在本篇博客中,作者将会讲解普通的二叉搜索树,其目的是为后面的AVLTree和红黑树进行铺垫。
一. 二叉搜索树
那么什么是二叉搜索树呢,二叉树应该大家都能理解,所以顾名思义,二叉搜索树就是一个用来搜索的二叉树,二叉树搜索树也可以叫做一棵二叉排序树,因为它的中序遍历是有序的。
1.性质
二叉搜索树的性质:
1.如果当前结点的左子树不为空,则左子树上的所有结点都小于该当前结点。
2.如果当前结点的右子树不为空,则右子树上的所有结点都大于该当前结点。
3.它的左右子树分别也是二叉搜索树。
即一棵二叉树的中序遍历是有序的就是二叉搜索树,也叫二叉排序树
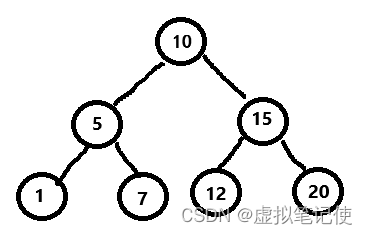
如下就是一棵二叉搜索树。
二.二叉搜索树的实现
那么已经知道了二叉搜索树是什么,也知道了它的性质,那么现在我们来实现一下。
首先,二叉搜索树最主要的接口有下面这几个:
1.插入
2.删除
3.查找
4.修改(注意,不是所有二叉搜索树都能修改的,因为二叉搜索树要严格遵守它的性质,一旦它的性质被破坏,则这棵树就会无意义)
1.树结点的定义
首先我们来看一下树结点的定义。
template<class K>
struct Blog_TreeNode
{//成员变量K _key;Blog_TreeNode<K>* _left;Blog_TreeNode<K>* _right;//成员函数Blog_TreeNode(const K& key)//构造函数:_key(key),_left(nullptr),_right(nullptr){}
};树结点的定义不是很难,就二叉树常规的定义即可。
2.类的定义
我们可以把树结点封装到一个Blog_Tree的类中,在类中实现它的成员函数。
template<class K>
class Blog_Tree
{typedef Blog_TreeNode<K> Node;//typedef一下,这样在类中可以使用Node来代替Blog_TreeNode
public://构造函数Blog_Tree():_root(nullptr){}private:Node* _root;//成员变量为一个根节点的指针
};3.构造函数与析构函数
对于一个类,有四个比较重要的成员函数:构造函数、析构函数、拷贝构造、赋值=重载。
在这里,拷贝构造和赋值=重载先不做讲解,先把构造函数和析构函数进行讲解。
①构造函数
对于二叉搜索树的构造函数来说非常简单,直接把_root给nullptr即可。
//构造函数Blog_Tree():_root(nullptr){}②析构函数
对于析构函数来说,我们可以使用后序遍历来完成。
//析构函数~Blog_Tree(){destory(_root);}void destory(Node* root){if (root == nullptr)return;destory(root->_left);destory(root->_right);delete root;}4.插入结点
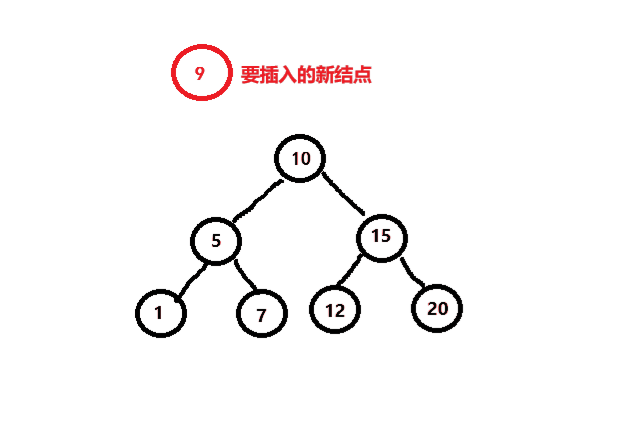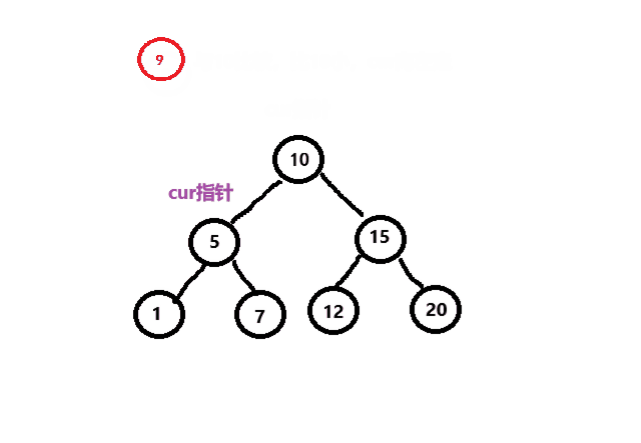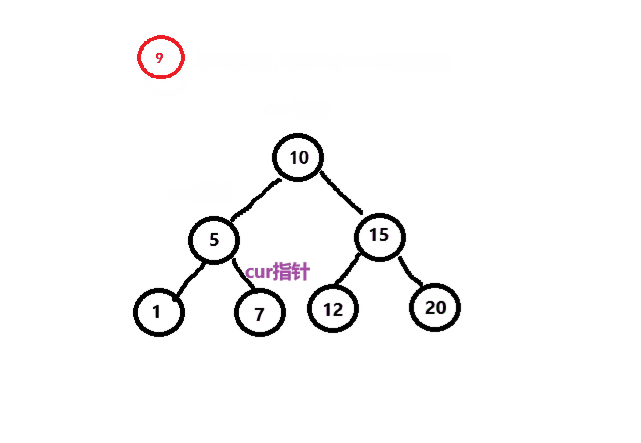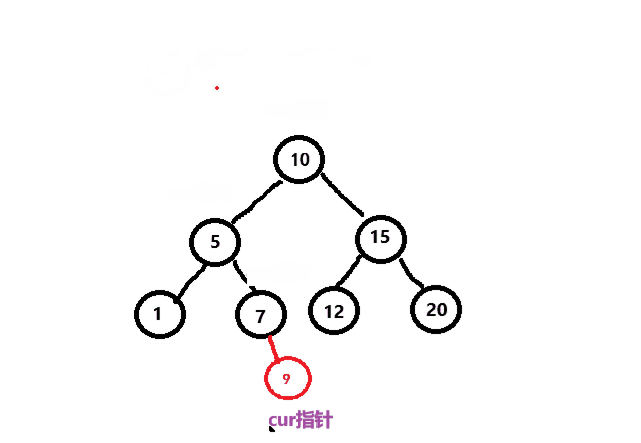
二叉搜索树插入结点的过程如下:
1.如果树为空,则直接将新结点给_root根结点。
2.如果树不为空,则将新结点与当前结点进行比较,如果新结点大于当前结点,则当前结点向右走,否则向左走,如果相等,则不插入。
如下图所示。
接下来我们来编写代码来实现这个过程。
//插入结点bool insert(const K& data){//如果树为空,则直接将新结点给到_rootif (_root == nullptr)_root = new Node(data);//如果树不为空,这开始找空位,将新结点插入Node* cur = _root;Node* cur_parent = nullptr;//这里要提前保留cur的parent,因为后面插入时要用到while (cur != nullptr){if (data > cur->_key)//如果要插入的数据大于cur,则cur往右走{cur_parent = cur;//保留cur的parentcur = cur->_right;}else if (data < cur->_key)//如果要插入的数据小于cur,则cur往左走{cur_parent = cur;//保留cur的parentcur = cur->_left;}else//如果相等,说明树中已有,则不插入,返回失败{return false;}}//找到空位后,将新结点进行插入Node* newnode = new Node(data);if (cur_parent->_key > newnode->_key)cur_parent->_left = newnode;elsecur_parent->_right = newnode;return true;}5.删除结点
