paper:Exploring Simple Siamese Representation Learning
official implementation:https://github.com/facebookresearch/simsiam
本文的创新点
本文提出了一种名为SimSiam的简单孪生网络(Siamese network)结构,用于无监督的视觉表示学习。它具有以下特点:
- 无需负样本对:与依赖负样本对(negative pairs)的对比学习方法不同,SimSiam直接最大化同一图像两个增强视图的相似性,而不使用负样本对。
- 无需动量编码器:SimSiam不依赖于动量编码器(momentum encoder),这是一种在其他方法中用于防止网络输出崩溃(collapsing)的技术。
- 停止梯度操作:SimSiam使用停止梯度(stop-gradient)操作来防止网络输出崩溃,这是其成功的关键因素。这一发现挑战了之前关于动量编码器在防止崩溃中必要性的观点。
SimSiam提供了一个简单而有效的baseline,能够与现有的更复杂方法相媲美。这表明孪生网络结构本身可能是近期方法成功的核心原因。
本文通过实验表明,对于损失和结构确实存在坍塌解,但停止梯度操作在防止坍塌方面起着至关重要的作用。
本文还研究了SimSiam与现有的一些方法如SimCLR、SwAV和BYOL的联系,通过移除这些方法中的某些核心组件,可以展示它们之间的关系。
文章提出了一个假设,即SimSiam可以被视为一种类似于期望最大化(Expectation-Maximization, EM)算法的优化过程,其中涉及两组变量并通过交替优化来求解。
方法介绍

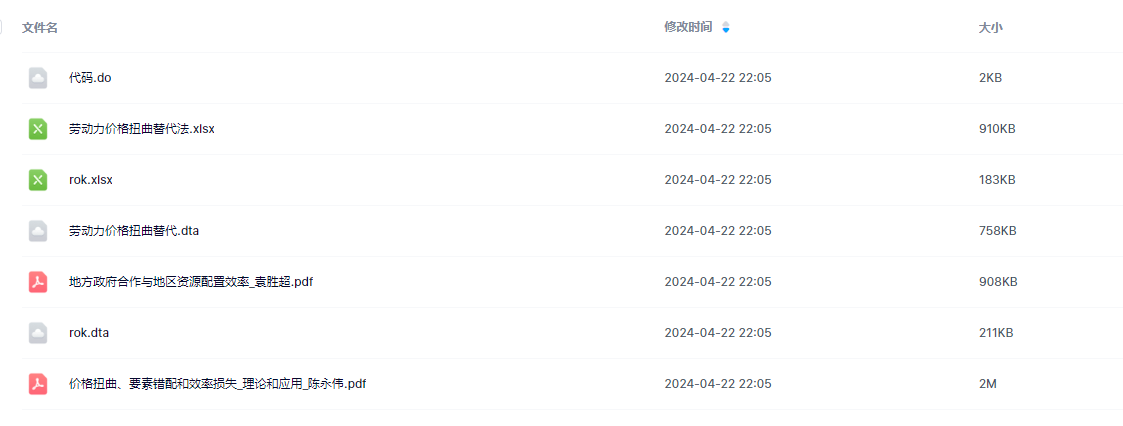
SimSiam的整理结构如图1所示。它以一张图片 \(x\) 的两个随机增强视图 \(x_1\) 和 \(x_2\) 为输入,这两个视图由一个backbone和一个projection MLP head组成的encoder网络 \(f\) 进行处理,编码器 \(f\) 在两个视图之间共享权重。一个prediction MLP head表示为 \(h\),转换一个视图的输出,并将其与另一个视图进行匹配。将两个输出向量分别表示为 \(p_1 \triangleq h\left(f\left(x_1\right)\right)\) 和 \(z_2 \triangleq f(x_2)\),我们最小化它们之间余弦相似度的负值
