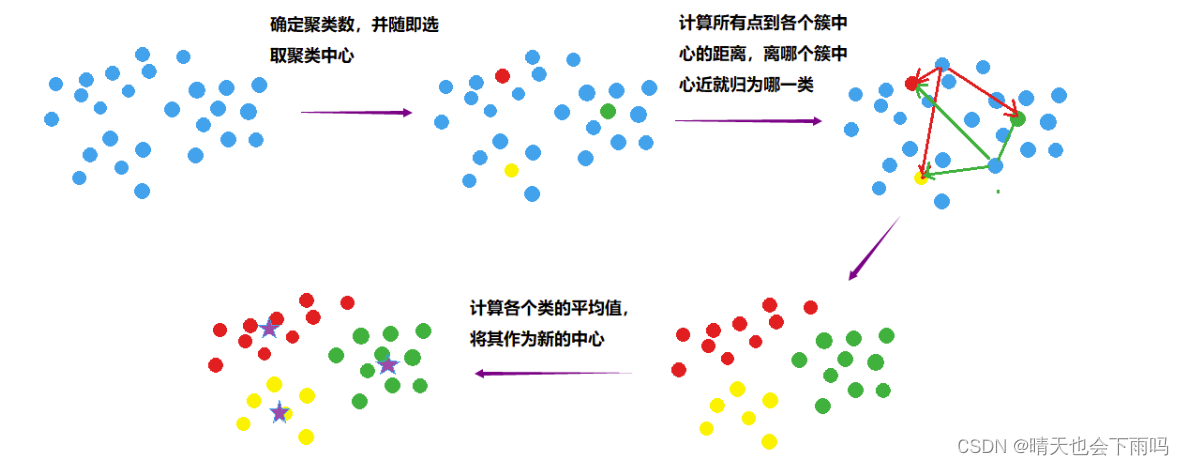
K-means算法是一种无监督学习算法,主要用于数据聚类。其工作原理基于迭代优化,将数据点划分为K个集群,使得每个数据点都属于最近的集群,并且每个集群的中心(质心)是所有属于该集群的数据点的平均值。以下是K-means算法的基本工作步骤:
- 初始化:
- 选择要将数据集分成的集群数量K。
- 随机选择K个数据点作为初始质心(即集群中心)。这些质心可以是从样本中随机选取的,也可以根据先验知识或经验来选择。
- 分配数据点到集群:
- 对于数据集中的每个数据点,计算其与每个质心的距离(通常使用欧氏距离)。
- 将每个数据点分配到距离其最近的质心所在的集群。
- 更新质心:
- 对于每个集群,计算属于该集群的所有数据点的平均值(坐标的均值)。
- 将计算出的均值作为新的质心。
- 迭代:
- 重复步骤2和3,直到满足停止条件。停止条件可以包括质心不再显著变化(即新旧质心之间的差异很小),或者算法达到了预定的最大迭代次数。
- 输出:
- 输出最终的K个集群以及每个集群的质心。
K-means算法的目标是最小化每个数据点到其所属集群质心的平方距离之和,即最小化集群内的平方误差。由于初始质心是随机选择的,因此不同的初始质心可能会导致不同的聚类结果。为了获得更稳定和更好的聚类效果,有时会多次运行K-means算法,并选择最佳的聚类结果。
在K-means算法中,K值(即要形成的集群数量)的确定是一个重要但具有挑战性的问题,因为不同的K值可能会导致不同的聚类结果。没有一种通用的方法可以直接确定最佳的K值,但可以通过以下一些策略来帮助你选择和评估不同的K值:
-
肘部法则(Elbow Method):
这种方法通过绘制不同K值对应的聚类内误差和(Sum of Squared Errors, SSE)或畸变(Distortion)的曲线来工作。随着K值的增加,SSE通常会减小,因为更多的集群意味着每个集群中的数据点更紧密。但是,当K值增加到一定程度时,SSE的减少会变得不那么显著,形成一个类似于“肘部”的转折点。这个转折点通常被认为是最佳的K值。 -
轮廓系数(Silhouette Analysis):
轮廓系数是评估聚类效果的一种方法,它结合了凝聚度和分离度两种度量。对于每个数据点,轮廓系数计算其到同一集群内其他点的平均距离(凝聚度)与其到最近邻集群内点的平均距离(分离度)的比值。整个数据集的轮廓系数是所有数据点轮廓系数的平均值。较高的轮廓系数值通常表示较好的聚类效果。你可以通过绘制不同K值的轮廓系数来找到最佳的K值。 -
间隙统计量(Gap Statistic):
间隙统计量是一种通过比较实际数据的聚类结果与随机数据(具有相同分布)的聚类结果来评估最佳K值的方法。当实际数据的聚类结果显著好于随机数据的聚类结果时,可以认为找到了一个合适的K值。 -
层次聚类(Hierarchical Clustering):
你可以首先使用层次聚类来确定大致的集群数量,然后再使用K-means算法进行细化。层次聚类可以提供一个关于数据集中可能存在多少自然集群的直观感受。 -
