小伙伴们大家好,本片文章将会讲解 哈希函数与哈希 之 闭散列的线性探测解决哈希冲突 的相关内容。
如果看到最后您觉得这篇文章写得不错,有所收获,麻烦点赞👍、收藏🌟、留下评论📝。您的支持是我最大的动力,让我们一起努力,共同成长!
文章目录
1. 哈希概念
⌛哈希函数的概念⏳
哈希函数是一种将输入数据(例如字符串、数字等)转换为固定长度的输出数据的函数。这个输出通常称为哈希值或哈希码。
哈希函数的特点是,对于相同的输入,它总是生成相同的输出,而且通常无法根据输出反推出输入。这种特性使得哈希函数在密码学、数据验证和数据检索等领域中非常有用。
⌛哈希表的概念⏳
哈希表是一种数据结构,它利用哈希函数来快速定位存储和检索数据。哈希表由一个数组组成,每个数组元素称为桶( b u c k e t bucket bucket)或槽( s l o t slot slot)。当需要存储数据时,哈希函数会将数据的键( k e y key key)映射到数组中的一个位置,这个位置称为哈希值。数据被存储在这个位置对应的桶中。当需要检索数据时,哈希函数会根据键计算出哈希值,并在数组中定位到对应的桶,然后从这个桶中检索数据。
哈希表的关键之处在于,哈希函数的设计要尽可能地使得不同的键映射到不同的桶,以减少哈希冲突(多个键映射到同一个桶的情况)。但即使哈希函数设计得非常好,也无法完全避免冲突。因此,哈希表通常会使用一些方法来处理冲突,例如链表、开放寻址等。
链表法是将哈希表的每个桶设置为一个链表,当发生冲突时,将新数据添加到对应桶的链表中。开放寻址法则是在发生冲突时,顺序地寻找下一个空桶来存储数据。
哈希表的优点是能够以常量时间复杂度进行数据的插入、删除和查找操作,使得它在处理大量数据时具有高效性。常见的应用包括哈希集合、哈希映射等。
