前言
本文是根据python官方教程中标准库模块的介绍,自己查询资料并整理,编写代码示例做出的学习笔记。
根据模块知识,一次讲解单个或者多个模块的内容。
教程链接:https://docs.python.org/zh-cn/3/tutorial/index.html
互联网访问
Python在互联网访问方面提供了强大的支持,无论是通过标准库还是第三方库,都能轻松实现网页抓取、API调用、数据下载等多种任务。
这里讲一下常用的互联网访问模块。
- urllib(包括urllib.request, urllib.parse, urllib.error): Python的标准库,可以用来打开URLs、解析URLs、读取网页内容等。虽然不如requests直观,但在不需额外安装的情况下也能完成基本的网络请求。
- requests: 这是最常用的第三方库,用于发送HTTP/1.1请求。它提供了简单的API来执行GET、POST等HTTP方法,同时处理JSON数据、二进制文件和响应内容也非常方便。.
- aiohttp: 面向异步编程的HTTP客户端/服务器库,适用于需要高效并发处理大量网络请求的场景。它基于Python的asyncio框架。
urllib
urllib 是Python标准库的一部分,提供了丰富的功能来处理URLs,包括请求的发送、解析等。
它包含四个子模块:urllib.request、urllib.parse、urllib.error 和 urllib.robotparser。
这四个模块我们一个个讲。
urllib.request
用于打开URLs,发送HTTP、FTP请求等。
常用的函数:
- urlopen(url, data=None, [timeout,]*, cafile=None, capath=None, cadefault=False, context=None):打开URL,返回一个文件类对象,可以用此对象的方法读取URL的内容。之前文件流不是学过open函数吗?open前面加个url,那么这个函数大概啥作用应该能猜出来,要有这种根据函数名联想函数功能的能力,同样也要有根据函数功能命名函数的能力。
- Request(url, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None)
from urllib import parse
