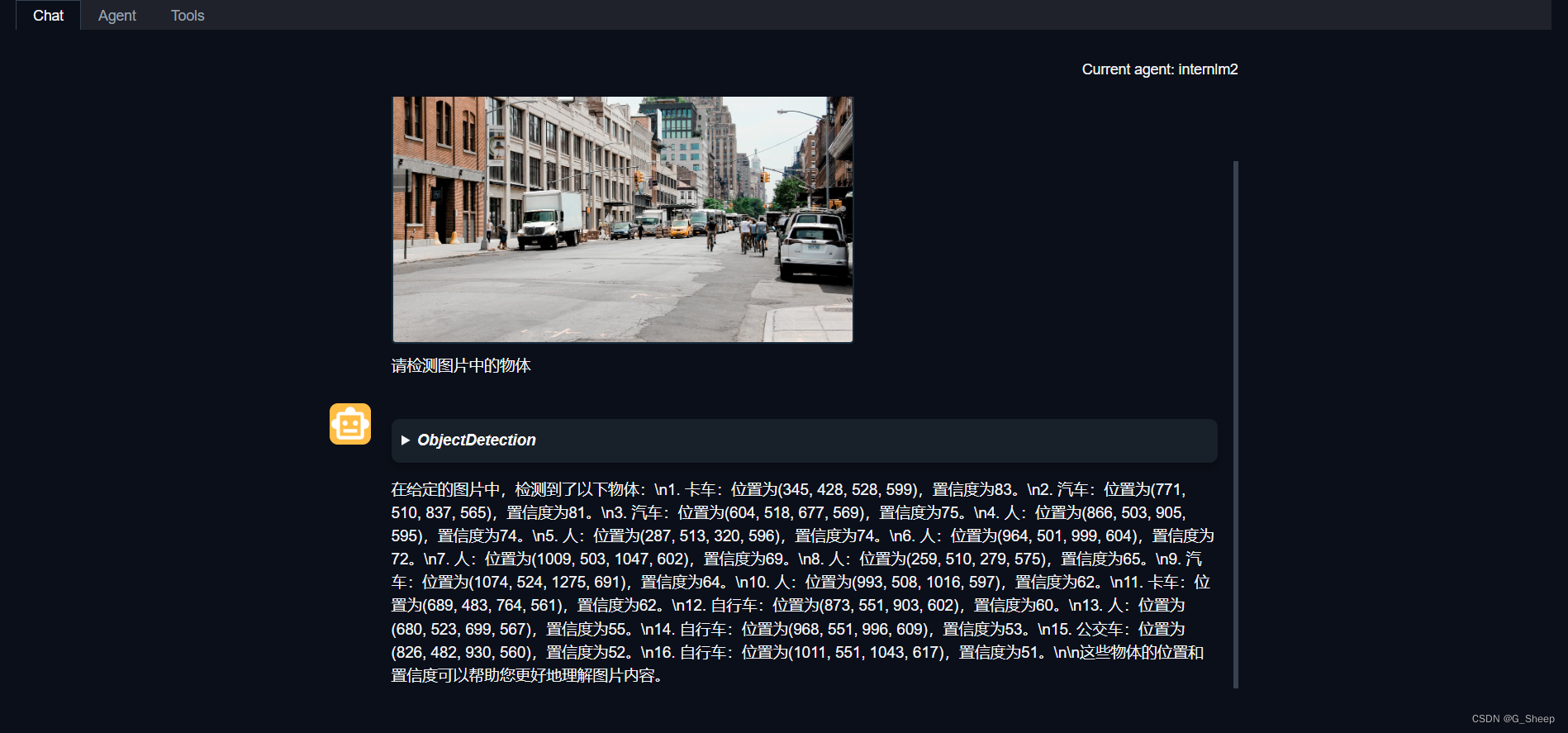
1.3.3、使用目标检测工具
创建 direct_use.py 文件。
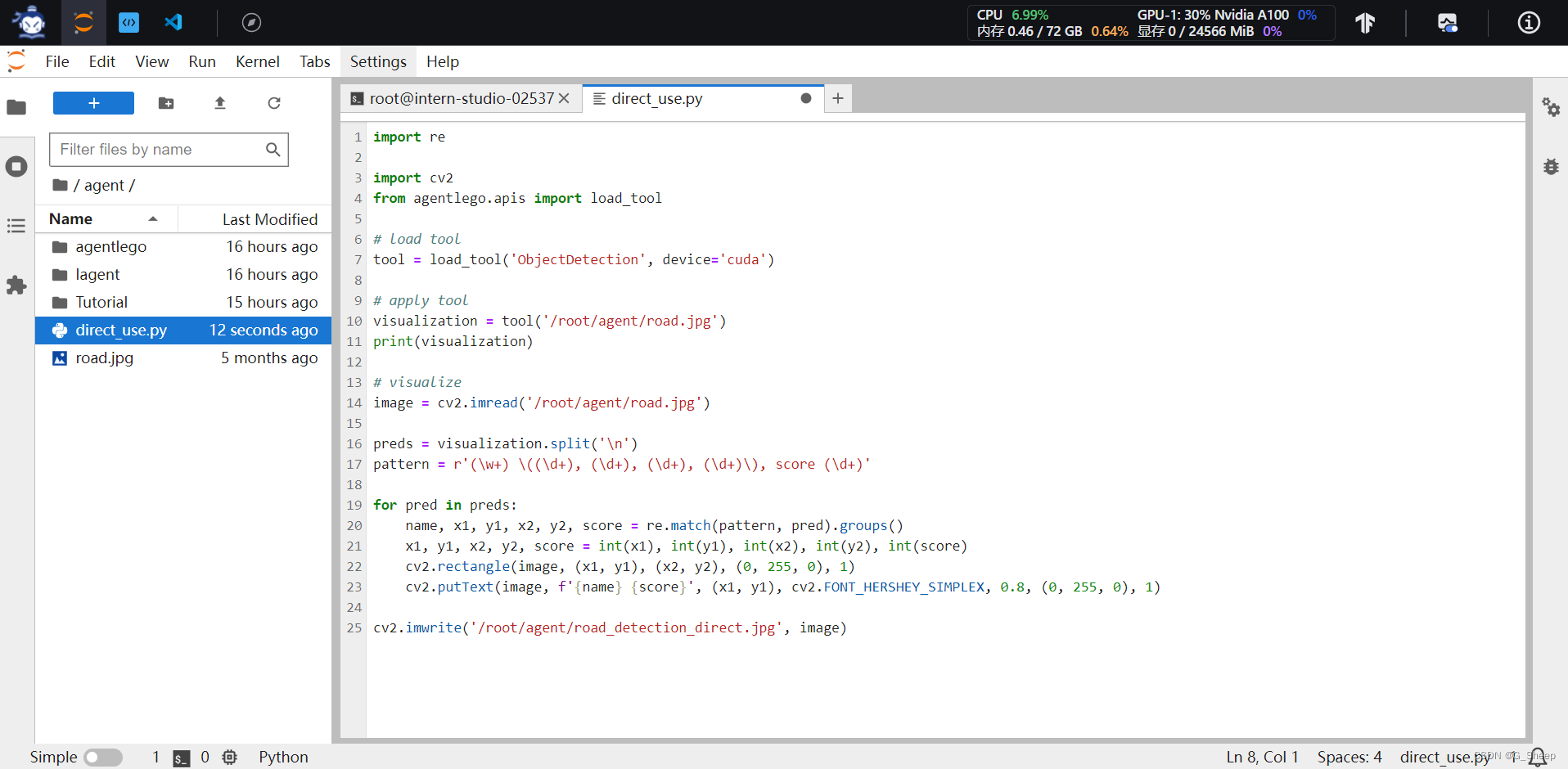
这段代码的核心主要是通过使用 ObjectDetection 这个工具来分析图片,正则表达式 pattern = r'(\w+) \((\d+), (\d+), (\d+), (\d+)\), score (\d+)' 用于解析给定格式的文本,以提取物体的名称、边界框的坐标和检测的置信分数,最后再使用 OpenCV 绘制矩形并添加相应文本。
文件运行结果如下图所示:
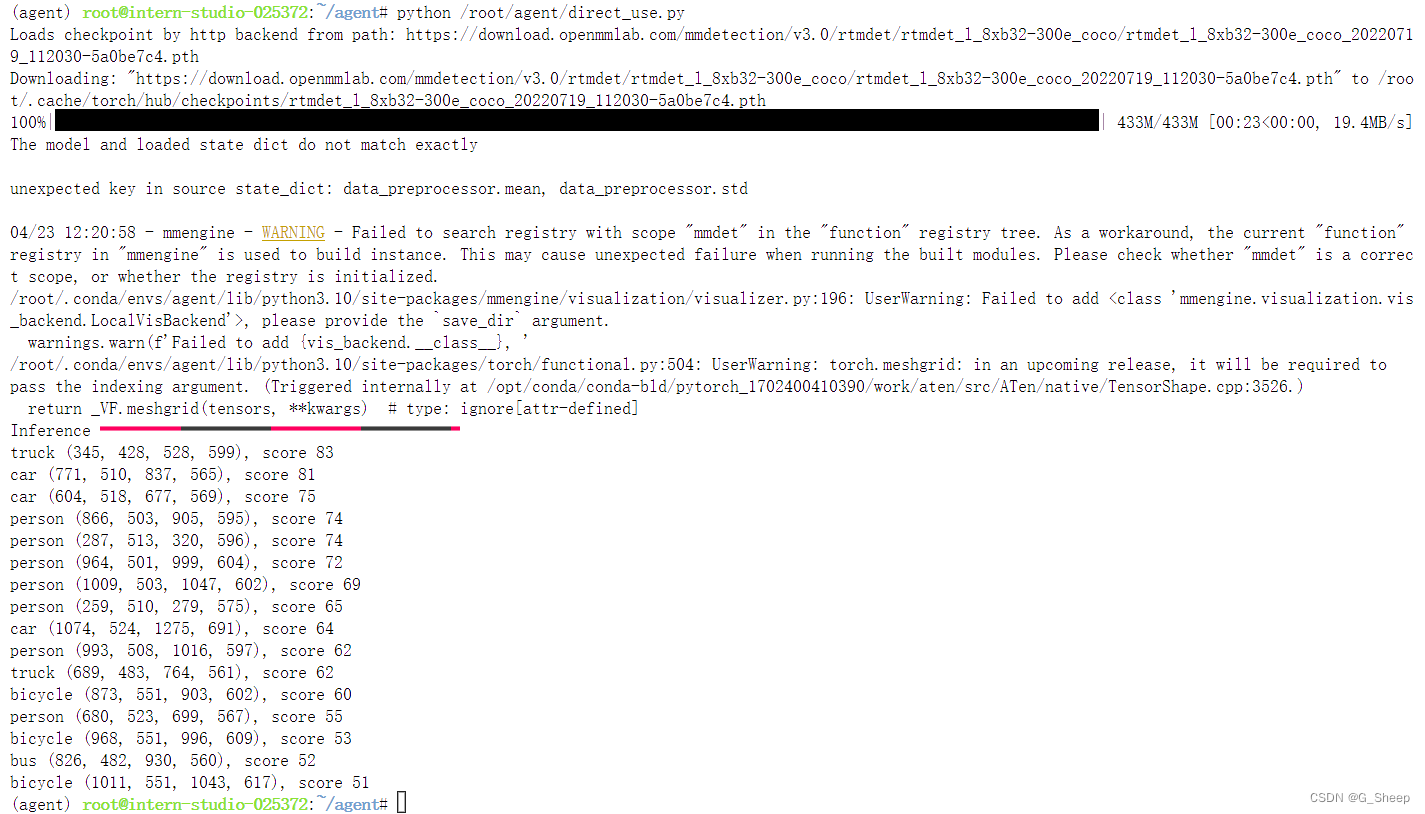
同时,结果还生成了一张修改后的图片。
