👽发现宝藏
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。【点击进入巨牛的人工智能学习网站】。
利用Python进行大规模数据处理:Hadoop与Spark的对比
随着数据量的不断增长,大规模数据处理变得越来越重要。在这个领域,Hadoop和Spark是两个备受关注的技术。本文将介绍如何利用Python编程语言结合Hadoop和Spark来进行大规模数据处理,并比较它们在不同方面的优劣。
简介
Hadoop
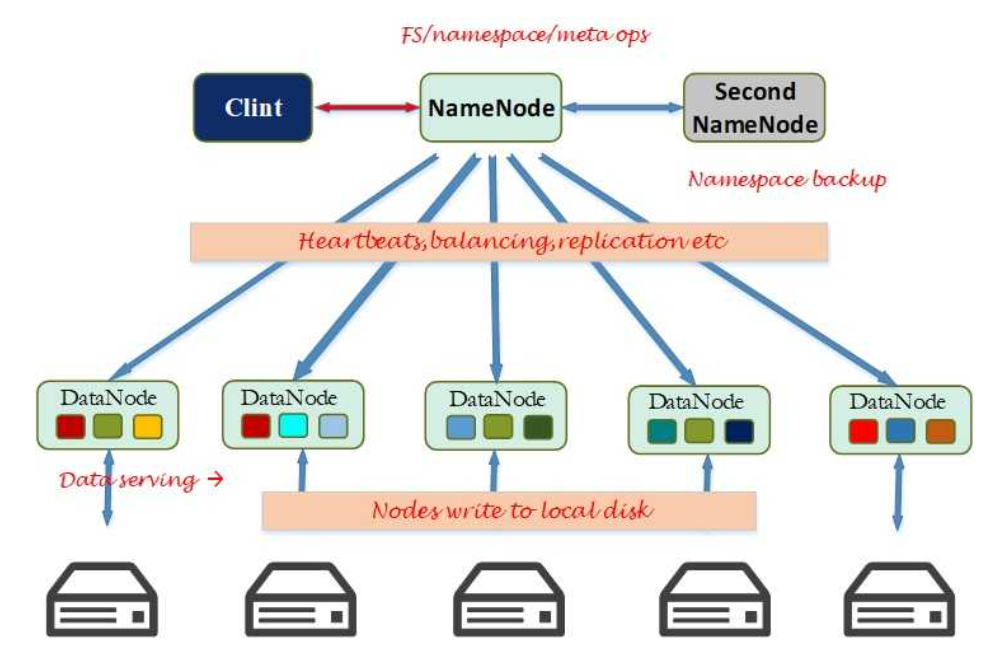
Hadoop是一个开源的分布式数据处理框架,它基于MapReduce编程模型,可以处理大规模数据集。Hadoop包括HDFS(分布式文件系统)和MapReduce(分布式计算框架)两个核心组件。
Spark
Spark是另一个开源的大数据处理框架,它提供了比Hadoop更快速和更强大的数据处理能力。Spark的核心是RDD(弹性分布式数据集)和Spark Core,它支持多种编程语言,包括Python。
Hadoop与Spark的对比
性能
Hadoop
Hadoop的性能受限于MapReduce的磁盘IO操作,因此在处理大规模数据时,性能可能会受到影响。
Spark
Spark使用内存计算,可以将数据存储在内存中,因此具有更快的处理速度和更高的性能。
编程模型
Hadoop
Hadoop的编程模型相对较为复杂,需要编写Map和Reduce函数,并手动管理中间数据的传输。
Spark
Spark提供了更简洁的编程模型,支持丰富的API,包括RDD、DataFrame和SQL等,使得开发人员可以更轻松地进行数据处理和分析。
生态系统
Hadoop
Hadoop生态系统庞大,包括Hive、HBase、Pig等多个项目,可以满足各种不同的数据处理需求。
Spark
Spark的生态系统也在不断壮大,支持与Hadoop生态系统的集成,并且提供了许多扩展库和工具,如Spark Streaming、Spark MLlib等。
案例代码
Hadoop案例
python"># 使用Python编写Hadoop的MapReduce程序
from mrjob.job import MRJobclass WordCount(MRJob):def mapper(self, _, line):for word in line.split():yield word, 1def reducer(self, word, counts):yield word, sum(counts)if __name__ == '__main__':WordCount.run()
Spark案例
python"># 使用Python编写Spark程序
from pyspark import SparkContextsc = SparkContext("local", "WordCount")# 读取文本文件
lines = sc.textFile("input.txt")# 分割单词并计数
word_counts = lines.flatMap(lambda line: line.split()) \.map(lambda word: (word, 1)) \.reduceByKey(lambda a, b: a + b)# 输出结果
word_counts.saveAsTextFile("output")
部署与管理
Hadoop
Hadoop的部署相对复杂,需要手动配置和管理HDFS、YARN等组件,并进行集群的调优和监控。通常需要专业的运维团队来负责维护和管理。
Spark
Spark的部署相对简单,可以通过Spark Standalone模式或者与其他集群管理工具如Apache Mesos、Kubernetes等集成来进行部署。Spark提供了丰富的监控工具和Web界面,方便用户进行集群的管理和监控。
进阶案例代码
使用Spark进行机器学习
python"># 导入必要的库
from pyspark.sql import SparkSession
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.regression import LinearRegression
from pyspark.ml.evaluation import RegressionEvaluator# 创建SparkSession
spark = SparkSession.builder \.appName("LinearRegressionExample") \.getOrCreate()# 读取数据集
data = spark.read.csv("data.csv", header=True, inferSchema=True)# 数据预处理
