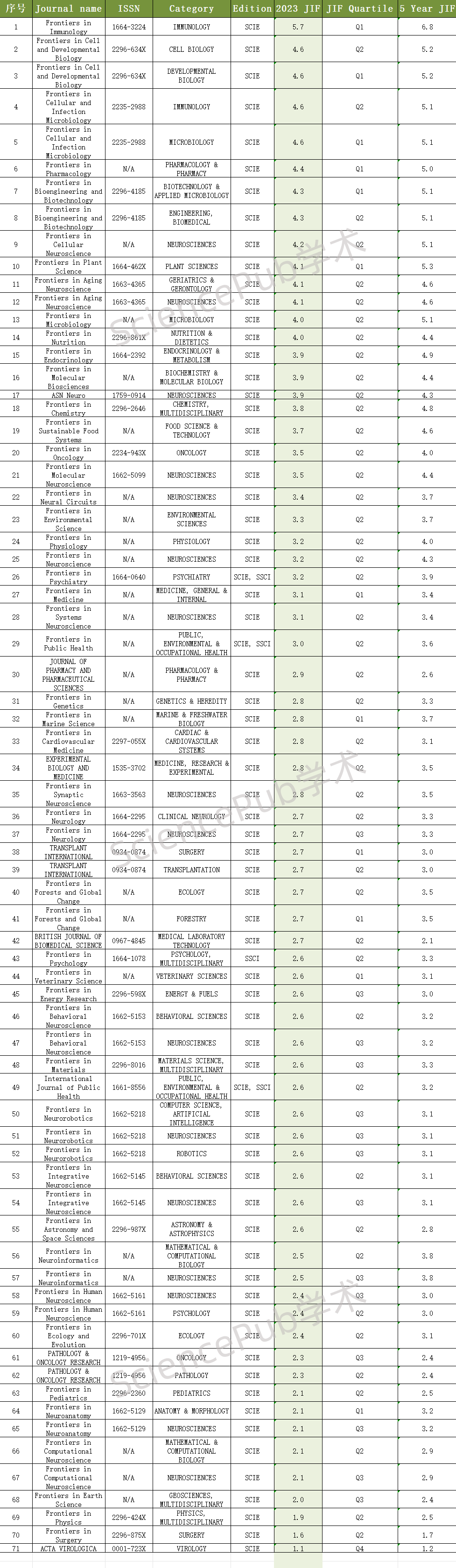
表是数据库最基本的逻辑结构,一切数据都存放在表中,其它数据库对象(索引、视图、同义词等)都是为了更方便的操作表中的数据。Oracle数据库是由若干个表组成,每个表由列和行组成。
数据库表的类型按照存储结构划分:
(1)普通表:Oracle数据库中有99%以上的表都是堆组织表(heap organized table)默认执行建表语句时,默认的表类型就是堆表。这种类型表的数据,以无序集合的方式,也就是堆的方式进行存储。
(2)分区表:分区表就是通过使用分区技术,将一张大表,拆分成多个表分区(独立的段,从而提升数据访问的性能,以及日常的可维护性。
(3)簇表:簇表由一组相同的列而且经常被一起使用的数据表构成,这组表在存储时会共享一部分的数据块。
(4)索引表:表存储在索引结构中,利用行本身物理排序。在堆中数据可能被填到任何适合的地方。在索引组织表中,根据主关键字以排序顺序来存储数据。
按照存在失效划分:
(1)临时表:只保存会话级别的数据,只在一个会话或是事务中存在,会话关闭或事物结束,临时表的数据就不存在了。
(2)永久表:数据保存在数据文件,可以供其他会话或是事务访问。
3.1.1分区表的概念和优势
在实际开发中经常使用到的是普通表和分区表,普通表在前面的章节中已经介绍了,
下面主要主要介绍一下分区表。当表中的数据量不断增大,查询数据的速度就会变慢,应用程序的性能就会下降,这时就应该考虑对表进行分区。表进行分区后,逻辑上表仍然是一张完整的表,只是将表中的数据在物理上存放到多个表空间(物理文件上),这样查询数据时,不至于每次都扫描整张表。
如果实际业务数据量比较大,大小超过2GB就需要使用使用分区表了。
分区表的优势:
(1)强可用性:如果表的一个分区由于系统故障而不能使用,那么表的其余好的分区仍可以使用。例如一个100GB的表,中间的数据果遭到损坏,那么恢复起来简直让人抓狂。如果这100GB的表被划分为了50个2GB的分区,当其中某个分区数据遭到破坏时,只需要恢复一个2GB的分区数据即可。出现错误时的停机时间将会大大减少,因为恢复所需的工作量大幅减少。
(2)减少关闭时间:如果系统故障只影响表的一部分分区,那么只有这部分分区需要修复,比整个大表全部修复花的时间更少。
(3)维护轻松:单独管理每个分区比管理单个大表要轻松得多。
(4)均衡I/O:以把表的不同分区分配到不同的磁盘来平衡I/O,改善性能。
(5)改善性能:对大表的查询、增加、修改等操作可以分解到表的不同分区来并行执行,可使运行速度更快。
3.1.2分区表的类型
分区表包括了以下类型:
(1)范围分区
(2)哈希分区
(3)列表分区
(4)范围-哈希复合分区
(5)范围-列表复合分区
1.范围分区
范围分区是应用范围比较广的表分区方式,以列的值的范围来做为分区的划分条件,将记录存放到列值所在的范围分区中。
范围分区将数据基于范围映射到每一个分区,这个范围是在创建分区时指定的分区键决定的。这种分区方式是最为常用的,并且分区键经常采用日期。举个例子:商品销售数据按照月份进行分区。
当使用范围分区时,请考虑以下几个规则:
每一个分区都必须有一个VALUES LESS THEN子句,它指定了一个不包括在该分区中的上限值。分区键的任何值等于或者大于这个上限值的记录都会被加入到下一个分区中。
所有分区,除了第一个,都会有一个隐式的下限值,这个值就是此分区的前一个分区的上限值。
【例3-1】创建基金交易表,包括交易日期、机构代码、操作员代码、交易金额。由于数据量比较大,需要按照交易日期分区,交易数据包括2022年5月到7月份的数据。需要查询出6月份的基金交易数据。
建立范围分区表,代码如下:
–第3章\bdgl.sql
–建立分区表
create table F_FUNDAFFIRM
(
tradedate CHAR(8),
organcode varchar2(9),
opercode varchar2(11),
successfulamount NUMBER(16,2)
)
partition by range (TRADEDATE)
(
partition P_202205 values less than (‘20220601’)
tablespace USERS
pctfree 10
initrans 1
maxtrans 255
storage
(
initial 8M
next 1M
minextents 1
maxextents unlimited
),
partition P_202206 values less than (‘20220701’)
tablespace USERS
