前不久,在“Gopher部落”知识星球[1]上回答了一个Gopher关于深拷贝(Deep Copy)的问题,让我感觉是时候探讨一下深拷贝技术了。
在日常开发工作中,深拷贝的使用频率相对较低,可能有80%的时间不需要使用深拷贝,只有在特定情况下才会遇到。这主要是因为大多数开发中处理的对象比较简单,通常只需使用浅拷贝(Shallow Copy)就能满足需求;此外,多数时候我们需要共享状态或数据,使用浅拷贝可以方便多个部分访问同一数据;最后,深拷贝通常比浅拷贝耗时更多,尤其是当对象嵌套较深时。因此,开发者倾向于选择更高效的浅拷贝。
说了这么多,那究竟什么是深拷贝以及浅拷贝呢?深拷贝又是在哪些场合下适用呢?在Go中如何实现深拷贝呢?带着这些问题,我们在本文中就来探讨一下Go语言中的深拷贝技术,希望能让大家对深拷贝技术的概念、实现以及局限有一个全面的了解。
1. 从细胞分裂看深拷贝
我们在初中生物课上都学过细胞分裂(Cell Division),有条件的学校的学生可以用显微镜观看到细胞分裂的全过程,大致就如下图所示:
我们知道细胞分裂复制了整个细胞的所有成分,包括细胞核、细胞质等,生成了一个完全独立的新细胞。无论原始细胞如何变化,分裂出的新细胞不会受到影响。而深拷贝就像是真正的细胞分裂,完全复制了原对象及其内部所有嵌套对象的数据,使新对象和原对象相互完全独立,各自演进,互不影响。
下面,我将使用Go语言给出一个结构体类型的示例,并用示意图直观展示深拷贝和浅拷贝的区别:
// Address 结构体
type Address struct {City stringState string
}// Person 结构体
type Person struct {Name stringAge intAddress *Address
}这里定义了Address和Person两个结构体,其中Person包含一个指向Address的指针(这可以理解为Person结构体的嵌套对象)。我们先来创建一个原始对象:
// 创建原始 Person 实例
original := Person{Name: "Alice",Age: 30,Address: &Address{City: "New York",State: "NY",},
}基于这个原始对象,我们可以使用下面代码创建一个浅拷贝的对象:
shallowCopy := original下面是浅拷贝完毕的对象关系示意图:
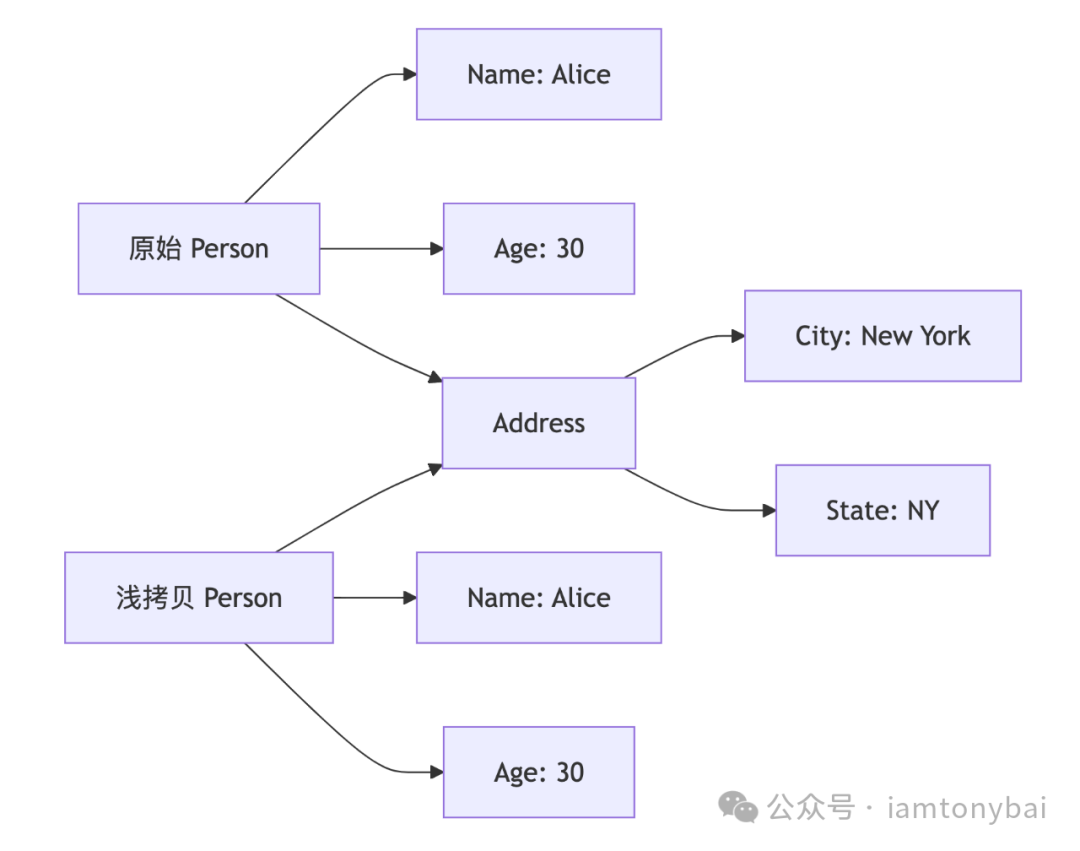
我们看到浅拷贝后,两个Person对象虽然有部分字段已经完全独立分开(Name和Age),但仍然存在关联,那就是Address字段指向了同一个Address对象。这样无论是原始对象修改了Address,还是浅拷贝后的对象修改了Address,都会对另一个对象产生影响。
我们再来看看深拷贝,这里为Person结构体增加了深拷贝的方法,然后通过该方法得到一个深拷贝后的对象:
// DeepCopy方法
func (p Person) DeepCopy() Person {newPerson := pif p.Address != nil {newAddress := *p.AddressnewPerson.Address = &newAddress}return newPerson
}deepCopy := original.DeepCopy()我们看到:DeepCopy方法实现了对Person的深拷贝,它不仅复制了Person结构体,还创建了一个新的Address结构体并复制了其内容。这样原始对象与深拷贝出的对象就完全分开了,下面是深拷贝后的对象关系示意图:
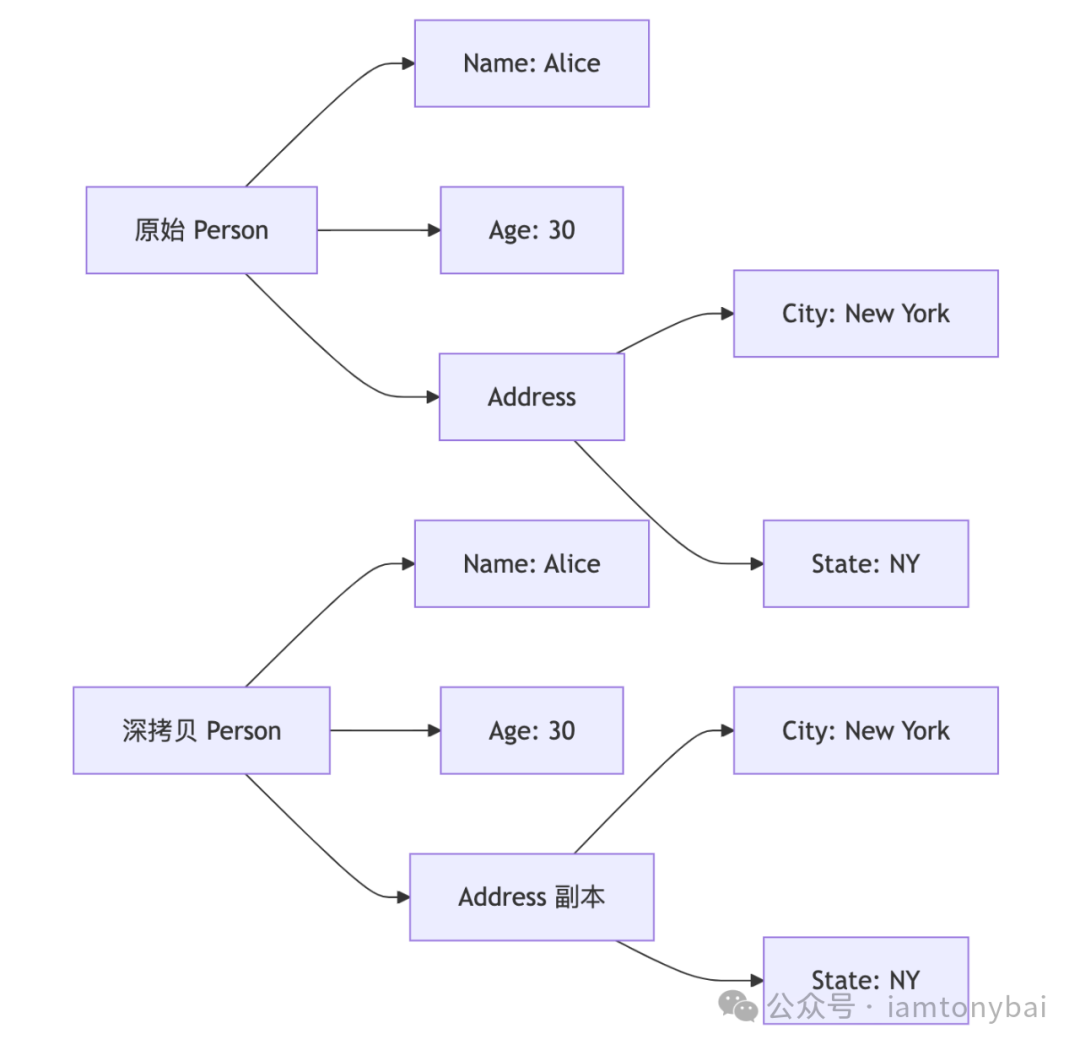
通过上面的示意图,我们可以将深拷贝与浅拷贝的对比整理如下:
浅拷贝(Shallow Copy)
创建一个新对象,并复制原对象的字段值,但对于引用类型(如指针、切片、map等),仅复制引用,不复制引用的对象。通常通过简单的赋值操作就能实现浅拷贝。
深拷贝(Deep Copy)
创建一个新对象,递归地复制原对象的所有字段值,对于引用类型,创建新的对象并复制其内容,而不是简单地复制引用。通常,深拷贝需要额外编写代码实现,简单的赋值操作对于复杂类型而言,无法实现深拷贝。
很显然就像在本文开始时所说的那样,我们日常使用最多的就是浅拷贝,浅拷贝的实现也是非常简单的,通过赋值语句就可以。那么我们为什么还需要深拷贝呢?或者说,在什么场景下需要使用到深拷贝呢?下面我就就来看看。
