知乎:然荻
链接:https://zhuanlan.zhihu.com/p/721941928
1. 背景介绍
如果你拿到了两台8卡A100的机器(做梦),你的导师让你学习部署并且训练不同尺寸的大模型,并且写一个说明文档。你意识到,你最需要学习的就是关于分布式训练的知识,因为你可是第一次接触这么多卡,但你并不想深入地死磕那些看起来就头大的底层原理,你只想要不求甚解地理解分布式的基本运行逻辑和具体的实现方法。那么,我来帮你梳理关于大模型的分布式训练需要了解的知识。
1.1 分布式定义
分布式就是把模型或者数据分散分布到不同的GPU去。为什么要分散到不同的GPU,当然是因为一个GPU的显存太小了(不管从为了训练加速还是模型太大塞不进去这两个角度来看,本质就是单个GPU显存不够)。为什么GPU显存这么小,是因为GPU对带宽的要求很高,能达到这样高带宽的内存都很贵,也就是说从成本的角度上导致单个GPU显存有限。
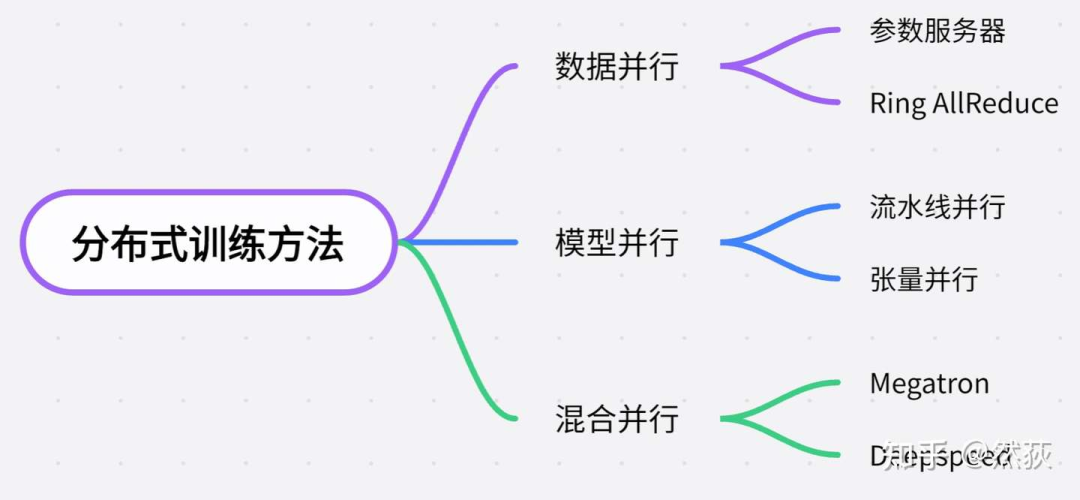
1.2 分布式方法分类
从需要加载的模型大小来分类,一般可以这样对分布式的方法进行分类。
单卡能够容纳训练的小模型,分布式就是为了训练加速,一般使用的是数据并行的方法,也就是每一块GPU复制一份模型,然后将不同的数据放到不同的GPU训练。
模型变得越来越大,单卡都无法支持一个模型训练的时候,就会使用模型并行的方法,模型并行又分为流水线并行(Pipeline Parallelism)和张量并行(Tensor Parallelism),其中流水线并行指的是将模型的每一层拆开分布到不同GPU。当模型大到单层模型都无法部署在单个gpu上的时候,我们就会用到张量并行,将单层模型拆开训练。
Deepspeed,则是用了Zero零冗余优化的方法进一步压缩训练时显存的大小,以支持更大规模的模型训练。
2. 必要知识补充
2.1 模型是怎么训练的
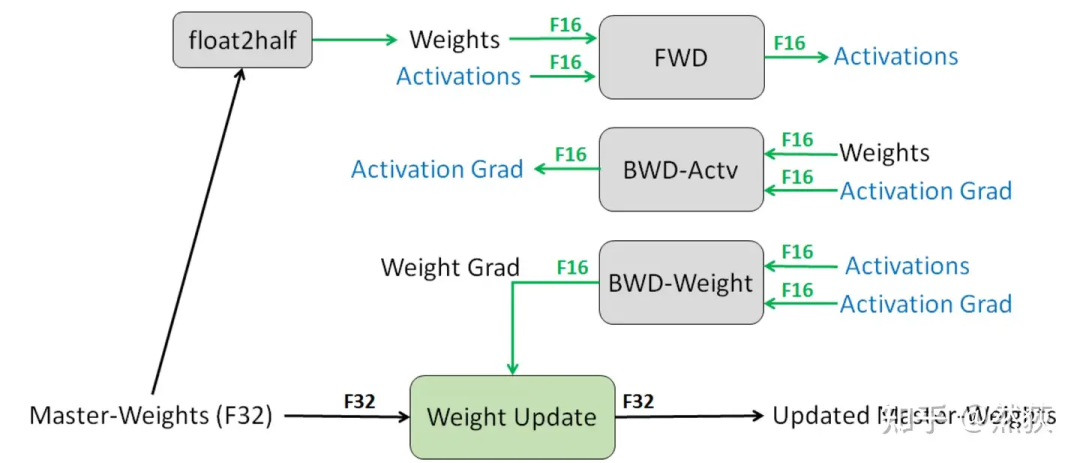 我们想了解模型训练时分布式是如何进行优化的,那么知道模型是如何训练的就非常重要。我们以目前最广泛使用的混合精度训练为例,按照训练运行的逻辑来讲:
我们想了解模型训练时分布式是如何进行优化的,那么知道模型是如何训练的就非常重要。我们以目前最广泛使用的混合精度训练为例,按照训练运行的逻辑来讲:
Step1:优化器会先备份一份FP32精度的模型权重,初始化好FP32精度的一阶和二阶动量(用于更新权重)。
Step2:开辟一块新的存储空间,将FP32精度的模型权重转换为FP16精度的模型权重(用于前向和计算梯度)。
Step3:运行forward和backward,产生的梯度和激活值都用FP16精度存储。
Step4:优化器利用FP16的梯度和FP32精度的一阶和二阶动量去更新备份的FP32的模型权重。
Step5:重复Step2到Step4训练,直到模型收敛。
我们可以看到训练过程中显存主要被用在四个模块上
模型权重本身(FP32+FP16)
梯度(FP16)
优化器(FP32)
激活值(FP16)
具体训练的时候会消耗多少显存怎么计算呢,多大的模型在训练的时候会超出我们的最大显存呢,关于大模型训练时的显存占用分析可以看一看这篇文章“一文讲明白大模型显存占用(只考虑单卡)”,讲得非常详细(自卖自夸),有助于后续我们理解怎么优化显存占用。
https://zhuanlan.zhihu.com/p/713256008
2.2 GPU是怎么通讯的
我们常常听说单机8卡、多机多卡、多节点,这里的“单机”和“节点”也就是指的是单个服务器,8卡自然指的是8张显卡。在同一个服务器内的8张GPU共享同一个主机系统的资源(如CPU资源、系统内存等),同一节点内的不同GPU之间通过PCIe总线或者NVLink(仅限NVIDIA显卡)进行通讯,不同节点之间的GPU一般是通过InfiniBand网卡通讯(NVIDIA的DGX系统就是一张GPU卡配一个InfiniBand网卡),下图可以看出,多节点之间的通讯带宽和单节点多GPU之间的通讯带宽是可以达到差不多速度的。你问为什么节点之间不用NVLink,因为 NVLink设计用于非常短距离的通信,通常在同一服务器机箱内 ,不方便扩展。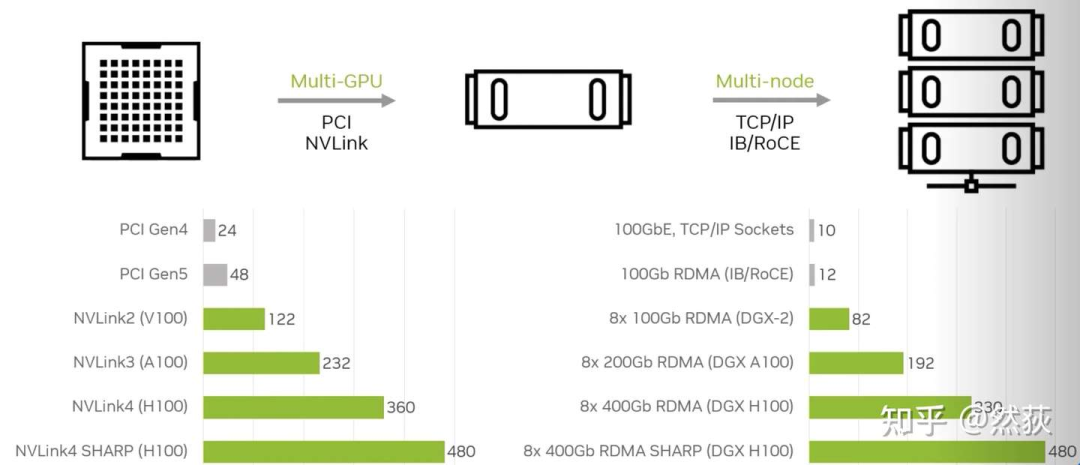 除了上面介绍的硬件,还有软件部分,就是大名鼎鼎的NCCL 英伟达集合通信库,专用于多个 GPU 乃至多个节点间通信的实现。AllReduce,Broadcast,Reduce,AllGather,ReduceScatter就是NCCL主要实现的通信原语。