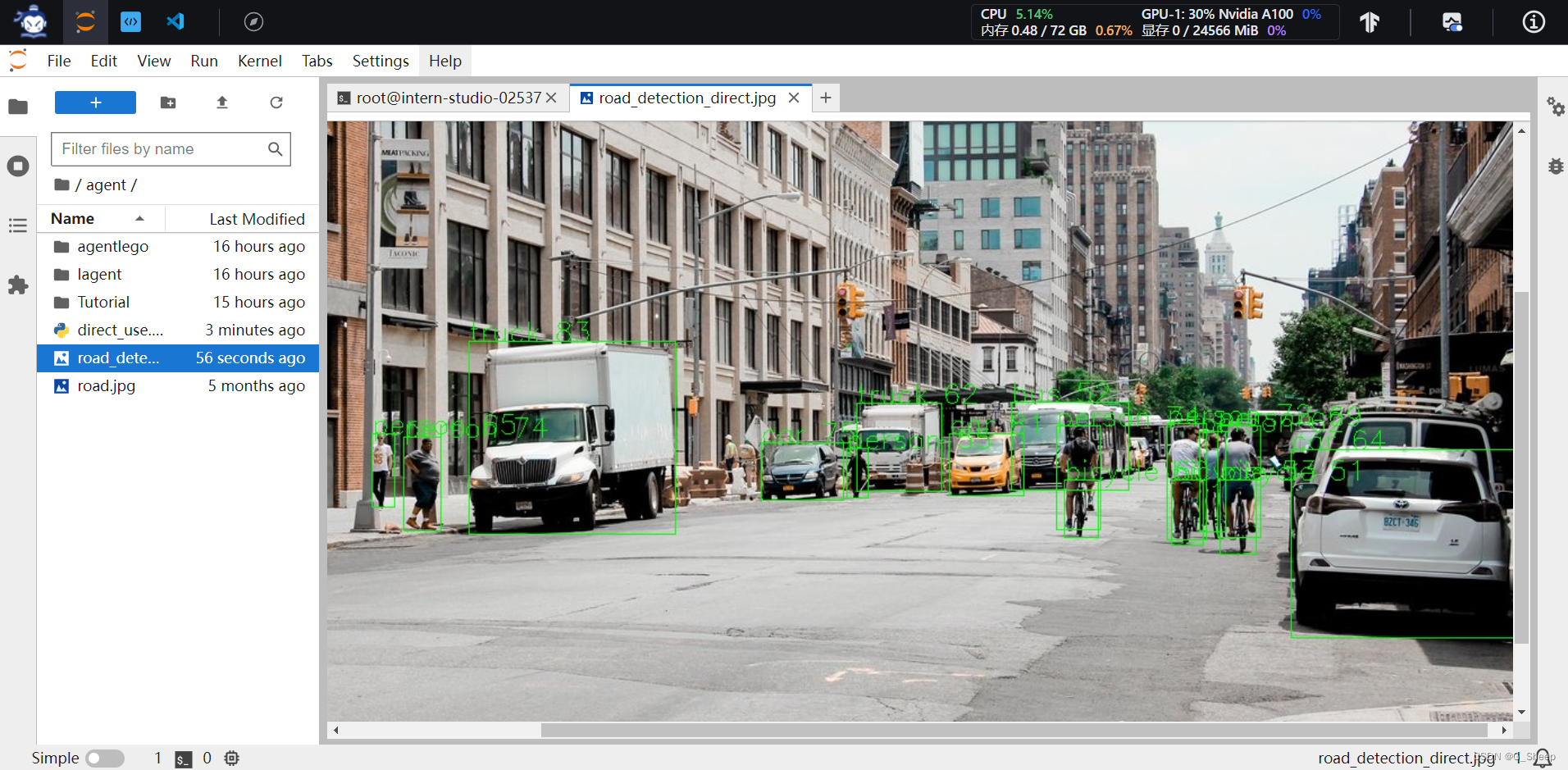
这种方式就比较直观地能看出结果,ObjectDetection 工具对于这种简单图片的识别还是很准确的。
二、进阶作业
2.1、完成 AgentLego WebUI 使用
2.1.1、修改文件
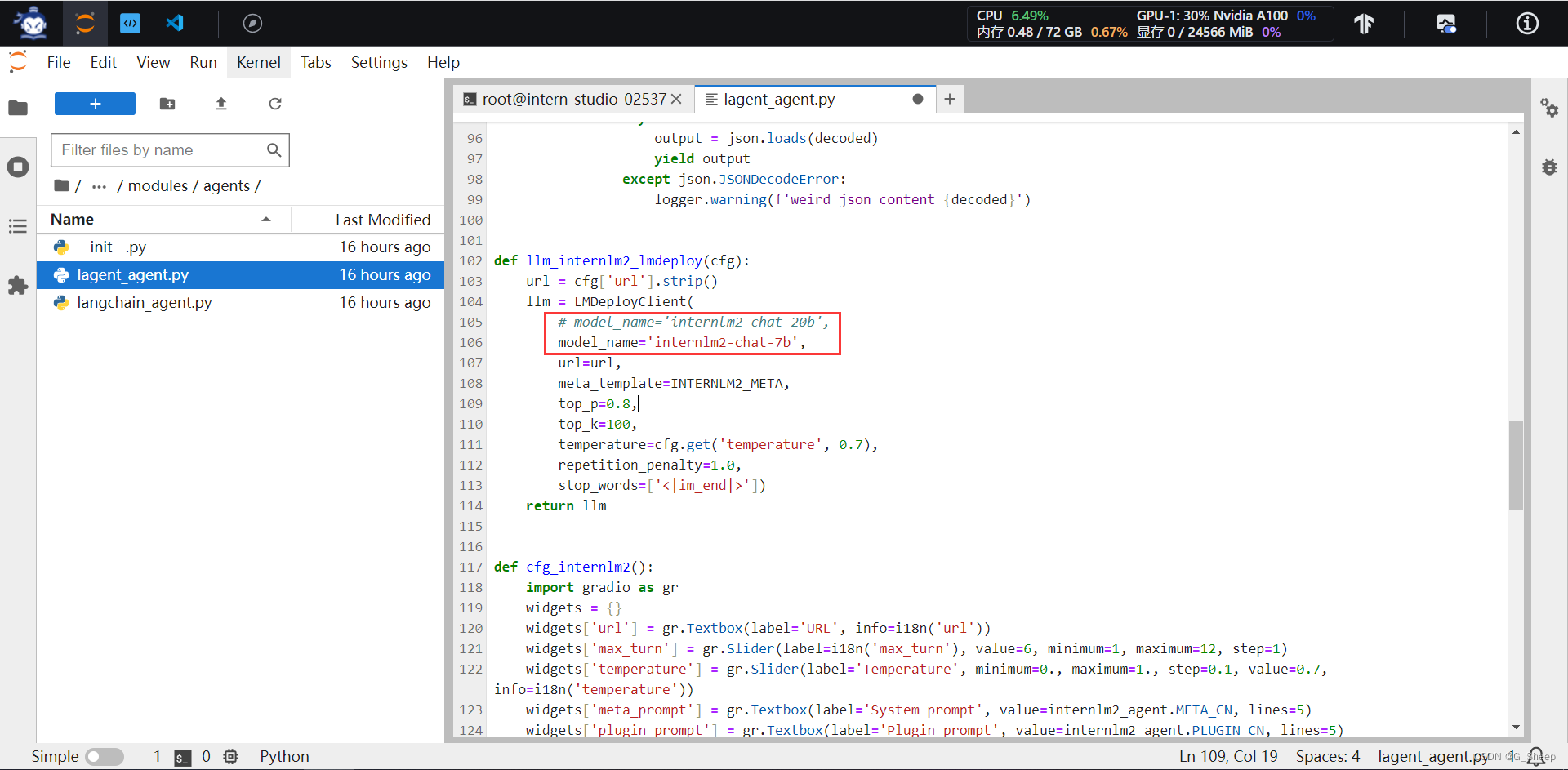
由于 AgentLego 算法库默认使用 InternLM2-Chat-20B 模型,因此我们首先需要修改 /root/agent/agentlego/webui/modules/agents/lagent_agent.py 文件的第 105行位置,将 internlm2-chat-20b 修改为 internlm2-chat-7b,即
2.1.2、启动服务器
2.1.3、建立客户端
2.1.4、使用 AgentLego WebUI
