流程
- 导入所要使用的包
- 引入kaggle的数据集csv文件
- 查看数据集有无空值
- 填充这些空值
- 提取特征
- 分离训练集和测试集
- 调用模型
导入需要的包
python">import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
引入kaggle的数据集csv文件
python">train=pd.read_csv('train.csv')
test=pd.read_csv('test.csv')
datas = pd.concat([train, test], ignore_index = True)
查看数据集有无空值
python">datas.info()
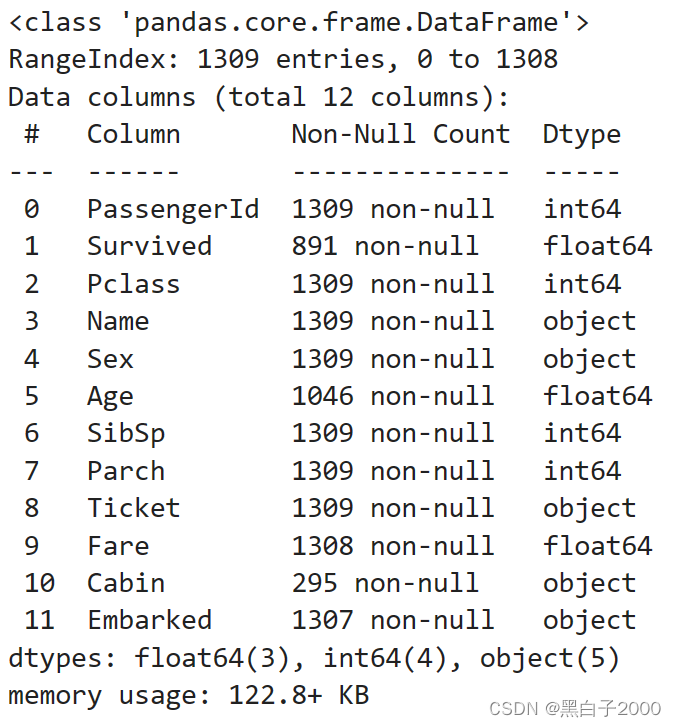
看到了有空值的属性列,Age,Fare,Cabin,Embarked
下面的操作就是给这些空值填充。
填充这些空值
首先填充少的Fare票价少了一行,先看一看这一行的信息
python">datas[datas['Fare'].isnull()]

已知信息,pclass等级是三类,说明比较贫穷
直接填一个较低的数字就行了
票价就给个差不多7.8好了,就一个数据缺失影响不大
python">datas['Fare']=datas['Fare'].fillna(7.8)
Embarked少了两行,先看一下这两行的信息
python">datas[datas['Embarked'].isnull()]
首先二人是女性,根据他们的女士优先的原则,存活概率比较高,pclass也是一级的,所以根据分配给他们三个港口存活率最高的C港口
python">datas['Embarked'] = datas['Embarked'].fillna('C')
还有Cabin船仓,缺失的很多,干脆把缺失的也归为一类,直接填充为U,然后每个取首字母,得到以字母为编号的船舱信息
空白填充为U
python">datas['Cabin']=datas['Cabin'].fillna("U")
每个取首字母
python">datas['Cabin']=datas['Cabin'].str.get(0)
还剩下一个数据是age年龄,缺失的也比较多,和存活率关系比较大,选用几个特征随机森林进行填充。
python">from sklearn.ensemble import RandomForestRegressor
ages = datas[['Age', 'Pclass','Sex']]
ages=pd.get_dummies(ages)
known_ages = ages[ages.Age.notnull()].values
unknown_ages = ages[ages.Age.isnull()].values
y = known_ages[:, 0]
X = known_ages[:, 1:]
rfr = RandomForestRegressor(random_state=60, n_estimators=100, n_jobs=-1)
rfr.fit(X, y)
pre_ages = rfr.predict(unknown_ages[:, 1::])
datas.loc[ (datas.Age.isnull()), 'Age' ] = pre_ages通过以上的操作,已经没有缺失值。
提取特征
由于外国人名字的特点,对其进行归类,人为的做一些特征
python">datas['Title'] = datas['Name'].apply(lambda x:x.split(',')[1].split('.')[0].strip())
datas['Title'].replace(['Capt', 'Col', 'Major', 'Dr', 'Rev'],'Officer', inplace=True)
datas['Title'].replace(['Don', 'Sir', 'the Countess', 'Dona', 'Lady'], 'Royalty', inplace=True)
datas['Title'].replace(['Mme', 'Ms', 'Mrs'],'Mrs', inplace=True)
datas['Title'].replace(['Mlle', 'Miss'], 'Miss', inplace=True)
datas['Title'].replace(['Master','Jonkheer'],'Master', inplace=True)
datas['Title'].replace(['Mr'], 'Mr', inplace=True)人多力量大,依据人性来看,有家庭成员的要比一个人的存活概率更高
python">datas['Fam_size'] = datas['SibSp'] + datas['Parch'] + 1datas.loc[datas['Fam_size']>7,'Fam_type']=0
datas.loc[(datas['Fam_size']>=2)&(datas['Fam_size']<=4),'Fam_type']=2
datas.loc[(datas['Fam_size']>4)&(datas['Fam_size']<=7)|(datas['Fam_size']==1),'Fam_type']=1
datas['Fam_type']=datas['Fam_type'].astype(np.int32)分离训练集和测试集
python">y=train['Survived']
features = ["Pclass", "Sex", "SibSp", "Parch","Title","Cabin","Fam_size","Embarked"]
# datas=datas.drop('Name',axis=1)
# datas=datas.drop('Age',axis=1)
# datas=datas.drop('Ticket',axis=1)
# datas=datas.drop('Fam_type',axis=1)
# datas=datas.drop('Fare',axis=1)
# qq=pd.get_dummies(datas)
train=datas[datas['Survived'].notnull()]
test=datas[datas['Survived'].isnull()].drop('Survived',axis=1)
X是训练集,取总数据的前这些行
python">X = pd.get_dummies(datas[features])
X=X.loc[0:890]
调用模型训练
python">from sklearn.ensemble import RandomForestClassifiermodel = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=1)
model.fit(X, y)划分测试集
python">X_test = pd.get_dummies(datas[features])
X_test = X_test.loc[891:1308]
输出文件
python">predictions = model.predict(X_test)output = pd.DataFrame({'PassengerId': test.PassengerId, 'Survived': predictions.astype(int)})
output.to_csv('mypredict.csv', index=False)