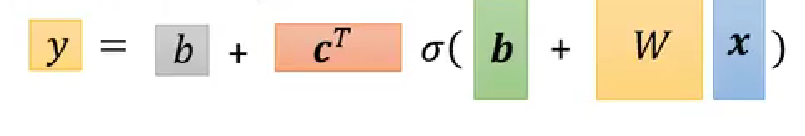- 为什么使用缓存?
- 使用缓存会带来什么问题?
- 双写不一致
- 缓存击穿(某个key失效)、缓存穿透(key不存在)和缓存雪崩(大规模失效)
- 并发竞争
- Redis为什么这么快?
- 纯内存操作:数据结构是基于哈希表+链表
- 线程模型:单线程
问:为什么单线程还会这么快?
redis服务器采用多路复用,即同时监听多个socket链接,将命令放到队列里面,然后再用文件事件处理器处理这批请求,处理的过程是单线程的。

- 说一说redis的过期策略和内存淘汰策略?
过期策略:
- 惰性删除:访问的时候,才会去处理:判断是否过期,过期则删除。内存不友好。
- 定期删除:默认100ms随机检查一部分设置了过期时间的键,循环遍历,如果键过期,则删除。
- redis同时采用惰性删除和定期删除两种策略。综合了CPU和内存压力。
内存淘汰策略:
内存淘汰策略是允许reids在内存资源紧张时,根据一定策略主动删除一些键值对,已释放内存空间并保持系统的稳定性。
- 不淘汰策略
- 最近最少使用: 优先删除最近未访问的数据
- 根据过期时间优先 : 优先删除快过期的数据
- 随机删除:
- 全局最近最少使用:选择最少使用的key,忽略是否设置了过期时间
- 全局随机删除:不管是否设置了过期时间
- 什么是redis的哨兵机制?
高可用
- 什么是缓存击穿、缓存穿透、缓存雪崩?
缓存击穿:热点数据失效,大量请求打到DB
解决方案:
- 热点数据永不过期(定时任务,扫描key的访问量,超过阈值,延长过期时间)
- 互斥锁:只有一个线程去查询DB
缓存雪崩:大规模缓存失效,或者缓存宕机
解决方案:
- 过期时间加个随机值
- 互斥锁===访问DB
- 多级缓存:本地缓存—公共缓存—DB
- 部署redis集群,避免单机宕机导致不可用
缓存穿透:查询不存在的数据
解决方案:
- 缓存空数据
- 参数校验
- 布隆过滤器:过滤掉不存在的数据
- redis持久化机制
- RDB持久化
- AOF持久化
- RDB+AOF持久化
- xxx