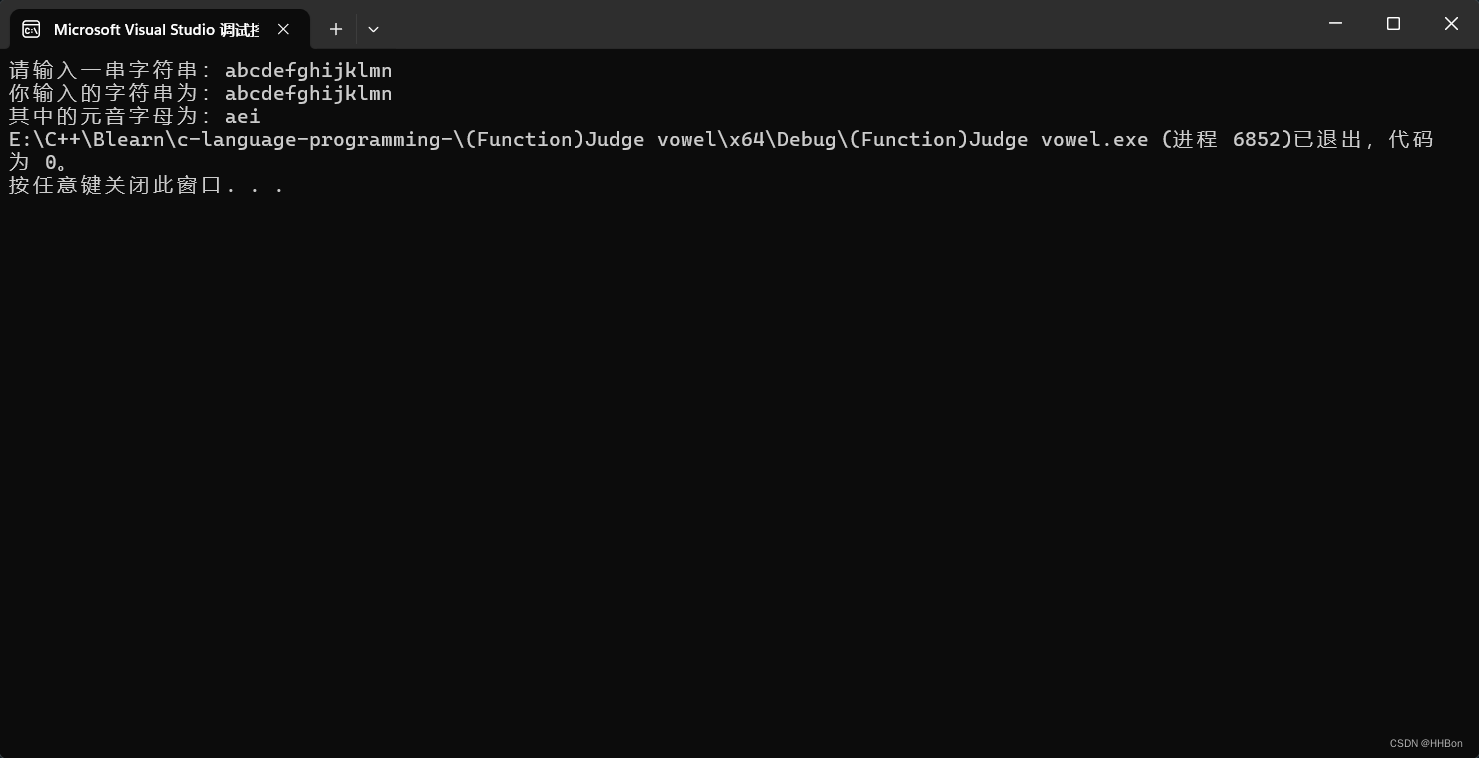
数据库>时序数据库(Time Series Database,TSDB)是一种专门用于存储、处理和查询时间序列数据的数据库系统。以下是关于数据库>时序数据库的详细解释:
定义
数据库>时序数据库是一种优化用于摄取、处理和存储时间戳数据的数据库。时间序列数据是指随时间不断产生的一系列数据,每个数据点都包含用于索引、聚合和采样的时间戳。
特点
- 高性能:数据库>时序数据库可以高效地存储和查询时间序列数据,其查询性能远超过传统的关系型数据库。
- 大规模支持:能够处理大规模时间序列数据,支持数据的水平扩展和负载均衡部署。
- 数据压缩:可以将时间序列数据进行压缩,从而减少存储空间的占用,有效节省成本。
- 精确时间戳:可以精确地记录数据的时间戳,支持高精度时间戳和不同时间分辨率。
- 数据分析:支持多种统计分析和聚合操作,如数据滚动平均、聚合计算、数据插值和预测等。
应用场景
- 物联网设备监测:物联网设备可以生成大量的时间序列数据,如温度、湿度、光照强度等。数据库>时序数据库可以高效地存储和查询这些数据,并提供实时的数据可视化和报警功能。
- 金融交易记录:金融机构需要记录每一笔交易的时间戳、金额、交易类型等信息。数据库>时序数据库可以高效地存储和查询这些交易记录,并提供实时的交易数据分析和预警功能。
- 气象观测数据:气象观测站可以生成大量的气象数据,如温度、湿度、气压等。数据库>时序数据库可以高效地存储和查询这些数据,并提供实时的天气预报和灾害预警功能。
- 制造业生产监控:制造商需要对生产线上的各种传感器数据进行实时监测和分析。数据库>时序数据库可以高效地存储和查询这些数据,并提供实时的生产数据可视化和故障诊断功能。
- 能源管理:能源管理系统需要实时监测和分析各种能源数据,如电力消耗、能源供应、能源价格等。数据库>时序数据库可以高效地存储和查询这些数据,并提供实时的能源数据分析和优化建议功能。
发展趋势
随着物联网、人工智能和设备的普及,时间序列数据在各个领域的应用越来越广泛,数据库>时序数据库的重要性也日益凸显。数据库>时序数据库的用例不断增加,已成为企业中增长最快的数据库类型之一。未来,数据库>时序数据库将继续发展,为更多领域提供更高效、更可靠的数据处理和分析能力。
二,时序数据的优缺点?
优点:
- 高性能:
- 大规模支持:
- 数据压缩:
- 精确时间戳:
- 实时数据分析和预测:
- 易于使用:
缺点:
- 场景受限:
- SQL能力受限:
- 学习成本高:
- 硬件资源需求高:
- 成本较高:
综上所述,数据库>时序数据库在处理时间序列数据方面具有独特的优势,但也存在一些缺点。企业在选择是否使用数据库>时序数据库时需要根据自身的业务需求、技术能力和经济状况进行综合考虑。
数据库>时序数据库和普通数据库在多个方面存在显著的区别,以下是对这些区别的详细解释:
- 设计目的和适用场景:
- 数据结构:
- 查询性能:
- 扩展性和容错性:
- 数据安全性:
- 易用性和灵活性:
综上所述,数据库>时序数据库和普通数据库在设计目的、数据结构、查询性能、扩展性和容错性、数据安全性以及易用性和灵活性等方面存在显著的区别。选择哪种类型的数据库取决于具体的应用场景和需求。
数据库>时序数据库的架构通常是为了高效地处理时间序列数据而设计的。以下是一个典型的数据库>时序数据库架构的清晰概述,结合了参考文章中的信息:
1. 数据存储
- 持久化存储介质:数据库>时序数据库将时间序列数据存储在持久化存储介质中,如磁盘或固态硬盘(SSD)。
- 列式存储结构:数据通常以列式存储结构进行存储,即将每个时间序列数据的不同字段存储在不同的列中。这种结构可以提高查询性能,因为查询通常只需要读取特定的字段。