⌛哈希函数与哈希表的例子⏳
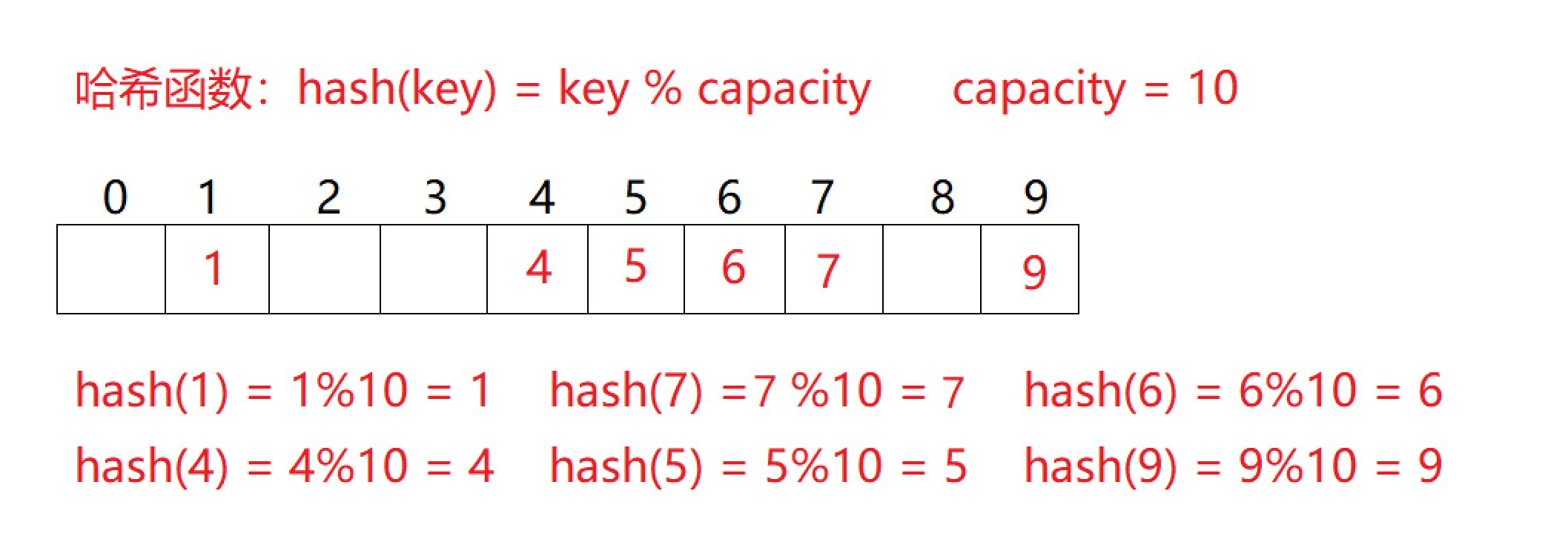
- 上图哈希函数是 h a s h ( k e y ) = k e y hash(key) = key hash(key)=key % c a p a c i t y capacity capacity;
- 通过哈希函数构造出的表称为哈希表。
2. 哈希冲突
对于两个数据元素的关键字 k i k_i ki和 k j k_j kj( i ! = j i != j i!=j),有 k i k_i ki != k j k_j kj,但有:Hash( k i k_i ki) == Hash( k j k_j kj),即:不同关键字通过相同哈希哈数计算出相同的哈希地址,该种现象称为哈希冲突或哈希碰撞。
⌛哈希冲突的例子⏳
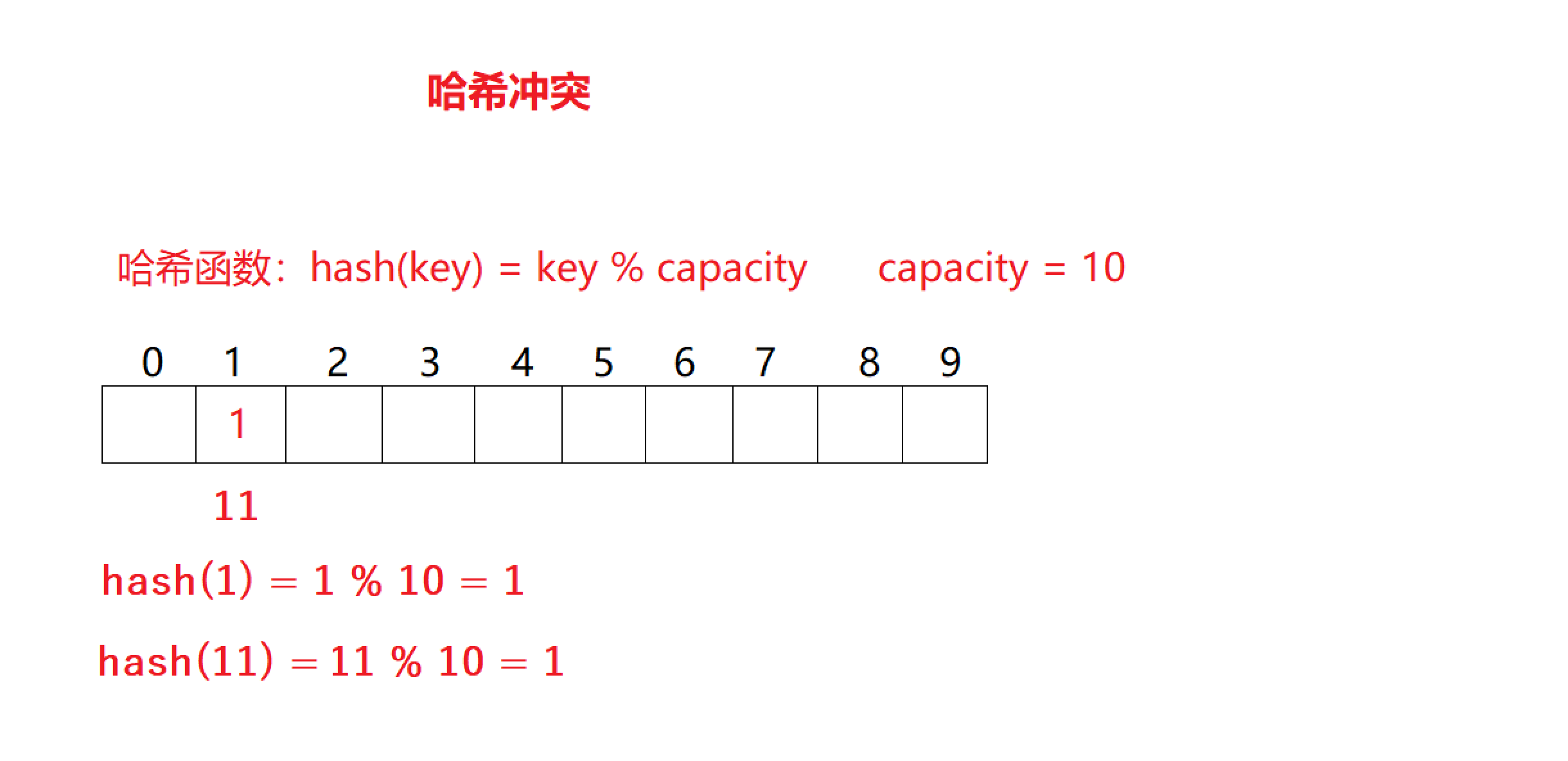
- 对于两个不同的输入数据 1 1 1 和 11 11 11,通过相同的哈希函数: h a s h ( k e y ) = k e y hash(key) = key hash(key)=key % c a p a c i t y capacity capacity;
- 计算出来的结果是相同的,这就是哈希冲突。
3. 解决哈希冲突的方法
解决哈希冲突 的两种常见的方法是:闭散列 和 开散列
⌛闭散列的线性探测法⏳
闭散列:也叫开放定址法,当发生哈希冲突时,如果哈希表未被装满,说明在哈希表中必然还有空位置,那么可以把 k e y key key 存放到冲突位置中的“下一个” 空位置中去。那如何寻找下一个空位置呢?
