1.磁盘与物理内存间的数据为什么以4KB交互?
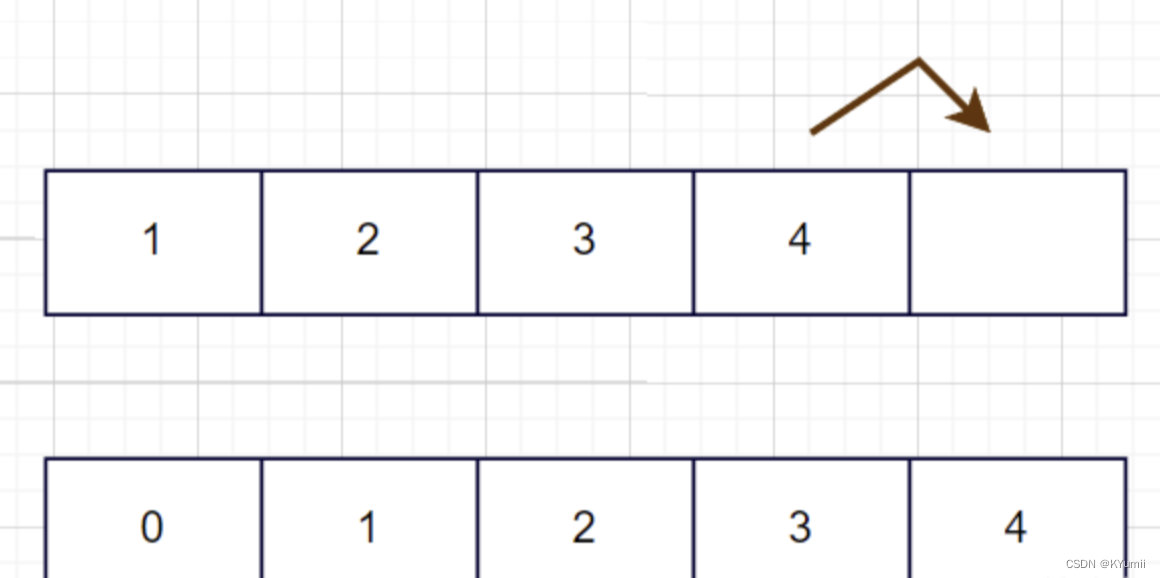
物理内存我们可以看成是多个4KB的单元,每一个4KB也称为页框;
因为文件在文件系统里存储的数据块是一个个4KB的单元,在磁盘上的文件也是被划分成多个4KB单元,每一个4KB也称作页帧;
那么这样的话物理内存与磁盘文件进行数据交互时就以4KB为单位进行数据交换。
4KB是啥意思呢?
比如当我们要访问100字节时,读取的并不是100字节而是4KB,
那么就会有人想,这不是访问变慢了吗?为什么不以要100字节就访问100节的方式? 其实不然。
一方面,因为但我们对数据访问时的主要矛盾是硬件,通俗的讲就是主要耗费时间的是硬件的磁头在寻找盘片,磁道,扇区这一过程,而在找到数据所在的位置后读取100字节和4KB其实差距不大;
另一方面,我们可以这么想,我们读取的是100字节,但是过一会我们会不会读取这100字节的附近的相关内容呢?这大概率是可能的。这一行为也被称作操作系统的一种预加载机制,可以减少io这一过程。
通过这两方面可以看出以4KB访问可以大大提高访问效率。
那当我们需要的是100字节,但实际上访问到的是4KB,那不会有垃圾数据吗?
答案是不会的,因为文件的属性里面记录着文件的大小,所以在进行读取时是可以正确的读取到数据。
那为什么是4KB而不是其他呢?
4KB这一个结果是科学家对计算机各方面经过大量的数据测试,综合来说性能最优的。
struct page结构体(存放了page页必要的属性信息)
物理内存被划分成多个页框,操作系统肯定是要将期管理起来的,
通过struct page这一结构体来描述每一个页框的信息,在通过struct page mem_array[1,048,576]这一个数组进行存储,这样就将内存管理起来了。
又因为数组是有下标的,那么我们就可以给每一个页框一个下标,这个下标就称为页号。
当我们要访问一个内存,只要通过虚拟地址找到页号,也就找到这个4KB对应的page,对应
的页框。
那么我们就可以知道所有对内存的操作就变成了对这个数组的操作。
管理内存的数组也是存放在内存当中的,所以page的大小是不能大的,这也是联系到了上面为什么以4KB划分这一问题,当以更小内存划分时就会产生更多page,对内存的消耗就更多了。
虚拟地址和物理地址的转化
由上可知,内存被分为多个4KB,那么我们只要将虚拟内存的低12位去掉就可以得到管理内存的数组的下标,即对应的页框。
0x12345678 & 0xfffff00 就可以得到虚拟地址映射的物理地址 。
内存分配和回收
1.伙伴系统算法
1.内存的分配
伙伴系统是分配内存的一种方法,操作系统将内存分配的大小划分成11个区域,大小分别是2的n次方(n=0,1,2,3.....11),单位是页,比如:2的1次方大小就是两个页。
当操作系统接收到要申请内存的大小时,会找到指定的区域进行分配。
那么是如何判断区域是否是满足条件的?
递归寻找满足申请内存大小大于分区的一半的区域,在该区域里寻找空闲块。
1.如果有空闲块就直接使用就可以了,
2.如果没有空闲块,就会向内存块更大的一级寻找空闲块,以此类推,
①如果到11分区也没有找到空闲块,则内存申请失败
②在更高级别的分区找到空闲块后,会一分为二的将空闲块分成相等的两份传给下一个分区,知道传递到我们申请内存所需的分区。