2. 为什么需要深拷贝?
根据上面提到的深拷贝的特点:独立与隔离,当数据的独立性和隔离性非常重要时,它能避免共享数据引发的副作用。据此,以下是需要使用深拷贝的常见场景,我们逐一简要说明一下。
2.1 防止意外修改共享数据
在Go语言中,切片、map和指针都是引用类型。如果多个对象引用同一个底层数据结构,修改其中一个对象的数据会影响所有引用该数据的对象。因此,在这些场合下,如果希望避免修改一个对象时影响其他对象,使用深拷贝是必需的。
下面这个Go例子中,shallowCopy和original共享同一个Data map,修改shallowCopy的数据会直接影响original。通过深拷贝Data map,deepCopy保持了数据的独立性:
package mainimport "fmt"type Config struct {Port intData map[string]string
}func main() {original := &Config{Port: 8080,Data: map[string]string{"key1": "value1"},}shallowCopy := original // 只是浅拷贝,共享Data引用// 深拷贝 DatadeepCopy := &Config{Port: original.Port,Data: make(map[string]string),}for k, v := range original.Data {deepCopy.Data[k] = v}shallowCopy.Data["key1"] = "modified" // 修改会影响originalfmt.Println(original.Data["key1"]) // 输出 "modified"deepCopy.Data["key1"] = "deepModified" // 修改不会影响originalfmt.Println(original.Data["key1"]) // 输出 "modified"
}2.2 并发编程中的数据隔离
Go语言利用goroutine进行并发编程。当多个goroutine操作相同的数据时,可能会导致竞争条件和数据一致性问题。如果每个goroutine都需要独立的数据副本,那么深拷贝是确保数据隔离的最佳方法。
下面这个示例就是在并发场景下,使用append深拷贝切片,确保每个goroutine操作的是独立的data副本,避免数据竞争:
package mainimport "fmt"func worker(data []int, ch chan []int) {// 深拷贝切片,避免影响其他 goroutinenewData := append([]int(nil), data...)for i := range newData {newData[i] *= 2 // 修改数据}ch <- newData
}func main() {data := []int{1, 2, 3}ch := make(chan []int)go worker(data, ch) // 启动goroutinego worker(data, ch) // 启动另一个goroutineresult1 := <-chresult2 := <-chfmt.Println(result1) // goroutine 1的独立数据副本 [2 4 6]fmt.Println(result2) // goroutine 2的独立数据副本 [2 4 6]
}2.3 不可变对象需求
Go目前不直接支持不可变对象,但在某些场合(如函数式编程[2]或安全性要求较高的应用),不可变性是很有用的。如果你希望传递给某个函数的数据不能被修改,那么需要在传递前对数据进行深拷贝。
下面示例通过深拷贝,保证original的数据在传递过程中不会被修改,保证了不可变性:
package mainimport "fmt"type ImmutableData struct {Values []int
}// 修改函数
func modifyData(data ImmutableData) {data.Values[0] = 100 // 尝试修改