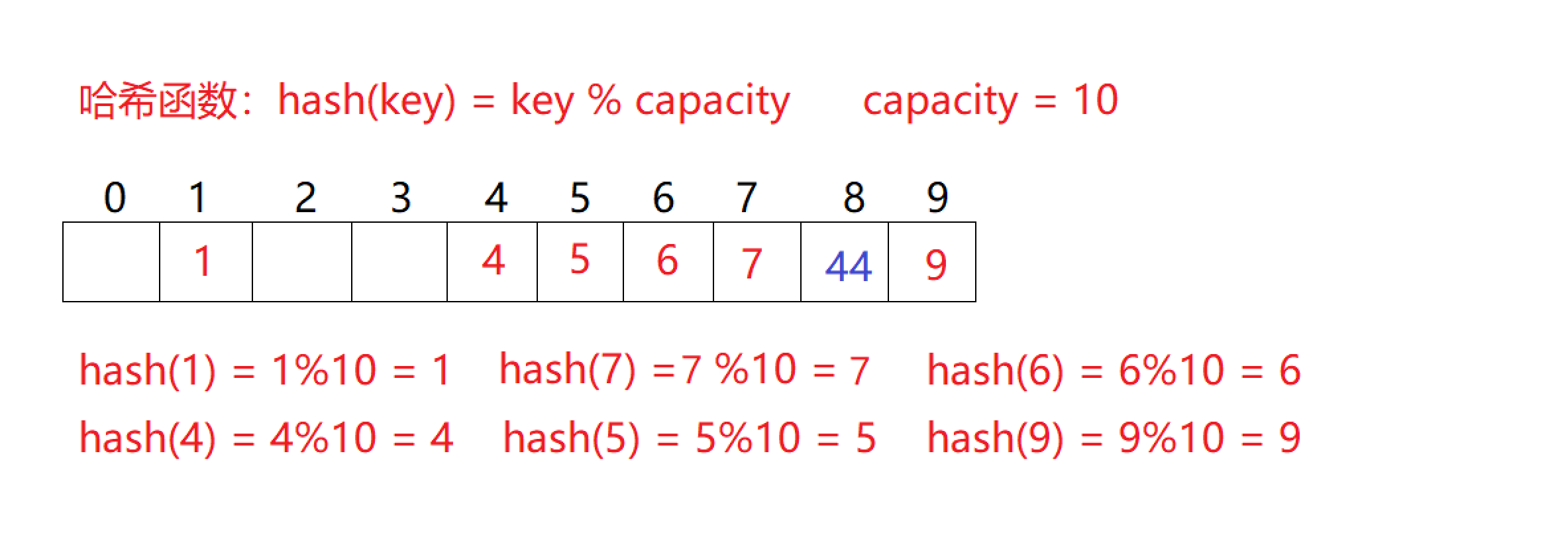
- 线性探测
比如下图中的场景,现在需要插入元素 44 44 44,先通过哈希函数计算哈希地址, h a s h A d d r hashAddr hashAddr为 4 4 4,因此 44 44 44 理论上应该插在该位置,但是该位置已经放了值为 4 4 4 的元素,即发生哈希冲突。
线性探测:从发生冲突的位置开始,依次向后探测,直到寻找到下一个空位置为止。- 插入
- 通过哈希函数获取待插入元素在哈希表中的位置
- 如果该位置中没有元素则直接插入新元素,如果该位置中有元素发生哈希冲突,使用线性探测找到下一个空位置,插入新元素
- 删除
采用闭散列处理哈希冲突时,不能随便物理删除哈希表中已有的元素,若直接删除元素会影响其他元素的搜索。比如删除元素 4 4 4,如果直接删除掉, 44 44 44 查找起来可能会受影响。因此线性探测采用标记的伪删除法来删除一个元素。
- 插入
3.1 线性探测的代码实现
⌛1、枚举类型定义状态⏳
在实现删除的思路的时候思路如下:
- 根据哈希函数算出对应的哈希值;
- 以此位置为起始点,开始向后寻找;
- 如果找到与传入 k e y key key 值相等的值则查找成功;
- 如果查找到空还未找到,则查找失败。
但是这样删除可能会出现以下错误:
- 当出现哈希冲突的时候,我们尝试删除对应哈希值位置上的元素,没问题,但是删除之后再删除另一个元素时,哈希值会映射到此位置,但是此位置为空,会引发错误。