pctfree 10
initrans 1
maxtrans 255
storage
(
initial 8M
next 1M
minextents 1
maxextents unlimited
),
partition P_202207 values less than (‘20220801’)
tablespace USERS
pctfree 10
initrans 1
maxtrans 255
storage
(
initial 8M
next 1M
minextents 1
maxextents unlimited
)
);
comment on table F_FUNDAFFIRM
is ‘基金待确认交易表’;
comment on column F_FUNDAFFIRM.tradedate
is ‘交易日期’;
comment on column F_FUNDAFFIRM.organcode
is ‘机构代码’;
comment on column F_FUNDAFFIRM.opercode
is ‘操作员代码’;
comment on column F_FUNDAFFIRM.successfulamount
is ‘成功金额’;
–插入数据
insert into F_FUNDAFFIRM
select ‘20220415’,‘1130’,‘4056’,50000 from dual;
insert into F_FUNDAFFIRM
select ‘20220620’,‘1160’,‘4960’,120000 from dual;
insert into F_FUNDAFFIRM
select ‘20220718’,‘1175’,‘5021’,360000 from dual;
insert into F_FUNDAFFIRM
select ‘20220729’,‘1185’,‘3306’,80000 from dual;
Commit;
–查询数据
Select * from F_FUNDAFFIRM partition(P_202206)
执行结果如图3-1所示。
图3-1查询结果
2.列表分区
列表分区的特点是某列的值只有几个,基于这样的特点使用列表分区。
【例3-2】创建大学学生信息表,包括字段学号、姓名、宿舍、年级。其中字段年级包括大一、大二、大三、大四。
建立列表分区表,代码如下:
–第3章\bdgl.sql
create table graderecord
(
sno varchar2(10),
sname varchar2(20),
dormitory varchar2(3),
uv_grade varchar2(10)
)
partition by list(uv_grade)
(
partition d1 values(‘大一’),
partition d2 values(‘大二’),
partition d3 values(‘大三’),
partition d4 values(‘大四’)
);
–插入测试记录
insert into graderecord select ‘1101’,‘张海’,‘205’,‘大二’ from dual;
Commit;
–如果插入六年级
insert into graderecord select ‘1102’,‘王萍’,‘205’,‘六年级’ from dual;
如果年级为六年级,执行结果如图3-2所示。
图3-2关键字未映射到任何分区
由于数据六年级不在年级字段的值列表范围之内,所以报错。
3.哈希分区
哈希分区主要的机制是根据HASH算法来计算具体某条纪录应该插入到哪个分区中,HASH算法中最重要的是HASH函数。行的存放目的地由数据库的内部hash函数来决定。hash算法的目是使数据在设备上均匀分布行,这样可以确保数据在各个分区中分布比较均匀。当然还需要分区键值是连续分布的,或接近连续分布。
用HASH分区,只需指定分区的数量即可。建议分区的数量采用2的n次方,这样可以使得各个分区间数据分布更加均匀。
【例3-3】建立名称为t_hash_partition的表,该表为哈希分区表,有两个分区。建表完成后查询两个分区数据。
建立哈希分区代码如下:
–第3章\bdgl.sql
create table t_hash_partition(a int,b int)
partition by hash(a)
(partition p1 tablespace users,
partition p2 tablespace users
);
以压缩模式创建表,代码如下:
create table t_hash_partition_cp(a int,b int)