除了上面介绍的硬件,还有软件部分,就是大名鼎鼎的NCCL 英伟达集合通信库,专用于多个 GPU 乃至多个节点间通信的实现。AllReduce,Broadcast,Reduce,AllGather,ReduceScatter就是NCCL主要实现的通信原语。
其实NCCL就是提供了一个接口,我们也不需要了解底层如何实现的,只需调用接口,就可以实现GPU间的通信。
2.2.1 Broadcast(广播)
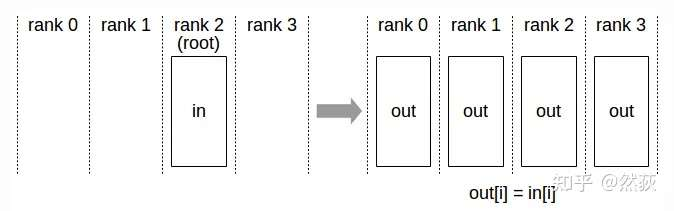 将一个GPU上的数据同时发送到所有其他GPU,这种操作方式就叫做广播(broadcast)。
将一个GPU上的数据同时发送到所有其他GPU,这种操作方式就叫做广播(broadcast)。
2.2.2 Scatter(散射)
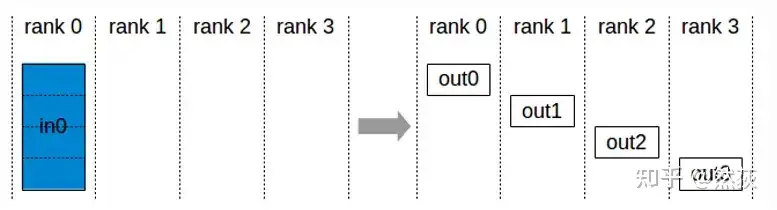 把一个GPU上的数据切分为多块,按照顺序向其他GPU发送数据块,就叫做散射。
把一个GPU上的数据切分为多块,按照顺序向其他GPU发送数据块,就叫做散射。
2.2.3 Reduce(规约)
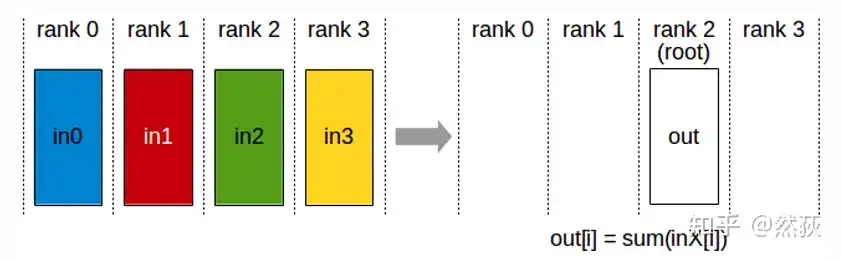 reduce在这里的作用是求和,即将多个GPU的数据发送到指定的GPU然后求和。
reduce在这里的作用是求和,即将多个GPU的数据发送到指定的GPU然后求和。
2.2.4 Gather(聚合)
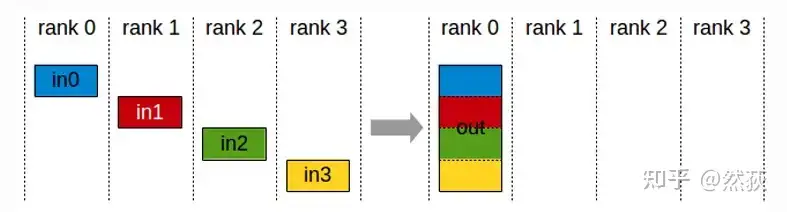 Gather是Scatter散射的逆操作,将分散在各个GPU的数据块拼接在一起。
Gather是Scatter散射的逆操作,将分散在各个GPU的数据块拼接在一起。
2.2.5 AllReduce(全规约)
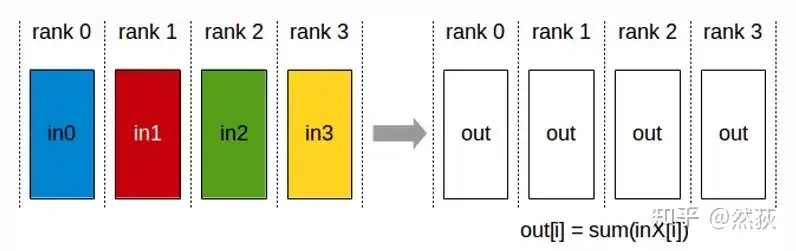 每一个GPU把数据发送给其余GPU,每个GPU对于接收到的数据进行求和。
每一个GPU把数据发送给其余GPU,每个GPU对于接收到的数据进行求和。
2.2.6 AllGather(全聚合)
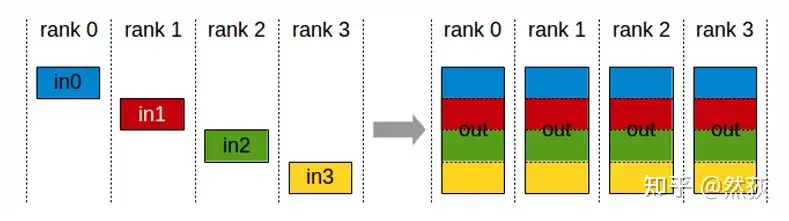 每一个GPU把数据发送到其余所有GPU,每个GPU对于接受到的数据拼接为完整数据。
每一个GPU把数据发送到其余所有GPU,每个GPU对于接受到的数据拼接为完整数据。
2.2.7 ReduceScatter(散射规约)
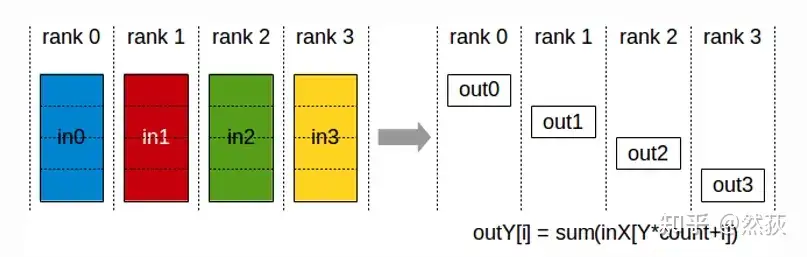 散射规约指的就是先做Scatter再做Reduce,先将GPU的数据分割为多个数据块,然后每一块数据按GPU序列进行散射Scatter。对所有的GPU都进行散射之后,当前GPU所接受到的所有数据块进行求和,也就是Reduce规约。
散射规约指的就是先做Scatter再做Reduce,先将GPU的数据分割为多个数据块,然后每一块数据按GPU序列进行散射Scatter。对所有的GPU都进行散射之后,当前GPU所接受到的所有数据块进行求和,也就是Reduce规约。
看完了感觉很混乱也不要紧,先有个大概的印象就好,你只要知道这些GPU间的基本通讯的组合拳能够能够实现我们分布式所需要的各种数据传输就好。
3. 数据并行
数据并行,就是一开始大模型很小的时候,单卡装下绰绰有余,这时候我们想加速训练,除了batchsize开大,还有什么办法呢,一个人刷盘子太慢,那就多招几个人嘛,多招几个人,指的就是多复制几个模型每个模型占领一个GPU去干活嘛,猴子猴孙身外身法启动!