- 插入有哈希冲突的两个值( v 1 和 v 2 v1和v2 v1和v2),插入第一个值的时候没问题,插入的位置为 l o c 1 loc1 loc1,假设此位置后面有一个元素 x x x ,在插入第二个元素的时候,会沿着顺序查找到为空的位置 l o c 2 loc2 loc2 。插入完成。
- 如果此时我们要删除 x x x,那么此位置就变为空;
- 接着删除 v 1 v1 v1,没问题;
- 删除 v 2 v2 v2 的时候,就会出现问题。
因此我们需要有一个标记来记录每个节点的状态:
代码:
enum Status
{EXIST,DELETE,EMPTY
};template<class K, class V>
struct HashData
{Status _status = EMPTY;pair<K, V> _kv;
};
⌛2、插入元素(Insert)⏳
插入元素思路:
- 根据哈希函数计算插入的位置;
- 如果此位置的状态不为存在,直接插入;
- 如果此位置的状态为存在,向后查找,找到第一个状态不等于存在(空或者删除)的位置,进行插入。
Insert代码(version 1):
bool Insert(const pair<K, V>& kv)
{// 哈希函数计算位置size_t hashi = kv.first % _table.size();// 状态为存在就加加while (_table[hashi]._status == EXIST){++hashi;hashi %= _table.size();}// 出循环说明找到状态不为存在的位置,进行插入_table[hashi]._kv = kv;_table[hashi]._status = EXIST;++_n;return true;
}
⌛2.1、负载因子(load_factor)⏳
我们可以思考一下什么时候进行扩容呢?