删除结点是所有操作里面比较难的,但是不要怕,我们来分析一下。
删除结点,有四种情况:
1.要删除的结点没有左子树和右子树。
2.要删除的结点没有左子树,有右子树。
3.要删除的结点有左子树,没有右子树。
4.要删除的结点有左子树和右子树。
我们基于这四种情况分析一下。
①要删除的结点没有左子树和右子树
对于这种情况的处理,非常简单。
我们只需要将该结点删除,让它的parent指向空即可。如下图所示。
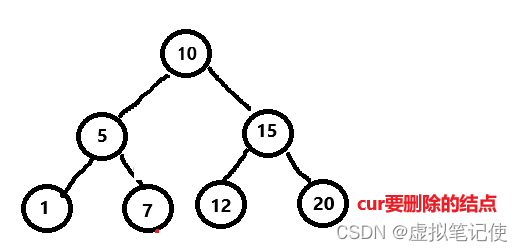
注意!!!在进行删除操作时,要注意一种情况
1.被删除的结点是根结点
②要删除的结点没有左子树,有右子树
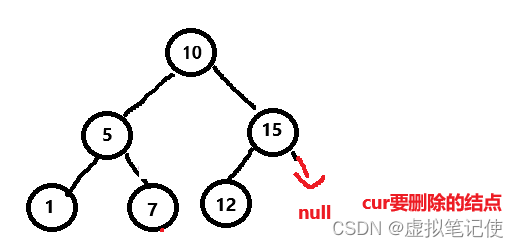
对于这种情况,也还好,直接将要删除结点的parent指向被删除结点的右孩子即可,如下图所示。
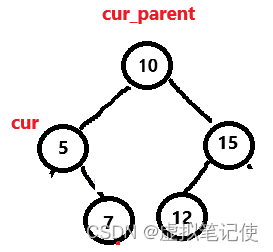
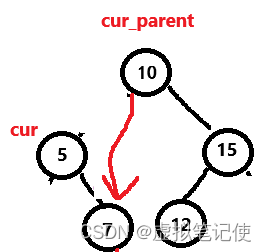
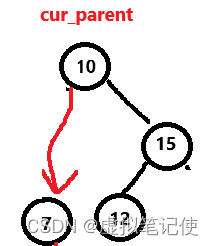
这里也一样,要判断被删除的cur是否时根结点。
③要删除的结点有左子树,没有右子树
这种情况与第二种一样,只不过相反了而已。这里就不多解释。
④ 要删除的结点有左子树和右子树
对于这种情况,我们的解决方法是,去找被删除结点(cur)的右子树的最小结点(即被删除结点的右子树的最左结点)(cur_right_min),后将cur_right_min赋值给cur,这样我们就可以将删除cur转换完删除cur_right_min。如下图所示。
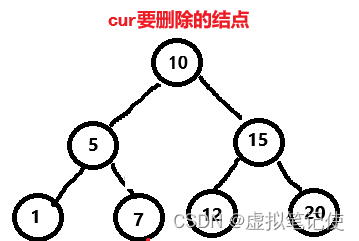
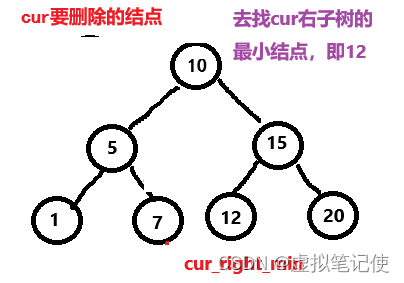
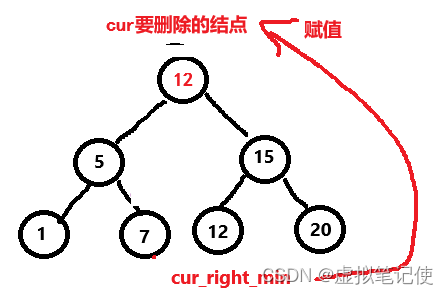
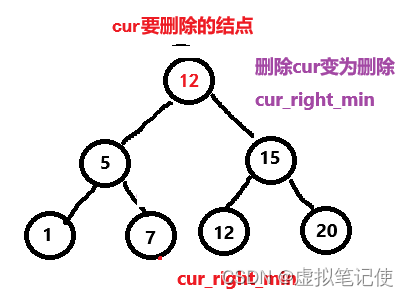
此时删除cur变为删除cur_right_min,那么这个时候删除cur_right_min,也就是第一种情况,或者第二种情况。
注意!!!这里也可能会有特殊情况,例如,下面这种情况。
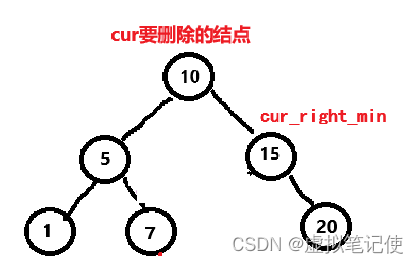
所以最后要进行一个判断。
删除代码如下:
//删除结点bool erase(const K& data){if (_root == nullptr)return false;//先找到要删除的结点Node* cur = _root;Node* cur_parent = nullptr;while (cur != nullptr){//先找到要删除的结点if (data > cur->_key){cur_parent = cur;cur = cur->_right;}else if (data < cur->_key){cur_parent = cur;cur = cur->_left;}else//找到了cur要删除的结点{//判断是那种删除情况if (cur->_left == nullptr && cur->_right == nullptr)//第一种情况{if (cur_parent == nullptr)//如果cur_parent为空,说明删除的cur为_root{_root = nullptr;}else{if (cur_parent->_left == cur)//这里要判断cur时cur_parent左还是右{cur_parent->_left = nullptr;}else{cur_parent->_right = nullptr;}}delete cur;}else if (cur->_left == nullptr && cur->_right != nullptr)//第二种情况{if (cur_parent == nullptr)//如果cur_parent为空,说明删除的cur为_root{_root = cur->_right;}else{if (cur_parent->_left == cur)//这里要判断cur时cur_parent左还是右{cur_parent->_left = cur->_right;}else{cur_parent->_right = cur->_right;}}delete cur;}else if (cur->_left != nullptr && cur->_right == nullptr)//第三种情况{if (cur_parent == nullptr){_root = cur->_left;}else{if (cur_parent->_left == cur)//这里要判断cur时cur_parent左还是右{cur_parent->_left = cur->_left;}else{cur_parent->_right = cur->_left;}delete cur;}}else//第四种情况{Node* cur_right_min = cur->_right;//cur右子树的最小左结点Node* cur_right_min_parent = cur;while (cur_right_min->_left != nullptr)//去找cur右子树的最小左结点{cur_right_min_parent = cur_right_min;cur_right_min = cur_right_min->_left;}cur->_key = cur_right_min->_key;//找到后将其赋值给cur,后转变为删除cur_right_minif (cur_right_min_parent->_key > cur_right_min->_key){cur_right_min_parent->_left = cur_right_min->_right;}else{cur_right_min_parent->_right = cur_right_min->_right;}delete cur_right_min;}return true;}}return false;}6.查找结点
接下来我们来实现查找结点的函数,查找的过程与插入的过程类似。
1.要查找的值比cur大,则cur往右走。
2.要查找的值比cur小,则cur往左走。
3.如果找到,则返回该结点的指针,如果没找到,则返回nullptr
Node* find(const K& data){Node* cur = _root;while (cur != nullptr){if (data > cur->_key){cur = cur->_right;}else if (data < cur->_key){cur = cur->_left;}else{return cur;}}return nullptr;}三. 二叉搜索树的应用
那么二叉搜索树有什么应用了,由名字可以得知,二叉搜索树主要就是用来搜索的。
二叉搜索树的搜索又分为两种模型:K模型,和KV模型。
K模型
什么是K模型,K指的是key的意思,如上面我们实现的二叉搜索树就是一种K模型的搜索树,就是在树的结点中,只存储一个K类型的值,剩下的是两个孩子指针。
template<class K> struct Blog_TreeNode {//成员变量K _key;Blog_TreeNode<K>* _left;Blog_TreeNode<K>* _right;//构造函数Blog_TreeNode(const K& key):_key(key),_left(nullptr),_right(nullptr){} };K模型的主要用途是:查找这个值在不在。
比如说:学校宿舍的门禁系统,在这个门禁系统里面,就有着一棵二叉搜索树,每个树结点K都是一个string类型,存的是该宿舍学生的名字,那么这棵二叉搜索树里面存着你们宿舍里每个学生的姓名,当有一个人想要进入该宿舍的时候,他需要进行刷卡识别,这个时候,程序就会去该宿舍的二叉搜索树中去进行查找,查查这个人的姓名在不在这个二叉搜索树中,如果在就能进入,不在不能进入。
KV模型
什么是KV模型,K是key,V是value的意思,在树结点中,不仅仅有一个K类型,还有一个V类型,意思就是说,每一个key都对应的一个value的意思,即<key,value>键值对,但是注意的是,在KV模型中,我们依然是使用K来进行比较来插入。
比如说,用来存储单词,又或者说统计次数。下面我会来演示一下。
在演示之前,我们需要需要把我们的K模型的二叉搜索树改造成KV模型的二叉搜索树。
改造非常简单,在树结点结构体中增加一个V类型的值,后将所有成员函数涉及到的K,V都小改一下,例如,插入中,要多传一个参数。改造完后如下所示。
template<class K, class V>
struct Blog_TreeNode
{//成员变量K _key;V _val;Blog_TreeNode<K>* _left;Blog_TreeNode<K>* _right;//构造函数Blog_TreeNode(const K& key, const V& val):_key(key),_val(val),_left(nullptr),_right(nullptr){}
};template<class K, class V>
class Blog_Tree
{typedef Blog_TreeNode<K, V> Node;