2.1.4.1、配置 Agent
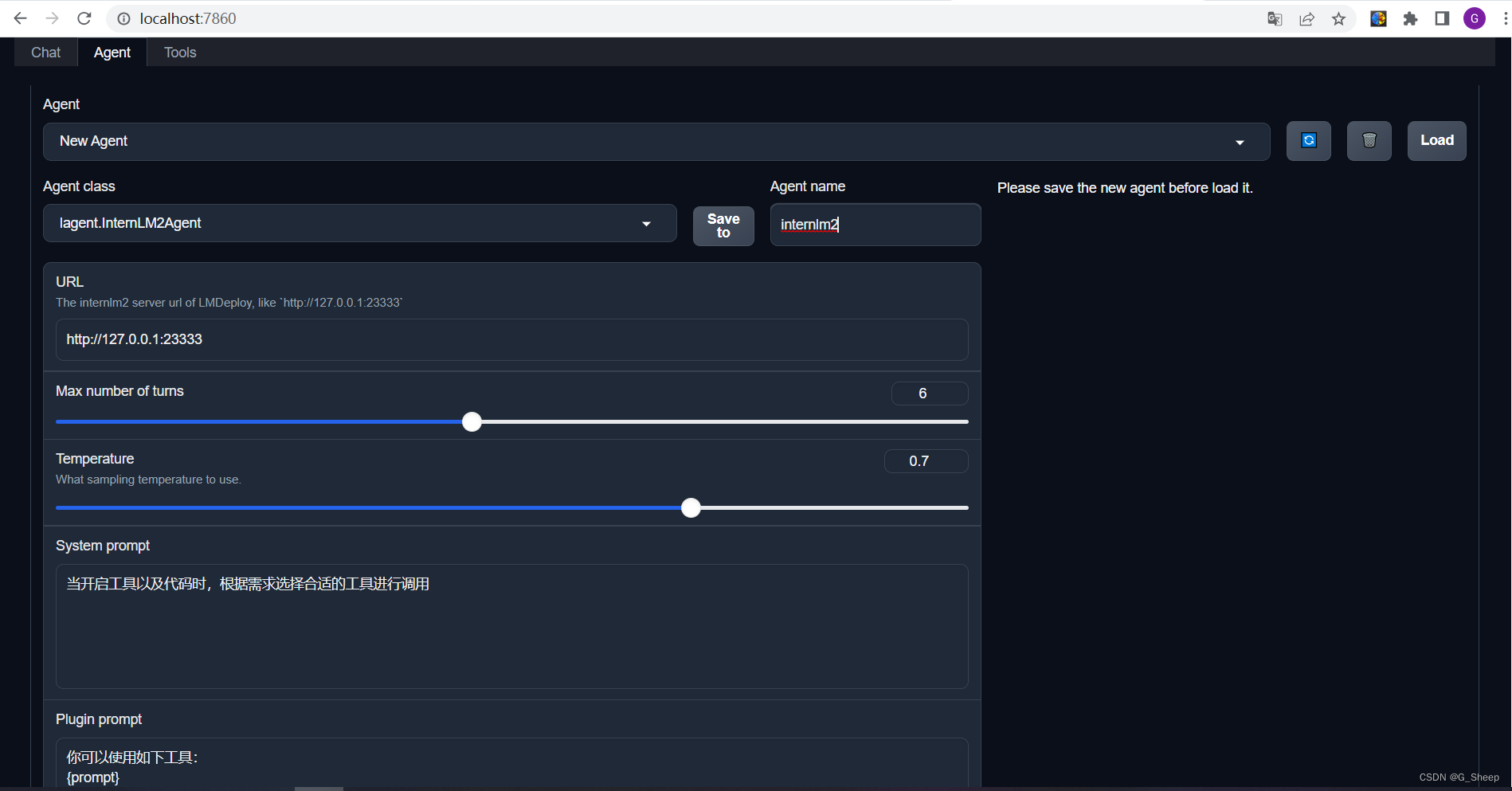
2.1.4.2、配置 Tools
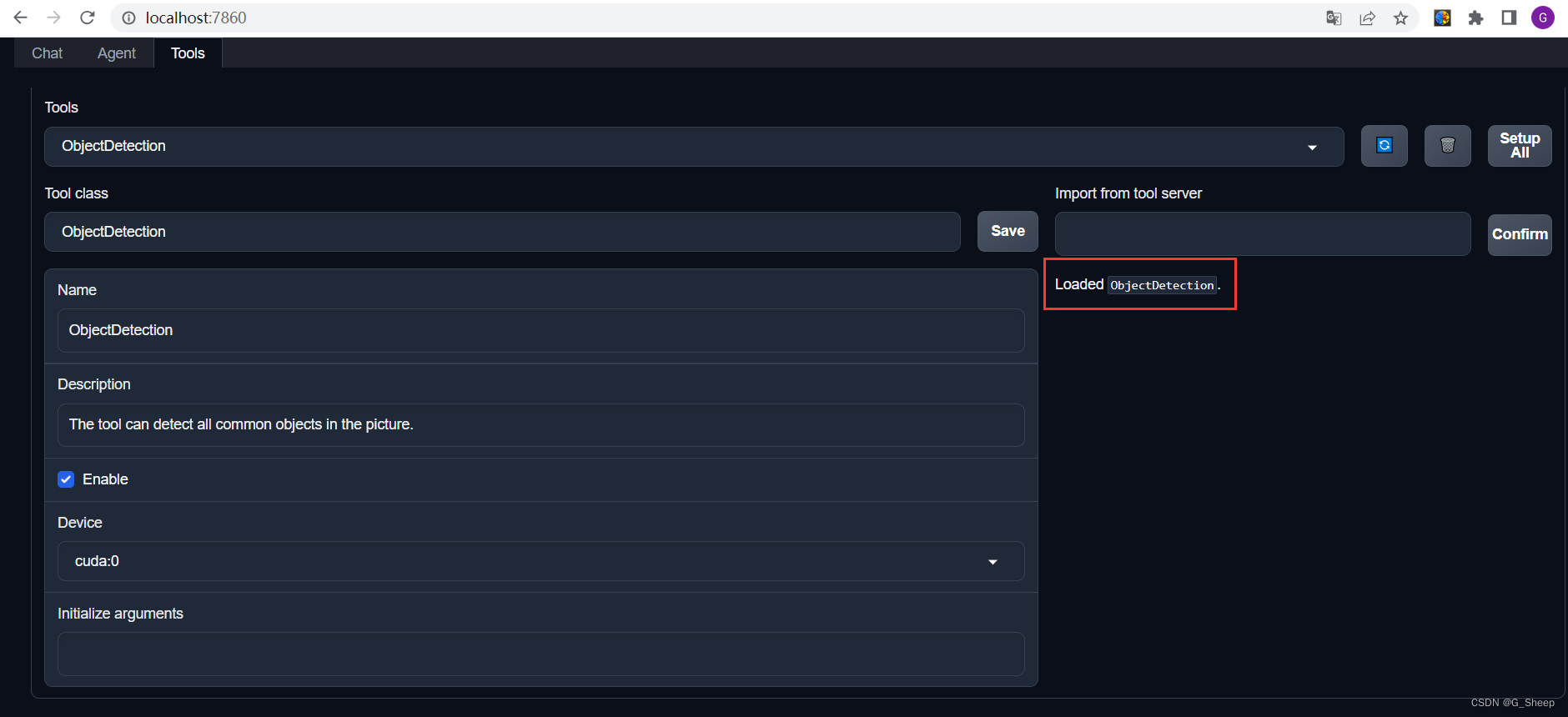
2.1.4.3、使用结果
首先,在 Chat 界面选择工具部分选择 ObjectDetection 工具,为了确保调用工具的成功率,在使用时确保仅有这一个工具启用。
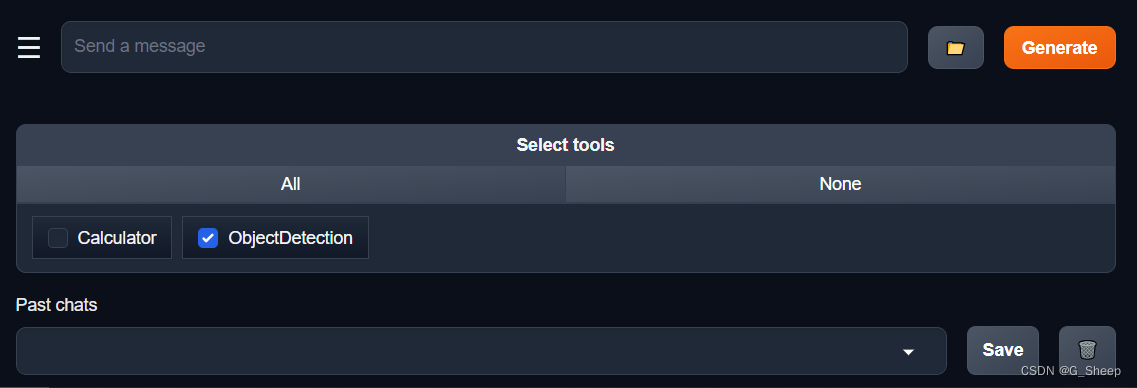
然后再次检测刚刚的 road 图片。
效果还可以,但我觉得这个图片难度有点低,所以去网上找了一个稍微负责的图片,命名为 complex,先修改文件的对应位置。
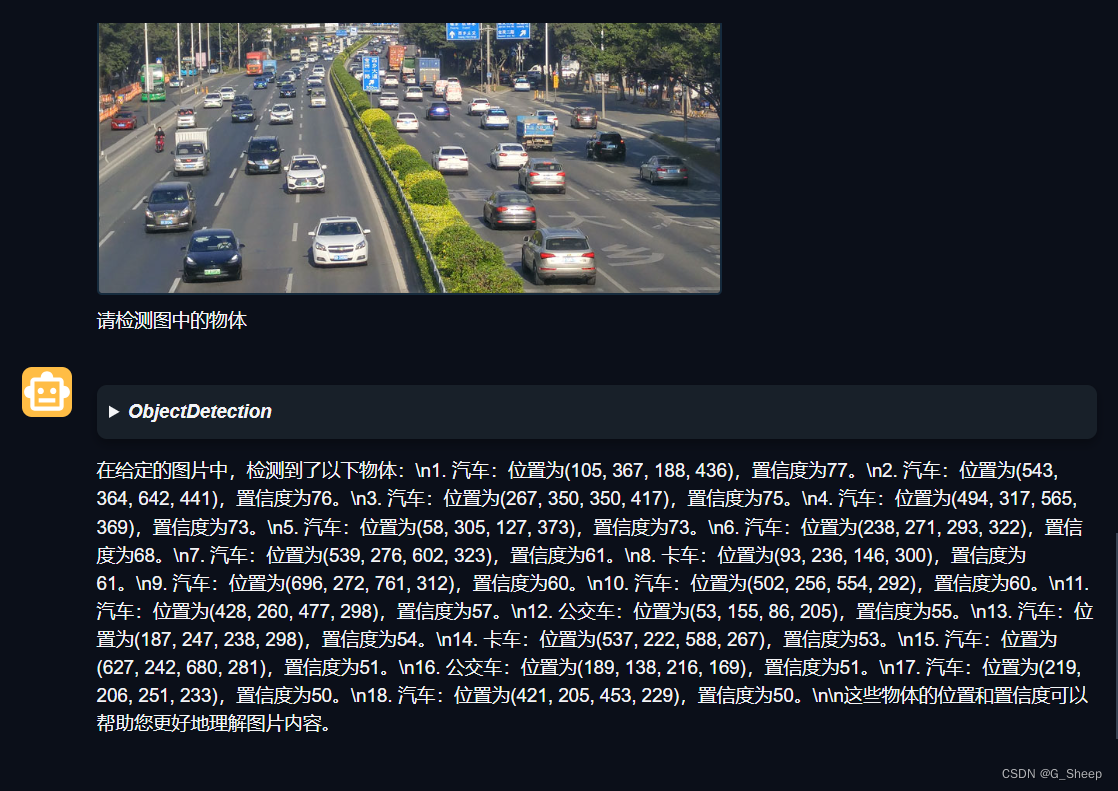