首先看一下负载因子的定义:

- 负载因子: l o a d f a c t o r = n ÷ t a b l e . s i z e ( ) loadfactor = n ÷ table.size() loadfactor=n÷table.size()
我们这边控制:当负载因子超过 0.7 0.7 0.7 的时候进行扩容,扩容思路如下:
- 新定义一个
HashTable的对象newht,开的空间大小为两倍的原始大小( n e w s i z e = 2 ∗ t a b l e . s i z e ( ) newsize = 2 * table.size() newsize=2∗table.size()); - 遍历
原始HashTable对象中的成员变量_table,如果状态为存在,则调用newht的Insert函数; - 如果状态不为存在,则继续往后加加;
- 直到走到
原始HashTable中的成员变量_table的_table.size()位置。 - 对两个
_table进行交换:_table.swap(newht._table);
扩容代码:
if (_n * 10 / _table.size() >= 7)
{// 新空间大小size_t newsize = 2 * _table.size();// 定义一个新对象HashTable<K, V, Func> newHT(newsize);for (size_t i = 0; i < _table.size(); ++i){// 如果状态为存在则在新的对象中进行插入if (_table[i]._status == EXIST)newHT.Insert(_table[i]._kv);}// 交换两个表_table.swap(newHT._table);
}
Insert代码(version 2):
bool Insert(const pair<K, V>& kv)
{if (_n * 10 / _table.size() >= 7){size_t newsize = 2 * _table.size();HashTable<K, V, Func> newHT(newsize);for (size_t i = 0; i < _table.size(); ++i){if (_table[i]._status == EXIST)newHT.Insert(_table[i]._kv);}_table.swap(newHT._table);}size_t hashi = kv.first % _table.size();while (_table[hashi]._status == EXIST){++hashi;hashi %= _table.size();}_table[hashi]._kv = kv;_table[hashi]._status = EXIST;++_n;return true;
}
⌛3、查找元素(Find)⏳
查找元素的思路:
- 首先根据哈希函数计算出哈希值(映射位置);
- 以此位置为起始点,向后寻找,直到找到为空的位置;
- 如果在此之间找到与所给的值相等的位置,返回此位置的地址;
- 注意这里要判断一下找到的节点的状态是否为删除,如果是删除状态,那就直接跳过;
- 如果不是删除才可以返回此节点的地址。
- 如果一直到空还未找到,说明没有哈希表中没有此元素,返回空指针
nullptr。
查找代码:
HashData<K, V>* Find(const K& key)
{// 根据哈希函数计算位置size_t hashi = key % _table.size();// 如果状态不为空则继续向后查找while (_table[hashi]._status != EMPTY){// 找到了并且状态不为删除,则返回此位置的地址if (_table[hashi]._status != DELETE &&_table[hashi]._kv.first == key){return &_table[hashi];}// 找不到则继续向后找else{++hashi;hashi %= _table.size();}}// 找到空还未找到返回空指针return nullptr;
}
⌛4、删除元素(Erase)⏳
删除元素的思路:
- 调用查找函数,看是否有此元素;
- 如果找到此元素,直接对此位置的状态置为
DELETE;- 这就是为什么在查找的时候要判断一下找到的那个节点的位置是否是删除状态;
- 如果是删除状态并且返回,可能会造成重复删除的可能。
- 如果未找到,则返回
false。
删除代码:
bool Erase(const K& key)
{HashData<K, V>* ret = Find(key);if (ret == nullptr)return false;else{ret->_status = DELETE;return true;}
}
4. 字符串哈希
那当我们 插入字符串 的时候应该 用什么样的哈希函数来解决值与位置的对应关系 来实现哈希表呢?
