慢查询日志
概述
Redis的慢查询日志功能用于记录执行时间超过给定时长的命令请求,用户可以通过这个功能产生的日志来
监视和优化查询速度。服务器配置有两个和慢查询日志相关的选项:
- 1.slowlog-log-slower-than选项指定执行时间超过多少微妙(1秒=1000 000微妙)的命令请求会被记录到日志上
- 2.slowlog-max-len选项指定服务器最多保存多少条慢查询日志。
例子
- 举个例子。如果slow-log-slower-than选项的值为100,那么执行时间超过100微妙的命令就会被记录到慢查询日志,如果这个选项的值为500,那么执行的时间超过500微妙的命令就会被记录到慢查询日志
- 举个例子。如果服务器slowlog-max-len的值为100,并且假设服务器已经储存了100条慢查询日志,那么如果服务器打算添加一条新日志的话,它就必须先删除目前保存的最旧的那条日志,然后再添加新日志
- 举个例子。首先用COFIG SET将slowlog-log-slower-than选项的值设为0微妙,这样Redis服务器执行的任何命令都会被记录到慢查询日志中,接着讲slowlog-max-len选项的值设为5,让服务器最多保存5条慢查询日志:
127.0.0.1:6379> CONFIG SET slowlog-log-slower-than 0
OK
127.0.0.1:6379> CONFIG SET slowlog-max-len 5
OK
接着,用客户端发送几条命令请求:
127.0.0.1:6379> SET msg "hello world"
OK
127.0.0.1:6379> SET number 10086
OK
127.0.0.1:6379> SET database "Redis"
OK
然后使用SLOWLOG GET命令查看服务器所保存的慢查询日志:
如果这是再执行一条SLOWLOG GET命令,那么将看到,上一次执行的SLOWLOG GET命令已经被记录到了慢查询日志中,而最旧的、ID为0的慢查询日志已经被删除,服务器的慢查询日志数量仍然为5条
1) 1) (integer) 62) (integer) 17136709343) (integer) 54) 1) "SET"2) "database"3) "Redis"
2) 1) (integer) 52) (integer) 17136709273) (integer) 64) 1) "SET"2) "number"3) "10086"
3) 1) (integer) 42) (integer) 17136709233) (integer) 104) 1) "SET"2) "msg"3) "hello world"
4) 1) (integer) 32) (integer) 17136708683) (integer) 64) 1) "CONFIG"2) "SET"3) "slowlog-max-len"4) "5"
5) 1) (integer) 22) (integer) 17136708603) (integer) 74) 1) "CONFIG"2) "SET"3) "slowlog-log-slower-than"4) "0"
1) 1) (integer) 72) (integer) 17136709773) (integer) 20954) 1) "SLOWLOG"2) "GET"
2) 1) (integer) 62) (integer) 17136709343) (integer) 54) 1) "SET"2) "database"3) "Redis"
3) 1) (integer) 52) (integer) 17136709273) (integer) 64) 1) "SET"2) "number"3) "10086"
4) 1) (integer) 42) (integer) 17136709233) (integer) 104) 1) "SET"2) "msg"3) "hello world"
5) 1) (integer) 32) (integer) 17136708683) (integer) 64) 1) "CONFIG"2) "SET"3) "slowlog-max-len"4) "5"
慢查询记录的保存
服务器状态中包含了几个和慢查询日志功能有关的属性:
struct redisServer {
// ...// 下一条慢查询日志的ID
long long slowlog_entry_id;// 保存了所有慢查询日志的链表
list *slowlog;// 服务器配置slowlog-log-slower-than选项的值
long long slowlog_log_slower_than;// 服务器配置slowlog-max-len选项的值
unsigned long slowlog_max_len;// ...