基于业务或先验知识:
在某些情况下,你可能已经知道数据集中应该有多少个集群,这通常基于业务逻辑或先验知识。例如,你可能正在分析一个包含三个不同产品类别的数据集,因此自然会选择K=3。 -
稳定性方法:
通过多次运行K-means算法并评估结果的稳定性来确定K值。如果对于不同的初始条件,算法都能产生相似的聚类结果,那么可以认为这个K值是稳定的。
请注意,没有一种方法是绝对正确的,每种方法都有其优点和局限性。在实际应用中,你可能需要结合多种方法来确定最佳的K值。同时,还需要考虑算法的计算复杂度和数据的特性。
clear;clc;clf;
% 假设你有一个名为data的数据集,它是一个n×d的矩阵,其中n是数据点的数量,d是每个数据点的维度。
% 你想将数据点划分为k个集群。 rng(1314);%固定随机数种子
% 生成一些随机数据作为示例
data = rand(100, 3); % 100个2维数据点 %绘图
figure(1);
scatter3(data(:,1),data(:,2),data(:,3),'filled');% 定义要测试的K值范围
K_values = 1:9; % 例如,测试从1到9的K值 % 初始化一个用于存储SSE的数组
SSE = zeros(size(K_values)); % 对每个K值运行K-means算法并计算SSE
for i = 1:length(K_values) k = K_values(i); [C,idx] = mykmeans(data, k); % 计算SSE SSE(i) = sum(sum((data - C(idx,:)).^2,2));
end % 绘制肘部图
figure(2);
plot(K_values, SSE, 'bx-');
xlabel('Number of clusters K');
ylabel('Sum of squared errors (SSE)');
title('Elbow Method For Optimal K');
grid on; % 找出“肘部”点,这里简单地通过观察图形来确定
% 在实际应用中,可以使用更复杂的策略,比如计算SSE变化的百分比等
dsse = abs(diff(SSE));
bestK = find(dsse < 1 , 1, 'first');
fprintf('Suggested number of clusters: %d\n', bestK);
hold on;
plot(bestK, SSE(bestK), 'ro', 'MarkerSize', 10, 'LineWidth', 2); % 在图上标出建议的K值点
legend('SSE for each K', 'Suggested K');
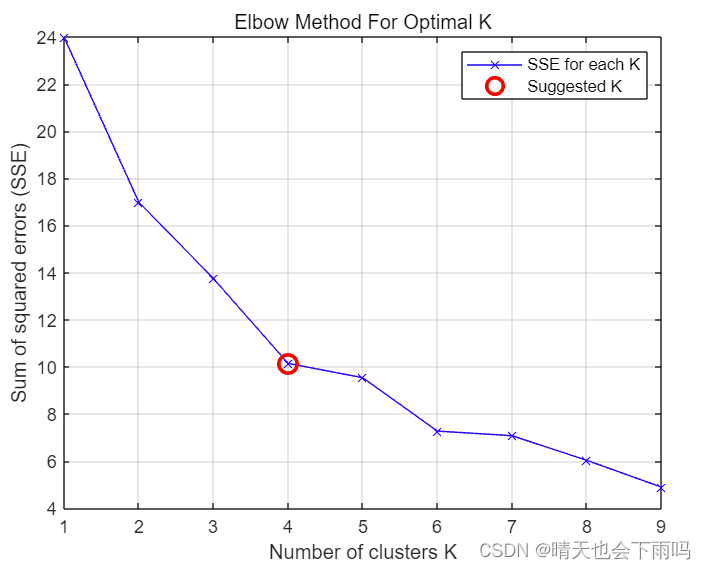
hold off;在下图可以观察到,k<4时曲线下降迅速,k>4时曲线下降出现明显放缓,因此K取4:
K-means算法是一种非常常见的聚类算法,用于将数据点划分为K个集群。在上述数据和K取4的条件下,以下是一个简单的K-means算法的MATLAB实现示例:
% 选择要划分的集群数量
k = bestK; % 运行k-means算法
[centroids, idx] = mykmeans(data, k); % 绘制结果
colors = {'r','b','g','y'}; % 生成k种不同的HSV颜色
figure;
for i = 1:k % 提取属于当前组别的数据点 new_data = data(idx == i, :); % 绘制当前组别的数据点,使用不同的颜色和标记 scatter3(new_data(:,1), new_data(:,2), new_data(:,3),colors{i},'filled');hold on;
end
% scatter3(data(:,1),data(:,2),data(:,3),idx);
h2 = plot3(centroids(:,1), centroids(:,2),centroids(:,3), 'kx', 'MarkerSize', 15, 'LineWidth', 3);
legend('类别1','类别2','类别3','类别4','中心点');
hold off;function [centroids, idx] = mykmeans(data, k) % 初始化 [n, ~] = size(data); centroids = data(randperm(n, k), :); % 随机选择k个数据点作为初始质心 prev_centroids = centroids; max_iters = 100; % 最大迭代次数 for iter = 1:max_iters % 分配数据点到最近的质心 idx = zeros(n, 1); for i = 1:n distances = sum((data(i,:) - centroids).^2, 2); [~, min_idx] = min(distances); idx(i) = min_idx; end % 重新计算质心 for i = 1:k points = data(idx == i, :); if ~isempty(points) centroids(i,:) = mean(points); end end % 检查收敛 if all(centroids == prev_centroids) break; end prev_centroids = centroids; end
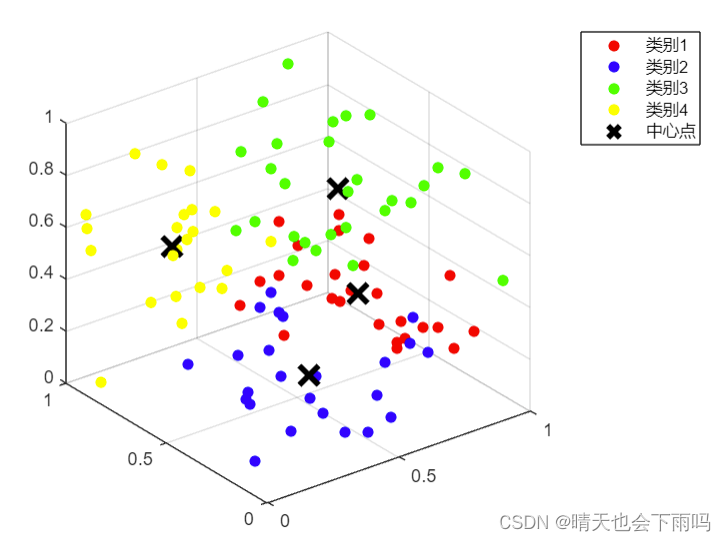
end初始三维散点图对比k-means聚类后的三维散点图如下:

需要注意的是,K-means算法对于初始质心的选择非常敏感,并且可能陷入局部最小值。此外,它假设集群的形状是球形的,并且集群的大小和密度大致相同,这在处理复杂形状或大小差异较大的集群时可能不是最优的。因此,在实际应用中,可能需要根据数据的特性和需求来选择和调整算法参数,或者考虑使用其他更复杂的聚类算法。