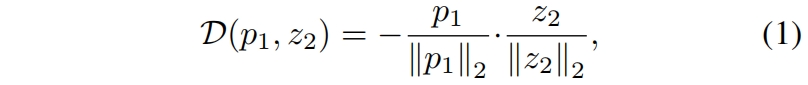
其中 \(\begin{Vmatrix}
\cdot
\end{Vmatrix}_2\) 是 \(\ell_2\)-norm。我们定义对称损失

这是针对每张图片定义的,完整的损失是对所有图片的损失取均值,最小可能值为-1。
如图1所示,该方法的一个重要部分就是停止梯度操作,我们修改式(1)得到
![]()
这意味着该式中 \(z_2\) 视为常数。同样,式(2)修改如下
这里 \(x_2\) 上的encoder在第一项中不接受来自 \(z_2\) 的梯度,但在第二项中接受来自 \(p_2\) 的梯度(对于\(x_1\)反之亦然)。
SimSiam的伪代码如下所示

实验结果
Stop-gradient
作者在实验中重点关注了是什么导致了SimSiam的非崩溃解。
图2比较了有/没有停止梯度的结果,其中架构和所有的超参都是相同的,停止梯度是唯一的区别。图2(左)是训练损失,在没有停止梯度情况下优化器迅速找到了退化解,并达到了-1的最小损失。为了证明退化是由坍塌引起的,作者又研究了 \(\ell_2\) 归一化输出的标准差 \(z/\begin{Vmatrix}
z
\end{Vmatrix}_2\)。如果输出坍缩到一个常数向量,它在所有样本上每个通道的std应该为0,这可以从图2(中)的红色曲线观察到。
作为比较,如果输出 \(z\) 是一个零均值各向同性的高斯分布,我们可以证明 \(z/\begin{Vmatrix}
z
\end{Vmatrix}_2\) 的std为 \(\frac{1}{\sqrt{d} } \)。图2(中)的蓝色曲线表明在有停止梯度的情况下,std值接近 \(\frac{1}{\sqrt{d} } \)。这表明输出没有崩溃,它们分散在unit hypersphere上。
图2(右)绘制了一个k-近邻(kNN)分类器的验证精度。这个kNN分类器可以作为一个进度的监控。在有停止梯度的情况下,kNN的精度稳步提高。
线性评价结果如图2中的表所示。SimSiam达到了67.7%的准确率。通过5次试验的std结果显示,该结果相当稳定。仅仅是去掉停止梯度,准确率就变成了0.1%。
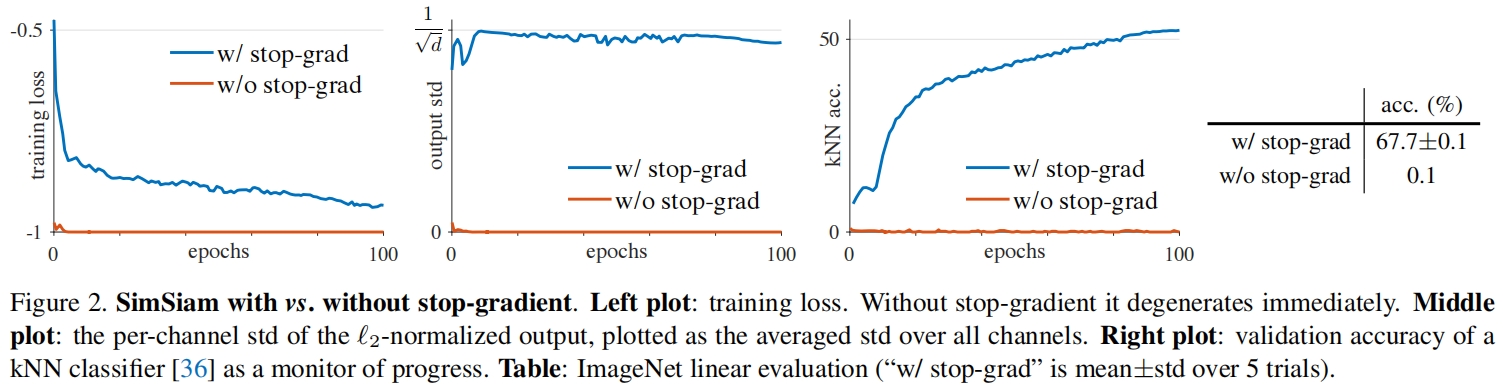