}func main() {original := ImmutableData{Values: []int{1, 2, 3},}// 传递之前进行深拷贝copyData := ImmutableData{Values: append([]int(nil), original.Values...),}modifyData(copyData)fmt.Println(original.Values) // 输出 [1 2 3],original数据保持不变
}2.4 回滚机制或撤销操作
在涉及事务处理或编辑器等场景中,Go开发者常需要在操作前保存对象的快照,以便在出现错误或用户撤销操作时恢复到原状态。这时候,深拷贝用于保存独立的状态副本。下面示例使用了更复杂的数据结构来展示深拷贝的作用,并体现了在实际应用中如何通过深拷贝实现状态的回滚机制:
package mainimport ("encoding/json""fmt"
)// State 结构体包含嵌套结构体和引用类型
type State struct {Value stringData []intMetadata *Metadata
}// Metadata 是嵌套的引用类型结构体
type Metadata struct {Version intAuthor string
}// 深拷贝函数,通过JSON序列化与反序列化实现
func deepCopy(original *State) *State {copy := &State{}bytes, _ := json.Marshal(original)_ = json.Unmarshal(bytes, copy)return copy
}func main() {// 初始化原始状态state := &State{Value: "initial",Data: []int{1, 2, 3},Metadata: &Metadata{Version: 1,Author: "Alice",},}// 保存当前状态的深拷贝backup := deepCopy(state)// 修改状态state.Value = "modified"state.Data[0] = 100state.Metadata.Version = 2// 输出修改后的状态fmt.Println("Current state:", state.Value) // 输出 "modified"fmt.Println("Current Data:", state.Data) // 输出 "[100 2 3]"fmt.Println("Current Metadata.Version:", state.Metadata.Version) // 输出 "2"// 恢复之前的状态state = backup// 输出恢复后的状态fmt.Println("Restored state:", state.Value) // 输出 "initial"fmt.Println("Restored Data:", state.Data) // 输出 "[1 2 3]"fmt.Println("Restored Metadata.Version:", state.Metadata.Version) // 输出 "1"
}在这个场景中,backup是对state的深拷贝,确保可以在需要时恢复到原始状态。
在以上这些场景中,深拷贝虽然开销较大,但它确保了数据的独立性、隔离性以及安全性。当然,深拷贝适用的场景可能不止这些,这里也无法穷举所有场景。
知道了深拷贝的一些应用场景后,我们再来梳理一下如何在Go中实现深拷贝,其实在上面的示例中已经见过不少深拷贝的实现方法了。
3. Go语言中实现深拷贝的方法
在Go语言中,实现深拷贝有几种常见的方法,每种方法都有其优缺点和适用场景。让我们逐一探讨这些方法。
3.1 手动实现深拷贝
赋值操作通常无法实现复杂结构的深拷贝,因此最常见的深拷贝实现方法就是像上面示例中那样根据具体的类型手动实现深拷贝。手动实现深拷贝是最直接但也可能是最繁琐的方法,通常我们要为每种要深拷贝的类型单独编写深拷贝函数DeepCopy(Go没有像Java那样有object基类,因此也没有内置的clone方法去override)。
关于手动实现深拷贝DeepCopy方法的示例在前面我们已经见识过了,比如最开始的那个Person类型DeepCopy方法。
手动实现深拷贝的优点显而易见,那就是开发者可以完全控制拷贝的过程,并且性能通常较好,可以避免使用反射[3]等有额外开销的机制来实现。
当然不足也很明显,那就是我们需要为每个要支持深拷贝的类型都维护一个单独的实现,并且对于带有复杂嵌套结构的类型,这个实现还会很冗长和复杂。