如上图所示,回复肯定是回复了,但只有冰冷的数字并不能看到具体的效果,也不知道结果怎么样,所以还是又直接使用 AgentLego 查看生成的图片结果。
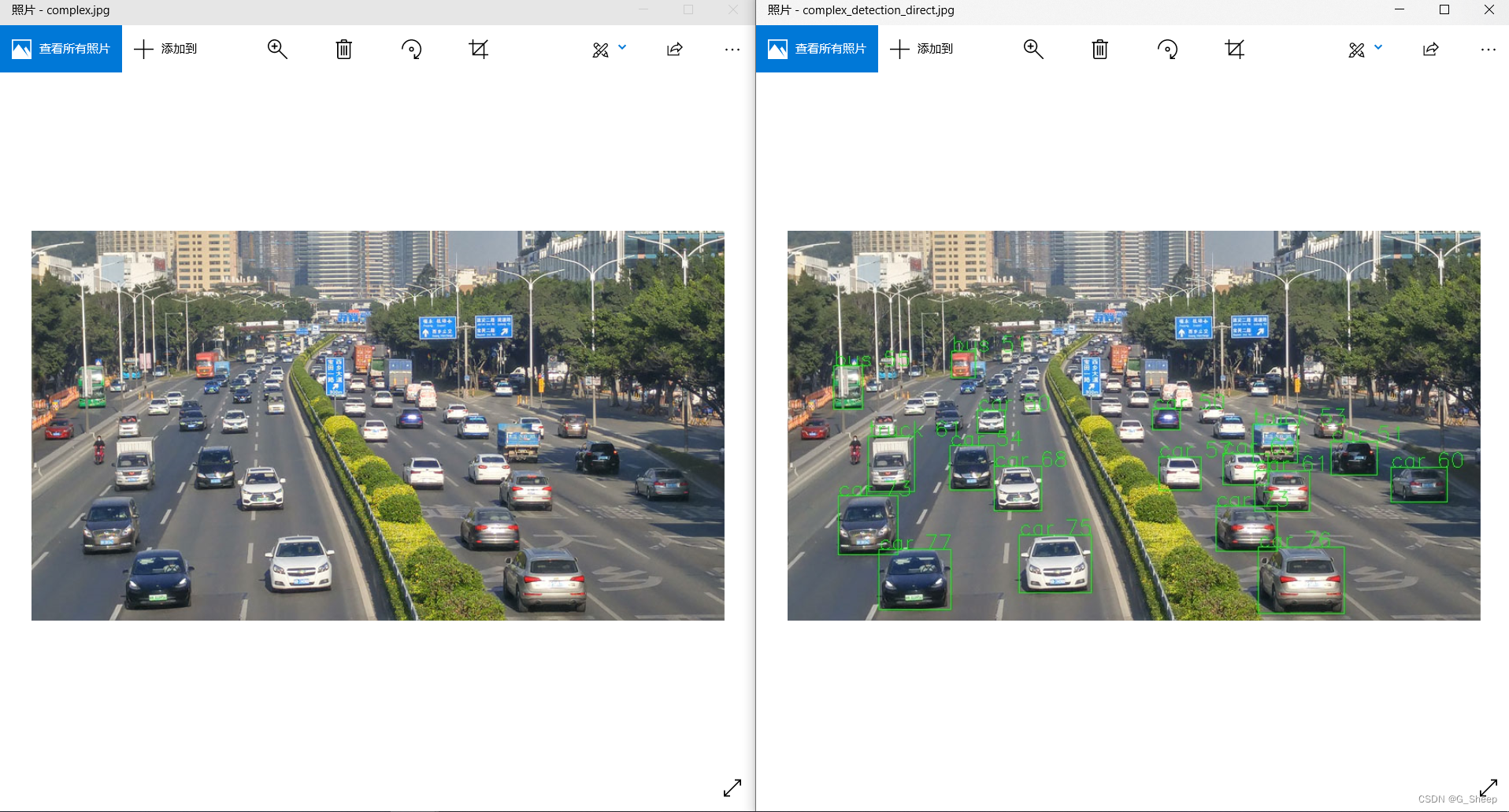
只能说结果一般,对于图片中离我们近的车辆大部分都可以识别出来,但是后面的车辆计划几乎就全军覆没了,只能说这个 ObjectDetection 工具还是有待改进。
2.2、使用 Lagent 实现自定义工具并完成调用
2.2.1、创建工具文件
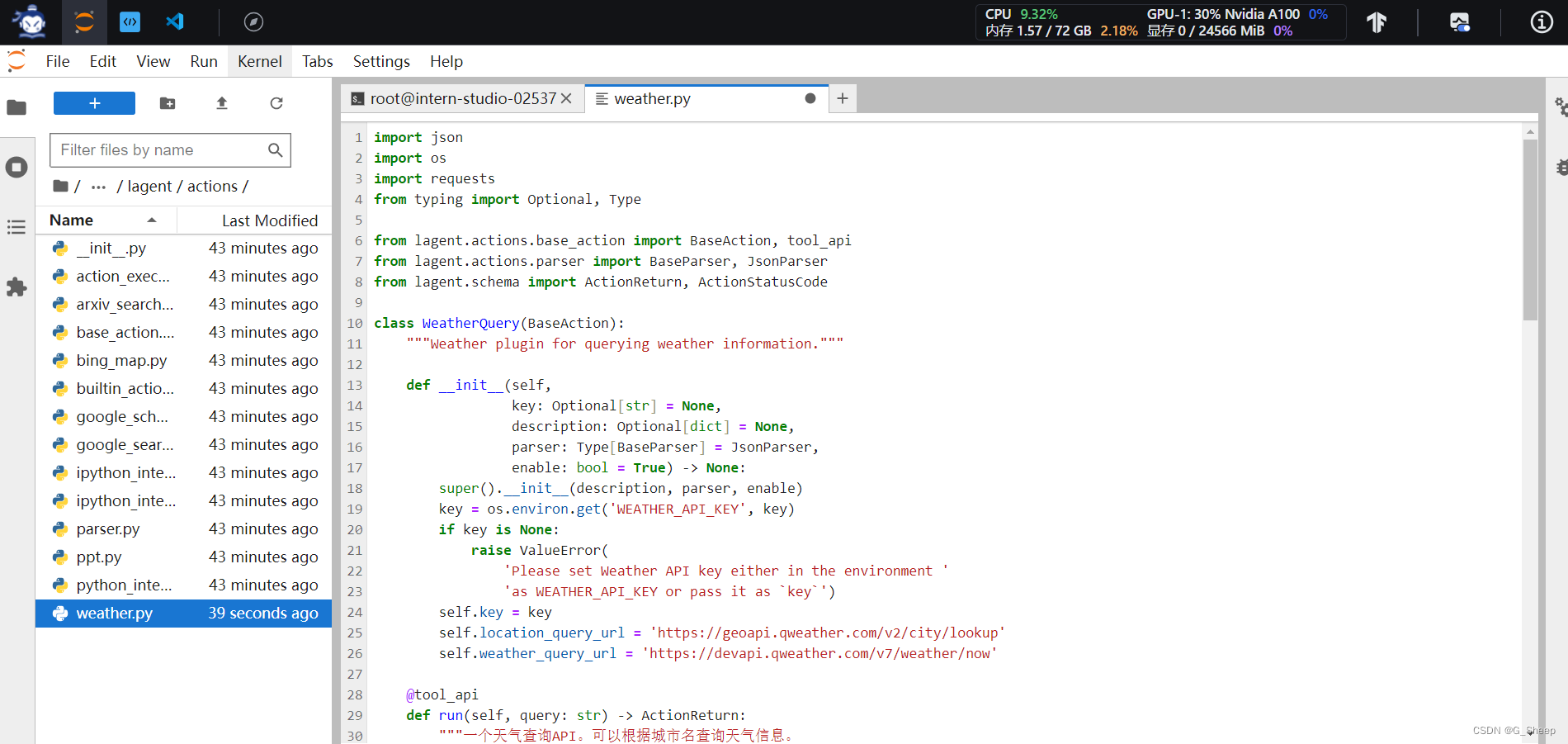
2.2.2、获取 API KEY
2.2.3、启动服务器
2.2.4、建立客户端
2.2.5、体验自定义工具
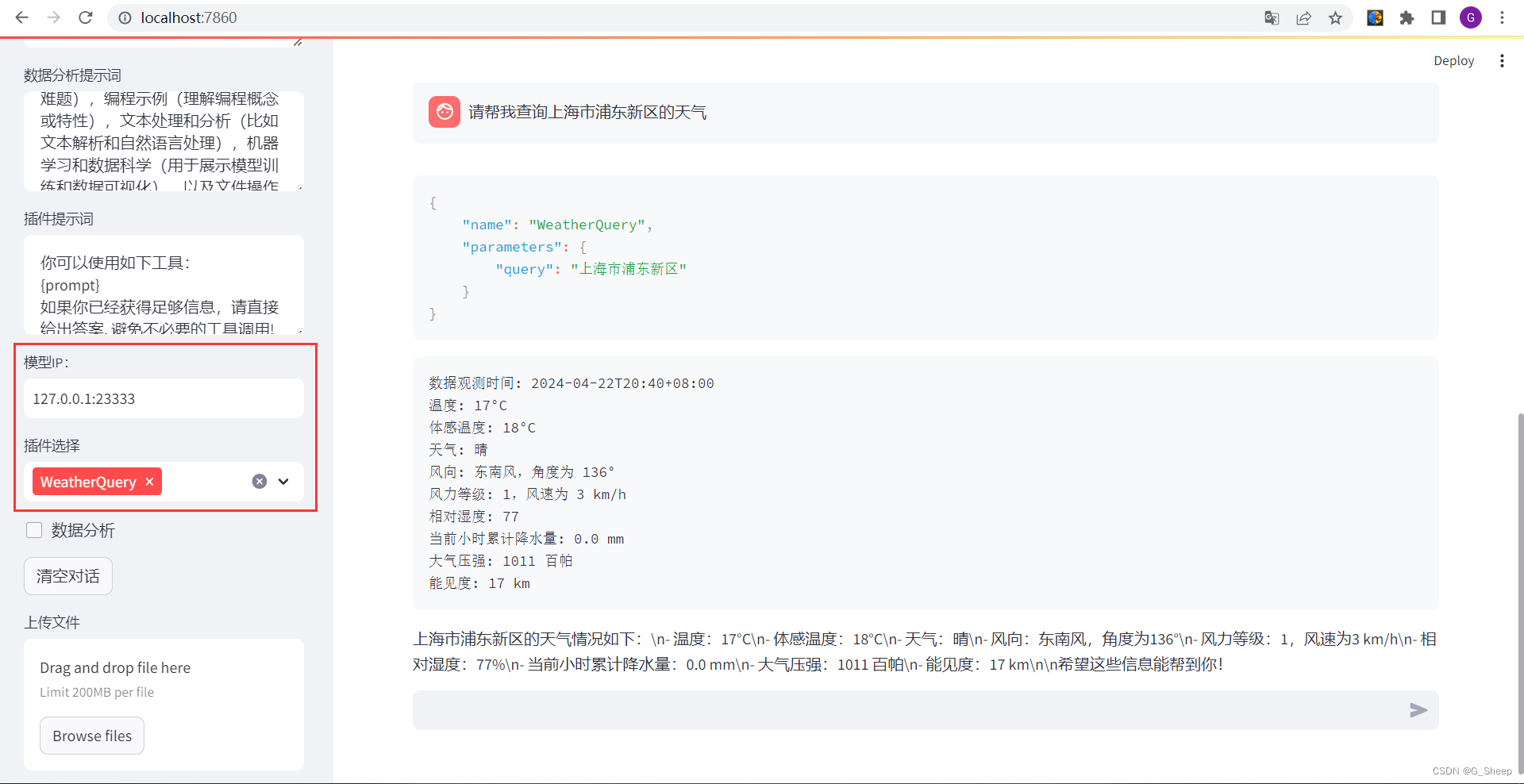
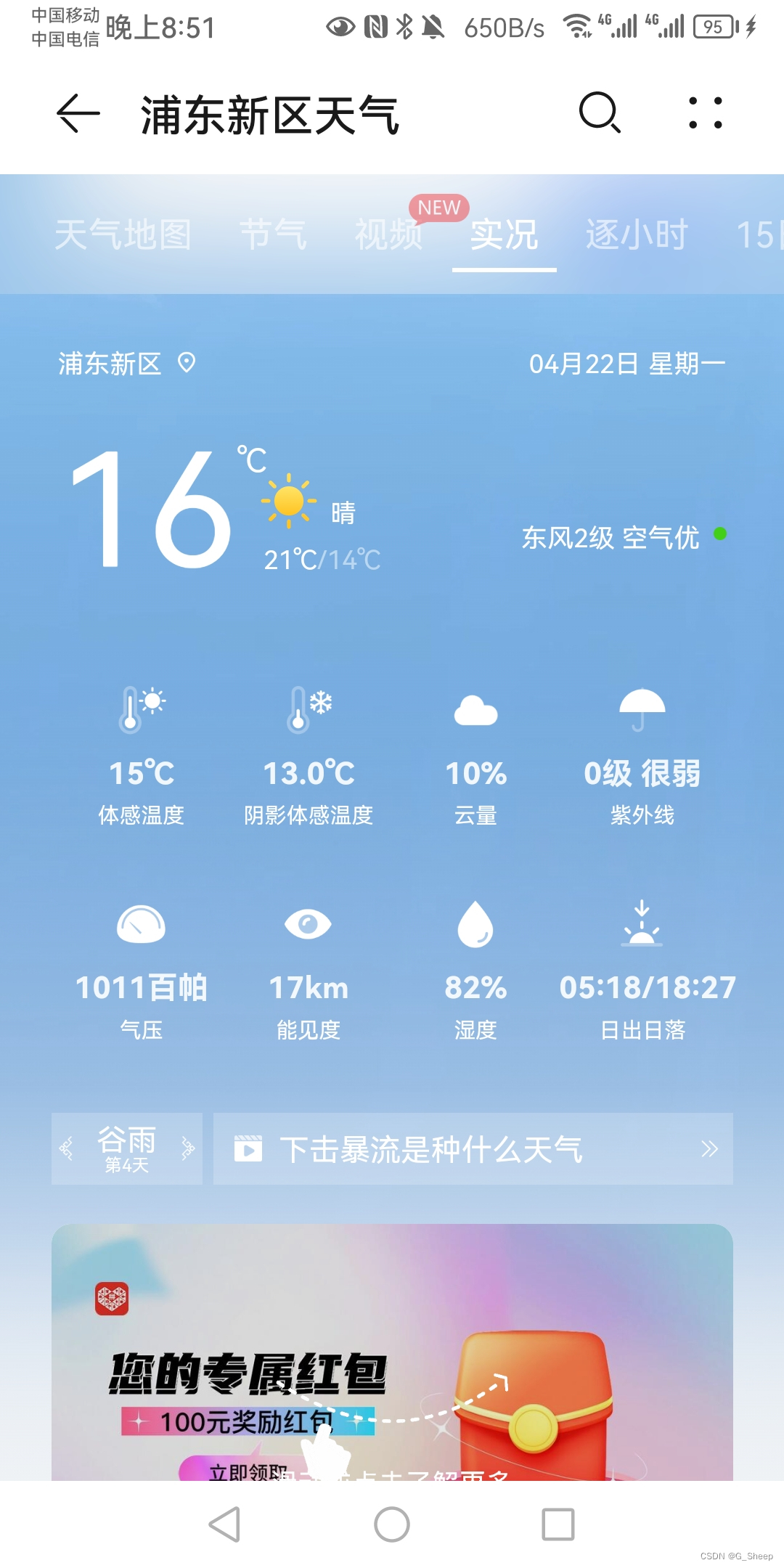