该实验证明了确实存在坍塌解。坍塌解可以通过可能达到的最小损失以及恒定的输出观察到。坍塌解的存在意味着我们的方法仅通过结构设计(例如predictor、BN、\(\ell_2\)-norm)来防止坍塌是不够的。在实验的比较中,所有结构设计保持不变,仅去掉停止梯度操作,就无法阻止得到坍塌解。
Comparisons with SOTA
和其它方法在ImageNet上的linear evaluation结果如表4所示。SimSiam的batch size为256,既不使用负样本也不使用动量编码器,尽管方法很简单,但仍取得了具有竞争力的结果。在预训练100个epoch的情况下,SimSiam在所有方法中取得了最高的准确率,尽管随着训练时间变长精度提高的较少。在所有情况下SimSiam都优于SimCLR。

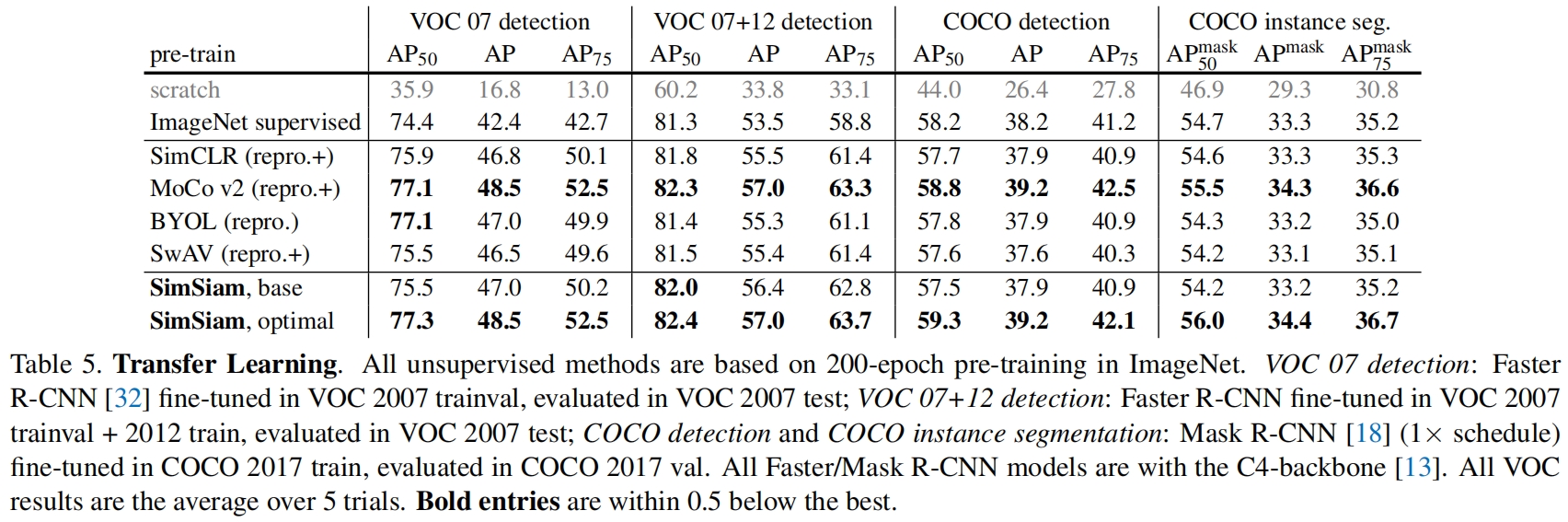
表5比较了迁移到下游任务的表现,包括VOC目标检测以及COCO目标检测和实例分割。可以看到虽然SimSiam在ImaegNet上的linear evaluation结果比其它方法稍差,但在下游任务中的效果表现的更好。
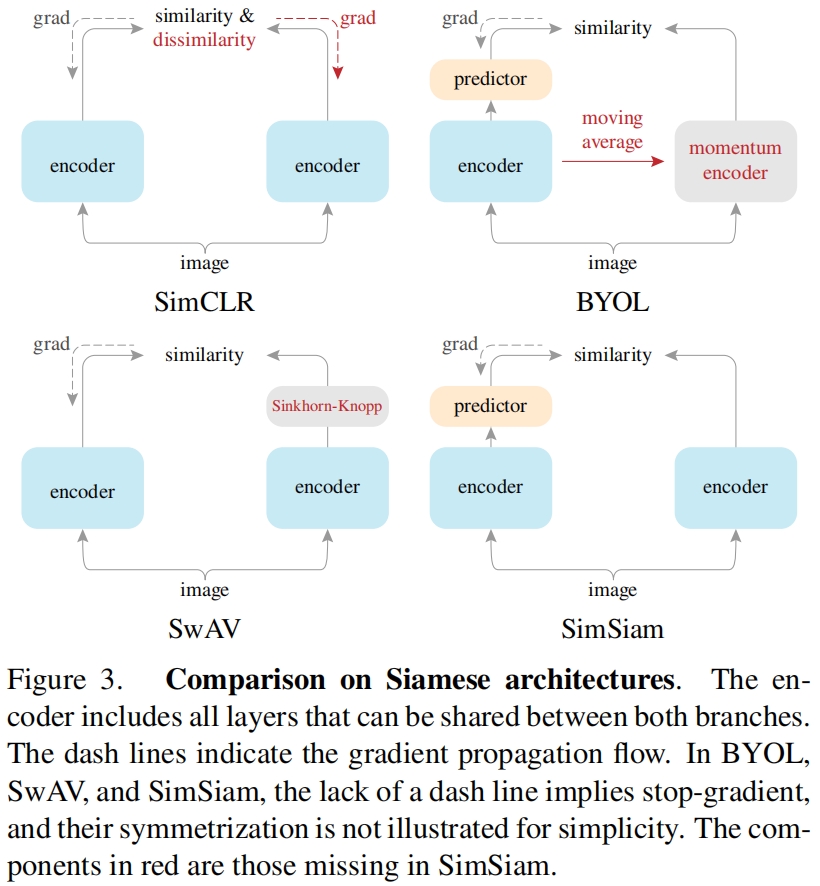
Methodology comparisons
最后,作者比较了这些孪生结构的方法的架构,如图3所示,SimSiam充当了联系这些方法的枢纽。其中红色部分是SimSiam和其它方法的区别之处,可以看到仅仅添加一个component,SimSiam就可以变换成其它方法。
代码解析
SimSiam的实现非常简单,这里就不过多介绍了。
import torch
import torch.nn as nnclass SimSiam(nn.Module):"""Build a SimSiam model."""def __init__(self, base_encoder, dim=2048, pred_dim=512):"""dim: feature dimension (default: 2048)pred_dim: hidden dimension of the predictor (default: 512)"""super(SimSiam, self).