from urllib.request import urlopen, Request
python"># GET请求示例
with urlopen('http://www.example.com/') as response:content = response.read()print(content.decode('utf-8'))print("================分隔符===============")# POST请求示例
url = 'http://httpbin.org/post'
headers = {'User-Agent': 'Mozilla/5.0'}
data = bytes(parse.urlencode({'key': 'value'}), encoding='utf8')
req = Request(url, data=data, headers=headers, method='POST')
with urlopen(req) as res:print(res.read().decode('utf-8'))
代码中出现的两个链接是开源的测试学习用的地址。大家学习访问互联网信息的时候也可以去访问这两个网址。
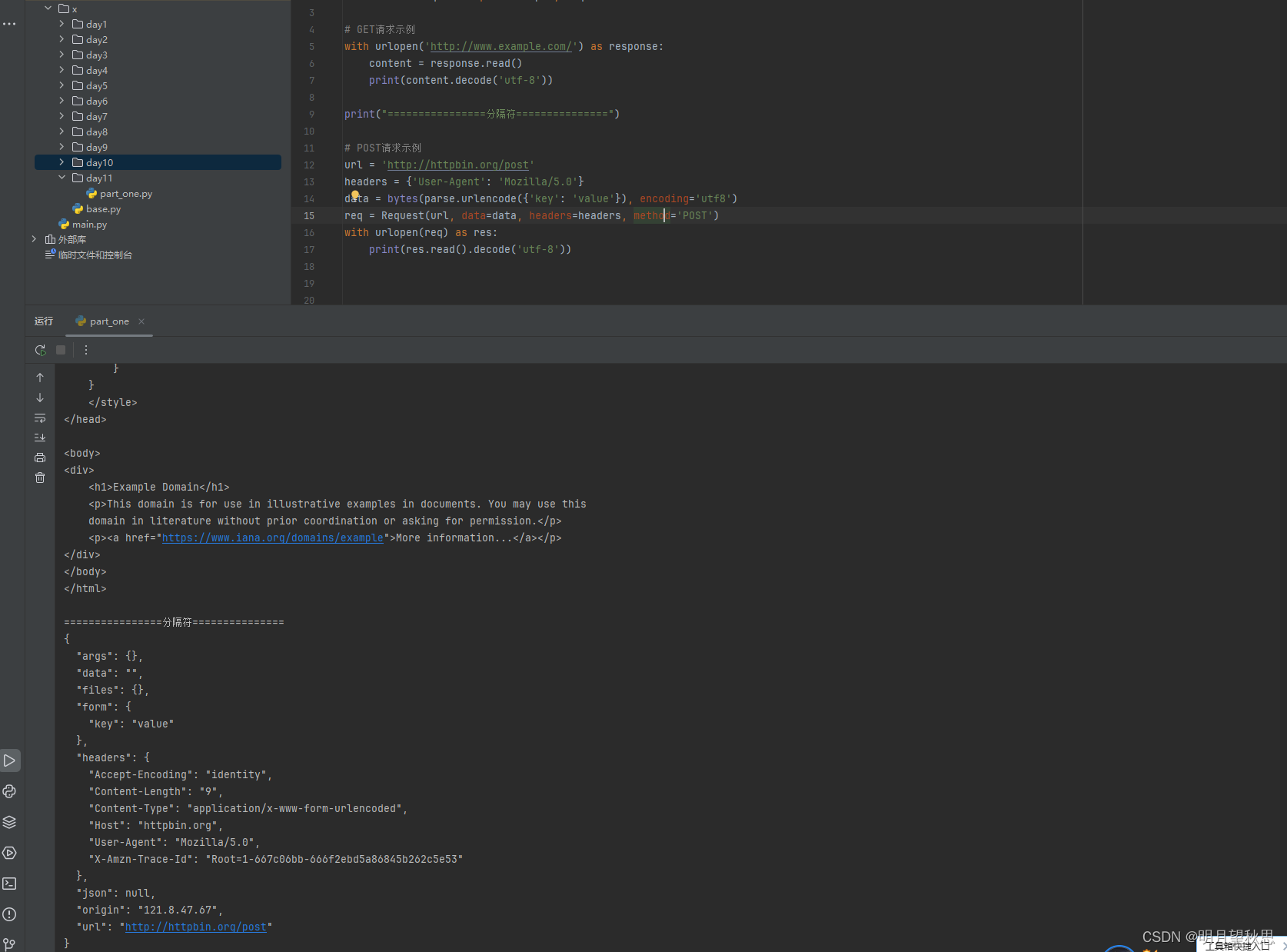
分析我们打印的信息。
我们使用urlopen函数打开了http://www.example.com/这个链接返回的是一个文件类型对象,我们使用read函数读取了内容并打印。你可以把打印信息复制到一个.txt的文件里面,把文件改成.html格式,打开以后样式和你直接访问是一样的。

第二个输出则是打印了我们模拟的一个http请求的信息。这里我就不详细解释这些字段一个个是啥了。
urllib.parse
提供URL解析和操作功能,如分解URL、构建查询字符串等。其实在urllib.request中,解析请求信息使用了一下。
常用函数
- urlencode(query):将字典转换成URL编码的字符串。
- parse_qs(qs, keep_blank_values=0, strict_parsing=0, encoding=‘utf-8’, errors=‘replace’):将URL查询字符串解析成字典。
- urlsplit(url, scheme=‘’, allow_fragments=True):分割URL为组成部分。
