本文字数:7728;估计阅读时间:20 分钟
作者:Mark Needham
审校:庄晓东(魏庄)
本文在公众号【ClickHouseInc】首发
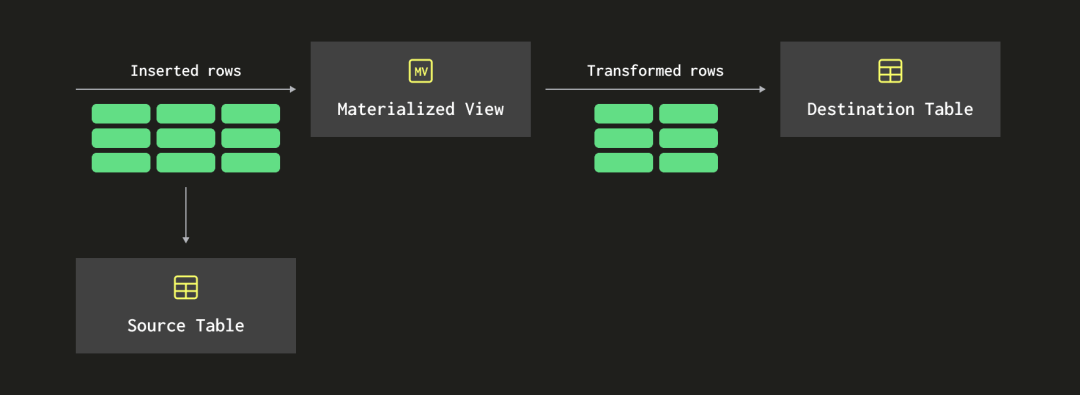
在 ClickHouse 中,物化视图【https://clickhouse.com/docs/en/guides/developer/cascading-materialized-views】是在源表接收到一批行时触发的查询。它们将在这些行上操作,可能在写入目标表之前转换数据。下面的图表展示了这个工作原理的概览:
最近几周,我一直在学习聚合状态(aggregation states)。我创建了一个小型演示,其中包括两个物化视图,它们从同一个 Kafka 表引擎中读取数据。一个用于存储原始事件数据,另一个用于存储聚合状态数据。
当我给Tom演示时Tom【https://www.linkedin.com/in/schreibertom1/】建议我将两个物化视图进行链接,而不是直接从Kafka引擎表中读取数据。他的想法如下图所示:
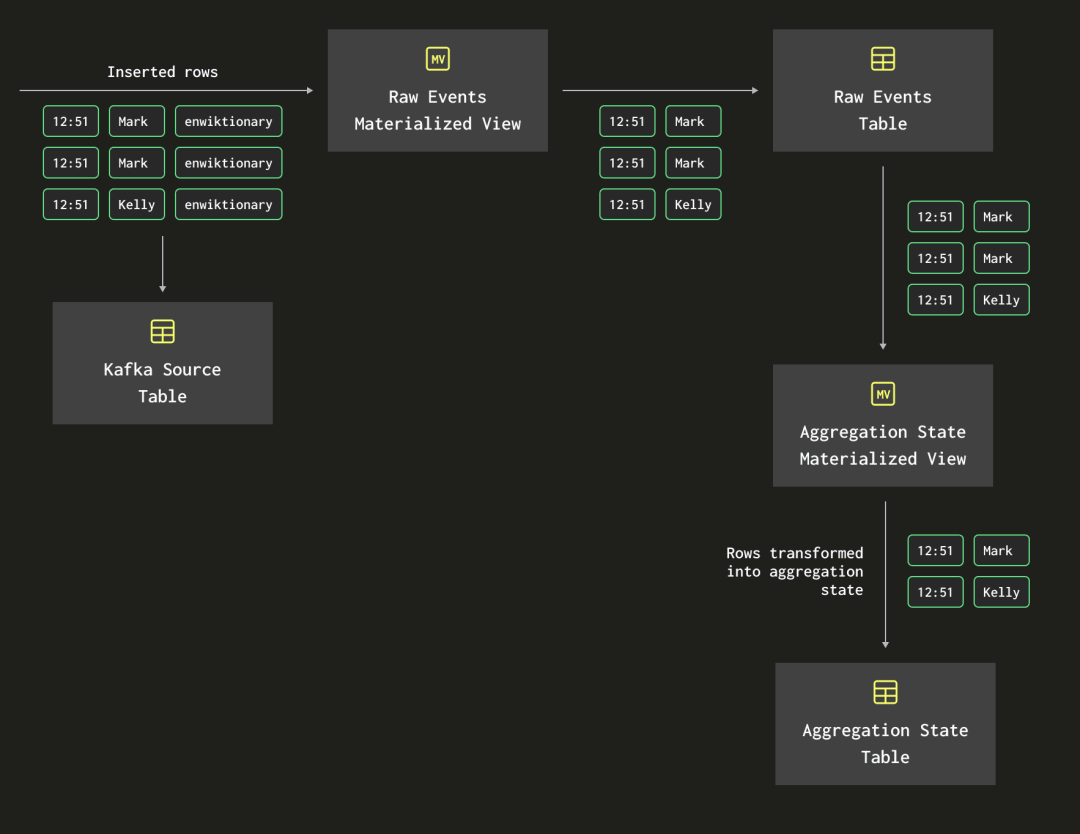
换句话说,我应该让聚合状态的物化视图不直接从 Kafka 引擎表中读取数据,而是应该从已经从 Kafka 中提取出的原始事件中读取。
在接下来的博客文章中,我们将通过一个实际示例演示如何链式使用物化视图。我们将使用“维基最近更改”源,该源提供了表示对各种维基媒体属性进行的更改的事件流。这些数据以服务器端事件的形式提供,下面将展示一个示例消息的数据属性:
{"$schema": "/mediawiki/recentchange/1.0.0","meta": {"uri": "https://en.wiktionary.org/wiki/MP3%E6%92%AD%E6%94%BE%E5%99%A8","request_id": "ccbbbe2c-6e1b-4bb7-99cb-317b64cbd5dc","id": "41c73232-5922-4484-82f3-34d45f22ee7a","dt": "2024-03-26T09:13:09Z","domain": "en.wiktionary.org","stream": "mediawiki.recentchange","topic": "eqiad.mediawiki.recentchange","partition": 0,"offset": 4974797626},"id": 117636935,"type": "edit","namespace": 0,"title": "MP3播放器","title_url": "https://en.wiktionary.org/wiki/MP3%E6%92%AD%E6%94%BE%E5%99%A8","comment": "clean up some labels; add missing space after *; {{zh-noun}} -> {{head|zh|noun}}, {{zh-hanzi}} -> {{head|zh|hanzi}} per [[WT:RFDO#All templates in Category:Chinese headword-line templates except Template:zh-noun]], [[WT:RFDO#Template:zh-noun]]; fix some lang codes (manually assisted)","timestamp": 1711444389,"user": "WingerBot","bot": true,"notify_url": "https://en.wiktionary.org/w/index.php?diff=78597416&oldid=50133194&rcid=117636935","minor": true,"patrolled": true,"length": {"old": 