首先查询了上海市浦东新区的天气,同时对比了当时手机上的天气,可以看得出来,结果还是非常准确的。
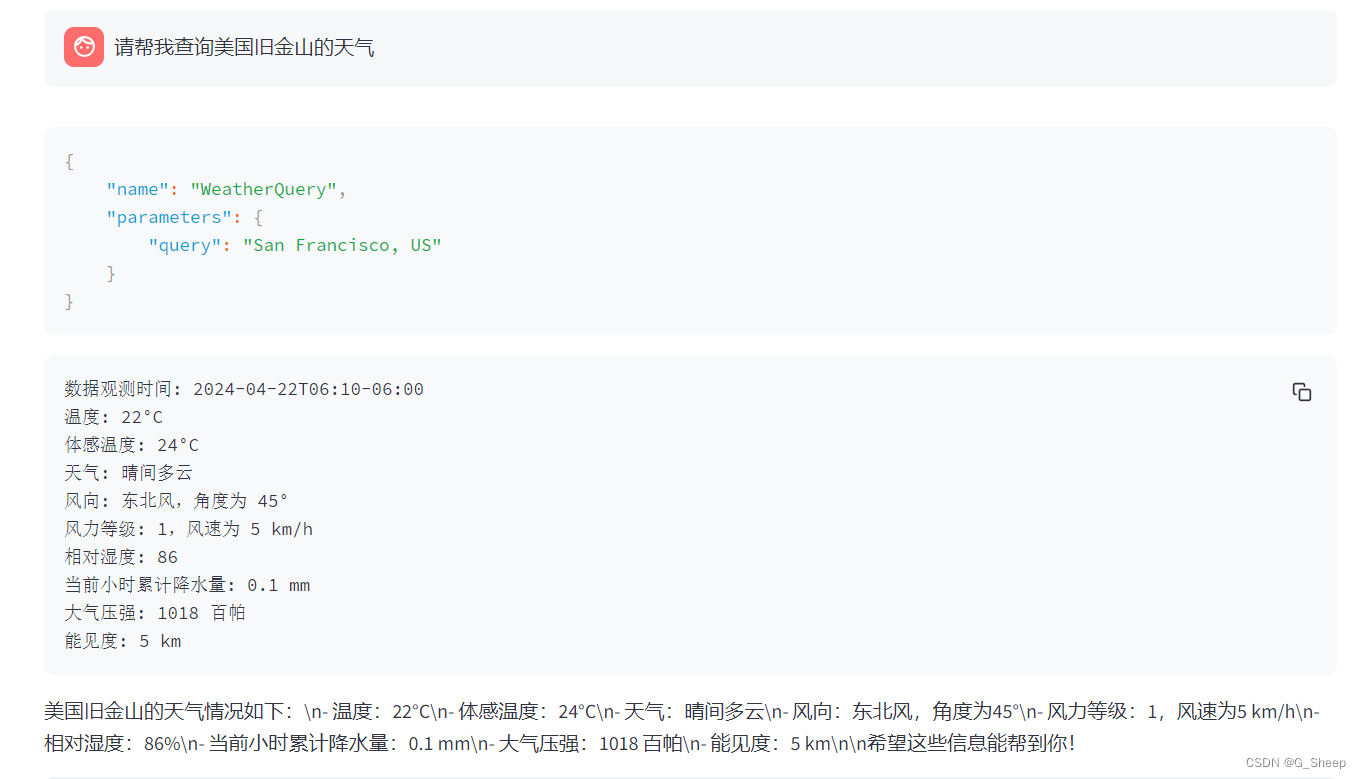
查询美国的天气也能及时准确地回复。
下面我想测试下,当输入的查询城市名字不对时,会作出如何回复。
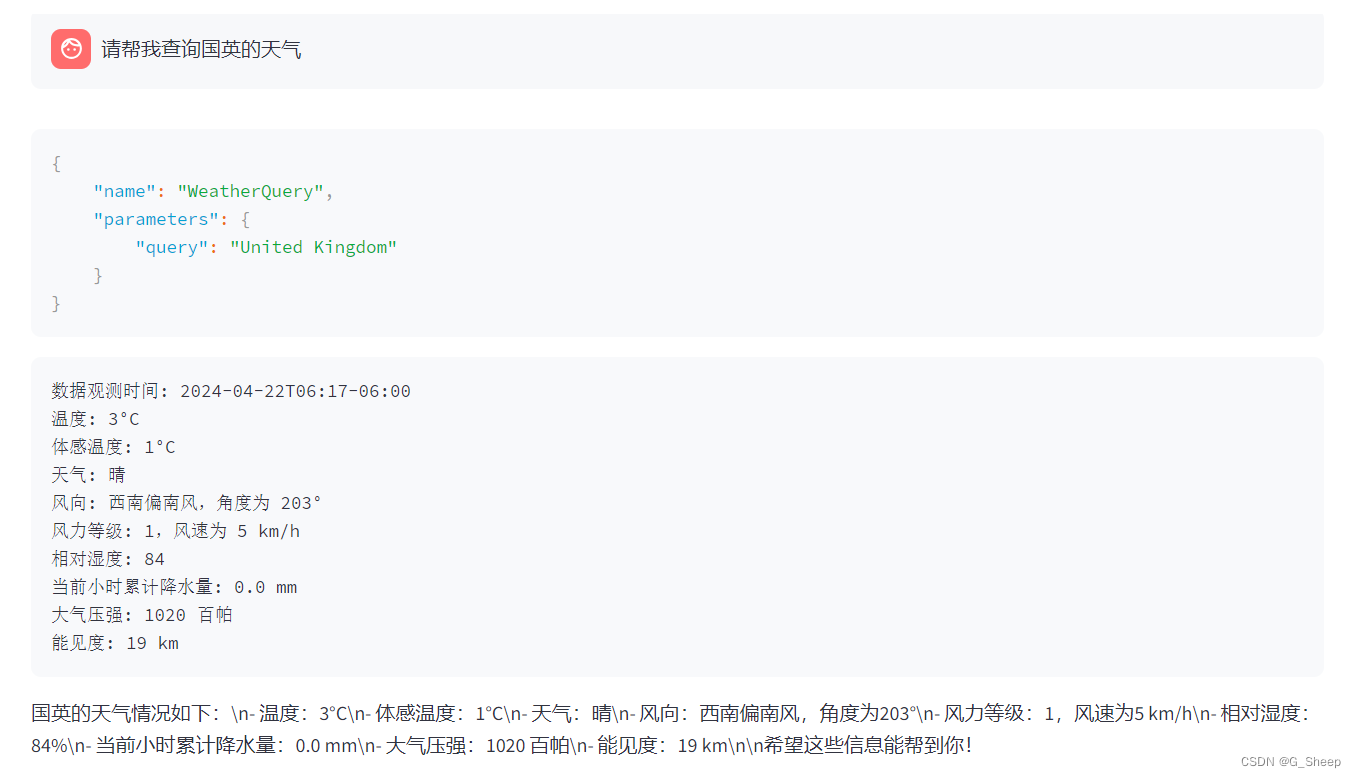
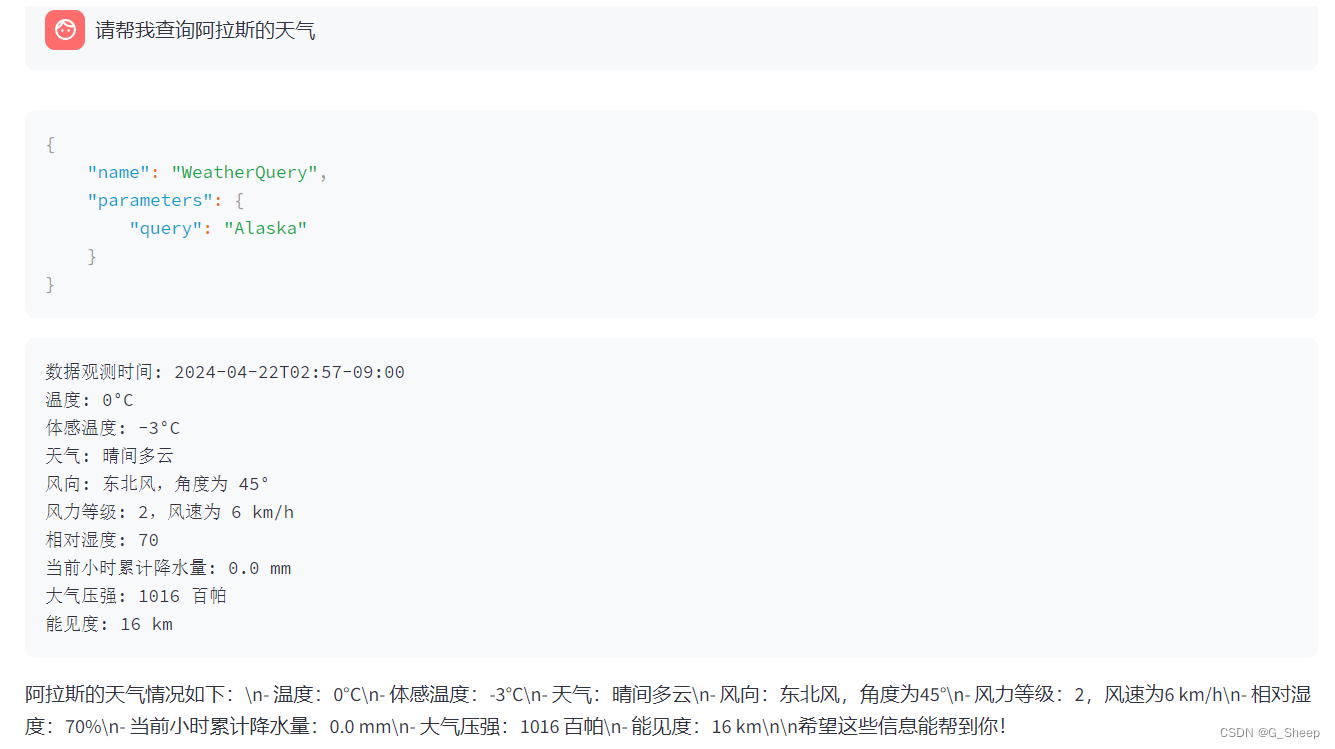
这个地方是非常出乎意料的,我故意打打反了英国的名称,阿拉斯加也少了一个字,但依然能迅速准确地回答。
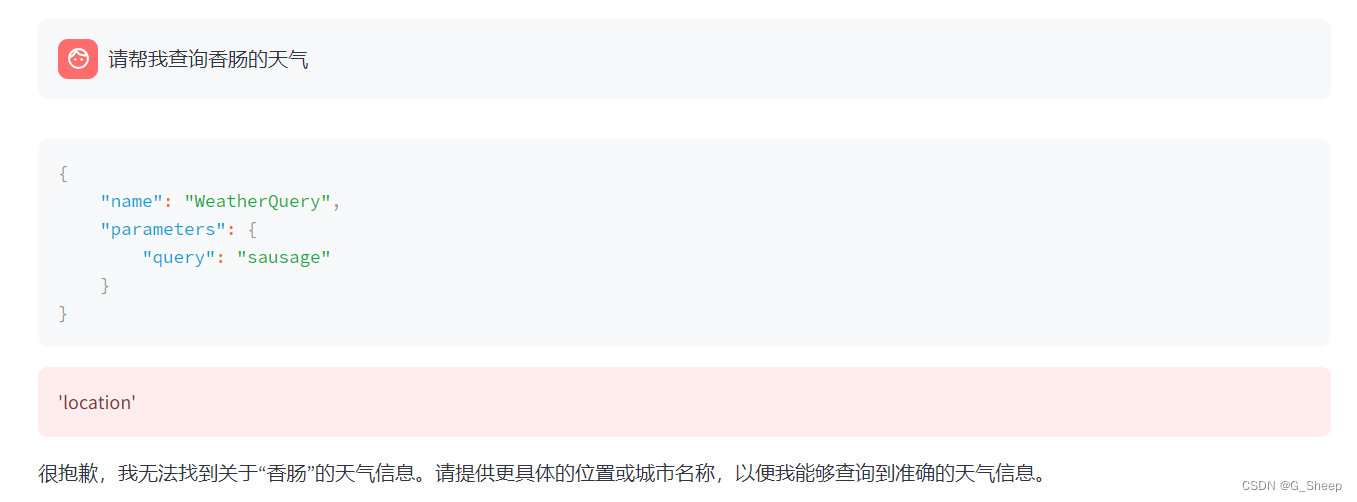
只有当我问出足够离谱的城市天气时,才会识别错误,这个界限其实就很模糊,因为我个人觉得打错城市名字应该已经算不能识别的城市了,只能说可能确实有的人会喜欢这样的效果。