}
slowlog_entry_id属性的初始值为0,每当创建一条新的慢查询日志时,这个属性的值就会用作新日志的ID值,之后程序会对这个属性的值增一。例如,在创建第一条慢查询日志时,slowlog_entry_id的值0会称为第一条慢查询日志的id,而之后服务器会对这个属性的值增一;当服务器再创建新的慢查询日志的时候,slowlog_entry_id的值1就会成为第二条慢查询日志的ID,然后服务器再次对这个属性的值增一,以此类推。slowlog链表保存了服务器中的所有慢查询日志,链表中的每个节点都保存了一个
slowlogEntry结构,每个slowlogEntry结构代表一条慢查询日志:
typedef struct slowlogEntry {
// 唯一标识符
long long id;// 命令执行时的时间,格式为UNIX时间戳
time_t time;// 执行命令消耗的时间,以微妙为单位
long long duration;// 命令与命令参数
robj **argv;// 命令与命令参数的数量
int argc;
} slowlogEntry;
例子
- 举个例子。对于以下慢查询日志来说:
2) 1) (integer) 52) (integer) 17136709273) (integer) 64) 1) "SET"2) "number"3) "10086"
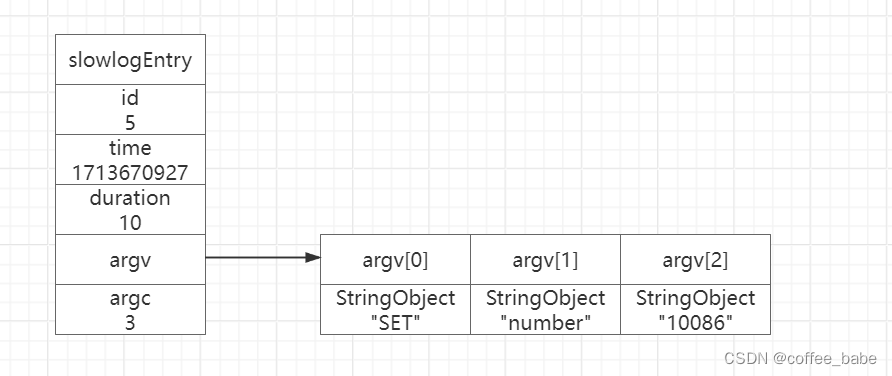
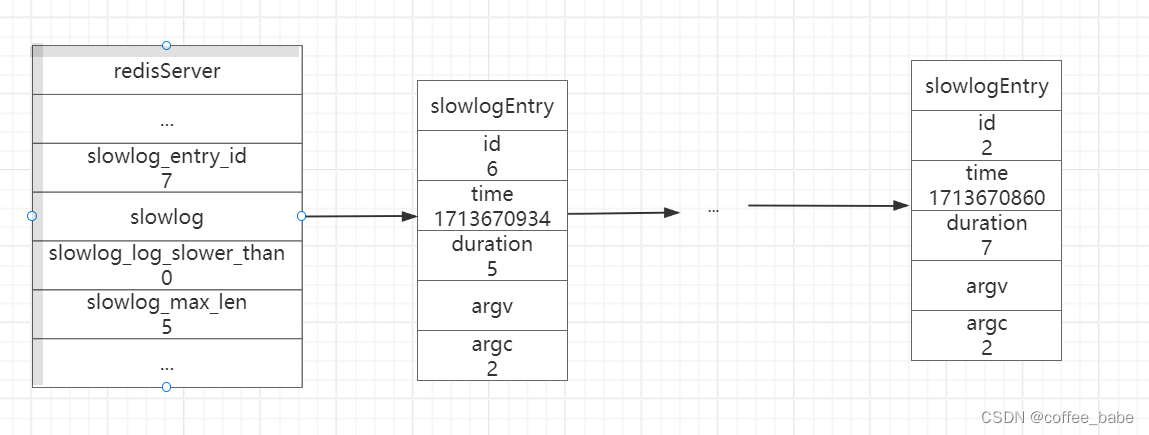
- 如图展示了服务器状态中和慢查询日志功能有关的属性:
1.slowlog_entry_id为7,表示服务器下条慢查询日志的id将为7
2.slowlog链表包含了id为6至2的慢查询日志,最新的6号日志排在链表的表头,而最旧的2号日志排在链表的表尾,这表明slowlog链表是使用插入到表头的方式来添加新日志的。
3.slowlog_log_slower_than记录了服务器配置slowlog-log-slower-than选项的值0,表示任何执行的时间超过0微妙的命令都会被慢查询日志记录
4.slowlog-max-属性记录了服务器配置slowlog-max-len选项的值为5,表示服务器最多储存5条慢查询日志
慢查询日志的阅览和删除
SLOWLOG GET命令的伪代码实现:
def SLOWLOG_GET(number=None):
# 用户没有给定number参数
# 那么打印服务器包含的全部慢查询日志
if number is None;
number = SLOWLOG_LEN()# 遍历服务器中的慢查询日志
for log in redisServer.slowlog:
if number <= 0:
# 打印的日志数量已经足够,跳出循环
break
else:
# 继续打印,将计数器的值减一
number -= 1
# 打印日志
printLog(log)
查看日志数量的SLOWLOG LEN命令可以用以下伪代码来定义
def SLOWLOG_LEN():
# slowlog链表的长度就是慢查询的条目数量
retuern len(redisServer.slowlog)
另外用于清除所有慢查询日志的SLOWLOG RESET命令可以用以下伪代码来定义
def SLOWLOG_RESET():
# 遍历服务器中的所有慢查询的日志
for log in redisServer.slowlog:
# 删除日志
deleteLog(log)