229,"new": 234},"revision": {"old": 50133194,"new": 78597416},"server_url": "https://en.wiktionary.org","server_name": "en.wiktionary.org","server_script_path": "/w","wiki": "enwiktionary","parsedcomment": "clean up some labels; add missing space after *; {{zh-noun}} -> {{head|zh|noun}}, {{zh-hanzi}} -> {{head|zh|hanzi}} per <a href=\"/wiki/Wiktionary:RFDO#All_templates_in_Category:Chinese_headword-line_templates_except_Template:zh-noun\" class=\"mw-redirect\" title=\"Wiktionary:RFDO\">WT:RFDO#All templates in Category:Chinese headword-line templates except Template:zh-noun</a>, <a href=\"/wiki/Wiktionary:RFDO#Template:zh-noun\" class=\"mw-redirect\" title=\"Wiktionary:RFDO\">WT:RFDO#Template:zh-noun</a>; fix some lang codes (manually assisted)"
}假设我们正在建立一个仪表盘来追踪所做的更改。我们对单个更改不感兴趣,而是想要以分钟为单位追踪正在进行更改的用户数、正在更改的页面数以及总更改量。
我们将从创建并使用 wiki 数据库开始:
CREATE DATABASE wiki;USE wiki;创建 Kafka 表引擎
接下来,让我们创建一个名为 wikiQueue 的表,该表将从 Kafka 中消费消息。Kafka 代理运行在本地的端口 9092 上,我们的主题称为 wiki_events。
请注意,如果您正在使用 ClickHouse Cloud,您需要使用 ClickPipes 来处理从 Kafka 中摄取数据。
CREATE TABLE wikiQueue(id UInt32,type String,title String,title_url String,comment String,timestamp UInt64,user String,bot Boolean,server_url String,server_name String,wiki String,meta Tuple(uri String, id String, stream String, topic String, domain String)
)
ENGINE = Kafka('localhost:9092', 'wiki_events', 'consumer-group-wiki', 'JSONEachRow'
);rawEvents 表存储了 dateTime、title_url、topic 和 user。
CREATE TABLE rawEvents (dateTime DateTime64(3, 'UTC'),title_url String,topic String,user String
)
ENGINE = MergeTree
ORDER BY dateTime;接下来,我们将编写以下物化视图来将数据写入 rawEvents:
CREATE MATERIALIZED VIEW rawEvents_mv TO rawEvents AS
SELECT toDateTime(timestamp) AS dateTime,title_url, tupleElement(meta, 'topic') AS topic, user