2.空闲块的合并

在我们释放完空闲块后会对相邻的块进行检查,判断是不是空闲块,
1.如果是空闲块,且将要合并的这两个块中低地址的块的地址要为2的(i+1)次幂的倍数,这两个空闲块就可以合并,合并完和有会对相邻的块进行检查,以此类推(操作系统通过递归的方式完成) 在上图的体现就是当D释放后并不会和左边256K进行合并,而是和右边的256K合并,也是就是他们要有相同的父亲节点。
2.如果不是空闲块就不合并
slab分派器
在我们进行小内存申请时,比如要申请128个字节,伙伴系统算法则会分配4KB的空间,这显然是浪费了大量的空间。
slab分配器在我们进行小内存申请时会将页再次进行细分。


如上图我们会将相同大小的slab构成一个链表存放在kmem_cache中,每一个kmem_cache保存的是大小不同的slab,然后我们又可以将kmem_cache以双向链表的形式管理起来。
kmem_cache_cpu是CPU的本地缓存,数据交换速度快,所以操作系统会将部分slab加载到CPU的本地缓存当中,当CPU本地缓存没有对应的slab时再将内存中的slab加载到CPU的本地缓存。
内存的缓存机制
对于高频率使用的内核数据结构对象操作系统会将其缓存起来下次使用时就不用再申请内存了。
进程打开一个文件是如何打开的?
1.文件的属性获取
struct file 里面有一个struct inode这一个结构体的指针,struct inode里保存了绝大部分属性
当我们在进程中打开一个文件时,我们会输入路径和文件名,通过对路径的解析得到各个目录,然后在存储目录的树形结构中就可以找到文件对应的目录,
然后对这个目录的数据块(date block)进行访问,用文件名就可以获得对应的inode编号,通过inode编号就可以获得这个文件的inode
然后通过获取到的inode在内存中的inode bitmap链表里就可以查询对应的inode bitmap判断inode table是否存在,存在就读取其中的内容加载到struct inode结构体中。
2.文件的内容获取
struct file 里面有一个struct address_space这一个结构体的指针,struct address_space结构体内有struct radix_tree_node的根节点,以struct radix_tree_node构建了基树进行对struct page的映射

在struct radix_tree_node中的unsigned long tags[RADIX_TREE_MAX_TAGS][RADIX_TREE_TAG_LONGS]结构会存放一些标签,
标签通常用于快速确定节点或子树是否满足某种条件,而无需遍历整个树。例如,你可以使用标签来标记哪些节点包含特定的数据,或者哪些节点已经被访问过。当需要查询满足特定条件的节点时,只需检查相应的标签即可,而无需遍历整个树,从而大大提高了查询效率。
补充:
当我们启动linux操作系统时,会将文件系统的相关信息加载到内存中,比如:super block,inode bitmap,block bitmap,以双向链表的形式进行管理起来。
内存与磁盘的IO(与进程管理已经没有关系了)
当我们把数据从用户层拷贝到了内存后,就需要刷新到磁盘上,通过IO子系统完成。
由于每个页框都会有各自的状态,操作系统会将要刷新的页框用struct request结构体来描述,其中里面就有所要刷新到磁盘的地址。
struct request成员如下

面对如此多的IO请求我们肯定也是要将其管理起来的,操作系统用IO request queue(IO请求队列)
将这些管理起来。
这么多的请求,有的可能访问的是扇区1,有的可能访问的是扇区3....,
这些请求所访问的区域并不是连续的,那么在寻址时时间上的消耗就比较大,这是我们所不希望的,
那么操作系统为解决这一问题会将这些请求进行排序,将地址相邻的放到一起进行IO合并,这样就减少了IO的次数,提高了访问效率