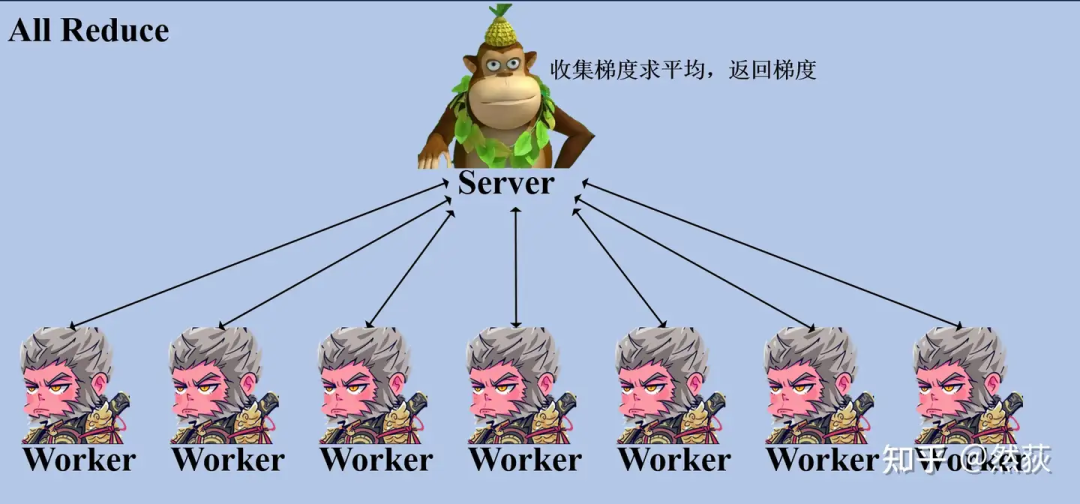
3.1 参数服务器
一个非常简单的方法就是从八个猴子里选一个作为一个主管,这个主管的作用就是收集所有猴子的梯度,然后经过九九八十一算得到平均梯度后再分别传回去。
https://zhuanlan.zhihu.com/p/713256008
 这里我们引入一个通讯量的概念,就是用来衡量单个GPU或者整个系统的通讯参数量,我们设一份完整的参数为 Φ ,在这里就是指的一份完整的梯度参数,假设有N个GPU,那么通讯量如下表:
这里我们引入一个通讯量的概念,就是用来衡量单个GPU或者整个系统的通讯参数量,我们设一份完整的参数为 Φ ,在这里就是指的一份完整的梯度参数,假设有N个GPU,那么通讯量如下表: 有没有感觉这个方法很熟悉,没错,就是上面提到过的ALL_Reduce方法。这也是李沐大佬的参数服务器这一论文提出的方法,想要深入了解的可以去看论文 Scaling Distributed Machine Learning with the Parameter Server 。
有没有感觉这个方法很熟悉,没错,就是上面提到过的ALL_Reduce方法。这也是李沐大佬的参数服务器这一论文提出的方法,想要深入了解的可以去看论文 Scaling Distributed Machine Learning with the Parameter Server 。
3.2 Ring AllReduce
上面的参数服务器方法虽然简单,但是也存在很致命的两个缺陷:
(1)冗余太多:每一个GPU都要复制一个模型权重,这些一样的权重就是冗余。
(2)通讯负载不均衡:Server需要和每一个Worker进行通讯,而Worker们却只用发送和接受各一次。
那么Ring AllReduce就是一种用来解决负载不均的方式,我们把上面的方法理解为中心化方法,那么该方法就是去中心化的方法,不再有Server和Worker的区别,做到了每一个GPU通讯量的均衡。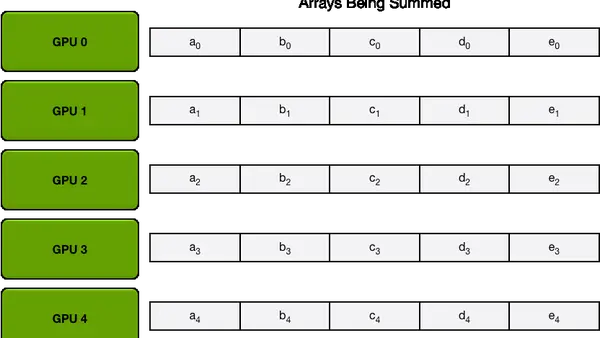 整个过程其实就是之前提到的通讯原语里的ReduceScatter然后AllGather,大家可以回去对照着看一下。对于Ring AllReduce的通讯量计算,因为是一个并行度很高的通讯,所以只需要看单个GPU的通讯量,然后乘数量就是总通讯量了。
整个过程其实就是之前提到的通讯原语里的ReduceScatter然后AllGather,大家可以回去对照着看一下。对于Ring AllReduce的通讯量计算,因为是一个并行度很高的通讯,所以只需要看单个GPU的通讯量,然后乘数量就是总通讯量了。 需要注意的是,参数服务器和Ring AllReduce在通讯总量上是几乎一样的,但是他们的通讯时间却不一样,就是因为前者在sever端通讯负载过大,堵车了,导致时间更长。现在我们torch常用的DDP( Distributed Data Parallel )多机多卡训练,就是用的Ring AllReduce进行通讯。
需要注意的是,参数服务器和Ring AllReduce在通讯总量上是几乎一样的,但是他们的通讯时间却不一样,就是因为前者在sever端通讯负载过大,堵车了,导致时间更长。现在我们torch常用的DDP( Distributed Data Parallel )多机多卡训练,就是用的Ring AllReduce进行通讯。
4. 模型并行
上面讲到的数据并行是在模型足够小能被单张GPU容纳的情况下的并行方法,但是现在大模型时代模型动不动70B、几百B的,单张卡都容纳不下,该怎么办呢,那就只能把模型肢解了呗。这样的分布式方法跟数据并行不一样的最深层次的原因就是,数据并行的数据都是相互独立的,数据并行是为了提高训练效率的并行;而模型并行的数据不一定是独立的,我把一个模型拆为两半,那么我这两半的模型都得用同一批数据去跑才行,模型并行是模型太大不得已的对模型进行肢解的一种并行。
4.1 流水线并行
流水线并行,也就是横切,模型不都一层一层的吗,那我们就正好一层一层地剥开~~,就是按照这样的思路拆开模型。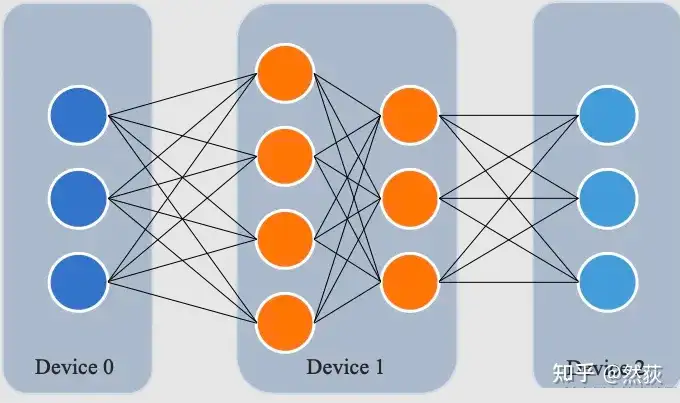