public://构造函数Blog_Tree():_root(nullptr){}//析构函数~Blog_Tree(){destory(_root);}//插入结点bool insert(const K& key, const V& val){//如果树为空,则直接将新结点给到_rootif (_root == nullptr){_root = new Node(key, val);}//如果树不为空,这开始找空位,将新结点插入Node* cur = _root;Node* cur_parent = nullptr;//这里要提前保留cur的parent,因为后面插入时要用到while (cur != nullptr){if (key > cur->_key)//如果要插入的数据大于cur,则cur往右走{cur_parent = cur;//保留cur的parentcur = cur->_right;}else if (key < cur->_key)//如果要插入的数据小于cur,则cur往左走{cur_parent = cur;//保留cur的parentcur = cur->_left;}else//如果相等,说明树中已有,则不插入,返回失败{return false;}}//找到空位后,将新结点进行插入Node* newnode = new Node(key, val);if (cur_parent->_key > newnode->_key){cur_parent->_left = newnode;}else{cur_parent->_right = newnode;}return true;}//删除结点bool erase(const K& key){if (_root == nullptr){return false;}//先找到要删除的结点Node* cur = _root;Node* cur_parent = nullptr;while (cur != nullptr){//先找到要删除的结点if (key > cur->_key){cur_parent = cur;cur = cur->_right;}else if (key < cur->_key){cur_parent = cur;cur = cur->_left;}else//找到了cur要删除的结点{//判断是那种删除情况if (cur->_left == nullptr && cur->_right == nullptr){if (cur_parent == nullptr)//如果cur_parent为空,说明删除的cur为_root{_root = nullptr;}else{if (cur_parent->_left == cur){cur_parent->_left = nullptr;}else{cur_parent->_right = nullptr;}}delete cur;}else if (cur->_left == nullptr && cur->_right != nullptr){if (cur_parent == nullptr)//如果cur_parent为空,说明删除的cur为_root{_root = cur->_right;}else{if (cur_parent->_left == cur){cur_parent->_left = cur->_right;}else{cur_parent->_right = cur->_right;}}delete cur;}else if (cur->_left != nullptr && cur->_right == nullptr){if (cur_parent == nullptr){_root = cur->_left;}else{if (cur_parent->_left == cur){cur_parent->_left = cur->_left;}else{cur_parent->_right = cur->_left;}delete cur;}}else{Node* cur_right_min = cur->_right;//cur右子树的最小左结点Node* cur_right_min_parent = cur;while (cur_right_min->_left != nullptr)//去找cur右子树的最小左结点{cur_right_min_parent = cur_right_min;cur_right_min = cur_right_min->_left;}cur->_key = cur_right_min->_key;//找到后将其赋值给cur,后转变为删除cur_right_minif (cur_right_min_parent->_key > cur_right_min->_key){cur_right_min_parent->_left = cur_right_min->_right;}else{cur_right_min_parent->_right = cur_right_min->_right;}delete cur_right_min;}return true;}}return false;}//查找Node* find(const K& key){Node* cur = _root;while (cur != nullptr){if (key > cur->_key){cur = cur->_right;}else if (key < cur->_key){cur = cur->_left;}else{return