- 当我们插入数字的类型,例如:
double、float、int、 char、unsigned用的是一种类型的哈希函数; - 当我们插入字符串类型
string的时候用的是另一种类型的哈希函数; - 🔎遇到这种情况的时候我们一般用仿函数来解决问题!!!🔍
因此我们要加一个仿函数的模板参数:class HashFunc
对于数字类型的仿函数代码:
template<class K>
struct Hash
{size_t operator()(const K& key){// 强转即可return (size_t)key;}
};
对于string类型的仿函数代码:
这里先写一下,待会再细谈:
struct StringFunc
{size_t operator()(const string& str){size_t ret = 0;for (auto& e : str){ret *= 131;ret += e;}return ret;}
};
由于string类型的哈希我们经常用,因此可以用模板的特化,并将此模板用缺省参数的形式传递,这样我们就不用在每次用的时候传入仿函数了。
template<class K>
struct Hash
{size_t operator()(const K& key){return (size_t)key;}
};template<>
struct Hash<string>
{size_t operator()(const string& str){size_t ret = 0;for (auto& e : str){ret *= 131;ret += e;}return ret;}
};
详谈字符串哈希的相关做法
我们用的哈希函数要尽量减少哈希冲突,因此在我们实现字符串转数字的时候也要尽量避免重复数据的出现次数,实际上有很多解决方法,这里有一篇文章,有兴趣的可以看一下:
其中讲了好几种哈希算法,并进行了很多测试:
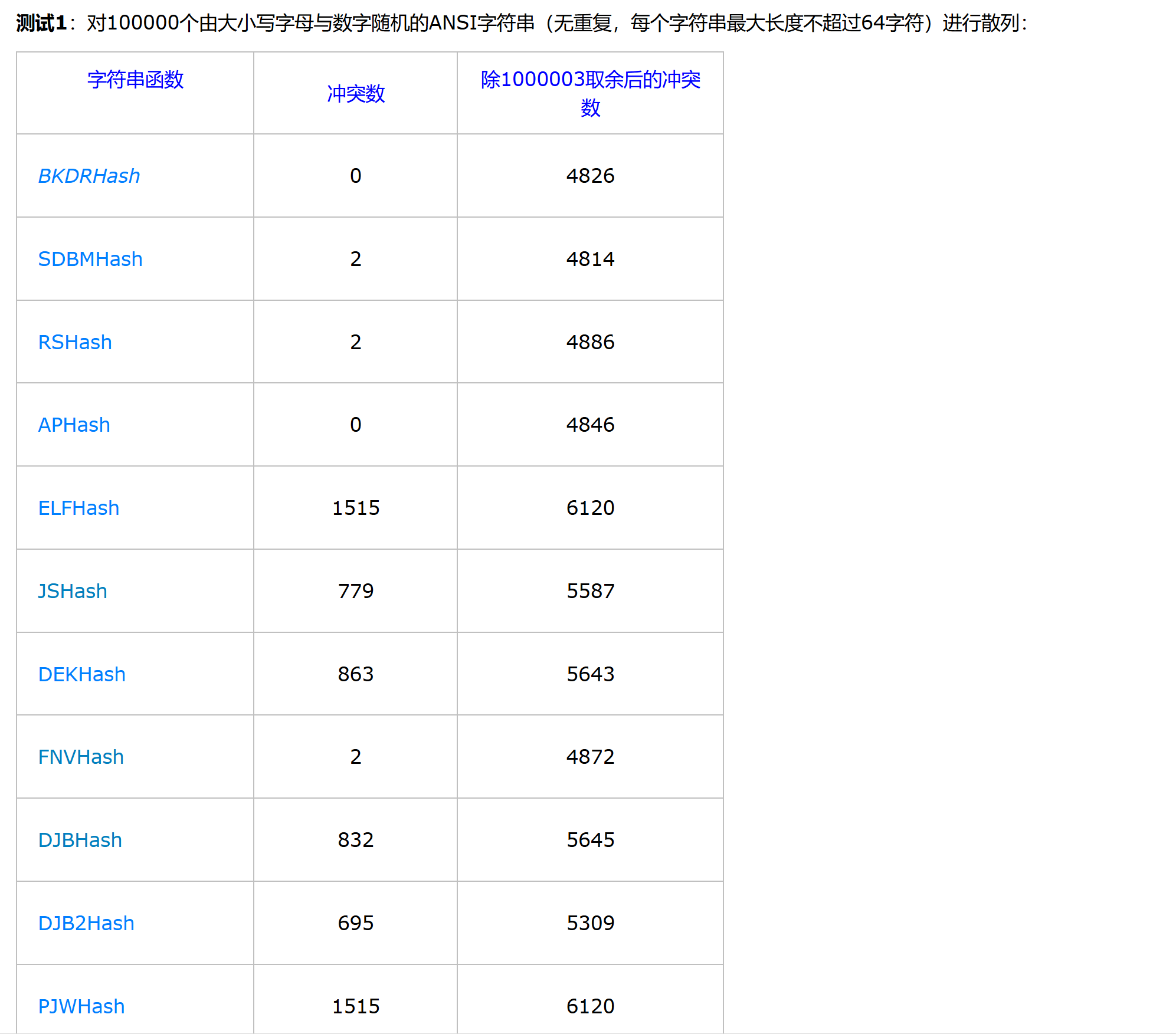
其中效果最好的就是BKDR字符串哈希算法,由于在Brian Kernighan与Dennis Ritchie的《The C Programming Language》一书被展示而得名,是一种简单快捷的hash算法,也是Java目前采用的字符串的Hash算法(累乘因子为31)。
下面代码来自于上述链接:
template<class T>
size_t BKDRHash(const T *str)
{ register size_t hash = 0; while (size_t ch = (size_t)*str++) { hash = hash * 131 + ch; // 也可以乘以31、131、1313、13131、131313.. // 有人说将乘法分解为位运算及加减法可以提高效率,如将上式表达为:hash = hash << 7 + hash << 1 + hash + ch; // 但其实在Intel平台上,CPU内部对二者的处理效率都是差不多的, // 我分别进行了100亿次的上述两种运算,发现二者时间差距基本为0(如果是Debug版,分解成位运算后的耗时还要高1/3); // 在ARM这类RISC系统上没有测试过,由于ARM内部使用Booth's Algorithm来模拟32位整数乘法运算,它的效率与乘数有关: // 当乘数8-31位都为1或0时,需要1个时钟周期 // 当乘数16-31位都为1或0时,需要2个时钟周期 // 当乘数24-31位都为1或0时,需要3个时钟周期 // 否则,需要4个时钟周期 // 因此,虽然我没有实际测试,但是我依然认为二者效率上差别不大 } return hash;
}
5. 完整代码
🎨博主gitee链接: Jason-of-carriben 闭散列哈希
#pragma once
#include <iostream>
#include <vector>
using namespace std;namespace open_adress
{enum Status{EXIST,DELETE,EMPTY};template<class K, class V>struct HashData{Status _status = EMPTY;pair<K, V> _kv;};struct StringFunc{size_t operator()(const string& str){size_t ret = 0;for (auto& e : str){ret *= 131;ret += e;}return ret;}};template<class K>struct Hash{size_t operator()(const K& key){return (size_t)key;}};template<>struct Hash<string>{size_t operator()(const string& str){size_t ret = 0;for (auto& e : str){ret *= 131;ret += e;}return ret;}};template<class K, class V, class Func = Hash<K>>class HashTable{public:HashTable(size_t n = 10){_table.resize(n);}bool Insert(const pair<K, V>& kv){HashData<K, V>* ret = Find(kv.first);if (ret != nullptr)return false;if (_n * 10 / _table.size() >= 7){size_t newsize = 2 * _table.size();HashTable<K, V, Func> newHT(newsize);for (size_t i = 0; i < _table.size(); ++i){if (_table[i]._status == EXIST)newHT.Insert(_table[i]._kv);}_table.swap(newHT._table);for (auto& data : _table){if (data._status == EXIST)++_n;}}Func hf;size_t hashi = hf(kv.first) % _table.size();while (_table[hashi]._status == EXIST){++hashi;hashi %= _table.size();}_table[hashi]._kv = kv;_table[hashi]._status = EXIST;++_n;return true;}HashData<K, V>* Find(const K& key){Func hf;size_t hashi = hf(key) % _table.size();while (_table[hashi]._status != EMPTY){if (_table[hashi]._status != DELETE &&_table[hashi]._kv.first == key){return &_table[hashi];}else{++hashi;hashi %= _table.size();}}return nullptr;}bool Erase(const K& key){HashData<K, V>* ret = Find(key);if (ret == nullptr)return false;else{ret->_status = DELETE;return true;}}private:vector<HashData<K, V>> _table;size_t _n = 0;};void HashTest1(){HashTable<int, int> ht;int arr[] = { 10001, 91, 72, 55, 63, 97, 80 };for (auto& e : arr){ht.Insert(make_pair(e, e));}ht.Insert(make_pair(93, 93));}void TestHT3(){//HashTable<string, int, StringHashFunc> ht;HashTable<string, int> ht;ht.Insert(make_pair("sort", 1));ht.Insert(make_pair("left", 1));ht.Insert(make_pair("insert", 1));/*cout << StringHashFunc()("bacd") << endl;cout << StringHashFunc()("abcd") << endl;cout << StringHashFunc()("aadd") << endl;*/}/*void test_map1(){string arr[] = { "苹果", "西瓜", "苹果", "西瓜", "苹果", "苹果", "西瓜","苹果", "香蕉", "苹果", "香蕉","苹果","草莓", "苹果","草莓" };unordered_map<string, int> countMap;for (auto& e : arr){countMap[e]++;}cout << countMap.load_factor() << endl;cout << countMap.max_load_factor() << endl;cout << countMap.size() << endl;cout << countMap.bucket_count() << endl;cout << countMap.max_bucket_count() << endl;for (auto& kv : countMap){cout << kv.first << ":" << kv.second << endl;}cout << endl;}*/}