4.1.1 朴素流水线
朴素流水线,如下图所示,也是最简单的一种流水线方法,按照时间顺序,先一层一层地进行前向,然后再一层一层地反向传播,也非常好理解。需要注意的是,我们在每一层之间传递的是当前层的输出张量,而不是梯度信息,故通讯量相对较小。但是通讯量小不代表总的利用效率越高,因为通讯和计算的并行程度还有内存冗余也是很需要考虑的因素。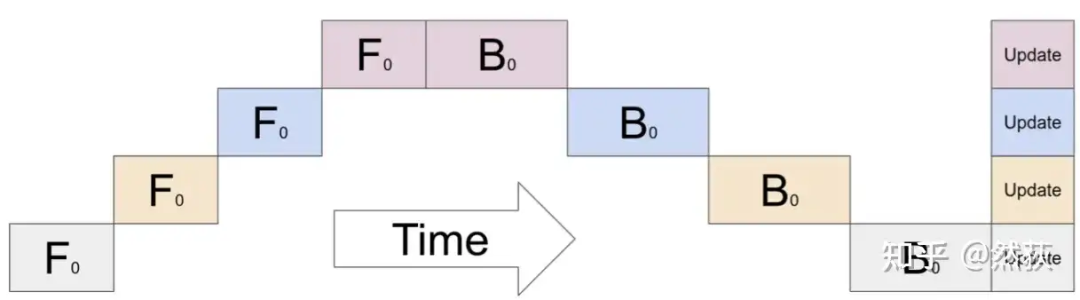 下面这张图是更加具体一些的两张GPU实现朴素流水线的展示,我们发现除了中间多了一步前向和后向的信息传输,实际运行起来跟放在一张GPU里是没有任何区别的。
下面这张图是更加具体一些的两张GPU实现朴素流水线的展示,我们发现除了中间多了一步前向和后向的信息传输,实际运行起来跟放在一张GPU里是没有任何区别的。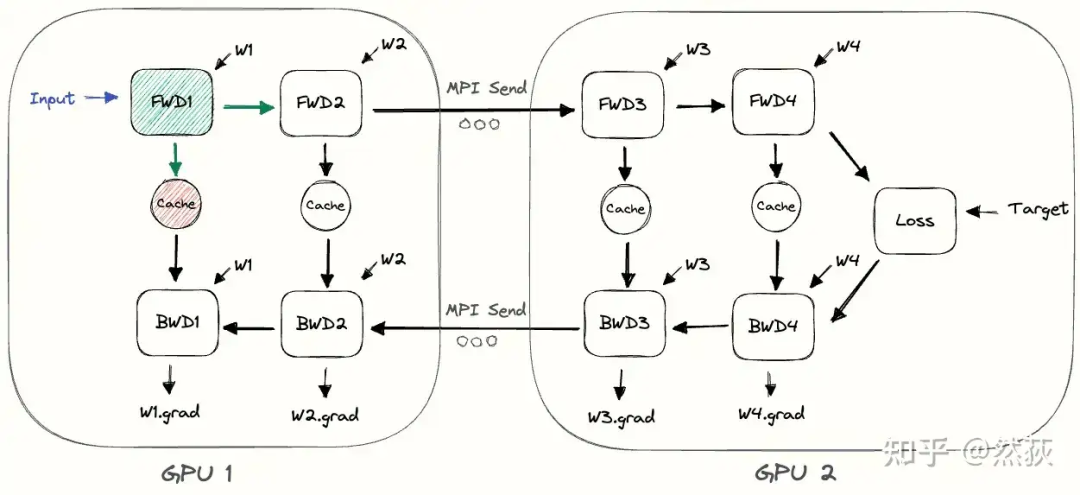 朴素流水线非常的简单,这导致的问题也非常的明显,我们指出最主要的两个问题:
朴素流水线非常的简单,这导致的问题也非常的明显,我们指出最主要的两个问题:
GPU利用率过低
从我们的图4-2也能看出来,图中所有的空白部分都是被我们浪费掉的GPU空间,这些GPU空间被叫做Bubble,也就是空泡。朴素流水线的空泡率可以计算为 ( \text{空泡率} = \frac{G - 1}{G} ) ,空泡率指的是时间上浪费的时间占比,( G ) 指的就是GPU数量,可以看到GPU越多,空泡率就越接近1,这会造成GPU利用率非常低。通讯和计算没有交错
GPU在层之间进行通讯的时候,所有GPU都被闲置了,通讯和计算并没有实现并行模式,这也会导致训练的效率大大降低。
4.1.2 微批次流水线并行
这个方法的核心思路就是用数据并行的方式来解决朴素流水线的GPU并行效率太低的问题,将一个大batch拆为多个小batch进行流水线。我们举个最简单例子来理解,张三和李四用朴素流水线处理一筐鱼,张三负责洗鱼,李四负责煮鱼,李四必须得等张三洗完一整筐鱼才能煮鱼。现在他们改进为微批次流水线,把一大筐鱼分为N小框鱼,这时张三洗完一小筐鱼就给李四煮鱼,然后张三又接着洗下一小筐鱼,张三和李四之间就产生了并行处理的部分。
我们现在来看下面的图就很好理解了,这种方法叫做F-then-B 模式的流水线策略,在微批次的情况下,先进行前向计算,再进行反向计算。F-then-B 模式的空泡率可以计算为 空泡率 是GPU数量,是minibatch数,可以看到,空泡率明显下降了,而且随着相比越大,的影响就会越小。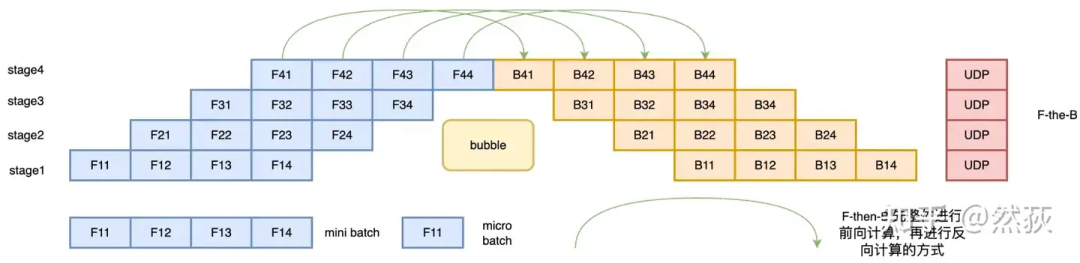 什么,你说还不够高效,那么我们看看1F1B(One Forward pass followed by One Backward pass)模式的流水线策略,这是一种前向计算和反向计算交叉进行的方法。在 1F1B 模式下,前向计算和反向计算交叉进行,可以及时释放不必要的中间变量。如下图所示,绿色的箭头就表示前向和反向之间的距离,他们之间的距离比F-then-B里的距离要更近,这就说明这种方法可以在反向后更快地释放不需要的激活值。1F1B 模式的空泡率可以计算为空泡率,诶,这里空泡率怎么跟F-then-B的模式一模一样啊,他们的效率应该是一样的才对吧,为什么还说优化了。这是因为1F1B 的交叉进行快速释放的策略模式节省了显存,在设备显存一定的情况下,就可以通过增大的值(增大micro-batch的个数)来降低Bubble率了。
什么,你说还不够高效,那么我们看看1F1B(One Forward pass followed by One Backward pass)模式的流水线策略,这是一种前向计算和反向计算交叉进行的方法。在 1F1B 模式下,前向计算和反向计算交叉进行,可以及时释放不必要的中间变量。如下图所示,绿色的箭头就表示前向和反向之间的距离,他们之间的距离比F-then-B里的距离要更近,这就说明这种方法可以在反向后更快地释放不需要的激活值。1F1B 模式的空泡率可以计算为空泡率,诶,这里空泡率怎么跟F-then-B的模式一模一样啊,他们的效率应该是一样的才对吧,为什么还说优化了。这是因为1F1B 的交叉进行快速释放的策略模式节省了显存,在设备显存一定的情况下,就可以通过增大的值(增大micro-batch的个数)来降低Bubble率了。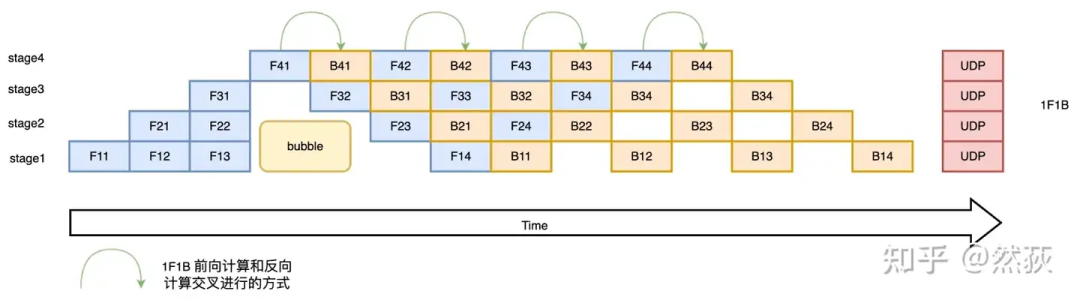