cur;}}return nullptr;}//中序遍历void InOrder(){_InOrder(_root);cout << endl;}private:void _InOrder(Node* root){if (root == nullptr)return;_InOrder(root->_left);cout << root->_key << ":" << root->_val << endl;_InOrder(root->_right);}void destory(Node* root){if (root == nullptr)return;destory(root->_left);destory(root->_right);delete root;}
private:Node* _root;
};存储单词
接下来我们来演示一下。
//字典树
void Blog_test1()
{Blog_Tree<string, string> root;root.insert("树", "tree");root.insert("排序", "sort");root.insert("水", "water");Blog_TreeNode<string, string>* tmp = root.find("排序");if (tmp == nullptr){cout << "无该单词" << endl;}else{cout << tmp->_val << endl;}
}在上面的代码中,我们可以在树中存一个又一个的<中文,英文>键值对,通过这个中文可以找到对应的英文。
统计次数
//统计次数
void Blog_test2()
{string str[] = { "衣服","鞋子","衣服","裤子","衣服","衣服","裤子","鞋子","帽子","帽子","袜子" };Blog_Tree<string, int> root;for (auto& e : str){Blog_TreeNode<string, int>* tmp = root.find(e);//如果树中没有,则插入,并且val给1if (tmp == nullptr){root.insert(e, 1);}else//如果树中有,则val++{tmp->_val++;}}root.InOrder();
}当我们要插入时,先判断在二叉搜索树中在不在,如果不在,则进行插入,并把val次数给1,如果存储,则对val进行++。
四.二叉树搜索树的性能
对于二叉搜索树的性能来说,我们可以看到,它的插入和查找最多进行高度次的查找,例如下面这棵树,如果要进行查找最多查找3次,如果要插入,最多也就4次,所以可以得出二叉搜索树的性能为O(logN),其中N为树中结点的个数。
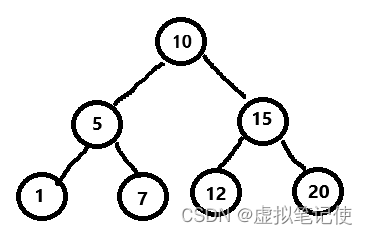
但是我们的树不一定是我们所想的那么理想的,如果要插入的数据完全有序或者接近有序的时候,二叉树会退化成单支树。如下图所示。
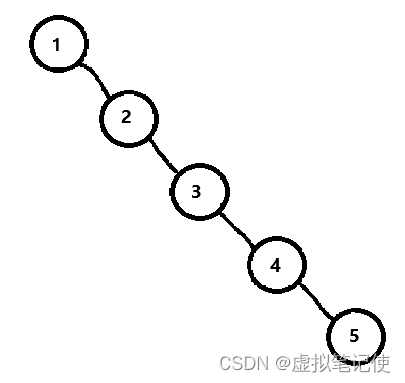
这个时候二叉搜索树的性能就会退化成O(n),这显然不是我们想要的,所以这个时候又衍生出来的AVLTree和红黑树,这两棵树会在后面的博客中进行讲解。
五.所以源代码
所以源代码分为K模型的和KV模型的。
K模型
BinarySearchTree.h
#pragma once
#include<iostream>
using namespace std;template<class K>
struct Blog_TreeNode
{//成员变量K _key;Blog_TreeNode<K>* _left;Blog_TreeNode<K>* _right;//构造函数Blog_TreeNode(const K& key):_key(key),_left(nullptr),_right(nullptr){}};template<class K>
class Blog_Tree
{typedef Blog_TreeNode<K> Node;
public://构造函数Blog_Tree():_root(nullptr){}//析构函数~Blog_Tree(){destory(_root);}//插入结点bool insert(const K& data){//如果树为空,则直接将新结点给到_rootif (_root == nullptr){_root = new Node(data);}//如果树不为空,这开始找空位,将新结点插入Node* cur = _root;Node* cur_parent = nullptr;//这里要提前保留cur的parent,因为后面插入时要用到while (cur != nullptr){if (data > cur->_key)//如果要插入的数据大于cur,则cur往右走{cur_parent = cur;//保留cur的parentcur = cur->_right;}else if (data < cur->_key)//如果要插入的数据小于cur,则cur往左走{cur_parent = cur;//保留cur的parentcur = cur->_left;}else//如果相等,说明树中已有,则不插入,返回失败{return false;}}//找到空位后,将新结点进行插入Node* newnode = new Node(data);if (cur_parent->_key > newnode->_key){cur_parent->_left = newnode;}else{cur_parent->_right = newnode;}return true;}//删除结点bool erase(const K& data){if (_root == nullptr){return false;}//先找到要删除的结点Node* cur = _root;Node* cur_parent = nullptr;while (cur != nullptr){//先找到要删除的结点if (data > cur->_key){cur_parent = cur;cur = cur->_right;}else if (data < cur->_key){cur_parent = cur;cur = cur->_left;}else//找到了cur要删除的结点{//判断是那种删除情况if (cur->_left == nullptr && cur->_right == nullptr){if (cur_parent == nullptr)//如果cur_parent为空,说明删除的cur为_root{_root = nullptr;}else{if (cur_parent->_left == cur){cur_parent->_left = nullptr;}else{cur_parent->_right = nullptr;}}delete cur;}else if (cur->_left == nullptr && cur->_right != nullptr){if (cur_parent == nullptr)//如果cur_parent为空,说明删除的cur为_root{_root = cur->_right;}else{if (cur_parent->_left == cur){cur_parent->_left = cur->_right;}else{cur_parent->_right = cur->_right;}}delete cur;}else if (cur->_left != nullptr && cur->_right == nullptr){if (cur_parent == nullptr){_root = cur->_left;}else{if (cur_parent->_left == cur){cur_parent->_left = cur->_left;}else{cur_parent->_right = cur->_left;}delete cur;}}else{Node* cur_right_min = cur->_right;//cur右子树的最小左结点Node* cur_right_min_parent = cur;while (cur_right_min->_left != nullptr)//去找cur右子树的最小左结点{cur_right_min_parent = cur_right_min;cur_right_min = cur_right_min->_left;}cur->_key = cur_right_min->_key;//找到后将其赋值给cur,后转变为删除cur_right_minif (cur_right_min_parent->_key > cur_right_min->_key){cur_right_min_parent->_left = cur_right_min->_right;}else{cur_right_min_parent->_right = cur_right_min->_right;}delete cur_right_min;}return true;}}return false;}Node* find(const K& data){Node* cur = _root;while (cur != nullptr){if (data > cur->_key){cur = cur->_right;}else if (data < cur->_key){cur = cur->_left;}else{return cur;}}return nullptr;}//中序遍历void InOrder(){_InOrder(_root);cout << endl;}private:void _InOrder(Node* root){if (root == nullptr)return;_InOrder(root->_left);cout << root->_key << " ";_InOrder(root->_right);}void destory(Node* root){if (root == nullptr)return;destory(root->_left);destory(root->_right);delete root;}