python">from urllib.parse import urlencode, parse_qs, urlsplit# 构建查询字符串
query_params = {'name': '明月望秋思', 'age': 28}
encoded_query = urlencode(query_params)
print(encoded_query)
print("================分隔符===============")
# 解析查询字符串
query_string = 'name=%E6%98%8E%E6%9C%88%E6%9C%9B%E7%A7%8B%E6%80%9D&age=28'
parsed_query = parse_qs(query_string)
print(parsed_query)
print("================分隔符===============")
# 分割URL
url = 'https://www.example.com/path?query=value#fragment'
components = urlsplit(url)
print(components)
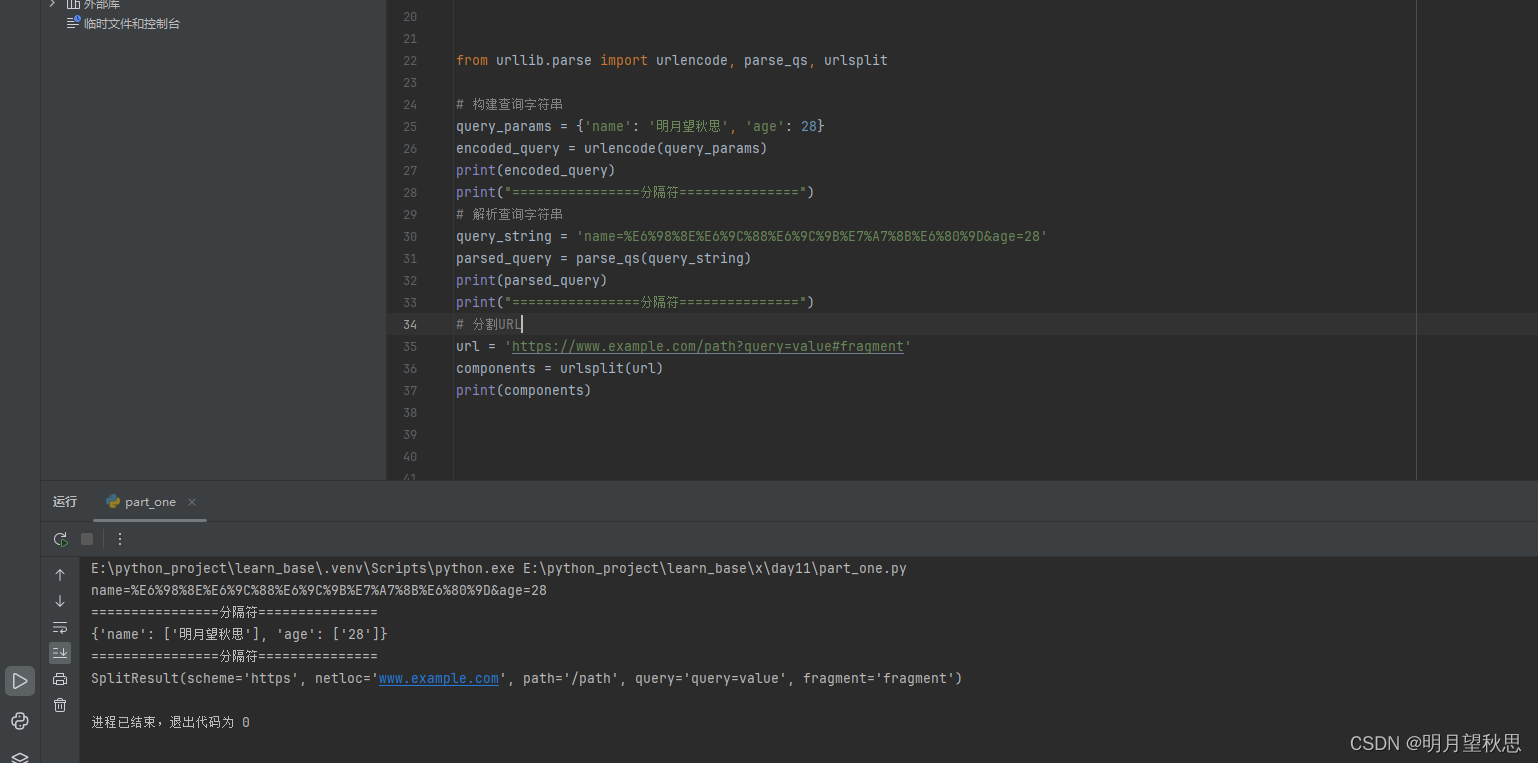
可以看到中文被转换成了一堆看不懂的符号加字母,然后用一串东西又能解析回中文。实际上我们有时候在复制一些网站链接的时候也会复制出这样的一串,但是链接仍然能访问,原理是一样的。
最后一串输出就没啥特殊的了,把url分割了。这个函数可以用在什么地方呢?需要获取url中的信息的时候,就可以用这个函数分割获取想要的信息。
urllib.error
定义了由urllib.request抛出的异常,如URLError和HTTPError。这些异常在使用urllib.request进行网络请求时可能被抛出。了解这些异常有助于进行错误处理和调试。
这里没有函数需要学习的,涉及到的知识点就是我们之前学习的异常处理,我们可以通过捕获上面两种error来进行针对性的处理或者打印日志信息等。
urllib.robotparser
解析robots.txt文件,帮助遵守网站的爬虫协议。robots.txt文件定义了网站上哪些页面可以被爬虫访问,哪些不可以。
常用函数