4.2 张量并行
上面讲了横着切的流水线并行,我们知道横着切指的是按模型分层的维度来切分,那么我们的竖着切,指的是什么呢,指的就是按照模型每一层的层内参数(张量)进行切分。
张量并行从数学原理上来看就是对于linear层就是把矩阵分块进行计算,然后把结果合并;对于非linear层,则不做额外设计。
如下图所示,X是输入,A是权重矩阵,Y则是输出,我们对权重矩阵A有横切和竖切两种切法。竖切的最后两个向量就是合并,横切的两个向量就是相加,这是由矩阵乘法性质决定的。其实这就是张量并行的最核心原理,后面提到的方法无论怎么包装都离不开这两个矩阵乘法的切分。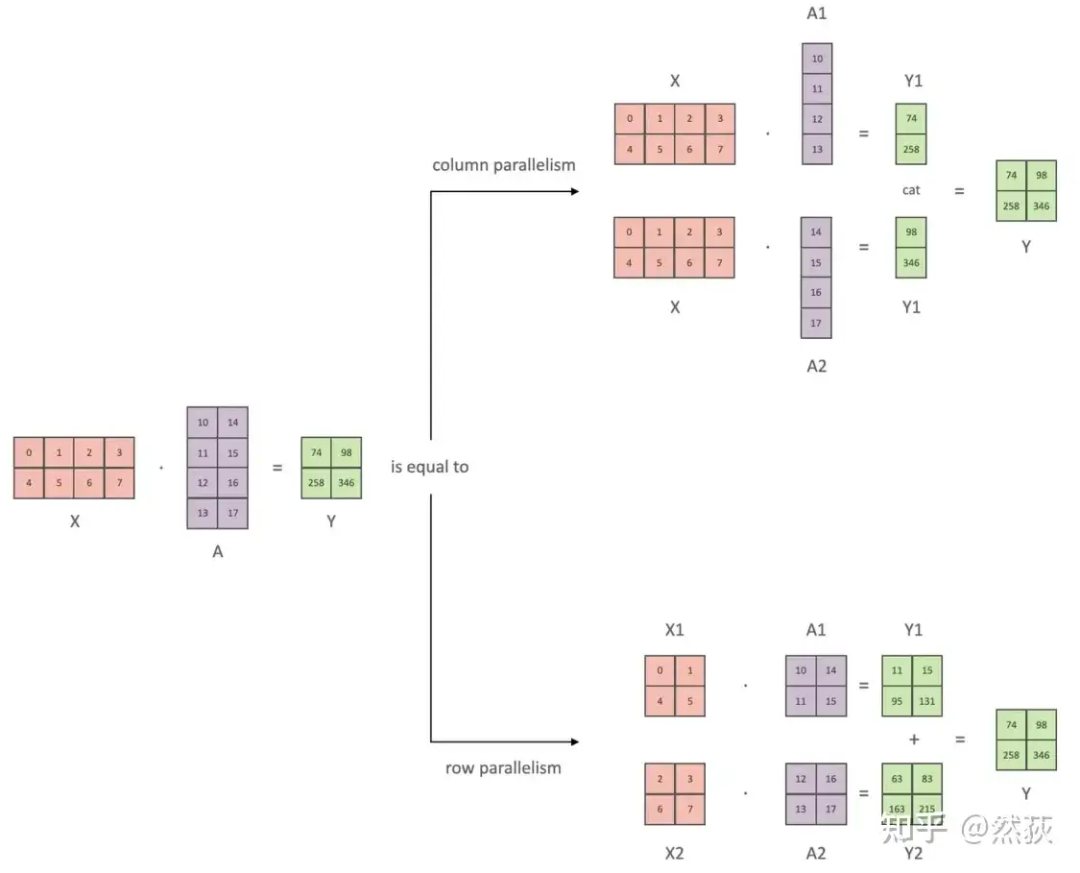 正如之前提到的,只有在线性层中会出现张量并行,下图就是关于线性层矩阵乘法的具体实现,包括前向和反向会存在的具体计算和通讯。
正如之前提到的,只有在线性层中会出现张量并行,下图就是关于线性层矩阵乘法的具体实现,包括前向和反向会存在的具体计算和通讯。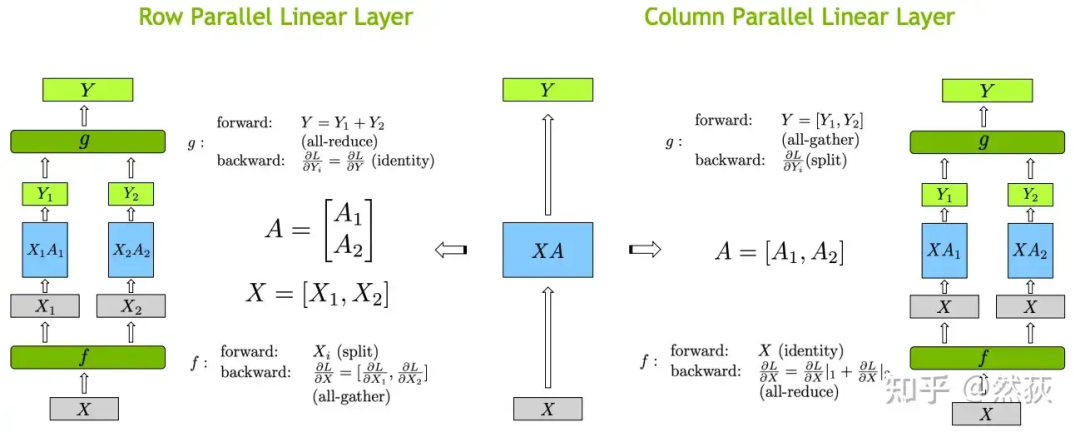
5. 混合并行
上面几节介绍了关于数据并行和模型并行的基础实现思路,那么这一小节我们就来讲一讲实际应用中,我们常听到的Megatron和deepspeed,具体是如何在数据并行和模型并行上混合优化,并且玩出花来的。我们这篇文章还是主要讲思路逻辑,帮助你去理解整体而不纠结于太细枝末节的技术,毕竟如果要扣细节和深度,Megatron和deepspeed随便一个单独拿出来讲解都是需要大量篇幅的。
5.1 Megatron
Megatron的核心思路就是混合了模型并行(MP)(包括了张量并行(TP)、流水线并行(PP))和数据并行(DP)这三种并行方式,也被称为3D并行的策略。其中张量并行是Megatron的重点,也是我们要先学习的一个知识点,你说上面不是已经讲过张量并行是基于线性层进行横切或者竖切吗,那你知道具体在transformer架构里面是怎么切割的吗,什么情况下横切什么情况下竖切呢,transformer里面有哪些线性层是可以被这样切割的呢,这些问题也就是Megatron首先要回答的问题。
5.1.1 复习一下 Transformer 模型结构
我自己画了一个简易版的 Transformer 结构,旨在突出结构中的 linear 线性层有哪些部分,可以很清晰地看到,我们可以将模型分为三个板块,一个是 Embedding 输入和输出层,一个是多头注意力层,一个是前馈层。接下来我们就会分别介绍这三个板块的张量并行是如何具体实现的。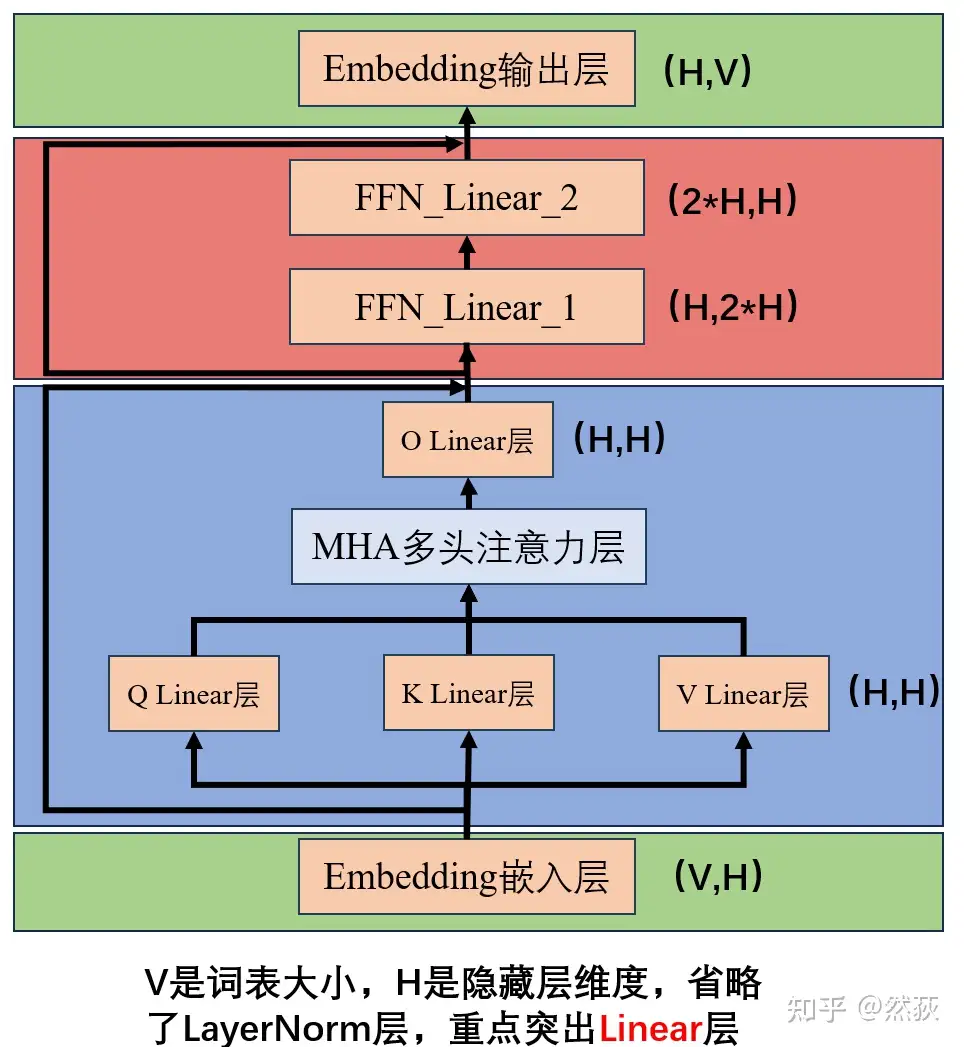
5.1.2 FFN 前馈层的张量并行
我们了解前馈层是由两层 Linear 组成的,也就是下图的 A 和 B 权重矩阵。下图的张量并行方式是很简单清晰的,就是对 A 进行了竖切,对 B 进行了横切。那么这时候就要问了,为什么?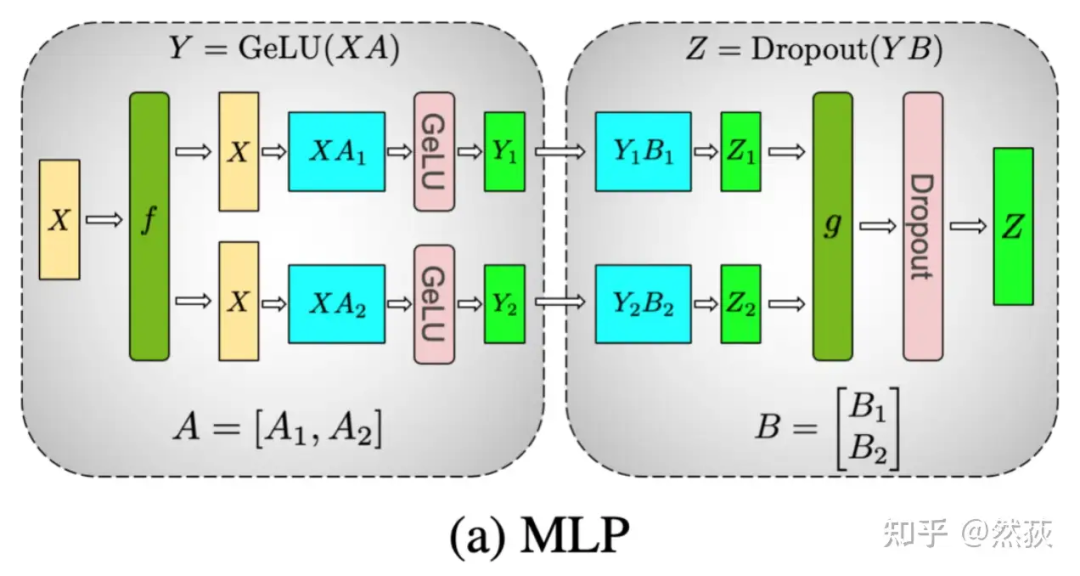 我们先来看两个式子:如果
我们先来看两个式子:如果
如果 ,其中冒号表示 concat
你觉得哪个式子是正确的,这里就不卖关子了,第一个加法的式子是不对的,第二个合并的式子是正确的。
因为 Relu 或者其他任意的非线性函数,是不具有类似乘法分配律 的性质的。
我们举一个简单的例子就很好理解了。
Relu (x) 就是 max (0, x) 嘛
可以很清楚地看到,对于非线性激活函数,是不能先分开经过激活函数然后求和的。合并的例子更简单,这里就不写了。经过激活函数后再合并的结果和直接合并再经过激活函数的结果是相同的。
这里我们应该也明白为什么上图中的 要对 进行竖切了吧,因为这样子可以不需要在计算非线性激活函数前做加法的通讯,而仅仅在最后合并结果进行一次通讯。对 进行竖切后,因为矩阵乘法的原因, 的 就只能进行横切了。
具体来分析一下:
f 的 forward 计算:把输入 拷贝到两块 GPU 上,每块 GPU 即可独立做 forward 计算。
g 的 forward 计算:每块 GPU 上的 forward 的计算完毕,取得 和 后,GPU 间做一次 AllReduce,相加结果产生 。
g 的 backward 计算:只需要把 拷贝到两块 GPU 上,两块 GPU 就能各自独立做梯度计算。
f 的 backward 计算:当当前层的梯度计算完毕,需要传递到下一层继续做梯度计算时,我们需要求得 。则此时两块 GPU 做一次 AllReduce,把各自的梯度 和 相加即可。
因此此时两块 GPU 做一次 AllReduce,把各自的梯度 和 相加即可。
5.1.3 MHA 多头注意力层的张量并行
对于多头注意力来讲,进行张量分割的方式则比较特殊,如下图所示,是按照多头的头数量来进行张量并行分割的,这是因为每个头上都可以独立计算 attention。
具体来讲,我们对 Q、K、V 矩阵做列切割,对 O 矩阵做行切割。这样切割的原因和 FFN 层一样,都是为了减少通讯量。forward 和 backward 计算也都差不多,都是进行两次 AllReduce,这里就不再赘述了。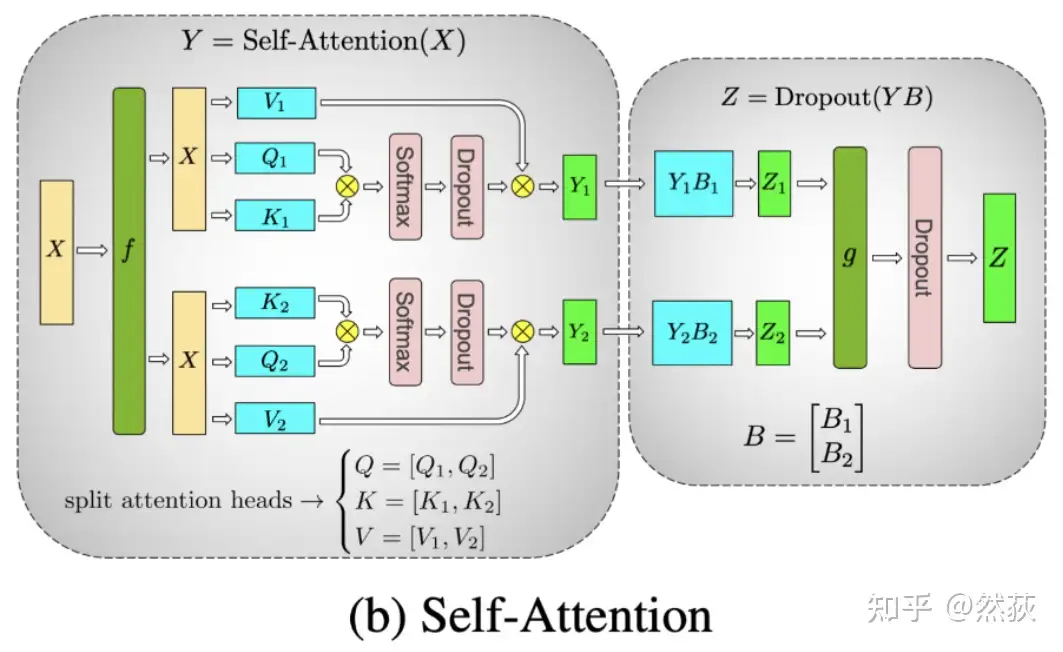
5.1.4 Embedding 嵌入层的张量并行
我们知道,对于 Embedding 层来讲,矩阵维度要么是(V,H)(输入矩阵),要么是(H,V)(输出矩阵)。
我们要对其进行并行分割的最主要原因就是这个 V 词表维度动不动就上十几万,相对于一般的 H 维度(几千维)是完全不在一个数量级。所以我们也只需要牢牢记住,对于 Embedding 层,就是对 V 词表维度进行分割。
对于输入 Embedding 层:
那么我们要从 这个维度拆分这个 ,就会横着切,每一个 GPU 上的权重维度就是
同理也可以分析得出,对于输出 Embedding 层, 会竖着切,每一个 GPU 上的权重维度就是
5.1.5 3D 并行举例分析
这里我会给出一个例子,来帮助大家理解 Megatron 的 3D 并行是如何具体应用的。
假设我们有两台机器,每台机器 8 张 GPU,我们的一个模型需要 8 张 GPU 才能完整装下,假设模型一共 4 层 Linear 层构成。
首先我们先用流水线并行的思路将模型的四层拆开,但是我们发现模型的一层也放不下一个 GPU,所以我们再用到张量并行的思路将每一层的权重一分为二,这时候我们将一个模型拆为八块,正好每一块可以放在一个 GPU 里。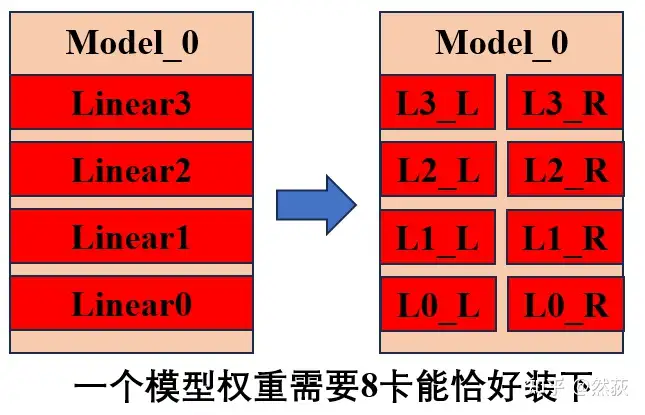 一般而言,通讯量排名是:TP(张量并行) > DP(数据并行) > PP(流水线并行)。通讯量大的部分尽量放入一台机器内,因为 node 内比 node 间带宽高。基于这个考虑,我们进行如下的分割。
一般而言,通讯量排名是:TP(张量并行) > DP(数据并行) > PP(流水线并行)。通讯量大的部分尽量放入一台机器内,因为 node 内比 node 间带宽高。基于这个考虑,我们进行如下的分割。
可以从下图看到,红色和蓝色分别代表两个独立的完整模型被分割为 8 块,L 和 R 对应的就是一层 Linear 层的张量分割模式。可以看到,我们所有成对的 L 和 R 张量并行都是放在一个 Node 里的,要优先保证张量并行的通讯。然后是考虑数据并行和流水线并行,我们将 0、1 两层和 2、3 两层分别置于不同的 Node,因为流水线并行的通讯量相对较少,可以将其分别放在两个 Node。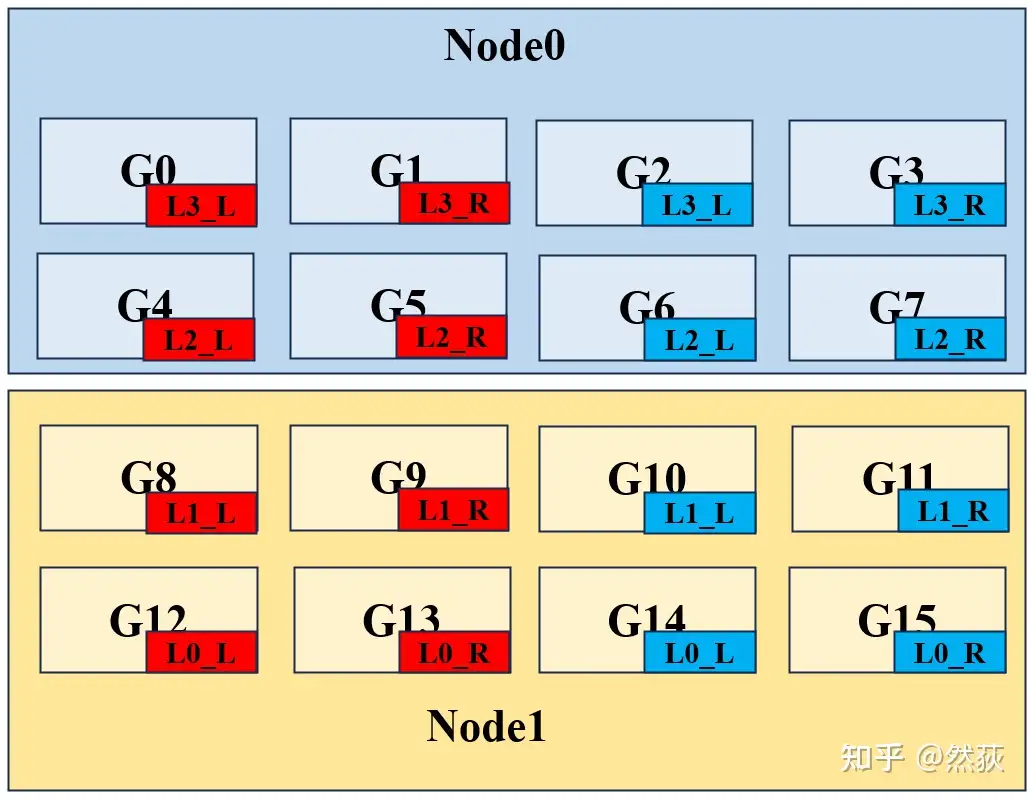
5.2 DeepSpeed
想要很好地理解 DeepSpeed,请一定复习一下之前提到的模型训练的流程和显存占用(2.1 小结)和 GPU 通讯原语(2.2 小结),这样会有更加深刻的理解。
假设我们有一个无限大显存的 GPU,就完全没有数据并行的必要了(这里可以自己思考一下,模型并行为什么是有必要的,即使是有无限大的 GPU),也就是说我们的数据并行,本质上就是利用通讯换取显存的思想,DeepSpeed 大名鼎鼎的 Zero 机制也是基于这样的思想。