assembler = VectorAssembler(inputCols=["feature1", "feature2", "feature3"], outputCol="features")
data_preprocessed = assembler.transform(data).select("features", "label")# 划分训练集和测试集
train_data, test_data = data_preprocessed.randomSplit([0.8, 0.2], seed=123)# 构建线性回归模型
lr = LinearRegression(featuresCol="features", labelCol="label")# 训练模型
lr_model = lr.fit(train_data)# 在测试集上进行预测
predictions = lr_model.transform(test_data)# 评估模型性能
evaluator = RegressionEvaluator(labelCol="label", predictionCol="prediction", metricName="rmse")
rmse = evaluator.evaluate(predictions)
print("Root Mean Squared Error (RMSE) on test data = %g" % rmse)# 关闭SparkSession
spark.stop()
使用Hadoop进行日志分析
python"># 导入必要的库
from mrjob.job import MRJobclass LogAnalysis(MRJob):def mapper(self, _, line):# 提取关键信息ip, date, time, request, status, _ = line.split()yield ip, (date, time, request, status)def reducer(self, ip, records):# 统计每个IP地址的请求次数count = 0for record in records:count += 1yield ip, countif __name__ == '__main__':LogAnalysis.run()
通过以上案例代码,我们可以看到如何利用Spark进行机器学习任务,以及如何利用Hadoop进行日志分析。这些示例展示了Python与大数据处理框架的结合,使得开发人员能够更轻松地处理大规模数据,并从中获取有价值的信息。
Hadoop
日志分析
在互联网和电子商务领域,大量的日志数据需要进行实时分析,以了解用户行为和产品趋势。Hadoop可以通过MapReduce模型对这些日志数据进行处理和分析,从而为企业提供更多有价值的信息。
数据仓库
许多企业使用Hadoop作为数据仓库,用于存储和管理海量的结构化和非结构化数据。Hadoop的分布式存储和计算能力使得企业可以轻松扩展存储空间,并实现快速的数据分析和查询。
Spark
实时数据处理
在金融、电信和物联网等领域,需要对实时生成的数据进行快速处理和分析,以及时发现异常情况和提供个性化服务。Spark的流式处理模块可以满足这些需求,实现实时数据处理和分析。
机器学习
随着人工智能和机器学习技术的发展,越来越多的企业开始利用大数据来构建和训练机器学习模型。Spark提供了强大的机器学习库(如MLlib),可以在分布式环境下进行大规模数据的机器学习和深度学习。
未来展望
随着数据量的不断增长和技术的不断发展,大数据处理技术将会进一步演进和完善。未来,我们可以期待更加高效和智能的大数据处理工具和平台的出现,从而为企业提供更多更好的数据处理和分析解决方案。同时,Python作为一种简洁而强大的编程语言,将继续在大数据领域发挥重要作用,为开发人员提供更多的创新和可能性。
总结
本文探讨了利用Python进行大规模数据处理时,Hadoop与Spark的对比及其在不同方面的优劣,并提供了相关案例代码。从性能、编程模型、生态系统、部署与管理等角度来看,Spark在许多方面都表现出了更优异的特性,尤其是在处理大规模数据时具有更快的速度和更高的性能。此外,Spark提供了更简洁和强大的编程模型,使得开发人员能够更轻松地进行数据处理和分析。
然而,Hadoop作为大数据领域的先驱,其生态系统庞大且成熟,为企业提供了多种多样的数据处理工具和解决方案。在实际应用中,需要根据具体需求和场景来选择合适的技术栈。无论选择Hadoop还是Spark,Python作为一种简洁而强大的编程语言,都可以与它们结合使用,为企业的数据处理和分析提供更多可能性和机遇。
随着大数据技术的不断发展和创新,我们可以期待更多更好的大数据处理工具和平台的出现,为企业提供更加高效和智能的数据处理和分析解决方案。同时,Python作为一种广泛应用于数据科学和人工智能领域的编程语言,将继续在大数据领域发挥重要作用,为开发人员提供更多的创新和可能性。