2.3、使用 AgentLego 实现自定义工具并完成调用
2.3.1、创建工具文件
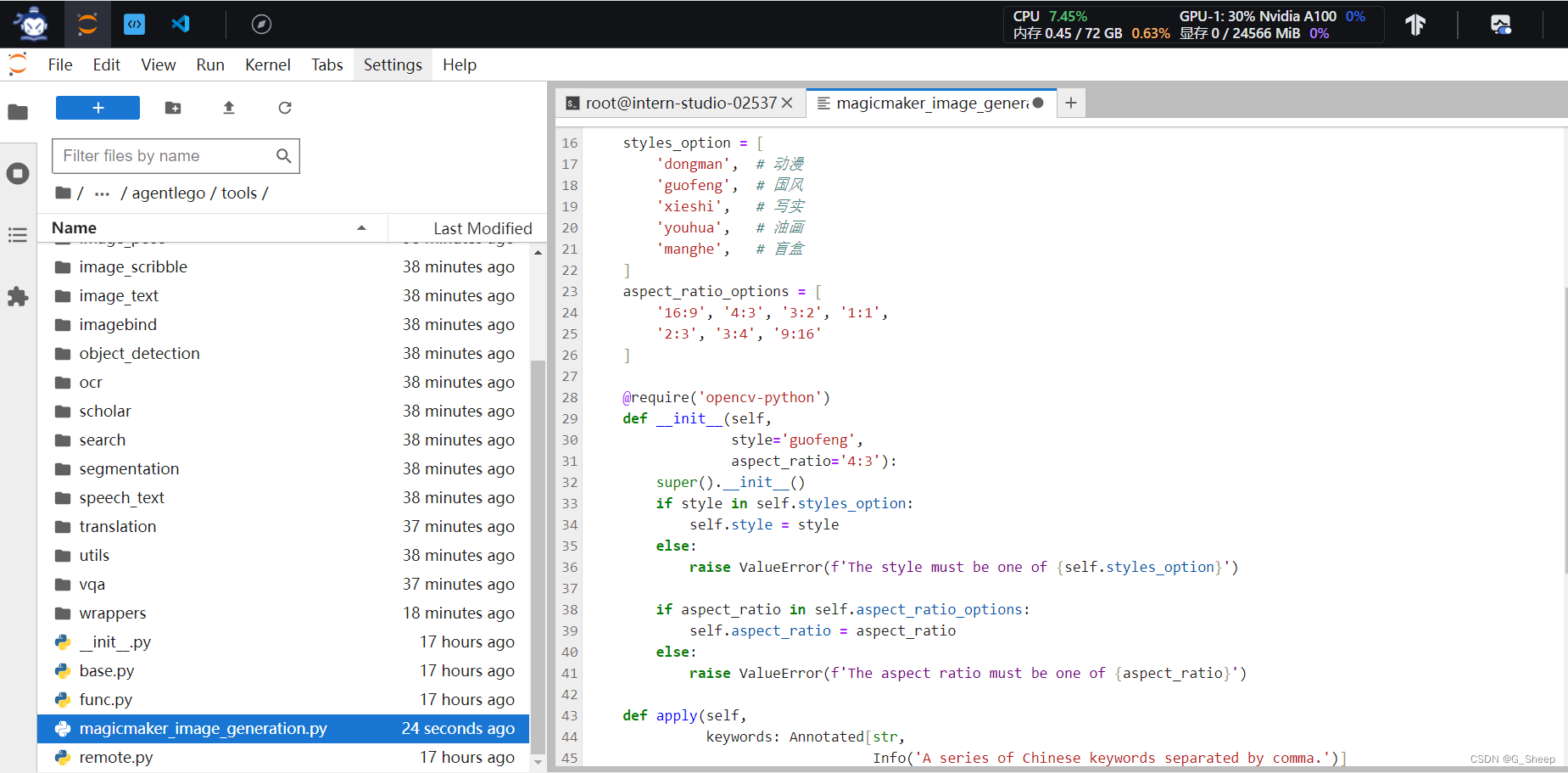
这段代码主要是定义了一个名为 MagicMakerImageGeneration 的类,这个类继承自 BaseTool 类,其中设置了两个属性 styles_option 来 和 aspect_ratio_options 来分别设置生成图像的图像分格和长宽比,同时,也定义了 apply 方法接受关键词作为参数,然后向 API 发起 POST 请求,以生成图像。
2.3.2、注册新工具
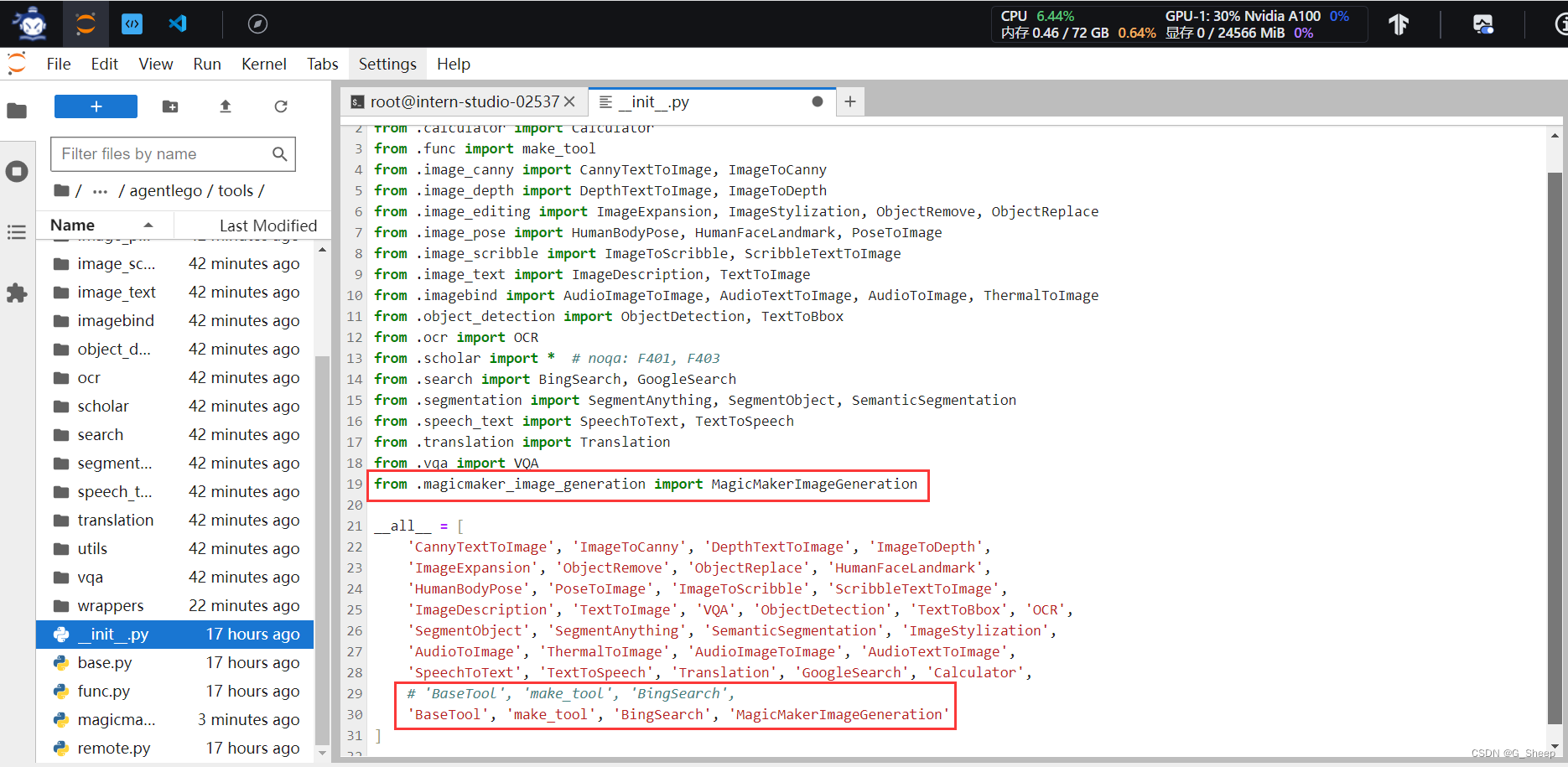
主要是讲刚刚创建的工具注册在工具列表中,以待后面使用。
2.3.3、启动服务器
