
接下来是Orca-2,这篇是微软在23年11月发表的论文,在Orca-1的基础上又进行了一些改进。

作者希望教会Orca-2各种推理策略,例如逐步思考、回忆然后回答、先回忆再推理再回答、直接生成回答等等策略。并且Orca-2应该能针对不同任务应该使用最合适的推理策略。
下图是Orca-2在各种benchmark上的表现,包括语言理解、常识推理、多步推理、数据问题等,可以看到Orca-2超过了所有同等规模的模型,并且接近(有时超过)了比它大5-10倍的模型。这里所有模型都是以LLaMA-2为基座模型训练得到的,排除了不同基座模型带来的性能差异。这里和Orca-1论文中不同,没比较ChatGPT是因为基座模型不同,没法体现出这篇论文训练方法所带来的优越性。

作者在这里探讨了一下不同的系统消息(推理策略)对推理结果带来的巨大影响,即使是GPT-4这样强大的模型也会受不同系统消息影响产生截然不同的推理结果。下面右图展示了这个现象,对GPT-4四次提问,第一次不添加系统消息,得到的答案是错误的。第二次使用类似思维链的系统消息,结果稍微好了一点,但也是错误的。第三次使用“解释你的答案”的系统消息,解释的过程是对的,但是答案是错的。第四次使用左边图中的系统消息,得到了正确的答案和推理过程。

所以针对不同的任务应该使用不同的系统消息(推理策略),这也是作者希望Orca-2做到的,能根据手头的问题选择最有效的解决策略。具体过程分为四步,第一步是先准备好一系列多样的任务。第二步是根据Orca-1的表现,决定每个任务需要哪种推理策略。第三步是根据推理策略写下系统消息,然后输入给教师模型获得回答,这样就得到了训练数据,训练数据的格式是个三元组(system instruction, user prompt, LLM answer)。第四步是prompt擦除,这是比较关键的一步,在训练时将特定任务相关的system instruction替换为与任务无关的通用system instruction,例如下图这样的instruction。这样学生模型只能看到问题和详细的回答,鼓励学生自己学习如何运用推理策略生成谨慎且有逻辑的回答,以及针对特定任务如何选择最优的推理策略。

训练用的数据集分为三部分,包括FLAN-v2的训练集、Orca-1收集的600万条数据、Orca-2新增的81万条数据。
其中Orca-2新增的数据又来自四个部分,第一部分是从FLAN-v2四个子集中1913个任务筛选出1448个高质量任务,从这些高质量任务的训练集中选择了60万个zero-shot问题,然后用这些问题输入LLM合成回答。之后这些数据再经过prompt擦除就可以了。第二部分是包含5万条数据的few-shot数据,将Orca-1数据集转为四元组(task, system instruction, user prompt, answer),然后针对同一个(task, system instruction)随机抽取3-5条(user prompt, answer)组成一条few-shot数据。这里没提到prompt擦除,那应该是没进行特殊处理。第三部分是收集了16万条数学问题。第四部分是完全合成的数据,使用GPT-4创建了2000次医患对话,然后每次对话生成一个摘要。
接下来是训练过程,这里使用LLaMA-2的7B和13B版本作为基座模型,也是类似Orca-1,使用渐进式学习方法来进行训练。先在FLAN-v2数据集上微调1个epoch,然后在500万条ChatGPT数据上微调3个epoch,最后在100万条GPT-4和Orca-2的81万条数据上微调4个epoch。
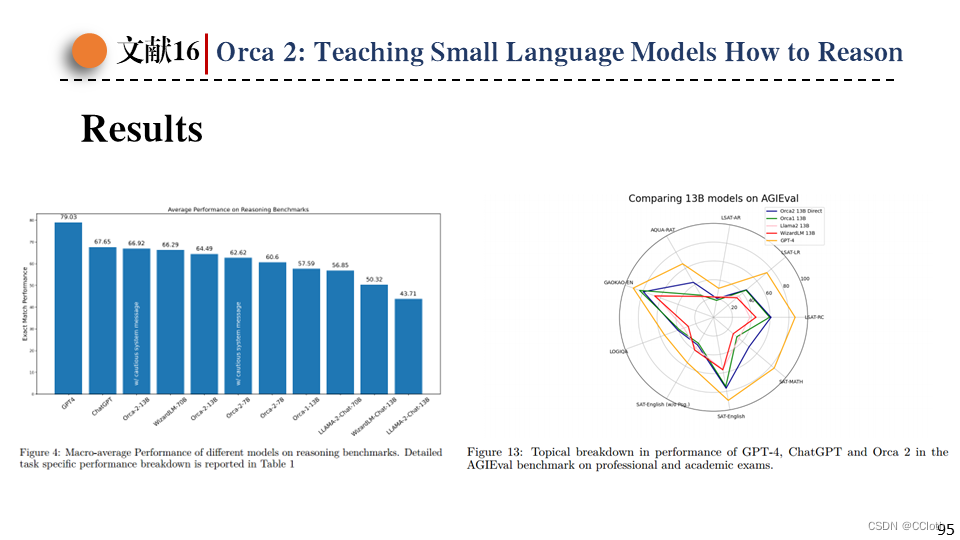
最后是模型性能展示,左侧为模型推理能力,可以看到13B版本的Orca-2已经无限接近ChatGPT了,并且优于其他13B的网络。右侧是Orca-2在学术考试上的结果,基本达到了13B网络的天花板。





![[Java基础揉碎]集合](https://img-blog.csdnimg.cn/direct/1f8272c26d0540a68fedf1f70fada69e.png)