FROM wikiQueue
WHERE title_url <> '';我们使用 toDateTime 函数将从 epoch 秒时间戳转换为 DateTime 对象。我们还使用 tupleElement 函数从 meta 对象中提取 topic 属性。
存储聚合状态
接下来,让我们创建一个表来存储聚合状态,以启用增量聚合。聚合状态存储在具有 AggregateFunction(<aggregationType>, <dataType>) 类型的列中。
为了保持 String 值的唯一计数,我们需要跟踪唯一用户和唯一页面,我们将使用 AggregateFunction(uniq, String) 类型。为了保持运行总数,我们需要对总更新使用 AggregateFunction(sum, UInt32) 类型。UInt32 类型给了我们最大值 4294967295,这远远超过了我们在一分钟内收到的更新数量。
我们将称这个表为 byMinute,其定义如下:
CREATE TABLE byMinute
(dateTime DateTime64(3, 'UTC') NOT NULL,users AggregateFunction(uniq, String),pages AggregateFunction(uniq, String),updates AggregateFunction(sum, UInt32)
)
ENGINE = AggregatingMergeTree()
ORDER BY dateTime;用于填充该表的物化视图将从 rawEvents 中读取数据,并使用 -State 组合器来提取中间状态。我们将使用 uniqState 函数来处理用户和页面,并使用 sumState 处理更新。
CREATE MATERIALIZED VIEW byMinute_mv TO byMinute AS
SELECT toStartOfMinute(dateTime) AS dateTime,uniqState(user) as users,uniqState(title_url) as pages,sumState(toUInt32(1)) AS updates
FROM rawEvents
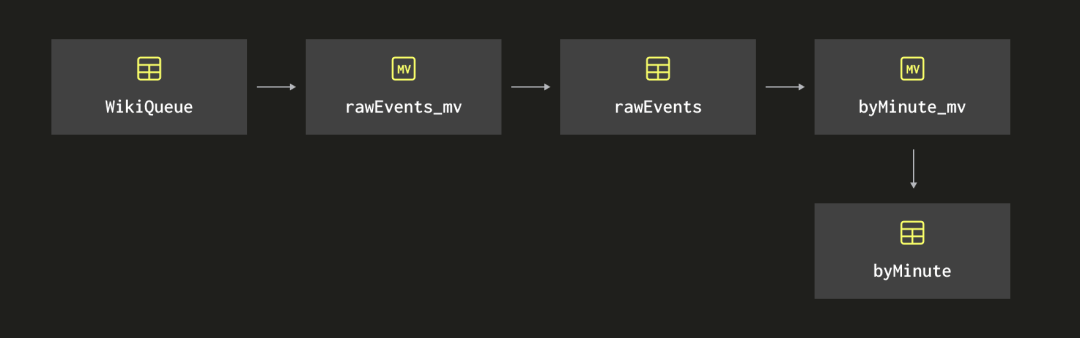
GROUP BY dateTime;下面的图展示了我们迄今为止创建的物化视图和表的链条:
由于没有数据流入 Kafka,所以这个表中没有任何数据。让我们通过执行以下命令来解决这个问题。
curl -N https://stream.wikimedia.org/v2/stream/recentchange |
awk '/^data: /{gsub(/^data: /, ""); print}' |
jq -cr --arg sep ø '[.meta.id, tostring] | join($sep)' |
kcat -P -b localhost:9092 -t wiki_events -Kø这个命令从最近更改源中提取 data 属性,使用 jq 构造一个 key:value,然后通过 kcat 将其传输到 Kafka。
如果我们让这个命令运行一段时间,然后我们可以编写一个查询来查看正在进行多少更改:
SELECTdateTime AS dateTime,uniqMerge(users) AS users,uniqMerge(pages) AS pages,sumMerge(updates) AS updates
FROM byMinute
GROUP BY dateTime
ORDER BY dateTime DESC