__init__()# create the encoder# num_classes is the output fc dimension, zero-initialize last BNsself.encoder = base_encoder(num_classes=dim, zero_init_residual=True)# build a 3-layer projectorprev_dim = self.encoder.fc.weight.shape[1]self.encoder.fc = nn.Sequential(nn.Linear(prev_dim, prev_dim, bias=False),nn.BatchNorm1d(prev_dim),nn.ReLU(inplace=True), # first layernn.Linear(prev_dim, prev_dim, bias=False),nn.BatchNorm1d(prev_dim),nn.ReLU(inplace=True), # second layerself.encoder.fc,nn.BatchNorm1d(dim, affine=False)) # output layerself.encoder.fc[6].bias.requires_grad = False # hack: not use bias as it is followed by BN# build a 2-layer predictorself.predictor = nn.Sequential(nn.Linear(dim, pred_dim, bias=False),nn.BatchNorm1d(pred_dim),nn.ReLU(inplace=True), # hidden layernn.Linear(pred_dim, dim)) # output layerdef forward(self, x1, x2):"""Input:x1: first views of imagesx2: second views of imagesOutput:p1, p2, z1, z2: predictors and targets of the networkSee Sec. 3 of https://arxiv.org/abs/2011.10566 for detailed notations"""# compute features for one viewz1 = self.encoder(x1) # NxCz2 = self.encoder(x2) # NxCp1 = self.predictor(z1) # NxCp2 = self.predictor(z2) # NxCreturn p1, p2, z1.detach(), z2.detach()