当是否可以有“万能”的深拷贝函数呢?我们继续往下看。
3.2 使用反射实现通用深拷贝
借助Go的reflect大法,我们可以实现一个通用的深拷贝函数,理论上,可以适用于各种类型。下面是一个示例实现(仅是示例,不要用在生产中):
package mainimport ("fmt""reflect"
)// 深拷贝函数,使用 reflect 递归处理各种类型
func DeepCopy(src interface{}) interface{} {if src == nil {return nil}// 通过 reflect 获取值和类型value := reflect.ValueOf(src)typ := reflect.TypeOf(src)switch value.Kind() {case reflect.Ptr:// 对于指针,递归处理指针指向的值copyValue := reflect.New(value.Elem().Type())copyValue.Elem().Set(reflect.ValueOf(DeepCopy(value.Elem().Interface())))return copyValue.Interface()case reflect.Struct:// 对于结构体,递归处理每个字段copyValue := reflect.New(typ).Elem()for i := 0; i < value.NumField(); i++ {fieldValue := DeepCopy(value.Field(i).Interface())copyValue.Field(i).Set(reflect.ValueOf(fieldValue))}return copyValue.Interface()case reflect.Slice:// 对于切片,递归处理每个元素copyValue := reflect.MakeSlice(typ, value.Len(), value.Cap())for i := 0; i < value.Len(); i++ {copyValue.Index(i).Set(reflect.ValueOf(DeepCopy(value.Index(i).Interface())))}return copyValue.Interface()case reflect.Map:// 对于映射,递归处理每个键值对copyValue := reflect.MakeMap(typ)for _, key := range value.MapKeys() {copyValue.SetMapIndex(key, reflect.ValueOf(DeepCopy(value.MapIndex(key).Interface())))}return copyValue.Interface()default:// 其他类型(基本类型,数组等)直接返回原始值return src}
}type Address struct {Street stringCity string
}type Person struct {Name stringAge intAddress *Address
}func main() {// 初始化原始对象original := &Person{Name: "Alice",Age: 30,Address: &Address{Street: "123 Go St",City: "Golang City",},}// 使用 reflect 实现的通用深拷贝copy := DeepCopy(original).(*Person)// 修改拷贝对象的值copy.Address.City = "New City"copy.Age = 31// 输出结果fmt.Println("Original Addr:", original.Address) // 输出 &{123 Go St Golang City}fmt.Println("Copy Addr:", copy.Address) // 输出 &{123 Go St New City}
}我们看到,在示例中,reflect包可以在运行时检查和操作Go的值。通过reflect.ValueOf(src)获取到值后,根据值的类型(指针、结构体、切片、map等)再递归进行深拷贝。如果遇到指针类型,DeepCopy将递归地拷贝指向的值,新的值通过reflect.New创建;对于结构体类型,它通过NumField()遍历字段,并递归地深拷贝该字段;对切片进行深拷贝时,首先使用reflect.MakeSlice()创建新的切片,再递归处理每个元素;对于map,它用reflect.MakeMap()创建新的map,并递归处理键值对。