LIMIT 10; ┌────────────────dateTime─┬─users─┬─pages─┬─updates─┐1. │ 2024-03-26 15:53:00.000 │ 248 │ 755 │ 1002 │2. │ 2024-03-26 15:52:00.000 │ 429 │ 1481 │ 2164 │3. │ 2024-03-26 15:51:00.000 │ 406 │ 1417 │ 2159 │4. │ 2024-03-26 15:50:00.000 │ 392 │ 1240 │ 1843 │5. │ 2024-03-26 15:49:00.000 │ 418 │ 1346 │ 1910 │6. │ 2024-03-26 15:48:00.000 │ 422 │ 1388 │ 1867 │7. │ 2024-03-26 15:47:00.000 │ 423 │ 1449 │ 2015 │8. │ 2024-03-26 15:46:00.000 │ 409 │ 1420 │ 1933 │9. │ 2024-03-26 15:45:00.000 │ 402 │ 1348 │ 1824 │
10. │ 2024-03-26 15:44:00.000 │ 432 │ 1642 │ 2142 │└─────────────────────────┴───────┴───────┴─────────┘一切看起来都运行得很好。
向链条中添加另一个物化视图
现在,在运行了一段时间后,我们决定将数据分组并分块为 10 分钟的桶,而不仅仅是 1 分钟的。我们可以通过针对 byMinute 表编写以下查询来实现这一点:
SELECTtoStartOfTenMinutes(dateTime) AS dateTime,uniqMerge(users) AS users,uniqMerge(pages) AS pages,sumMerge(updates) AS updates
FROM byMinute
GROUP BY dateTime
ORDER BY dateTime DESC
LIMIT 10;这将返回类似以下的结果,其中 dateTime 列的值现在以 10 分钟的增量递增。
┌────────────dateTime─┬─users─┬─pages─┬─updates─┐1. │ 2024-03-26 15:50:00 │ 977 │ 4432 │ 7168 │2. │ 2024-03-26 15:40:00 │ 1970 │ 12372 │ 20555 │3. │ 2024-03-26 15:30:00 │ 1998 │ 11673 │ 20043 │4. │ 2024-03-26 15:20:00 │ 1981 │ 12051 │ 20026 │5. │ 2024-03-26 15:10:00 │ 1996 │ 11793 │ 19392 │6. │ 2024-03-26 15:00:00 │ 2092 │ 12778 │ 20649 │7. │ 2024-03-26 14:50:00 │ 2062 │ 12893 │ 20465 │8. │ 2024-03-26 14:40:00 │ 2028 │ 12798 │ 20873 │9. │ 2024-03-26 14:30:00 │ 2020 │ 12169 │ 20364 │
10. │ 2024-03-26 14:20:00 │ 2077 │ 11929 │ 19797 │└─────────────────────┴───────┴───────┴─────────┘在处理我们的小数据量时,这是有效的,但是当处理更大的数据时,我们可能需要另一个表,将数据按 10 分钟的间隔分桶存储。让我们创建那个表:
CREATE TABLE byTenMinutes
(dateTime DateTime64(3, 'UTC') NOT NULL,users AggregateFunction(uniq, String),pages AggregateFunction(uniq, String),updates AggregateFunction(sum, UInt32)
)
ENGINE = AggregatingMergeTree()