可能有了解过 Zero 机制的同学会觉得它的方法更像是模型并行,因为它涉及对优化器参数、模型权重、模型梯度的分割。但 Zero 机制其实是一个数据并行,因为在做 forward 和 backward 的时候,仍然需要完整的模型权重。
模型并行的本质是将一个大的模型权重拆分为多个小的部分,每一个小部分都可以独立地在单张 GPU 上运行;数据并行则是需要一个完整的模型权重(这里的完整模型权重可以是一整个模型,也可以是被拆分过后的一层模型,只要这个模型是独立的就可以)在单张 GPU 上运行,而我们只是想办法塞进更多数据。Zero 机制尽管进行了很多分割,但在 forward 和 backward 时,仍然需要完整的模型权重。现在看不太懂没关系,继续看下去,到后面就会慢慢理解。
模型训练的步骤,我们先一起简单复习一下:
模型权重进行 forward 和 backward,得到梯度。
利用梯度去更新优化器(adam)一阶二阶动量。
优化器更新模型权重。
下面这张图是我之前一直非常纠结的地方,每一个蓝框里的内容都是我以为当前步骤下一定需要的显存。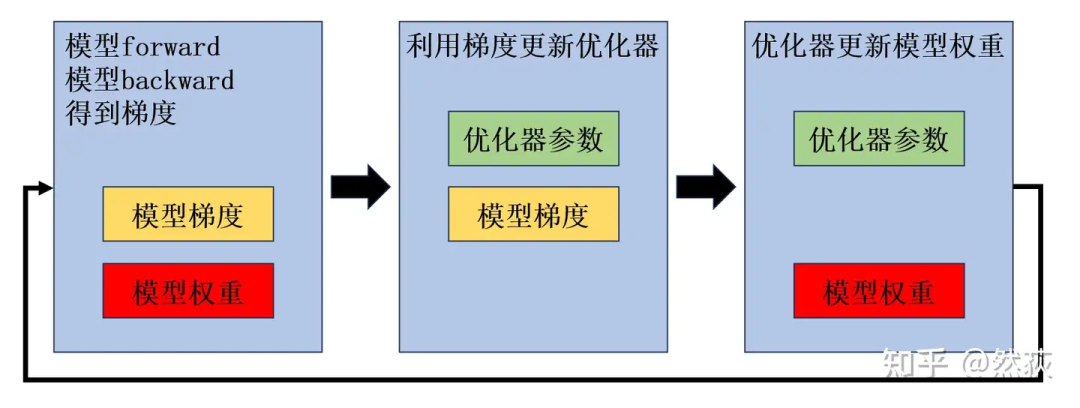
第一张图:backward 的时候,显存一定是有模型权重和模型梯度的,优化器参数其实用不到。
第二张图:在更新优化器一阶二阶动量的时候,其实不需要加载模型权重了。
第三张图:用优化器的一阶二阶动量去更新模型权重时,梯度应该是不需要的,可以释放掉。
但是,实际情况是模型权重、模型梯度、优化器参数一直都占用显存。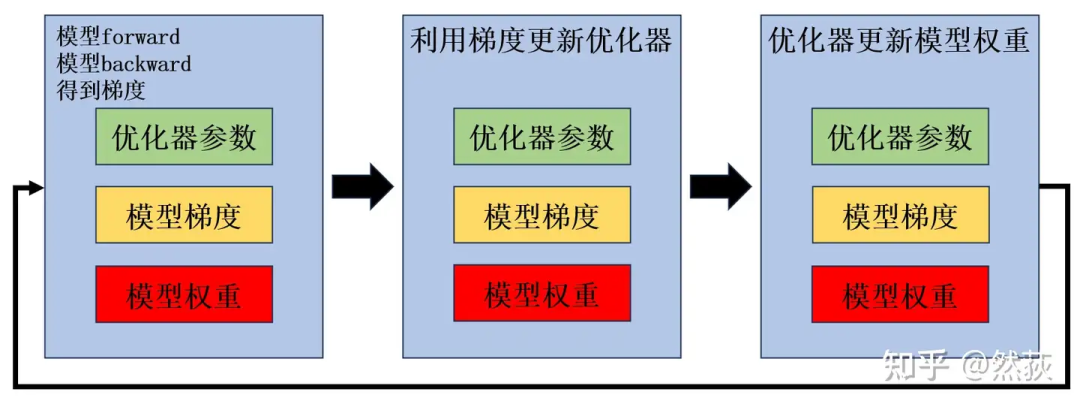
优化器一阶二阶动量参数的意义是存储历史的梯度信息、梯度变化信息,所以它不能被释放掉,要一直占用等待更新。
模型权重是我们要更新的参数,当然也需要一直保存在显存里等待更新。
梯度每一次都不一样,这总可以先释放掉吧?其实也不行,因为第二步和第三步是合在一起的,也就是
optimizer.step()这个函数,需要等更新完权重之后模型梯度才可以释放,但这时候又进入下一次的 forward 和 backward 了,梯度占用也就一直保存了(其实这里我现在也感觉怪怪的,不知道有没有大佬能解答一下,感觉这个梯度理论上应该是可以释放的)。
总之就是,我们实际训练的时候,会多出很多的冗余参数,明明当前阶段用不到但却在占用我们的显存。那么该怎么优化这些冗余呢?答案就是切,分布式切分。切开之后用通讯换取显存,需要的时候就传过来,不需要的时候就释放掉。我们可以切优化器参数、切梯度、切模型权重,这也是所谓的 Zero 123,我们下面将具体介绍。
5.2.1 切优化器(Optimizer States)Zero1
我们以 Ring AllReduce 为基准进行对比,不考虑模型并行进行分析可以更加清晰地理解 Zero 的思路。
设模型的参数量是 ,GPU 总数为 ,模型权重的显存是 ,模型梯度的显存是 ,模型优化器的显存是 (因为优化器可以用不同的,Adam 占用 ,占用非常多,这也是为什么要先切优化器)。 我们通过下面的动图和步骤来理解 Zero1 切优化器之后是如何训练的:
我们通过下面的动图和步骤来理解 Zero1 切优化器之后是如何训练的:
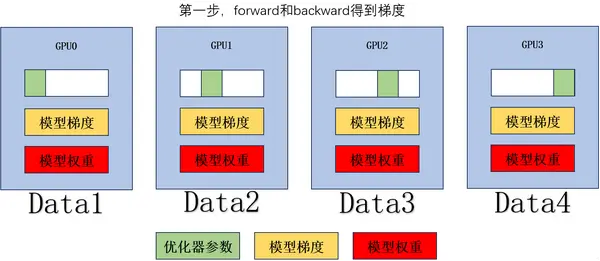
forward 和 backward 得到梯度。
对梯度做 Ring AllReduce,得到平均梯度,单个 GPU 通讯量 。
根据优化器参数和对应的模型梯度更新对应的模型权重。
对模型权重的更新部分做 AllGather,单个 GPU 通讯量 。
 最后我们来补充下面这个表格,很好理解,优化器部分的显存除以 ,被分布到各个 GPU 上,单卡通讯量在刚才的步骤分析里可以得出是增加到 。
最后我们来补充下面这个表格,很好理解,优化器部分的显存除以 ,被分布到各个 GPU 上,单卡通讯量在刚才的步骤分析里可以得出是增加到 。 有细心的人会发现,这个阶段有个明显的可优化的点:注意看第三步在每一个 GPU 上我们其实只用到了一部分的模型梯度,也就是虚线框里的梯度,其他的就是冗余的部分。这其实就是接下来 Zero2 要进行优化的点:对梯度进行拆分。