- RobotFileParser(url=‘’): 创建一个RobotFileParser对象,用于解析给定URL的robots.txt文件。
- read(): 从已设置的URL读取并解析robots.txt文件。
- can_fetch(useragent, url): 判断指定的user-agent是否可以抓取指定的URL。
- parse(lines): 从一个文件或列表中解析robots.txt的规则。
python">from urllib.robotparser import RobotFileParser# 初始化一个RobotFileParser对象,指定网站的robots.txt文件URL
rp = RobotFileParser('http://www.example.com/robots.txt')# 读取并解析robots.txt文件
rp.read()# 检查user-agent "my-bot" 是否可以抓取 "http://www.example.com/path"
print(rp.can_fetch('my-bot', 'http://www.example.com/path'))
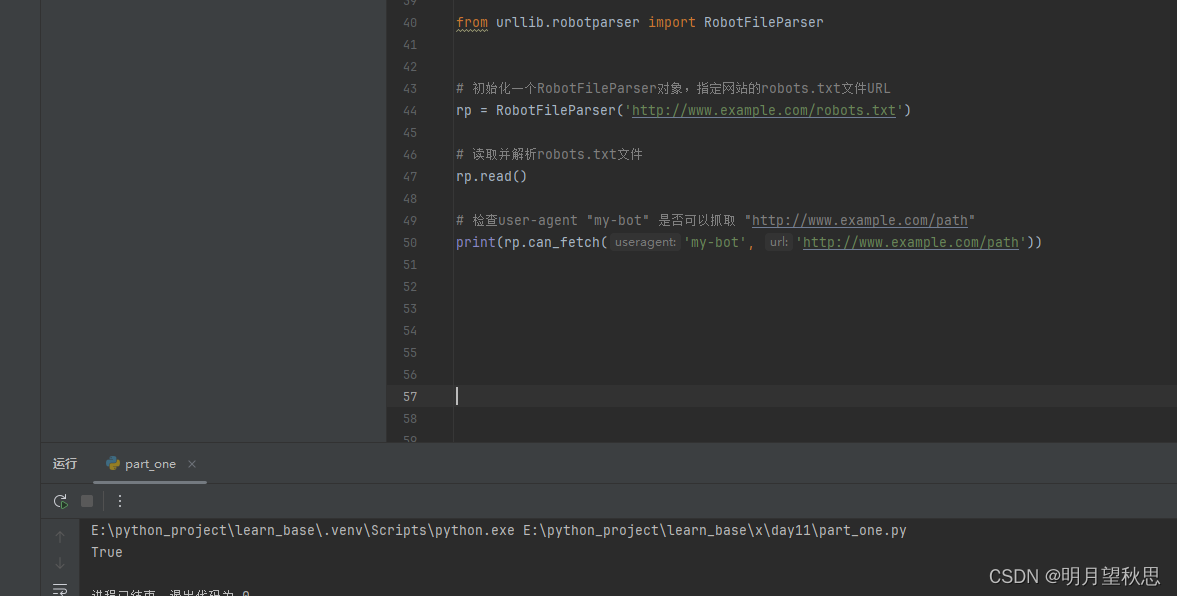
通过控制台打印的输出,我们知道了这个网站是可以被抓取的。
这里也贴一些关于robots.txt文件的知识,包括怎么检查网站有没有这个文件,这个文件的意义作用。
检查网站是否存在robots.txt文件很简单,可以直接在浏览器中输入网站域名后加上/robots.txt来尝试访问,或者使用编程方式发送HTTP请求到该地址。例如,对于www.example.com,你可以在地址栏输入http://www.example.com/robots.txt来查看。
存在robots.txt文件的意义:
指导爬虫行为:robots.txt文件是网站所有者与网络爬虫之间的协议,用于告知爬虫哪些页面可以被抓取,哪些不可以。这有助于爬虫更高效地工作,避免访问被禁止的区域,减少服务器负担。
保护隐私和安全:通过限制敏感或非公开页面的访问,网站可以有效保护用户数据和内部系统的安全。
优化资源分配:网站管理员可以利用robots.txt来引导搜索引擎爬虫关注更重要的内容,忽略如登录页、搜索结果页等动态生成或对SEO无益的页面。
缺失robots.txt文件的意义:
默认允许抓取:如果一个网站没有robots.txt文件,大多数搜索引擎和爬虫会默认认为所有页面都是允许抓取的。这意味着网站上的所有公开可访问的内容都有可能被搜索引擎索引。
缺乏明确指引:没有该文件,爬虫开发者或SEO专家无法获得关于网站爬取的具体指导,可能需要更多时间来确定哪些内容是应该或不应该被爬取的。
潜在的隐私或安全风险:在某些情况下,缺少robots.txt可能导致一些本应受保护的页面被意外抓取,尤其是在网站结构复杂或配置不当的情况下。
urllib模块暂时就讲到这里。
由于我们目前主要学习一些标准库,所以另外两个模块只简单记录,项目中用到在单独学习记录。
requests
这个库是Python中最受欢迎的HTTP库之一,它允许你以非常简单的方式发送HTTP请求,并处理响应。这个库的设计理念是“让HTTP服务人类”,因此它具有简洁的API和高度可读性,使得网络请求变得直观易懂。
get和post
python">import requestsresponse = requests.get('http://example.com')
# 打印HTTP响应状态码
print(response.status_code)
print("================分隔符===============")
# 打印响应内容的文本形式
print(response.text)
print("================分隔符===============")
data = {'key': 'value'}
response = requests.post('http://httpbin.org/post', data=data)
# 如果响应内容是JSON格式,可以直接解析为字典
print(response.json())
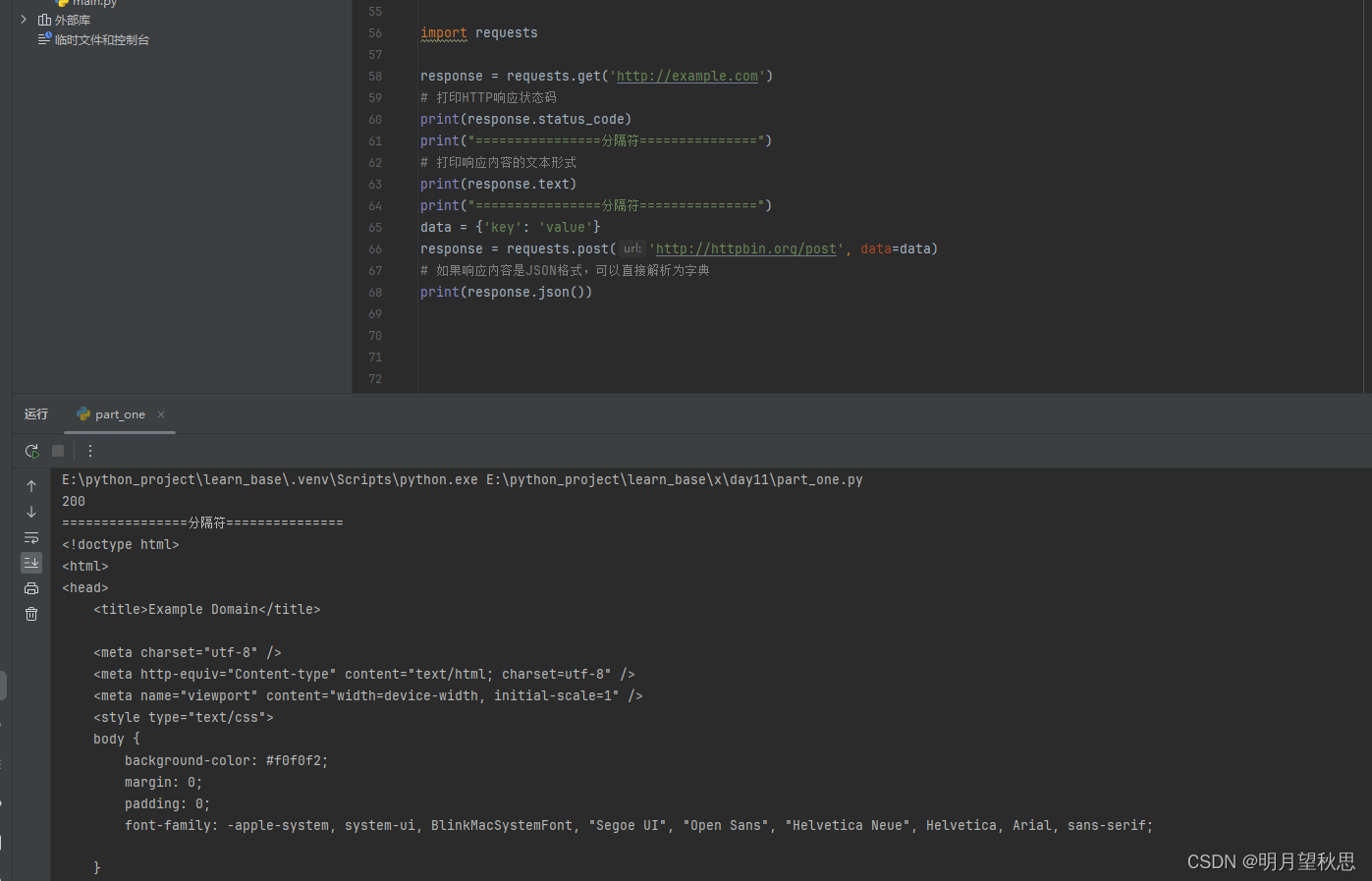
可以看到,仅仅是两三行代码,并且很简单明了的代码,我们就成功通过两个不同方式请求了一个网址,并成功获得返回信息。
Session
requests.Session()可以创建一个会话对象,它可以在多个请求之间保持某些参数,比如Cookies,这对于登录认证等场景非常有用。
python">s = requests.Session()
s.get('http://httpbin.org/cookies/set/sessioncookie/123456789')