ORDER BY dateTime;接下来,让我们创建一个物化视图来填充那个表。物化视图将使用类似于上面用于计算 10 分钟桶的查询来查询 byMinute 表。唯一的变化是,我们不再使用 -Merge 组合器,而是需要使用 -MergeState 组合器,以从聚合 byMinute 数据而不是底层结果返回聚合状态。
理论上,我们将节省一些计算时间,因为 byMinute MV 已经将数据聚合在一分钟的桶中。现在,我们不再将原始按秒的数据从头开始聚合到 10 分钟的桶中,而是利用了一分钟的桶。
物化视图如下所示:
CREATE MATERIALIZED VIEW byTenMinutes_mv TO byTenMinutes AS
SELECT toStartOfMinute(dateTime) AS dateTime,uniqMergeState(users) as users,uniqMergeState(pages) as pages,sumMergeState(updates) AS updates
FROM byMinute
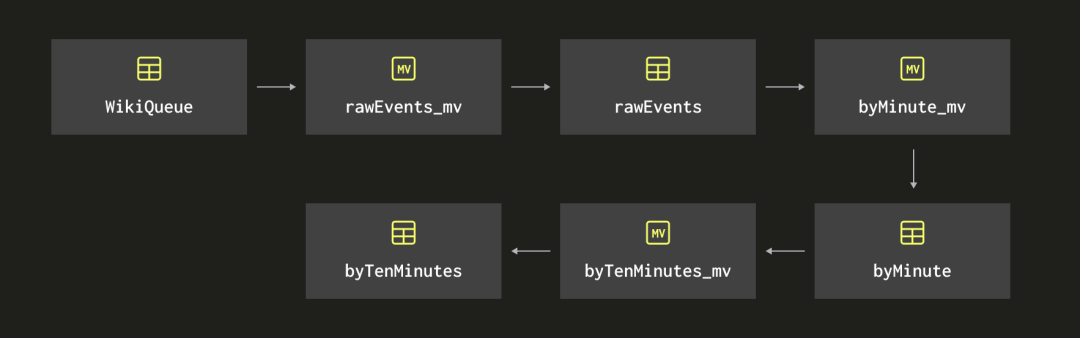
GROUP BY dateTime;下面的图展示了我们现在创建的物化视图的链式结构:
如果我们查询 byTenMinutes 表,它将没有任何数据,并且一旦开始填充,它将只捕获到添加到 byMinute 表中的新数据。但并不是一无所获,我们仍然可以编写一个查询来填补旧数据:
INSERT INTO byTenMinutes
SELECT toStartOfTenMinutes(dateTime),uniqMergeState(users) AS users, uniqMergeState(pages) AS pages,sumMergeState(updates) AS updates
FROM byMinute
GROUP BY dateTime;然后,我们可以对 byTenMinutes 编写以下查询,以按 10 分钟的间隔分组返回数据:
SELECTdateTime AS dateTime,uniqMerge(users) AS users,uniqMerge(pages) AS pages,sumMerge(updates) AS updates
FROM byTenMinutes
GROUP BY dateTime
ORDER BY dateTime DESC
LIMIT 10;我们将得到与查询 byMinute 表时相同的结果:
┌────────────dateTime─┬─users─┬─pages─┬─updates─┐1. │ 2024-03-26 15:50:00 │ 977 │ 4432 │ 7168 │2. │ 2024-03-26 15:40:00 │ 1970 │ 12372 │ 20555 │3. │ 2024-03-26 15:30:00 │ 1998 │ 11673 │ 20043 │4. │ 2024-03-26 15:20:00 │ 1981 │ 12051 │ 20026 │5. │ 2024-03-26 15:10:00 │ 1996 │ 11793 │ 19392 │6. │ 2024-03-26 15:00:00 │ 2092 │ 12778 │ 20649 │7. │ 2024-03-26 14:50:00 │ 2062 │ 12893 │ 20465 │8. │ 2024-03-26 14:40:00 │ 2028 │ 12798 │ 20873 │9. │ 2024-03-26 14:30:00 │ 2020 │ 12169 │ 20364 │
10. │ 2024-03-26 14:20:00 │ 2077 │ 11929 │ 19797 │└─────────────────────┴───────┴───────┴─────────┘征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com

联系我们
手机号:13910395701
邮箱:Tracy.Wang@clickhouse.com
满足您所有的在线分析列式数据库管理需求