2.3.4、建立客户端
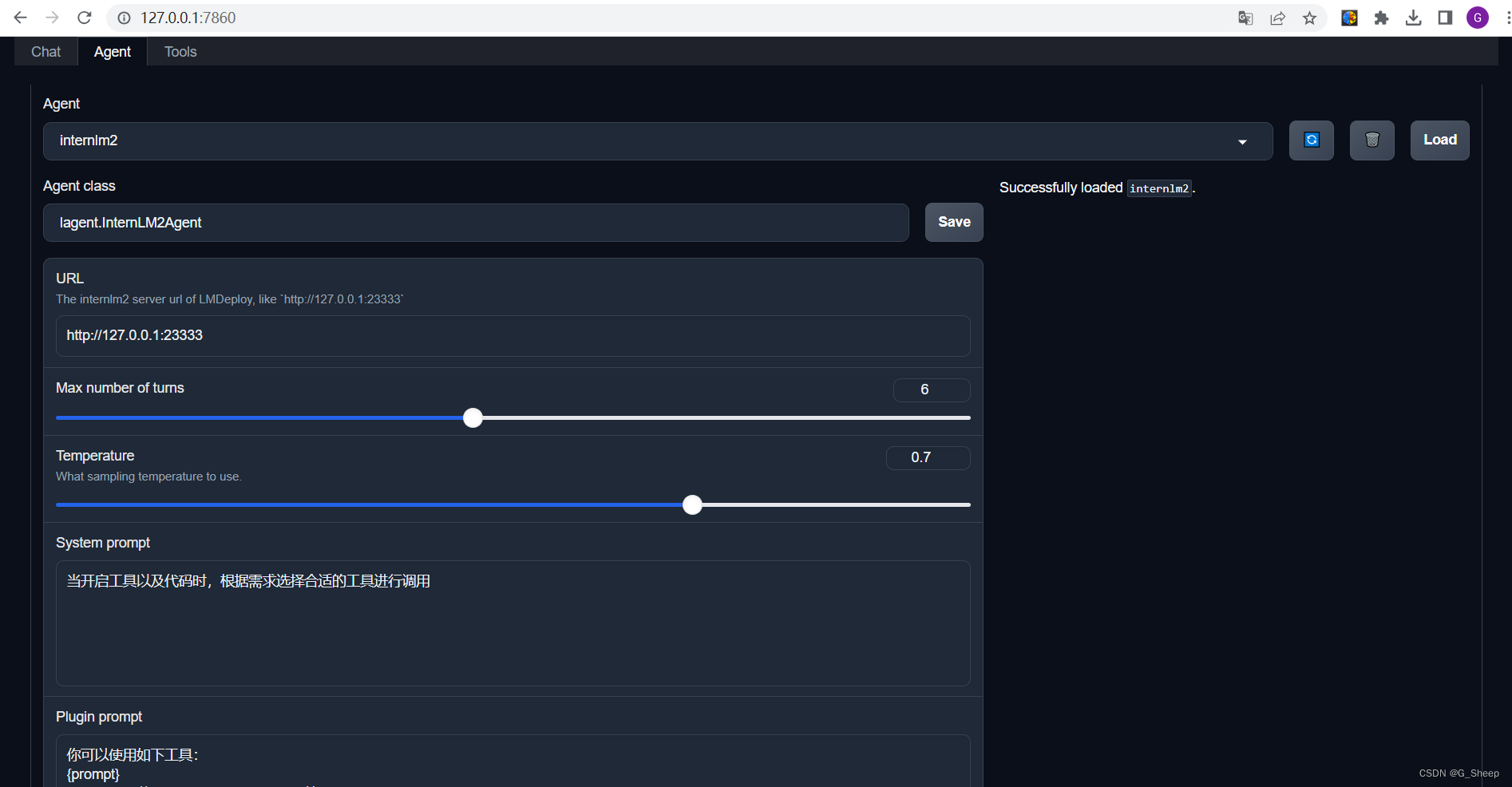
2.3.5、设置 Agent
直接使用之前创建好的 internlm2。
2.3.6、设置 Tools
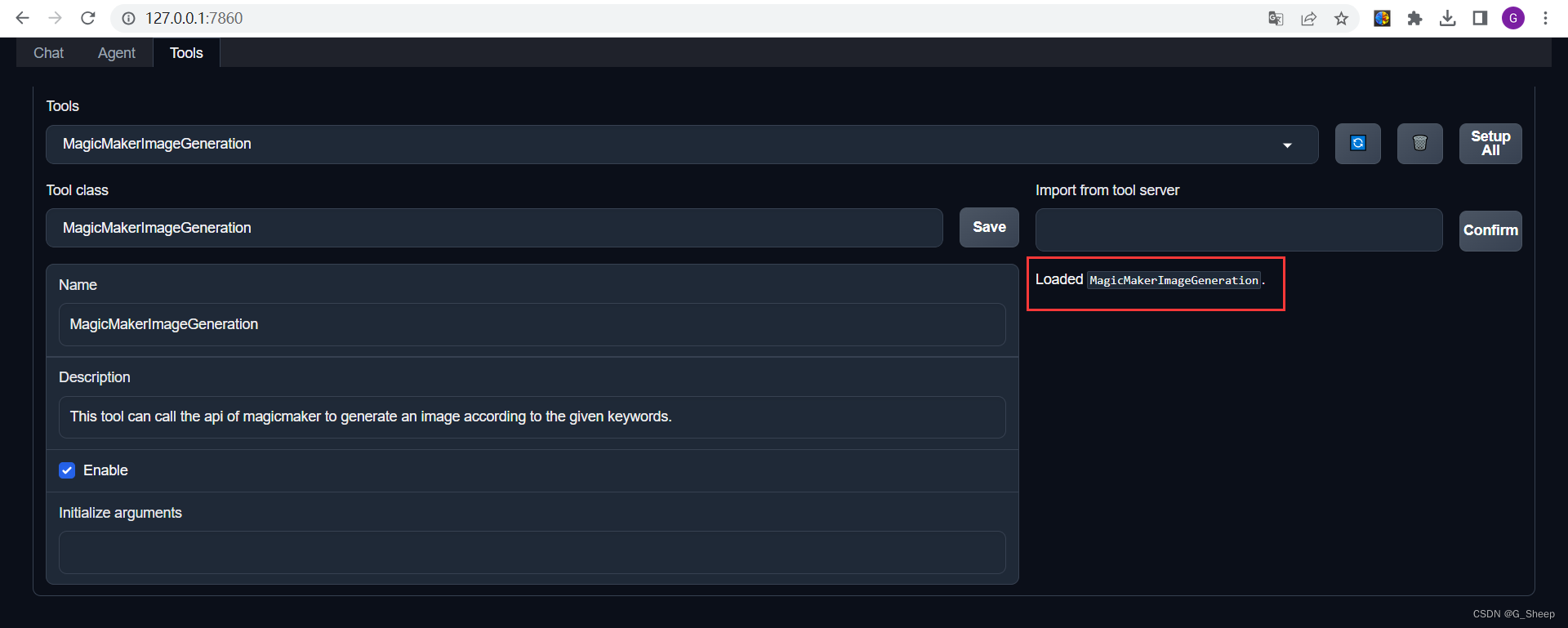
2.3.7、使用结果
别忘了在 Chat 界面选择 MagicMakerImageGeneration 工具。
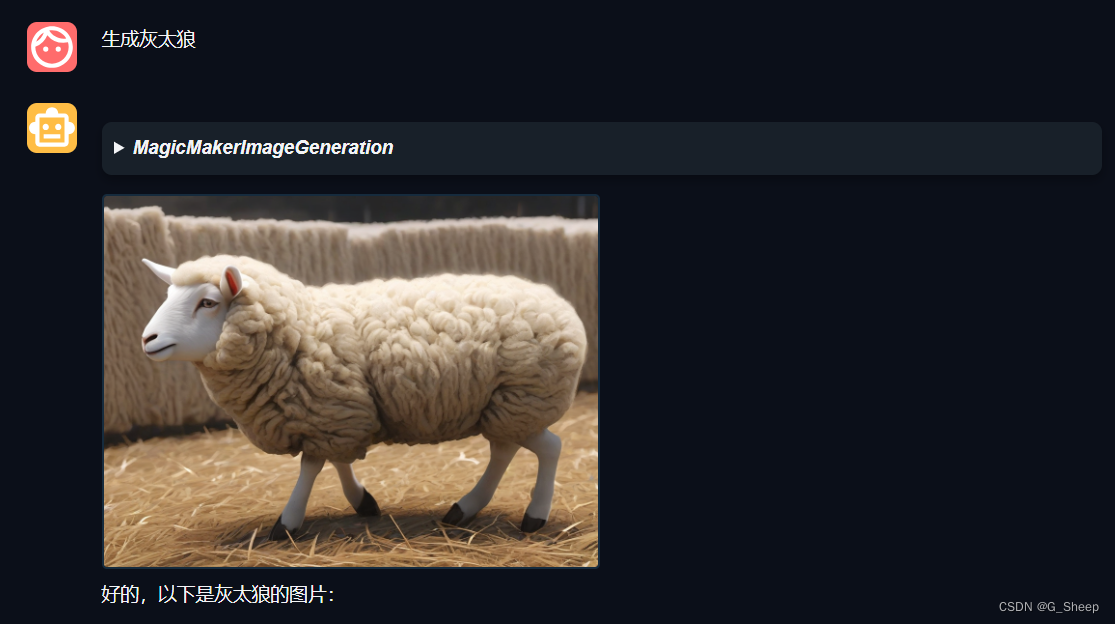
首先试试生成喜羊羊的图片。
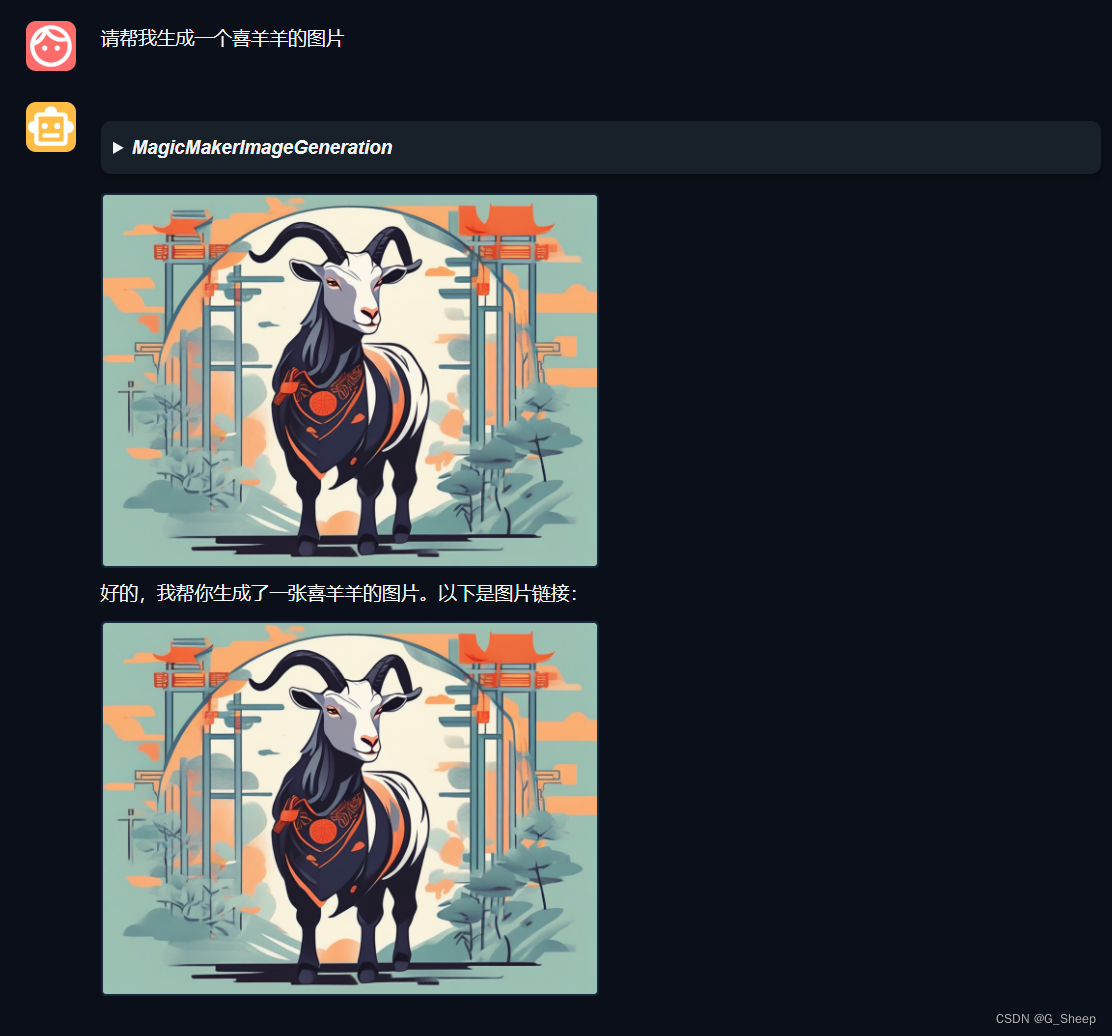
不对劲!十分有九分的不对劲,这不是我印象中的喜羊羊!然后后来我反应过来了,因为我只让生成喜羊羊,但目前生成的图片格式还是国风格式的。想着再生成龙的图片。

emmm,人中龙凤??
