一、目的
由于使用了新的Kafka协议,因为根据新的协议推送模拟数据到Kafka中,再Flume采集Kafka数据到HDFS中
二、技术选型
(一)Kettle工具
准备使用Kettle的JSON input控件和Kafka producer控件,但是搞了1天没搞定,博客上也找不到相关的资料,后面再研究研究
之前用kettle采集Kafka数据写入HDFS中(不建议使用这种方式采集Kafka数据到HDFS中)

(二)Flume工具
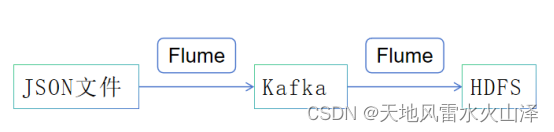
三、实施步骤
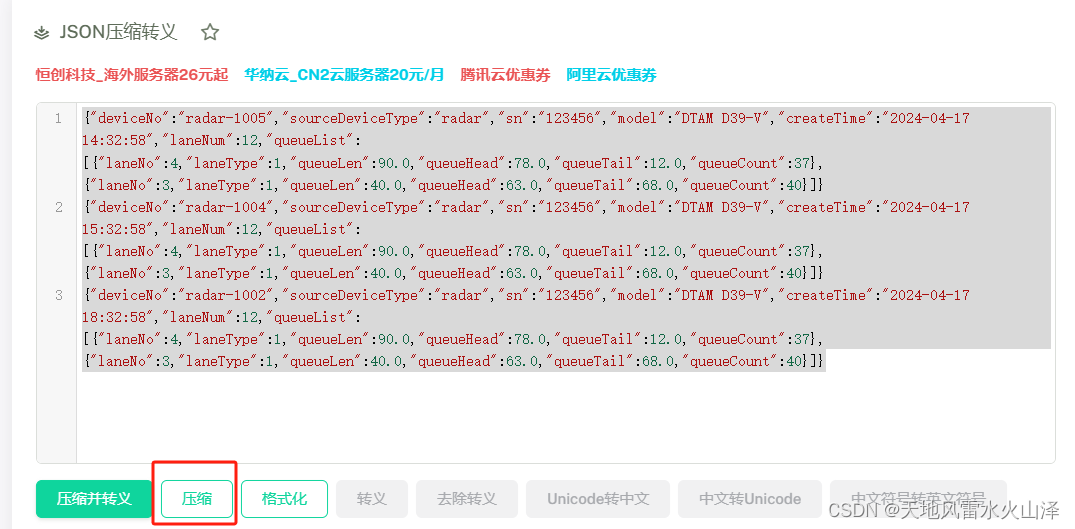
(一)准备json文件
![]()
注意:Json数据用JSOB工具压缩一下,1个完整的JSON为1行
(二)创建Kafka主题
[root@hurys23 bin]# ./kafka-topics.sh --create --bootstrap-server 192.168.0.23:9092 --topic topic_internal_data_queue --partitions 1 --replication-factor 1

(三)创建文件目录
[root@gree128 userfriends]# cd /opt/kb15tmp/
[root@gree128 kb15tmp]# mkdir -p /opt/kb15tmp/checkpoint/queue
[root@gree128 kb15tmp]# mkdir -p /opt/kb15tmp/checkpoint/data/queue