2. 数据索引
- 时间戳索引:数据库>时序数据库使用索引来加速数据查询。时间戳通常是主要的索引字段,以支持按时间范围查询数据。
- 辅助索引:除了时间戳外,还可以使用其他字段(如传感器ID、设备ID等)作为辅助索引,以进一步优化查询性能。
3. 集群与扩展性
- 分布式架构:为了支持大规模数据和高可用性,数据库>时序数据库通常采用分布式架构。这意味着数据可以跨多个物理节点进行存储和查询。
- 水平扩展:数据库>时序数据库支持水平扩展,即可以通过添加更多的节点来增加存储容量和计算能力。这有助于应对不断增长的数据量和查询需求。
4. 逻辑单元
- 数据节点(dnode):在分布式架构中,数据节点是执行代码在物理节点上的一个运行实例。每个数据节点可能包含多个虚拟节点(vnode),用于支持数据分片、负载均衡和数据隔离。
- 虚拟节点(vnode):虚拟节点是数据节点的逻辑分区,用于更好地支持数据分片、负载均衡和数据隔离。每个虚拟节点都可以处理一部分数据,并通过集群中的其他虚拟节点进行协作。
5. 租户隔离
- 多租户支持:一些数据库>时序数据库支持多个隔离的租户特性(又名命名空间)。每个租户可以通过特定的标识符(如accountID或accountID:projectID)进行标识,以确保数据的安全性和隔离性。
6. 架构示例(以VictoriaMetrics为例)
- 整体架构:VictoriaMetrics的集群主要由vmstorage、vminsert、vmselect等三部分组成。
- vmstorage:负责提供数据存储服务,采用shared-nothing架构,节点之间无感知、无需通信、不共享数据。
- vminsert:是数据存储vmstorage的代理,使用一致性hash算法进行写入分片。
- vmselect:负责数据查询,根据输入的查询条件从vmstorage中查询数据。
7. 安全性与可靠性
8. 易用性与灵活性
综上所述,数据库>时序数据库的架构是为了高效地处理时间序列数据而设计的,具有数据存储、数据索引、集群与扩展性、逻辑单元、租户隔离等关键组成部分。同时,数据库>时序数据库也注重数据的安全性、可靠性和易用性。
在C#中,对数据库>时序数据库(如InfluxDB、Prometheus等)进行读写和删除操作通常需要使用该数据库>时序数据库提供的客户端库或API。以下是一些一般性的步骤和示例,但请注意,具体的实现细节将取决于您使用的数据库>时序数据库和相应的客户端库。
1. 添加客户端库引用
首先,您需要在C#项目中添加对数据库>时序数据库客户端库的引用。这通常可以通过NuGet包管理器来完成。例如,如果您正在使用InfluxDB,您可以搜索并安装InfluxDB.Client库。
2. 建立连接
使用客户端库提供的API来建立与数据库>时序数据库的连接。这通常涉及设置连接字符串、认证凭据等。
3. 写入数据
写入数据通常涉及创建一个或多个数据点(时间序列数据的一个记录),并将其发送到数据库>时序数据库。以下是一个使用InfluxDB客户端库的示例:
csharp复制代码
using InfluxDB.Client; | |
using InfluxDB.Client.Api.Domain; | |
using InfluxDB.Client.Writes; | |
// 创建InfluxDB客户端 | |
var influxDBClient = InfluxDBClientFactory.Create("http://localhost:8086", "my-token"); | |
// 创建一个写入API的实例 | |
