文章目录
- 一、Maven
- 1.1 Maven 简介:
- 1.2 Maven 的核心功能:
- 1.2.1 项目构建:
- 1.2.2 依赖管理:
- 1.3 Maven 仓库:
- 1.3.1 本地仓库:
- 1.3.2 中央仓库:
- 1.3.3 私服:
- 二、第一个 SpringBoot 程序
- 2.1 Spring Boot介绍:
- 2.2 Spring Boot 项目创建:
- 2.3 目录介绍:
- 2.4 输出 Hello world:
- 三、Web 服务器
- 四、总结
首先环境准备:IDEA 专业版。
社区版要弄很多东西(版本,配 spring 之类的),IDEA 专业版可以网上找找破解版。
在 Java Web 这里,大部分概念都只要了解即可,不用记。
一、Maven
这部分内容,不涉及实战,主要是一些重要概念的介绍。
1.1 Maven 简介:
官方对于 Maven 的描述:

引用来自:Maven 官网
翻译过来就是:
Maven 是一个项目管理工具。基于 POM (Project Object Model,项目对象模型)的概念,Maven 可以通过一小段描述信息来管理项目的构建,报告和文档的项目管理工具软件。
POM 简介:
每一个 Maven 工程都有一个 pom.xml 文件,位于根目录中,包含项目构建生命周期的详细信息。通过 pom.xml 文件,我们可以定义项目的坐标、项目依赖、项目信息、插件信息等等配置。
简单来说:Maven 是一个项目管理工具,通过 pom.xml 文件的配置获取 jar 包,而不用手动去添加 jar 包。
Maven 的作用:
一句话:简单,方便,提高我们的开发效率,减少我们的开发 Bug。
1.2 Maven 的核心功能:
Maven 提供的功能非常多,主要体现在下面两个方面。
- 项目构建
- 管理依赖
1.2.1 项目构建:
Maven 提供了标准的,跨平台(Linux,Windows,MacOS等)的自动化项目构建方式。
当我们开发了一个项目之后,代码需要经过编译,测试,打包,发布等流程,每次代码的修改,都需要经过这些流程,如果代码反复调试修改,这个流程就需要反复进行,就显得特别麻烦,而 Maven 给我们提供了一套简单的命令来完成项目的构建。
1.2.2 依赖管理:
如果使用 Maven 构建产生的构件(例如 Jar 文件)被其他的项目引用,那么该构件就是其他项目的依赖。
在下面的 Maven 中央仓库中,你可以找到项目所需的依赖。
Maven 中央仓库
下面为导入 Mysql 依赖。
<dependencies><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.33</version></dependency>
</dependencies>
配置说明:
-
dependencies:一个 pom.xml 文件中只能存在一个这样的标签,是用来管理依赖的总标签。
-
dependency:包含在 dependencies 标签中,可以有多个,每一个表示项目的一个依赖。
-
groupId: 定义了当前 Maven 项目隶属的组织或公司。groupId 一般分为多段,通常情况下,第一段为域,第二段为公司名称。域又分为 org、com、cn 等,其中 org 为非营利组织,com 为商业组织,cn 表示中国。
-
artifactId:定义了当前 Maven 项目的名称,项目的唯一的标识符,对应项目根目录的名称。
-
version:定义了 Maven 项目当前所处版本。
依赖传递:
早期我们没有使用 maven 时,向项目中添加依赖的 jar 包,需要把所有的 jar 包都复制到项目工程下。比如 A 依赖 B。B 依赖 C。那么 A 项目引入 B 的同时,也需要引入 C,如果我们手动管理这个依赖,这个过程就会比较麻烦,我们需要知道每个库都依赖哪些库,以及这些依赖之间的版本是如何关联的。