有细心的人会发现,这个阶段有个明显的可优化的点:注意看第三步在每一个 GPU 上我们其实只用到了一部分的模型梯度,也就是虚线框里的梯度,其他的就是冗余的部分。这其实就是接下来 Zero2 要进行优化的点:对梯度进行拆分。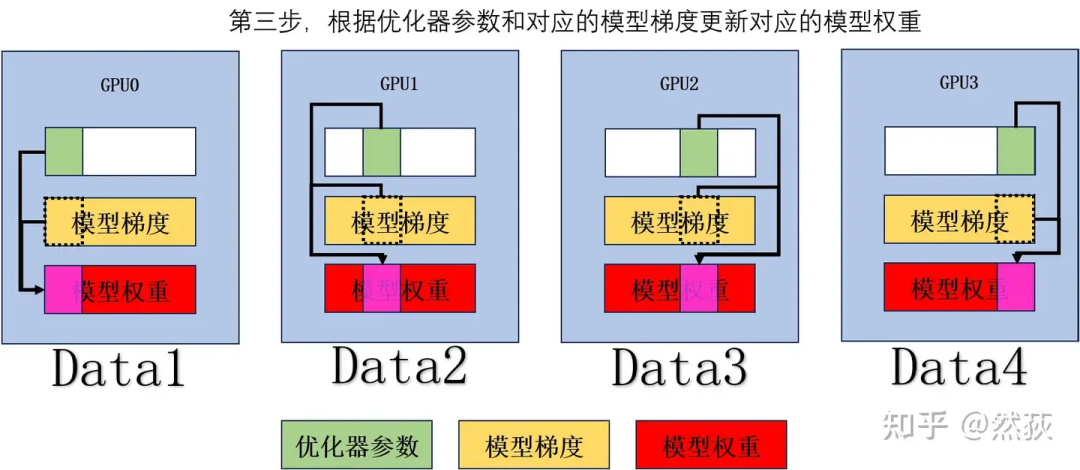
5.2.2 切梯度(Gradients)Zero2
我们直接上步骤和动图,大家可以结合前面的通讯原语言慢慢理解,还是挺有意思的:
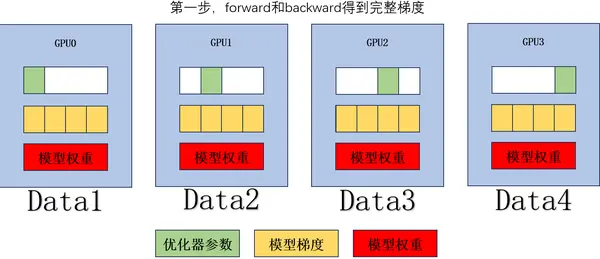
forward 和 backward 得到完整梯度。
对梯度进行 ReduceScatter,单个 GPU 通讯量 。
根据部分梯度以及对应的优化器参数,更新对应模型的部分权重。
对模型权重进行 AllGather 操作,单个 GPU 通讯量 。
 再来补充一下显存和通讯量的表格:
再来补充一下显存和通讯量的表格: 有的人会注意到在第一步的时候,在 ReduceScatter 之前我们不是得到了完整的梯度吗?那这个时候我们的显存应该是 才对啊,那么显存的上限不应该还是这么多吗?我认为是用到了 CPU 内存去作为一个暂时缓存的 buffer,缓存马上就要被 ReduceScatter 的梯度。因为在后面我们会给出的官方视频里,也可以看到模型在做 AllGather 之后会有一个 temporary buffer 去暂存。
有的人会注意到在第一步的时候,在 ReduceScatter 之前我们不是得到了完整的梯度吗?那这个时候我们的显存应该是 才对啊,那么显存的上限不应该还是这么多吗?我认为是用到了 CPU 内存去作为一个暂时缓存的 buffer,缓存马上就要被 ReduceScatter 的梯度。因为在后面我们会给出的官方视频里,也可以看到模型在做 AllGather 之后会有一个 temporary buffer 去暂存。
很神奇的发现 Zero2 相比于 Ring AllReduce,用的通讯量是一样的,显存占用却省了很多,这就是所谓的去冗余的效果。
5.2.3 切模型权重(Parameters)Zero3
这一部分本来也想做一个 GIF 图去展示,但画图的时候遇到了一些疑惑,然后就发现了下面这个官方的演示视频,实在是太过清晰明了了,如果你认真看懂了前面的内容,那么这个视频会非常容易地看懂,非常棒的视频。
个人建议一定要看一下,我之前看很多博客介绍都没看明白,一看这个视频就懂了。仔细想想,这个动态实现的方式确实很难用语言去没有歧义地描述。相信我,看这个视频绝对比你去慢慢琢磨那些博客更快。
总结一下:
从整个流程来看,模型权重进行了两次 AllGather,对梯度做了一次 ReduceScatter。但这里的 AllGather 和 ReduceScatter 跟之前不太一样,它是和 forward、backward 整个流程交叉着进行的,这一点真的要结合视频细细体会,你会恍然大悟。 终于我们得到了《 ZeRO: Memory Optimizations Toward Training Trillion Parameter Models 》论文里这张总结的大图,是否感觉一切明了了。
终于我们得到了《 ZeRO: Memory Optimizations Toward Training Trillion Parameter Models 》论文里这张总结的大图,是否感觉一切明了了。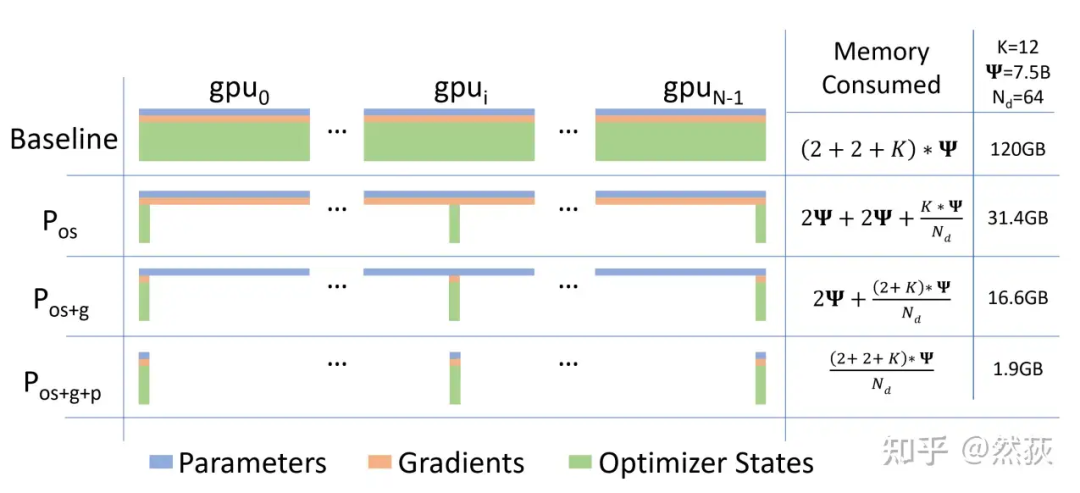
6. 总结
本来只想简单地勾勒出整个技术链路的逻辑,没想到写了这么多的内容,累鼠我了。感觉也没啥好总结的了,就先这样吧,有什么漏洞和问题的后面再补。毕竟要先做一坨屎出来,然后再慢慢修改是最好的。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦



![[数据集][目标检测]猪数据集VOC-2856张](https://i-blog.csdnimg.cn/direct/c66b9af20bd74637a464467054af8f45.png)