我想着是不是图片风格的问题,于是这次将风格改为了 donghua,再试一次。
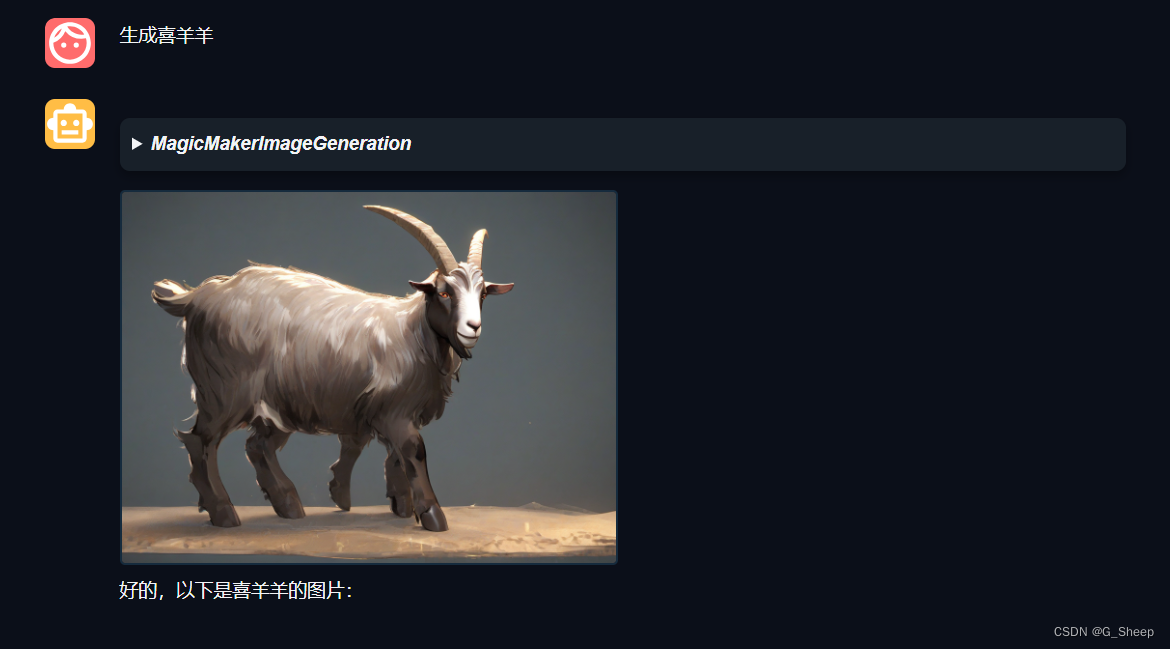
不好评价,我怀疑是不是因为模型不认识动画片《喜羊羊与灰太狼》,但是在后来询问得到了肯定的答复,于是我再次想让模型生成里面的喜羊羊角色。
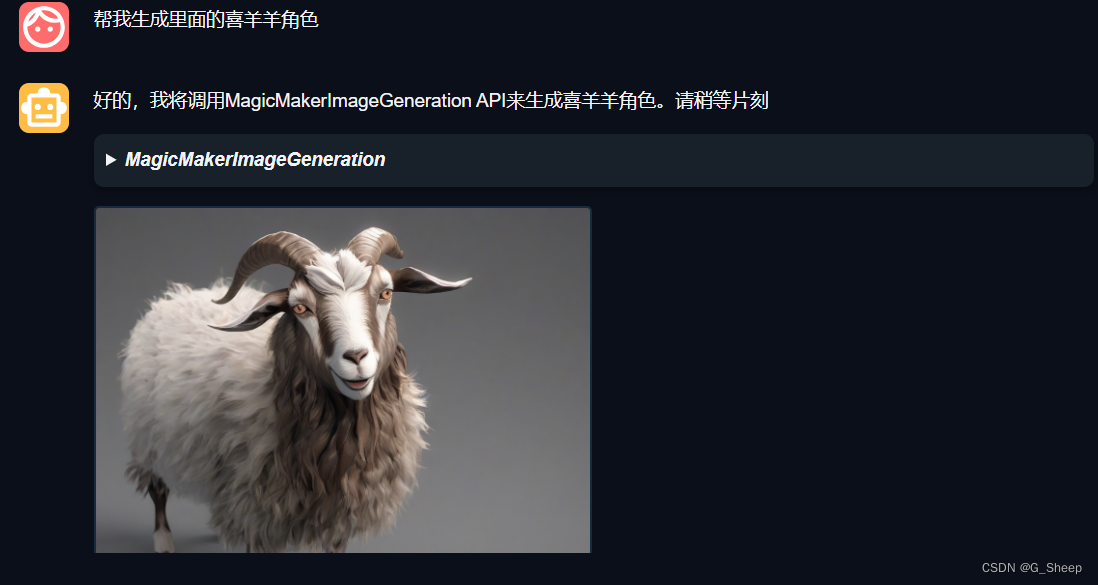
放弃了,真的不行,就是不行。那试试其他的角色吧。
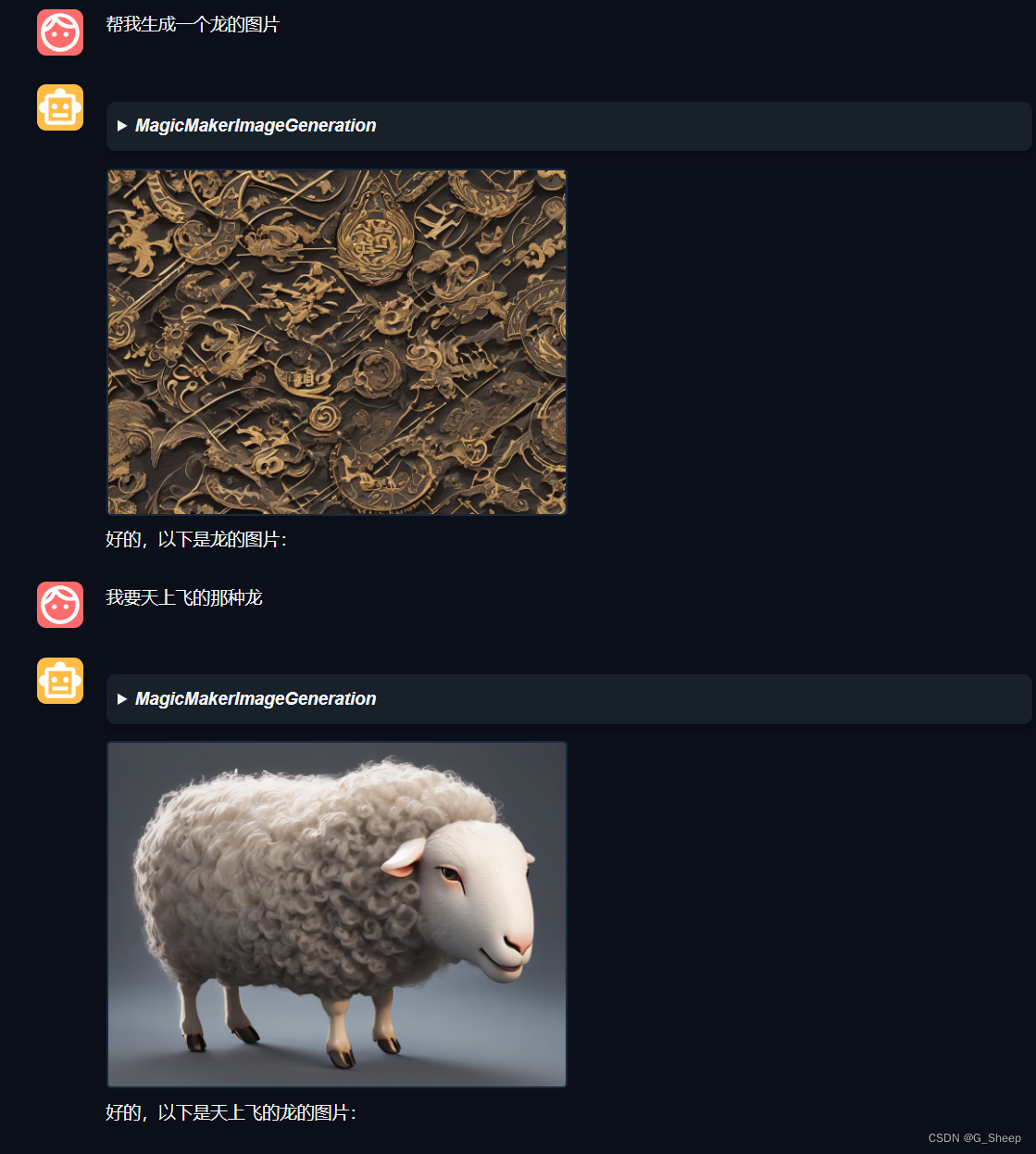
我不知道这是 AgentLego 算法库 还是 internlm2-chat-7b 或者是其他的什么问题,当你开启一个对话让其生成一个东西后,就代表定下了基调,那么后面无论你再让它生成什么,都离不开第一次生成的图片。
后面测试发现,当我新开启一个 Chat,无论是让生成龙还是狼都是正常的,不会再出现出现生成羊这样的图片,但缺陷也是一样,跟着后面再生成其他动物也是失败。
最新测试:
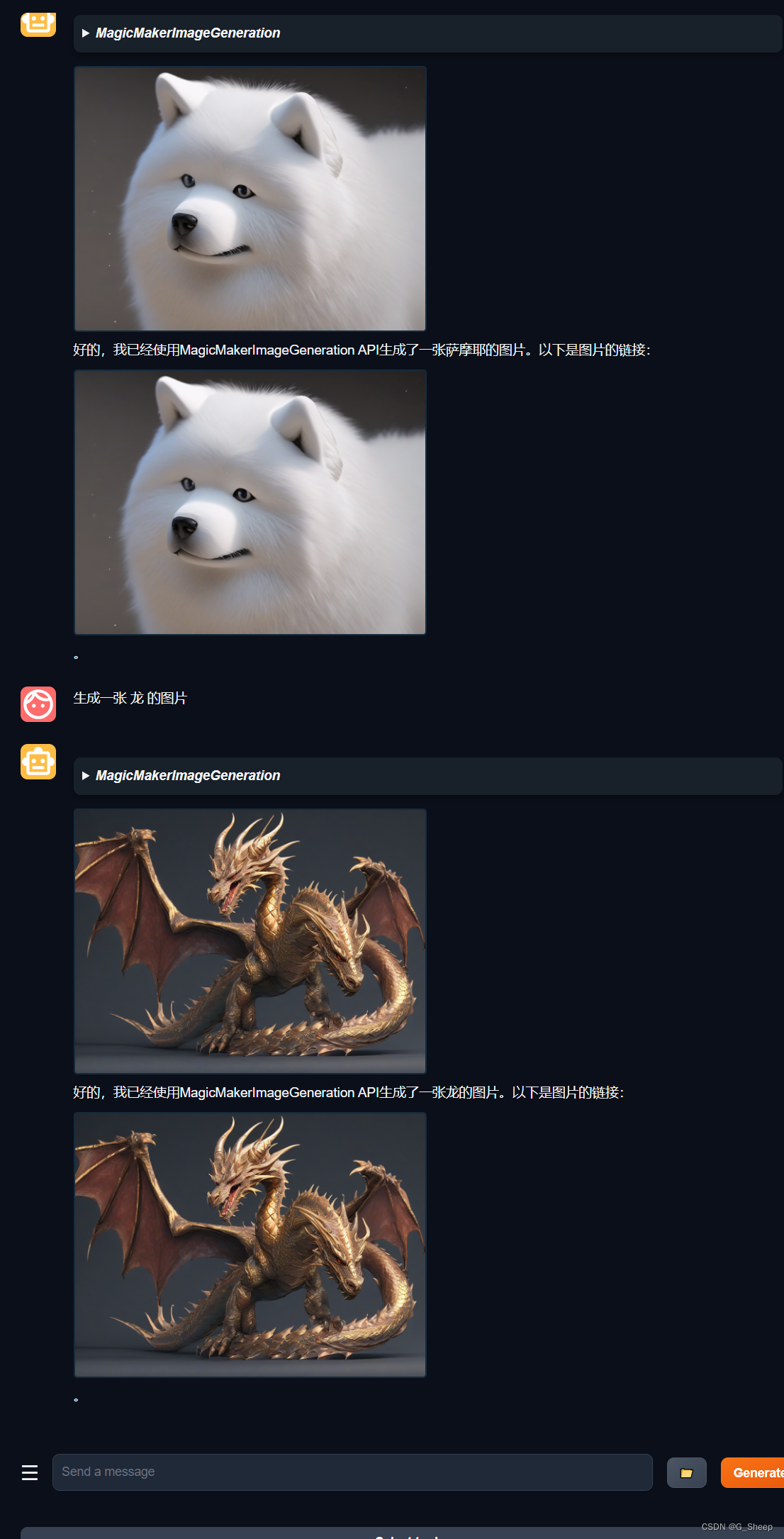
前两张是正常的,但再往后生成就会出现一些完全不相关的图片。