使用 maven 的话,就可以避免管理所需依赖的关系。我们只需要在 pom 文件中,定义直接依赖就可以了,由于 maven 的依赖具有传递性,所以会自动把所依赖的其他 jar 包也一起导入。
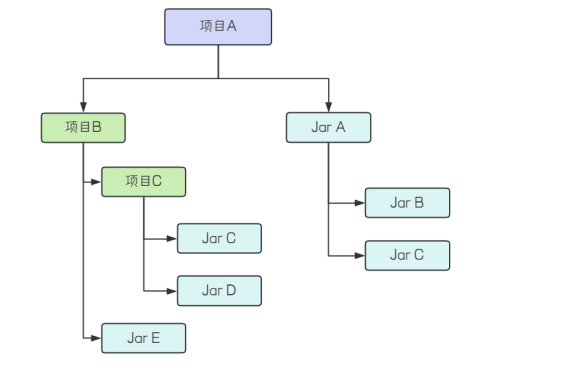
如上图,项目 A 通过 Maven 引入 Jar A 时,会自动引入 Jar B和 Jar C。Jar A 和项目 B 就是项目 A 的直接依赖。Jar B。Jar C 是间接依赖。
依赖冲突:
-
对于 Maven 而言,同一个 groupId 同一个 artifactId 下,只能使用一个 version。若相同类型但版本不同的依赖存在于同一个 pom 文件,只会引入后一个声明的依赖。
-
项目的两个依赖同时引入了某个依赖:
如同上图的 Jar C ,为了避免依赖重复,Maven 只会选择其中的一个进行解析。 Maven 在遇到这种问题的时候,会遵循 路径最短优先 和 声明顺序优先 两大原则。解决这个问题的过程也被称为 Maven 依赖调解 。
路径最短优先:
根据上图来进行理解。
依赖链路1:项目 A -> Jar A -> Jar C 。dis = 2
依赖链路2:项目 A -> 项目 B -> 项目 C -> Jar C。dis = 3
在这种情况下就会采用依赖链路 1 的 Jar C 依赖。
很容易能发现如果依赖链路的长度一样,这该怎么办,所以又引入声明顺序优先。
声明顺序优先:
在依赖路径长度相等的前提下,哪个依赖先被声明,那么就使用其依赖。
依赖排除:
当前阶段我们需要依赖的库并不多,但随着项目的越来越复杂,库之间的依赖关系也会变得越来越复杂。如上图中,如果项目 A 不需要Jar B,也可以通过排除依赖的方式来实现。