var writeApi = influxDBClient.GetWriteApi(); | |
// 创建一个数据点(Point) | |
var point = PointData.Measurement("h2o_feet") | |
.Tag("location", "coyote_creek") | |
.AddField("level description", "below 3 feet") | |
.Time(DateTimeOffset.UtcNow, WritePrecision.Ns) | |
.Build(); | |
// 将数据点写入数据库 | |
writeApi.WritePoint("mydb", "autogen", point); | |
// 确保所有请求都已发送 | |
writeApi.Flush(); | |
// 关闭连接 | |
influxDBClient.Dispose(); |
4. 读取数据
读取数据通常涉及发送查询请求到数据库>时序数据库,并处理返回的结果。以下是一个使用InfluxDB查询API的示例:
csharp复制代码
using InfluxDB.Client; | |
using InfluxDB.Client.Api.Service; | |
using InfluxDB.Client.Core.Flux.Domain; | |
// 创建InfluxDB客户端 | |
var influxDBClient = InfluxDBClientFactory.Create("http://localhost:8086", "my-token"); | |
// 创建一个查询API的实例 | |
var queryApi = influxDBClient.GetQueryApi(); | |
// 发送Flux查询 | |
var fluxQuery = @"from(bucket: ""mydb"") | |
|> range(start: -1h) | |
|> filter(fn: (r) => r._measurement == ""h2o_feet"" and r._field == ""level description"") | |
|> limit(n:10)"; | |
var tables = queryApi.Query(fluxQuery, "my-org"); | |
// 处理查询结果 | |
foreach (var table in tables) | |
{ | |
foreach (var record in table.GetRecords()) | |
{ | |
// 处理每条记录 | |
Console.WriteLine(record.GetValueByKey("_time")); | |
Console.WriteLine(record.GetValueByKey("_value")); | |
} | |
} | |
// 关闭连接 | |
influxDBClient.Dispose(); |
5. 删除数据
删除数据通常涉及发送删除请求到数据库>时序数据库。不同的数据库>时序数据库有不同的删除策略和方法。以下是一个假设性的示例,因为具体的删除方法将取决于您使用的数据库>时序数据库:
csharp复制代码
// 假设存在一个删除API或方法 | |
// influxDBClient.DeleteData(...); // 具体的删除方法取决于客户端库和数据库>时序数据库 | |
// 注意:在实际操作中,您需要查阅数据库>时序数据库的文档来了解如何删除数据 |