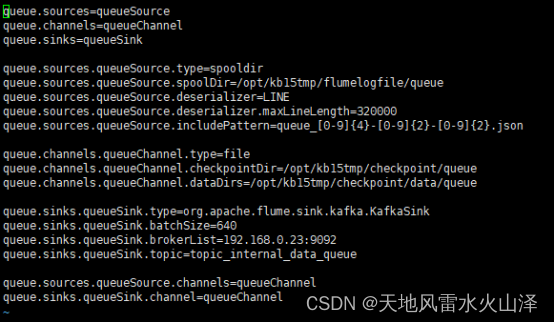
(四)配置Flume采集json任务文件
queue.sources=queueSource
queue.channels=queueChannel
queue.sinks=queueSink
queue.sources.queueSource.type=spooldir
queue.sources.queueSource.spoolDir=/opt/kb15tmp/flumelogfile/queue
queue.sources.queueSource.deserializer=LINE
queue.sources.queueSource.deserializer.maxLineLength=320000
queue.sources.queueSource.includePattern=queue_[0-9]{4}-[0-9]{2}-[0-9]{2}.json
queue.channels.queueChannel.type=file
queue.channels.queueChannel.checkpointDir=/opt/kb15tmp/checkpoint/queue
queue.channels.queueChannel.dataDirs=/opt/kb15tmp/checkpoint/data/queue
queue.sinks.queueSink.type=org.apache.flume.sink.kafka.KafkaSink
queue.sinks.queueSink.batchSize=640
queue.sinks.queueSink.brokerList=192.168.0.23:9092
queue.sinks.queueSink.topic=topic_internal_data_queue
queue.sources.queueSource.channels=queueChannel
queue.sinks.queueSink.channel=queueChannel
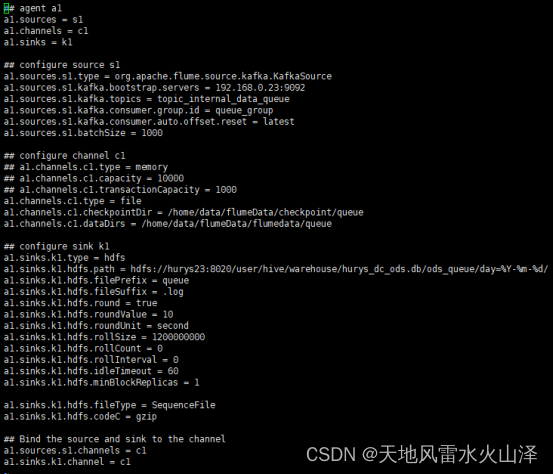
(五)修改Flume采集Kafka任务文件
## agent a1
a1.sources = s1
a1.channels = c1
a1.sinks = k1
## configure source s1
a1.sources.s1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.s1.kafka.bootstrap.servers = 192.168.0.23:9092
a1.sources.s1.kafka.topics = topic_internal_data_queue
a1.sources.s1.kafka.consumer.group.id = queue_group
a1.sources.s1.kafka.consumer.auto.offset.reset = latest
a1.sources.s1.batchSize = 1000
## configure channel c1
## a1.channels.c1.type = memory
## a1.channels.c1.capacity = 10000
## a1.channels.c1.transactionCapacity = 1000
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /home/data/flumeData/checkpoint/queue
a1.channels.c1.dataDirs = /home/data/flumeData/flumedata/queue
## configure sink k1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://hurys23:8020/user/hive/warehouse/hurys_dc_ods.db/ods_queue/day=%Y-%m-%d/
a1.sinks.k1.hdfs.filePrefix = queue
a1.sinks.k1.hdfs.fileSuffix = .log
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = second
a1.sinks.k1.hdfs.rollSize = 1200000000
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.rollInterval = 0
a1.sinks.k1.hdfs.idleTimeout = 60
a1.sinks.k1.hdfs.minBlockReplicas = 1
a1.sinks.k1.hdfs.fileType = SequenceFile
a1.sinks.k1.hdfs.codeC = gzip
## Bind the source and sink to the channel
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1
(六)打开监控,拷贝文件
[root@hurys23 kb15tmp]# cp queue.json /opt/kb15tmp/flumelogfile/queue/queue_2024-04-19.json

(七)执行Kafka消费窗口
[root@hurys23 bin]# ./kafka-console-consumer.sh --bootstrap-server 192.168.0.23:9092 --topic topic_internal_data_queue --from-beginning