依赖排除指主动断开依赖的资源。(被排除的资源无需指定版本)
我们可以通过exclusion标签手动删除依赖。
<dependency><groupId>org.springframework</groupId><artifactId>spring-core</artifactId><version>5.3.33</version><!--排除依赖--><exclusions><exclusion><artifactId>spring-jcl</artifactId><groupId>org.springframework</groupId></exclusion></exclusions>
</dependency>
如果觉得上面依赖排除操作,有点麻烦可以在 IDEA 上安装 Maven Help 插件:
1.3 Maven 仓库:
我们通过短短几行代码,就把依赖 jar 包放在了项目里,具体是如何做的呢?
<dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.30</version>
</dependency>
这个代码,我们称之为 “坐标”,也就是唯一的。
在 Maven 中,根据 groupId、artifactId、version 的配置,来唯一识别一个 jar 包,缺一不可。
当我们在 pom 文件中配置完依赖之后,点击刷新,Maven 会根据坐标的配置,去仓库里寻找 Jar 包,并把他下载下来,添加到项目中。这个 Jar 包下载的地方就称为仓库。
仓库:用于存储资源,管理各种 jar 包。
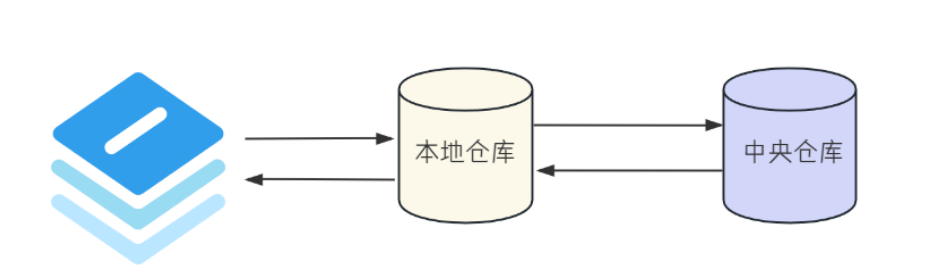
Maven 仓库分为两大类:本地仓库和远程仓库。其中远程仓库又分为中央仓库,私服和其他公共库。
1.3.1 本地仓库:
本地仓库:自己计算机上的一个目录(用来存储 jar 包),当项目中引入对应依赖 jar 包后,首先会查找本地仓库中是否有对应的 jar 包。
如果有,则在项目中直接引用。
如果没有,则去中央仓库中下载对应的 jar 包到本地仓库。
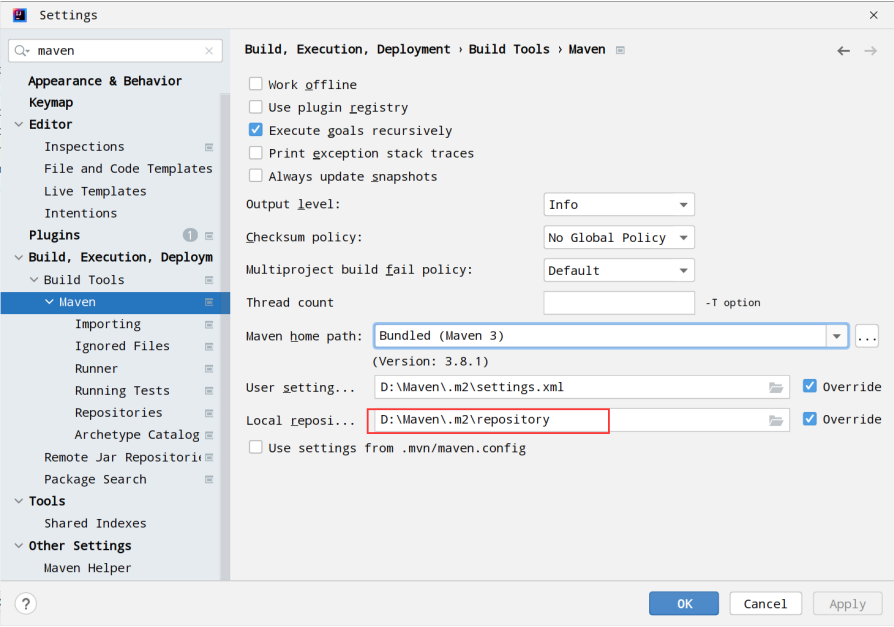
本地仓库地址可以通过 Maven 配置查看:
1.3.2 中央仓库:
中央仓库:maven 软件中内置一个远程仓库地址,就是中央仓库,服务于整个互联网。由 Maven 团队维护,全球唯一。
仓库地址:中央仓库
可以通过中央仓库网站来查询并下载。
我们可以把自己写好的 Jar 包上传到中央仓库(具备一定的要求),也可以从中央仓库下载 Jar 包。
1.3.3 私服:
私服:一般由公司团队搭建的私有仓库。
私服属于某个公司,或者某个部门,往往需要一定权限。
有了私服之后,Maven 依赖下载的顺序又发生了变化。
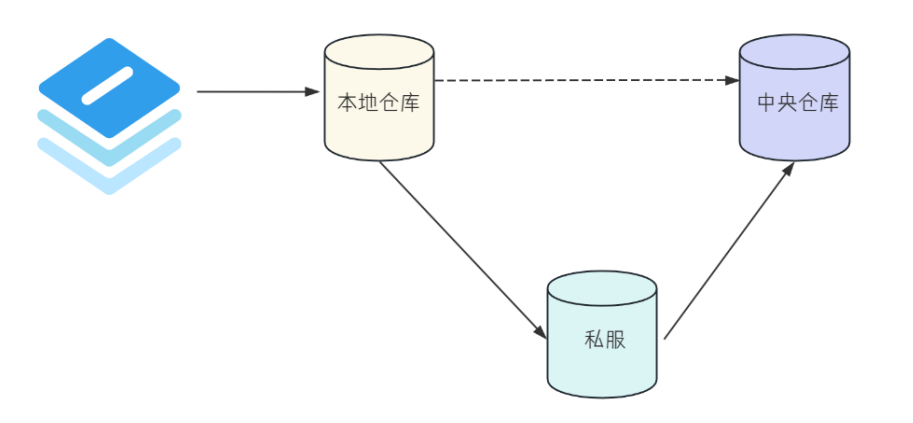
当 Maven 需要下载资源的时候:
-
先从本地仓库获取,本地仓库存在,则直接返回。
-
如果本地仓库没有,就从私服请求,私服存在该资源,就直接返回。
-
如果私服上不存在该资源,则从中央仓库下载,中央仓库不存在,就报错了。
-
如果中央仓库中存在,就先缓存在私服上之后,再缓存到本地仓库里,再为 Maven 的下载请求提供服务。
私服是很多人在使用的,所以只需要第一个使用者下载一次就可以了。
二、第一个 SpringBoot 程序
2.1 Spring Boot介绍:
在学习 SpringBoot 之前,我们先来认识一下 Spring。
我们看下 Spring 官方(spring 官网)的介绍。
可以看到,Spring 让 Java 程序更加快速,简单和安全。Spring 对于速度、简单性和生产力的关注使其成为世界上最流行的 Java 框架。