使用reflect包实现深拷贝的优点十分明显,那就是通用性强,能够处理各种数据结构(如指针、结构体、切片、map等),无需为每个类型单独实现DeepCopy方法。但由于使用了reflect,其带来的额外开销也是不可忽视的,尤其是对于嵌套很深的复杂类型。
有些情况是reflect无法正确处理的,比如被拷贝的类型中带有非导出字段时(比如给Person结构体增加一个gender字段),上面的反射版DeepCopy实现就会抛出panic:
panic: reflect.Value.Interface: cannot return value obtained from unexported field or method此外,实现一个生产级的DeepCopy并非易事,我们可以找一些“久经考验”的第三方库,比如下面的jinzhu/copier。
3.3 使用第三方库
有一些第三方库提供了深拷贝功能,例如github.com/jinzhu/copier,这类库通常结合了反射和一些优化技巧。在经过广泛的使用和反馈后,可以在生产中使用,并且可以覆盖大多数需求场景。
下面是使用copier实现对带有非导出字段的结构体类型的深拷贝:
package mainimport ("fmt""github.com/jinzhu/copier"
)type Person struct {Name stringAge intAddress *Addressgender string
}type Address struct {Street stringCity string
}func main() {addr := Address{Street: "Go 101 street",City: "Mars Capital",}original := Person{Name: "Alice",Age: 30,Address: &addr,gender: "female",}fmt.Println(original) // 输出:{Alice 30 0xc0000b0000 female}var copied Personerr := copier.CopyWithOption(&copied, &original, copier.Option{DeepCopy: true,})if err != nil {fmt.Println(err)return}fmt.Println(copied) // 输出:{Alice 30 0xc0000b0020 female}
}copier是怎么做到的呢?翻看copier源码[4],可以找到这样一个函数:
func copyUnexportedStructFields(to, from reflect.Value) {if from.Kind() != reflect.Struct || to.Kind() != reflect.Struct || !from.Type().AssignableTo(to.Type()) {return}// create a shallow copy of 'to' to get all fieldstmp := indirect(reflect.New(to.Type()))tmp.Set(from)// revert exported fieldsfor i := 0; i < to.NumField(); i++ {if tmp.Field(i).CanSet() {tmp.Field(i).Set(to.Field(i))}}to.Set(tmp)
}我们看到copyUnexportedStructFields函数首先检查源值和目标值是否都是结构体,并且源类型是否可以赋值给目标类型。如果可以赋值,则创建一个目标类型的新实例tmp,并将源值完整地设置到这个新实例中。这一步可以复制所有字段,包括非导出字段。接下来,遍历目标结构体的所有字段。对于可以设置的字段(即导出字段),将原始目标值中的对应字段值设置回tmp。最后,将tmp设置回原始目标值。
这个过程巧妙地利用了Go语言的反射机制。通过创建一个新的结构体实例并直接设置整个源值,它可以绕过Go语言对非导出字段的访问限制。然后,通过只恢复导出字段的原始值,保持了目标结构体中导出字段的完整性,同时保留了源结构体中非导出字段的值。