partition by hash(a)
(partition p1 tablespace users compress,
partition p2 tablespace users nocompress
);
查看该表的分区,代码如下:
select table_name,partition_name,tablespace_name from user_tab_partitions
where table_name=‘T_HASH_PARTITION’;
执行后如图3-3所示。
图3-3查询哈希表分区
改变分区表的日志模式,代码如下:
alter table t_hash_partition modify partition p1 nologging;
执行后如图3-4所示。
图3-4改变分区表日志模式失败
结论:分区不能变更日志模式。
【例3-4】建立名称为t的哈希分区表,包括两个字段id和name,该表有三个分区。
用两种方式往该表中插入数据,查看每个分区的数据是否分布均匀。
建表代码如下:
–第3章\bdgl.sql
create table t1
(
id varchar2(10),
name varchar2(20)
)
partition by hash(id)
(
partition p1,
partition p2,
partition p3
);
插入少量数据,代码如下:
insert into t1
select ‘1’,‘刘海平’ from dual;
insert into t1
select ‘2’,‘王涛’ from dual;
insert into t1
select ‘3’,‘张紫馨’ from dual;
insert into t1
select ‘4’,‘李明’ from dual;
insert into t1
select ‘5’,‘刘升’ from dual;
insert into t1
select ‘6’,‘方晓宁’ from dual;
Commit;
查询分区1的数据,代码如下:
select * from t1 partition(p1);
查看分区1的数据如图3-5所示。
图3-5查询哈希表分区1的数据
查询分区2的数据,代码如下:
select * from t1 partition(p2);
查看分区2的数据如图3-6所示。
图3-6查询哈希表分区2的数据
查询分区3的数据,代码如下:
select * from t1 partition(p3);
查看分区3的数据如图3-7所示。
图3-7查询哈希表分区3的数据
使用存储过程插入大量数据,代码如下:
delete from t1;
commit;
declare
i number;
begin
for i in 1…1000000 loop
insert into t1 values(i,‘name’);
end loop;
commit;
end;
/
查看分区1的记录数,代码如下:
select count(1) from t1 partition(p1);
查看分区1的记录数如图3-8所示。
图3-8查询哈希表分区1的记录数
查看分区2的记录数,代码如下:
select count(1) from t1 partition(p2);
查看分区2的记录数如图3-9所示。
图3-9查询哈希表分区2的记录数
查看分区3的记录数,代码如下:
select count(1) from t1 partition(p3);
查看分区3的数据如图3-10所示。
图3-10查询哈希表分区2的记录数
从本列中可以看出,通过两种方式插入的数据并不是完全均匀分布的。
哈希分区表使用总结如下:
(1)数据随机插入:Hash分区一般是在分区键值无法确定的情况下,使用的一种分区策略,Oracle按照hash 算法把数据插入用户指定的分区键中,它是随机的插入到某个区中,不受人为的干预。
(2)查看每个分区的数据,可以看出存在数据倾斜。每个哈希分区的数据量不是完全一致。
(3)分区大小:分区的初始大小受建表初始化参数的影响(即initial、next的影响),不指定时受建库时表空间参数的影响。实际分配数据后的大小,受分区字段值的影响。分区字段值相同时,所有数据只能插入到一个分区;分区字段值不同时,数据随机插入不同的分区。
(4)分区索引分为Local和Global索引,Local索引和表分区是一一对应的,Global索引又分为Global非分区索引和Global分区索引。Global非分区索引,可以与表分区对应,也可以不对应;但是当Global分区索引与表分区的表空间对应时,则Global分区索引就是个Local索引。