private:Node* _root;
};test.c
#include"BinarySearchTree.h"//测试插入和删除
void Blog_test1()
{Blog_Tree<int> root;int arr1[] = { 4, 2, 6, 1, 3, 5, 15, 7, 16,14 };for (auto& e : arr1){root.insert(e);}root.InOrder();for (auto& e : arr1){root.erase(e);root.InOrder();}
}//测试查找
void Blog_test2()
{Blog_Tree<int> root;int arr1[] = { 4, 2, 6, 1, 3, 5, 15, 7, 16,14 };for (auto& e : arr1){root.insert(e);}Blog_TreeNode<int>* tmp = root.find(20);if (tmp != nullptr){cout << tmp->_key << endl;}else{cout << "不存在给值" << endl;}
}int main()
{//Blog_test1();Blog_test2();return 0;
}KV模型
BinarySearchTree.h
template<class K, class V>
struct Blog_TreeNode
{//成员变量K _key;V _val;Blog_TreeNode<K, V>* _left;Blog_TreeNode<K, V>* _right;//构造函数Blog_TreeNode(const K& key, const V& value):_key(key),_val(value),_left(nullptr),_right(nullptr){}};template<class K, class V>
class Blog_Tree
{typedef Blog_TreeNode<K, V> Node;
public://构造函数Blog_Tree():_root(nullptr){}//析构函数~Blog_Tree(){destory(_root);}//插入结点bool insert(const K& key, const V& val){//如果树为空,则直接将新结点给到_rootif (_root == nullptr){_root = new Node(key, val);}//如果树不为空,这开始找空位,将新结点插入Node* cur = _root;Node* cur_parent = nullptr;//这里要提前保留cur的parent,因为后面插入时要用到while (cur != nullptr){if (key > cur->_key)//如果要插入的数据大于cur,则cur往右走{cur_parent = cur;//保留cur的parentcur = cur->_right;}else if (key < cur->_key)//如果要插入的数据小于cur,则cur往左走{cur_parent = cur;//保留cur的parentcur = cur->_left;}else//如果相等,说明树中已有,则不插入,返回失败{return false;}}//找到空位后,将新结点进行插入Node* newnode = new Node(key, val);if (cur_parent->_key > newnode->_key){cur_parent->_left = newnode;}else{cur_parent->_right = newnode;}return true;}//删除结点bool erase(const K& key){if (_root == nullptr){return false;}//先找到要删除的结点Node* cur = _root;Node* cur_parent = nullptr;while (cur != nullptr){//先找到要删除的结点if (key > cur->_key){cur_parent = cur;cur = cur->_right;}else if (key < cur->_key){cur_parent = cur;cur = cur->_left;}else//找到了cur要删除的结点{//判断是那种删除情况if (cur->_left == nullptr && cur->_right == nullptr){if (cur_parent == nullptr)//如果cur_parent为空,说明删除的cur为_root{_root = nullptr;}else{if (cur_parent->_left == cur){cur_parent->_left = nullptr;}else{cur_parent->_right = nullptr;}}delete cur;}else if (cur->_left == nullptr && cur->_right != nullptr){if (cur_parent == nullptr)//如果cur_parent为空,说明删除的cur为_root{_root = cur->_right;}else{if (cur_parent->_left == cur){cur_parent->_left = cur->_right;}else{cur_parent->_right = cur->_right;}}delete cur;}else if (cur->_left != nullptr && cur->_right == nullptr){if (cur_parent == nullptr){_root = cur->_left;}else{if (cur_parent->_left == cur){cur_parent->_left = cur->_left;}else{cur_parent->_right = cur->_left;}delete cur;}}else{Node* cur_right_min = cur->_right;//cur右子树的最小左结点Node* cur_right_min_parent = cur;while (cur_right_min->_left != nullptr)//去找cur右子树的最小左结点{cur_right_min_parent = cur_right_min;cur_right_min = cur_right_min->_left;}cur->_key = cur_right_min->_key;//找到后将其赋值给cur,后转变为删除cur_right_minif (cur_right_min_parent->_key > cur_right_min->_key){cur_right_min_parent->_left = cur_right_min->_right;}else{cur_right_min_parent->_right = cur_right_min->_right;}delete cur_right_min;}return true;}}return false;}//查找Node* find(const K& key){Node* cur = _root;while (cur != nullptr){if (key > cur->_key){cur = cur->_right;}else if (key < cur->_key){cur = cur->_left;}else{return cur;}}return nullptr;}//中序遍历void InOrder(){_InOrder(_root);cout << endl;}private:void _InOrder(Node* root){if (root == nullptr)return;_InOrder(root->_left);cout << root->_key << ":" << root->_val << endl;_InOrder(root->_right);}void destory(Node* root){if (root == nullptr)return;destory(root->_left);destory(root->_right);delete root;}
private:Node* _root;
};test.c
//字典树
void Blog_test1()
{Blog_Tree<string, string> root;root.insert("树", "tree");root.insert("排序", "sort");root.insert("水", "water");Blog_TreeNode<string, string>* tmp = root.find("排序");if (tmp == nullptr){cout << "无该单词" << endl;}else{cout << tmp->_val << endl;}
}//统计次数
void Blog_test2()
{string str[] = { "衣服","鞋子","衣服","裤子","衣服","衣服","裤子","鞋子","帽子","帽子","袜子" };Blog_Tree<string, int> root;for (auto& e : str){Blog_TreeNode<string, int>* tmp = root.find(e);if (tmp == nullptr){root.insert(e, 1);}else{tmp->_val++;}}root.InOrder();
}int main()
{//Blog_test1();Blog_test2();return 0;
}