然而,这种方法也有一些潜在的限制,比如对于包含指针或引用类型的非导出字段,这种方法就无法真正实现深拷贝,我们改造一下上面的示例:
type Person struct {Name stringAge intAddress *Addressgender *string
}type Address struct {Street stringCity string
}func (p *Person) SetGender(gender string) {p.gender = &gender
}
func (p *Person) Gender() *string {return p.gender
}func main() {addr := Address{Street: "Go 101 street",City: "Mars Capital",}original := Person{Name: "Alice",Age: 30,Address: &addr,}original.SetGender("female")fmt.Println(original) // 输出:{Alice 30 0xc00006a020 0xc000014070}fmt.Println(original.Gender()) // 输出:0xc000014070var copied Personerr := copier.CopyWithOption(&copied, &original, copier.Option{DeepCopy: true,})if err != nil {fmt.Println(err)return}fmt.Println(copied) // 输出:{Alice 30 0xc00006a040 0xc000014070}fmt.Println(copied.Gender()) // 输出:0xc000014070
}这里我们在Person类型中增加了一个字符串指针类型的非导出字段gender,我们看到通过copier进行拷贝的结果并不符合深拷贝的要求,copied和original使用了同一个gender了。因此,像jinzhu/copier这样的第三方库,虽然能处理大多数常见情况,但我们仍要明确它的局限。
不过即便有了上述三类实现深拷贝的方法,有些时候要在Go中实现完美的深拷贝也是很难的,甚至是不可能的,下面我们来看看Go语言中深拷贝的局限性。
4. Go语言中深拷贝的局限性
我们先从已经遇到过的非导出字段说起。
4.1 无法访问的非导出字段
就像上面示例中那样,如果原类型中带有非导出字段,那么有些时候即便使用jinzhu/copier这样的第三方通用拷贝库也很难实现真正的深拷贝。如果原类型在你的控制下,最好的方法是为原类型手动添加一个DeepCopy方法供外部使用。
不过,即便如此,某些情况下,手工实现一个DeepCopy方法也是很难的,甚至是不可能的,我们看下面两种局限的情况。
4.2 循环引用问题
当原类型中存在循环引用时,简单的递归深拷贝可能会导致无限循环。例如:
type Node struct {Value intNext *NodePrev *Node
}func main() {node1 := &Node{Value: 1}node2 := &Node{Value: 2}node1.Next = node2node2.Prev = node1// 这里的深拷贝可能会导致无限递归
}针对这样的带有循环引用的类型,我们通常会手工实现其DeepCopy方法,并通过使用类似哈希表的方式记录已经复制过的对象,下面是一个Node结构体的DeepCopy的示例实现:
package mainimport ("fmt"
)// Node表示双向链表的节点
type Node struct {Value intNext *NodePrev *Node
}// DeepCopy方法:对Node进行深拷贝
func (n *Node) DeepCopy() *Node {// 初始化visited map用于记录已访问的节点,防止无限递归visited := make(map[*Node]*Node)return n.deepCopyRecursive(visited)
}// deepCopyRecursive私有递归方法,内部处理深拷贝逻辑