response = s.get('http://httpbin.org/cookies')
print(response.text)

file
通过files参数上传文件
python">files = {'file': open('report.xls', 'rb')}
response = requests.post('http://httpbin.org/post', files=files)
在代码中,我们定义了一个files的参数,这个files的参数值则是文件report.txt文件。注意rb这个参数,表示我们读取二进制模式,通常文件上传也是读取文件二进制流的形式。然后将files参数使用post函数请求。
aiohttp
aiohttp库是为Python异步编程设计的,提供了异步HTTP客户端和服务器功能,基于Python的asyncio框架,非常适合构建高性能的异步网络应用程序。目前用不上,简单贴个示例看看就行。
python">import aiohttp
import asyncioasync def post_request(session, url, data):async with session.post(url, data=data) as response:return await response.text()async def main():async with aiohttp.ClientSession() as session:data = {'key': 'value'}response_text = await post_request(session, 'http://httpbin.org/post', data)print(response_text)# 同样,使用 asyncio.run 或者 loop.run_until_complete 来启动异步事件循环
asyncio.run(main())
结尾
关于Python访问互联网的知识就讲这些。主要了解标准库urlliib的知识,另外两个库的知识后面接触到会再深入学习。
作业
- urllib的函数使用。


![[职场] 教师资格面试流程 #经验分享#其他](https://img-blog.csdnimg.cn/img_convert/78092a603f0c7217bedbcca6bb41a092.jpeg)