Spring 官方提供了很多开源的项目,覆盖范围从 Web 开发到大数据,Spring 发展到了今天,已经形成了自己的生态圈。我们在开发时,也倾向于使用 Spring 官方提供的技术,来解决对应的问题。
Spring Boot 的诞生是为了简化 Spring 程序开发的。
Spring Boot 翻译一下就是 Spring 脚手架,什么是脚手架呢?如下图所示:

盖房子的这个架子就是脚手架,脚手架的作用是砌筑砖墙,浇筑混凝土、方便墙面抹灰,装饰和粉刷的,简单来说,就是使用脚手架可以更快速的盖房子。
而 Spring Boot 就是 Spring 框架的脚手架,它是为了快速开发 Spring 框架而诞生的。
2.2 Spring Boot 项目创建:
- New Project。按照下图红色框框选择,名称什么的自己取,不同版本的页面会有出路,不过问题不大。
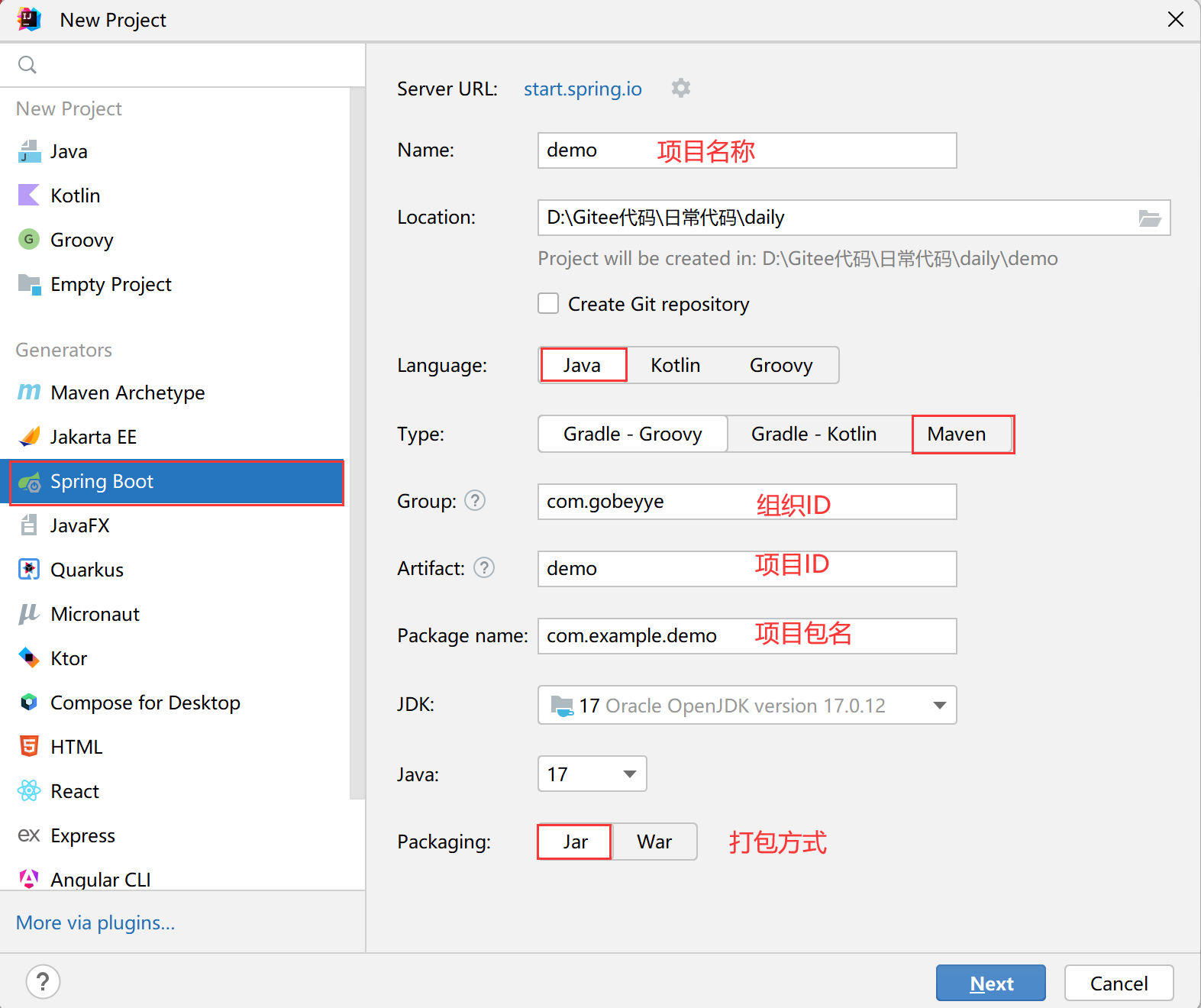
- 按照下图配置,点击创建即可。
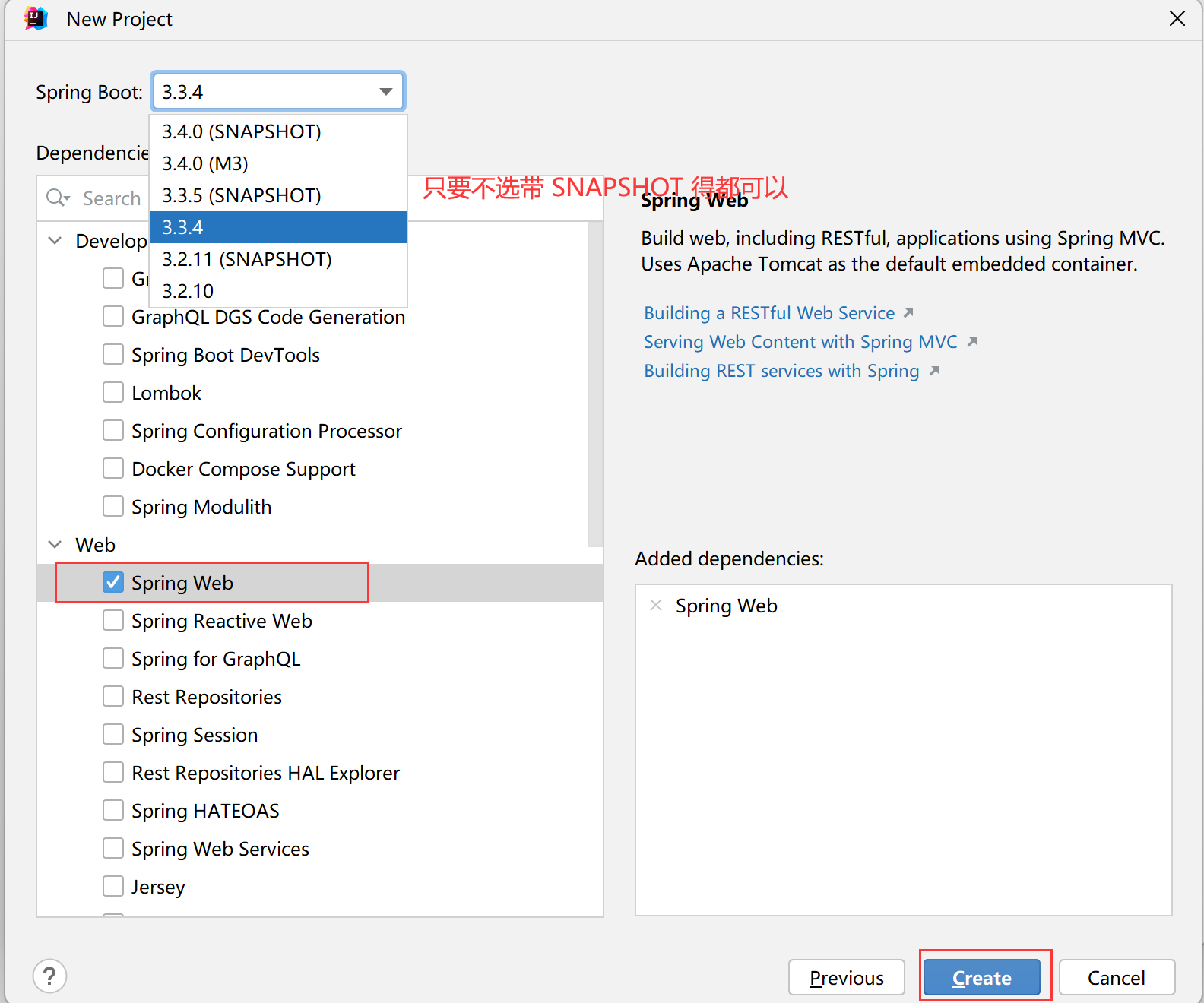
之所以不选择带 SNAPSHOT,是因为这是非稳定版本,可能会发生变化。
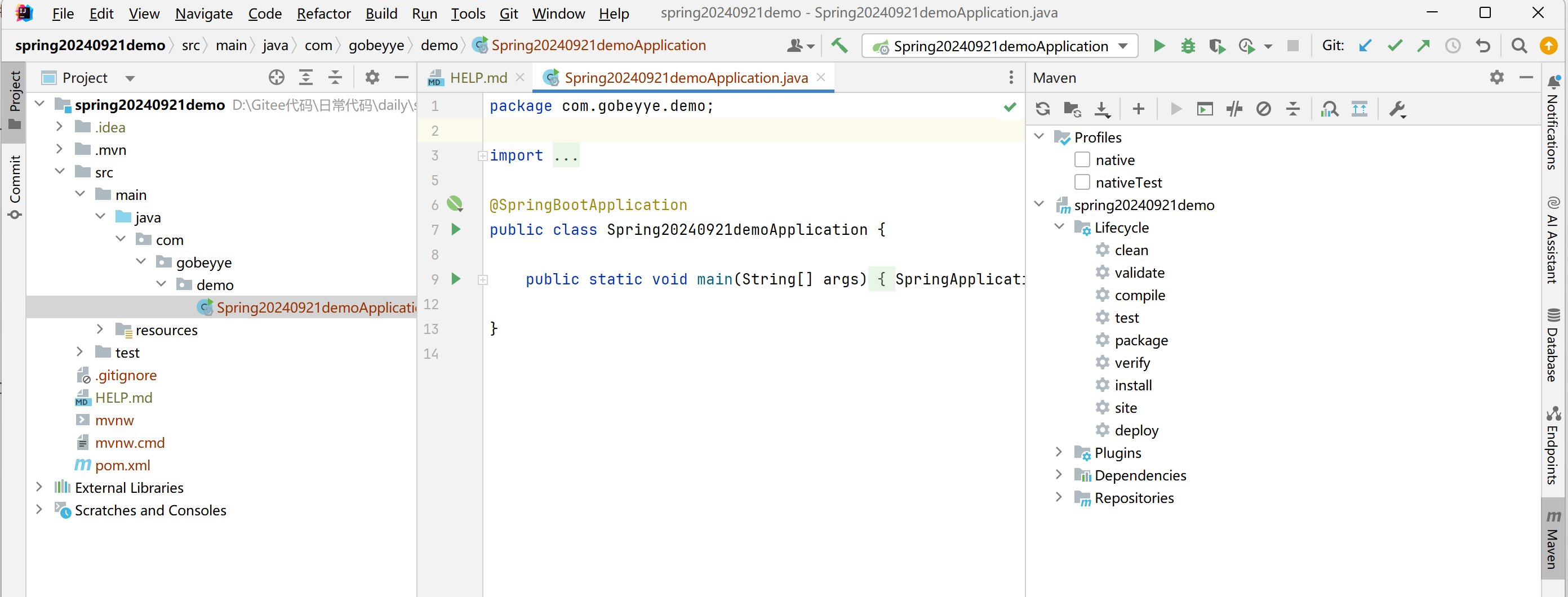
- 出现下面这个页面就基本已经成功了(不能有报错,一定要即使处理)。第一次创建 spring 项目时间要花比较久,有很多东西需要下载。
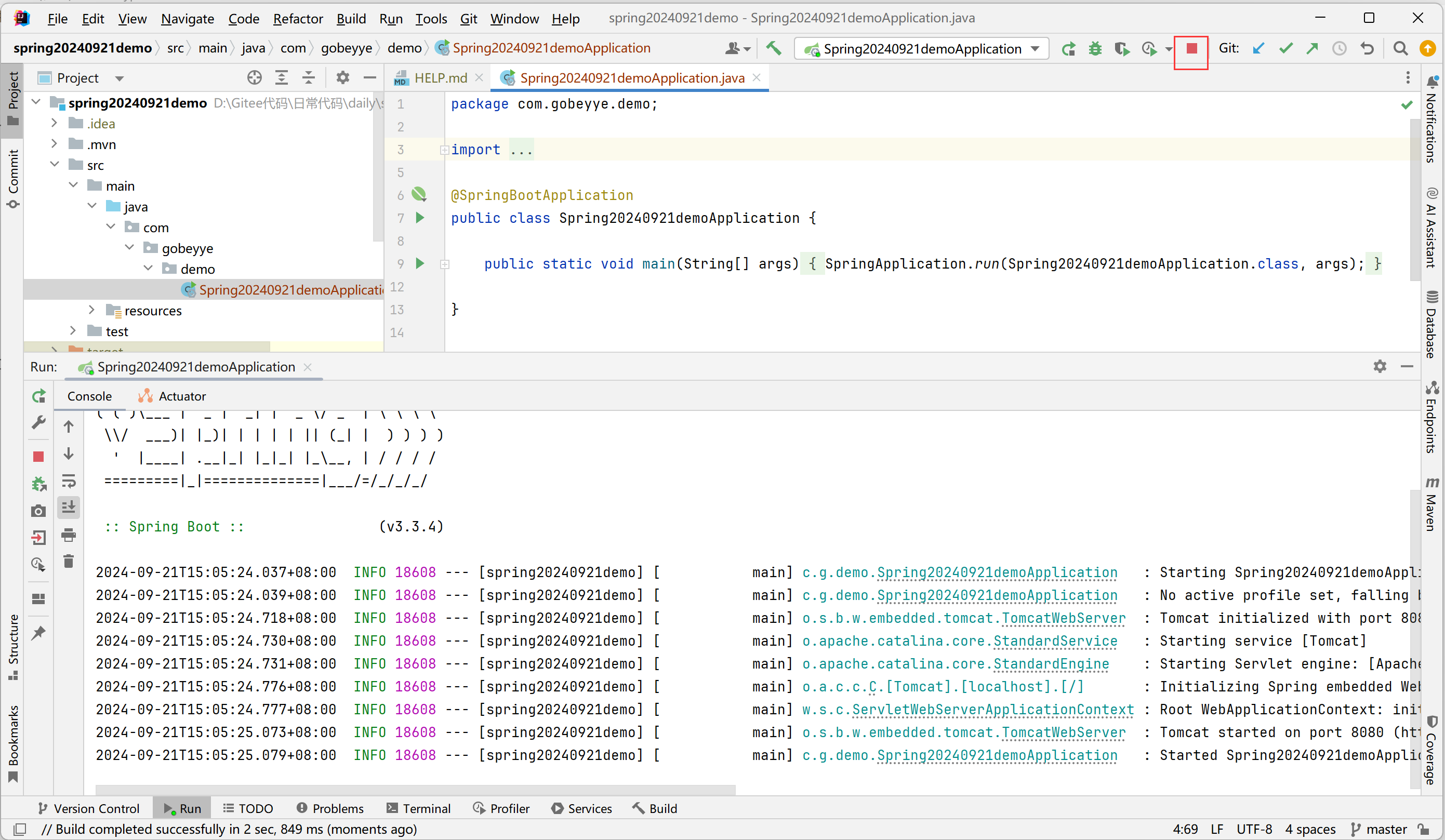
- 启动项目(spring 一创建就可以启动,在 @SpringBootApplication 标识的类(启动类)中启动),这个项目启动是不会自动结束的,如果没有报错,那么恭喜你,成功创建了一个 spring 项目。
2.3 目录介绍:
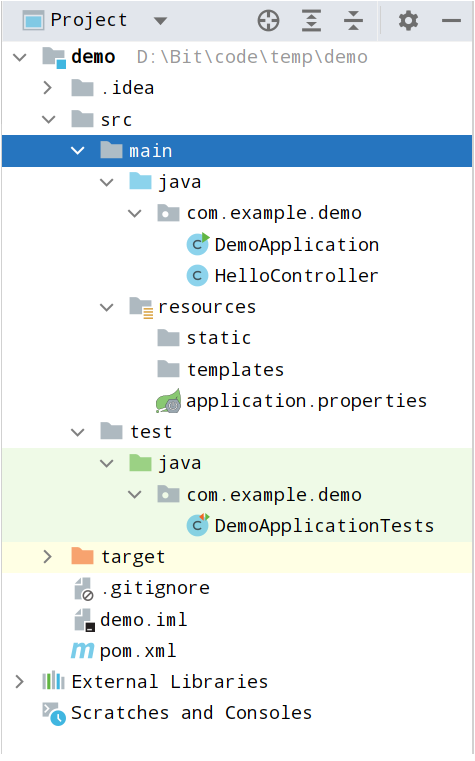
-
src/main/java: Java 源代码。
-
src/main/resources:为静态资源或配置文件。
-
src/test/java:测试代码源代码。
-
target:编译后的文件路径。
-
pom.xml:maven 配置文件。
2.4 输出 Hello world:
在创建的项目包路径下创建 UserController 文件,实现代码如下:
先实现,至于注解是什么意思,后面文章会给出。
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;@RestController
public class UserController {@RequestMapping("/hello")public String hello(){return "Hello World";}
}
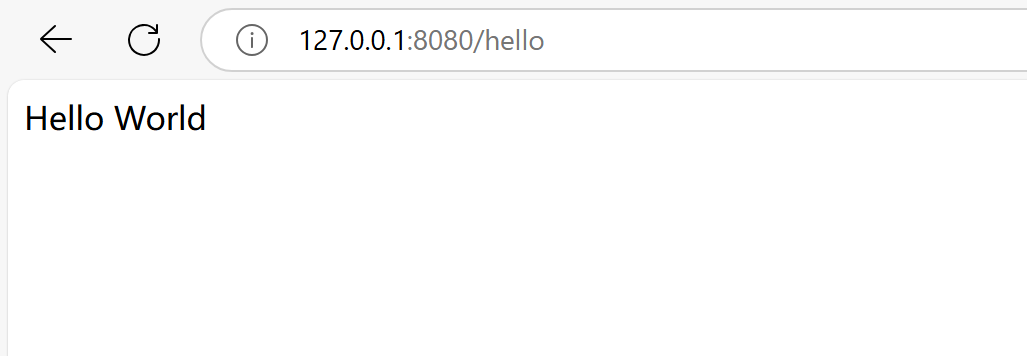
重新启动项目,访问 127.0.0.1:8080/hello 最终效果如下:
三、Web 服务器
浏览器和服务器两端进行数据交互,使用的就是 HTTP 协议。
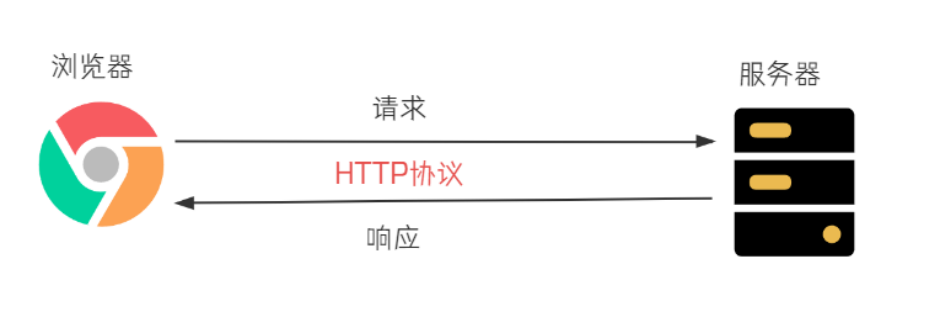
前面我们已经学习了 HTTP 协议,知道了 HTTP 协议就是 HTTP 客户端和 HTTP 服务器之间的交互数据的格式。
Web 服务器就是对 HTTP 协议进行封装,程序员不需要直接对协议进行操作(自己写代码去解析 http 协议规则),让 Web 开发更加便捷,所以 Web 服务器也被称为 WWW 服务器,HTTP 服务器,主要功能是提供网上信息浏览服务。
常见的 Web 服务器有:Apache,Nginx,IIS,Tomcat,Jboss等。
SpringBoot 内置了 Tomcat 服务器,无需配置即可直接运行。