func (n *Node) deepCopyRecursive(visited map[*Node]*Node) *Node {// 如果节点为空,返回nilif n == nil {return nil}// 如果节点已经被拷贝过,直接返回拷贝的引用if copyNode, found := visited[n]; found {return copyNode}// 创建当前节点的拷贝,并将其加入已访问mapcopyNode := &Node{Value: n.Value}visited[n] = copyNode// 递归拷贝下一个和前一个节点copyNode.Next = n.Next.deepCopyRecursive(visited)copyNode.Prev = n.Prev.deepCopyRecursive(visited)return copyNode
}func main() {// 创建包含循环引用的双向链表node1 := &Node{Value: 1}node2 := &Node{Value: 2}node1.Next = node2node2.Prev = node1// 进行深拷贝copyNode1 := node1.DeepCopy()// 修改拷贝对象,确保原始对象不受影响copyNode1.Next.Value = 3// 输出原始链表和拷贝链表的指针地址,验证深拷贝是否成功fmt.Println("Original node1 address:", node1)fmt.Println("Original node1.Next address:", node1.Next)fmt.Println("Original node2.Prev address:", node2.Prev)fmt.Println("Copied node1 address:", copyNode1)fmt.Println("Copied node1.Next address:", copyNode1.Next)fmt.Println("Copied node2.Prev address:", copyNode1.Next.Prev)
}运行这段示例程序会得到下面结果:
Original node1 address: &{1 0xc00011c018 <nil>}
Original node1.Next address: &{2 <nil> 0xc00011c000}
Original node2.Prev address: &{1 0xc00011c018 <nil>}
Copied node1 address: &{1 0xc00011c048 <nil>}
Copied node1.Next address: &{3 <nil> 0xc00011c030}
Copied node2.Prev address: &{1 0xc00011c048 <nil>}下面再说一种极端情况,导致我们即便手工实现也无法实现深拷贝。
4.3 某些类型不支持拷贝
Go语言的某些内置类型或标准库中的类型,比如sync.Mutex、time.Timer等不应该被复制,复制这些类型可能会导致未定义的行为。
type Resource struct {Data stringmutex sync.Mutex
}// 错误的深拷贝方式
func (r *Resource) DeepCopy() *Resource {return &Resource{Data: r.Data,mutex: r.mutex, // 不应该复制 mutex}
}对于这样的包含不支持拷贝的类型,我们在不改变源类型组成的情况下,无法实现深拷贝。
除了上面三种情况外,有些时候性能也是使用深拷贝时需要考量的点,尤其是当你使用反射实现的通用深拷贝技术时,可能会带来显著的性能开销。尤其是在关键路径上处理大型数据结构或频繁操作时,这可能成为一个问题。
如果在使用深拷贝时遇到性能问题,可以考虑通过手动编写深拷贝逻辑替代反射、使用对象池或预分配的方式缓存并优化内存分配,减少深拷贝的次数,甚至是针对复杂类型或数据结构的并发拷贝来优化,这些需要视具体场景来确定优化策略,这里就不展开了。
5. 深拷贝(Deep Copy)vs. 克隆(Clone)
最后再来说一下深拷贝(Deep Copy)和克隆(Clone)。它们都是复制对象的概念,但它们在概念和实现细节上存在一些差异。
通过上面说明,我们知道深拷贝是一种递归的复制过程,不仅复制对象本身,还会复制该对象所有引用的其他对象。这意味着所有的对象层级都会被独立地复制,最终形成一个完全独立的新对象,原对象和拷贝之间不存在任何共享的内存。