(八)运行Flume采集Kafka到HDFS的任务
[root@hurys23 flume190]# bin/flume-ng agent -n a1 -f /usr/local/hurys/dc_env/flume/flume190/conf/queue.properties
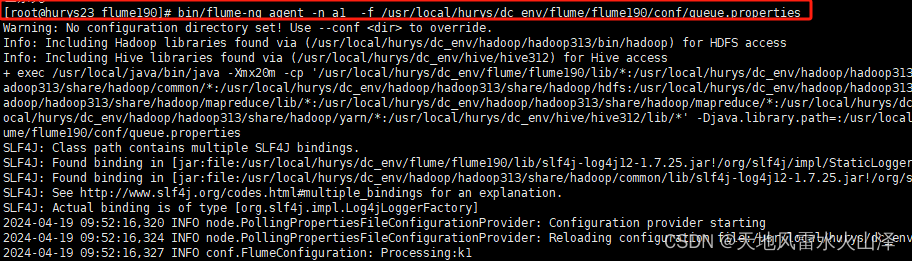
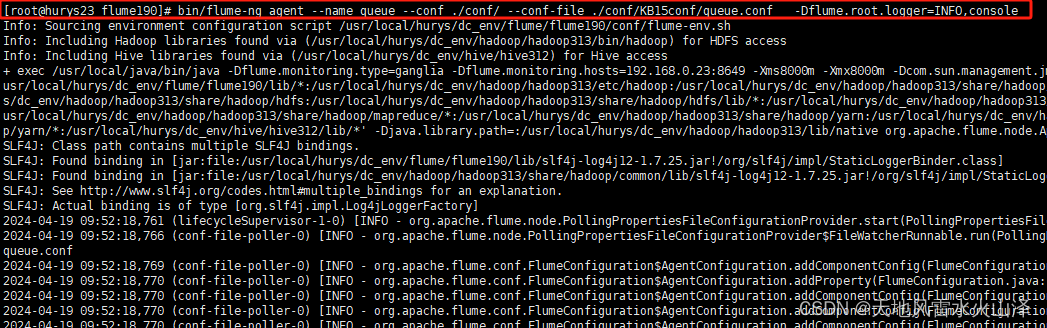
(九)运行Flume采集json文件到Kafka的任务
[root@hurys23 flume190]# bin/flume-ng agent --name queue --conf ./conf/ --conf-file ./conf/KB15conf/queue.conf -Dflume.root.logger=INFO,console
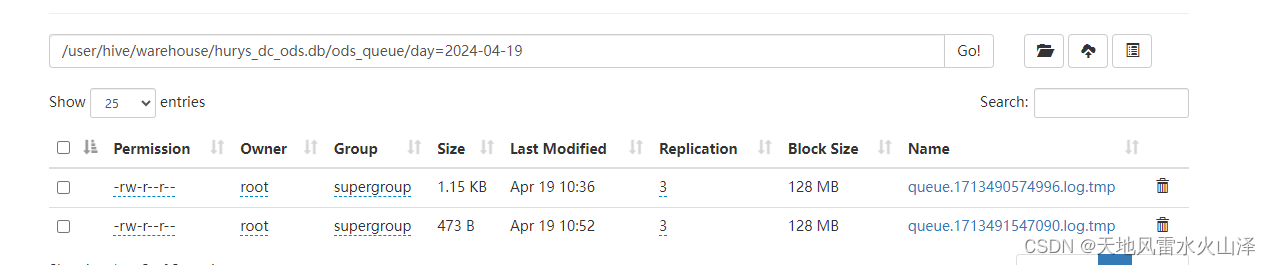
(十)查看HDFS文件
(十一)ODS层验证JSON格式是否正确,是否可以解析
--刷新表分区 msck repair table ods_queue;
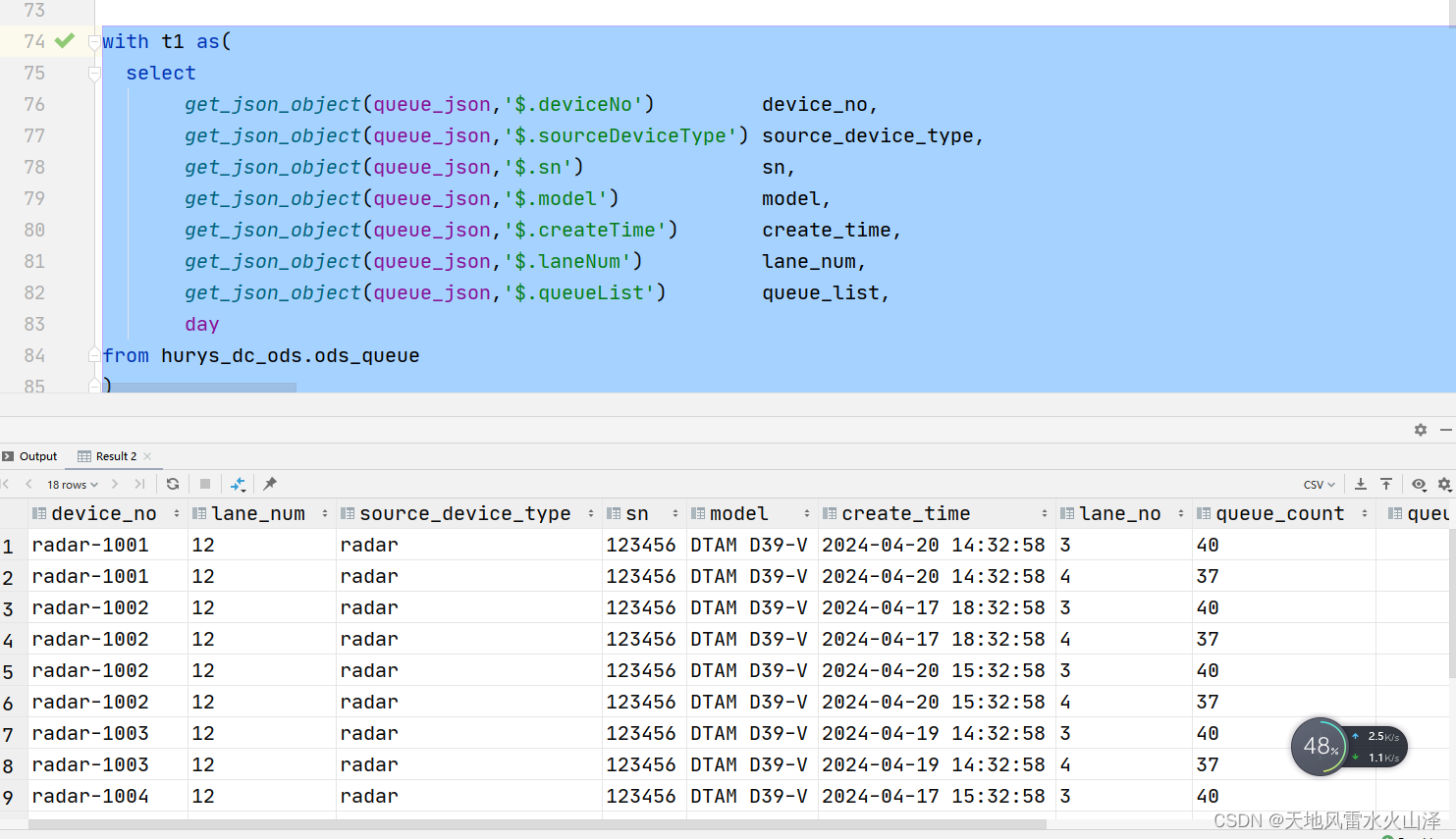
里面的JSON字段都可以解析出来,搞定!