Tocmat 默认端口号是 8080,所以我们程序访问时的端口号也是 8080。
- 请求响应流程分析:
浏览器输入 URL 之后,发起请求,就和服务器之间建立了连接。
浏览器:
输入网址: 127.0.0.1:8080/hello
- 通过 IP 地址 127.0.0.1 定位到网络上的一台计算机,127.0.0.1 就是本机。
- 通过端口号 8080 找到计算机上对应的进程,也就是在本地计算机中找到正在运行的 8080 端口的程序。
- /hello 是请求资源位置(资源:对计算机而言资源就是数据。web资源:通过网络可以访问到的资源)。
127.0.0.1:8080/hello 就是向本地计算机中的 8080 端口程序,获取资源位置是 /hello 的数据。8080 端口程序,在服务器找 /hello 位置的资源数据,发给浏览器。
服务器:
-
接收到浏览器发送的信息。
-
在服务器上找到对应的资源。
-
把资源发送给浏览器。
四、总结
最开始学习 Spring 的时候,会遇到很多问题,更多是环境相关的问题。
我们不仅要学习 Spring 代码的基本写法,更重要的是学习排查错误的思路。
熟悉 HTTP 协议能让我们调试问题事半功倍。
-
4xx 的状态码标识路径不存在,往往需要检查 URL 是否正确。
-
5xx 的状态码表示服务器出现错误,往往需要观察页面提示的内容和 Tomcat 自身的日志,观察是否存在报错。
-
出现连接失败往往意味着服务没有正确启动,也需要观察服务器的自身日志是否有错误提示。
参考:
- Maven JavaGuide
结语:
其实写博客不仅仅是为了教大家,同时这也有利于我巩固知识点,和做一个学习的总结,由于作者水平有限,对文章有任何问题还请指出,非常感谢。如果大家有所收获的话,还请不要吝啬你们的点赞收藏和关注,这可以激励我写出更加优秀的文章。