而克隆是指复制一个对象。其行为依赖于具体语言的实现方式。对于某些语言,克隆可能指的是浅拷贝(Shallow Copy),即只复制对象的基础数据字段,引用类型字段仍然指向原始对象。也有些语言将克隆定义为深拷贝,取决于上下文。比如在Java中,Object类提供了clone()方法,默认是浅拷贝,用户可以通过实现Cloneable接口来自定义克隆的行为,比如实现为深拷贝的逻辑。
因此,当目标对象在结构上与原对象一致的情况下,可以将深拷贝理解为一种特定类型的克隆。但在一些场景下(比如RPC),深拷贝不仅仅是简单的在内存中深度复制自身,而是需要考虑源对象和目的对象之间的结构差异和数据转换逻辑,本文并未覆盖这类场景,大家可以自行脑补。
5. 小结
在本文中,我们深入探讨了Go语言中的深拷贝概念、实现方法以及局限性。深拷贝在需要对象之间完全独立的场景中尤为重要,尤其是在防止意外修改共享数据、并发编程、不可变对象需求、回滚机制等情况下。我们介绍了手动实现深拷贝、利用反射的通用深拷贝方法以及使用第三方库的不同实现方式,并分析了每种方法的优缺点。
尽管深拷贝提供了数据的独立性和安全性,但在实现过程中也面临一些挑战,包括无法访问非导出字段、循环引用的问题,以及某些类型不支持拷贝的限制。性能问题也是一个需要考虑的因素,特别是在处理复杂数据结构时。
通过对深拷贝的理解,我希望大家能够在实际开发中更有效地使用这一技术,并根据具体需求选择合适的实现方式,从而优化代码质量和程序性能。
往期推荐
- Go语言的“黑暗角落”:盘点学习Go语言时遇到的那些陷阱
- Go语言反射编程指南
- 使用反射操作channel
- 为什么这个T类型实例无法调用*T类型的方法
- htmx:Gopher走向全栈的完美搭档?
Gopher部落知识星球[5]在2024年将继续致力于打造一个高品质的Go语言学习和交流平台。我们将继续提供优质的Go技术文章首发和阅读体验。同时,我们也会加强代码质量和最佳实践的分享,包括如何编写简洁、可读、可测试的Go代码。此外,我们还会加强星友之间的交流和互动。欢迎大家踊跃提问,分享心得,讨论技术。我会在第一时间进行解答和交流。我衷心希望Gopher部落可以成为大家学习、进步、交流的港湾。让我相聚在Gopher部落,享受coding的快乐! 欢迎大家踊跃加入!




著名云主机服务厂商DigitalOcean发布最新的主机计划,入门级Droplet配置升级为:1 core CPU、1G内存、25G高速SSD,价格5$/月。有使用DigitalOcean需求的朋友,可以打开这个链接地址[6]:https://m.do.co/c/bff6eed92687 开启你的DO主机之路。
Gopher Daily(Gopher每日新闻) - https://gopherdaily.tonybai.com
我的联系方式:
微博(暂不可用):https://weibo.com/bigwhite20xx
微博2:https://weibo.com/u/6484441286
博客:tonybai.com
github: https://github.com/bigwhite
Gopher Daily归档 - https://github.com/bigwhite/gopherdaily
Gopher Daily Feed订阅 - https://gopherdaily.tonybai.com/feed

商务合作方式:撰稿、出书、培训、在线课程、合伙创业、咨询、广告合作。
参考资料
[1]
“Gopher部落”知识星球: https://public.zsxq.com/groups/51284458844544
[2]函数式编程: https://tonybai.com/2024/08/11/understand-functional-programming-in-go/
[3]反射: https://tonybai.com/2023/06/04/reflection-programming-guide-in-go
[4]copier源码: https://github.com/jinzhu/copier/blob/master/copier.go
[5]Gopher部落知识星球: https://public.zsxq.com/groups/51284458844544
[6]链接地址: https://m.do.co/c/bff6eed92687