文章目录
第6章 多级缓存
6.1 什么是多级缓存?
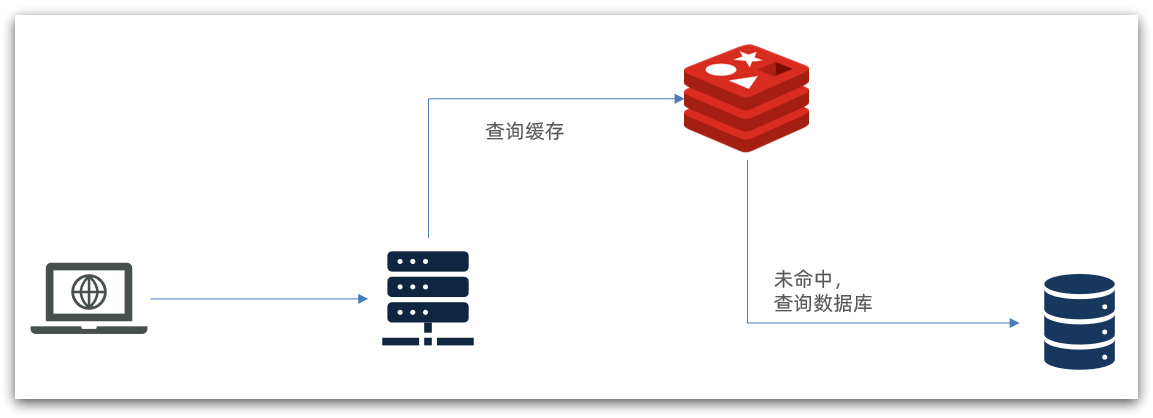
传统的缓存策略一般是请求到达Tomcat后,先查询Redis,如果未命中则查询数据库,如图:
但这样的策略存在以下两个问题:
而多级缓存就是要充分利用请求处理的各个环节,分别添加缓存,减轻Tomcat压力,如图:
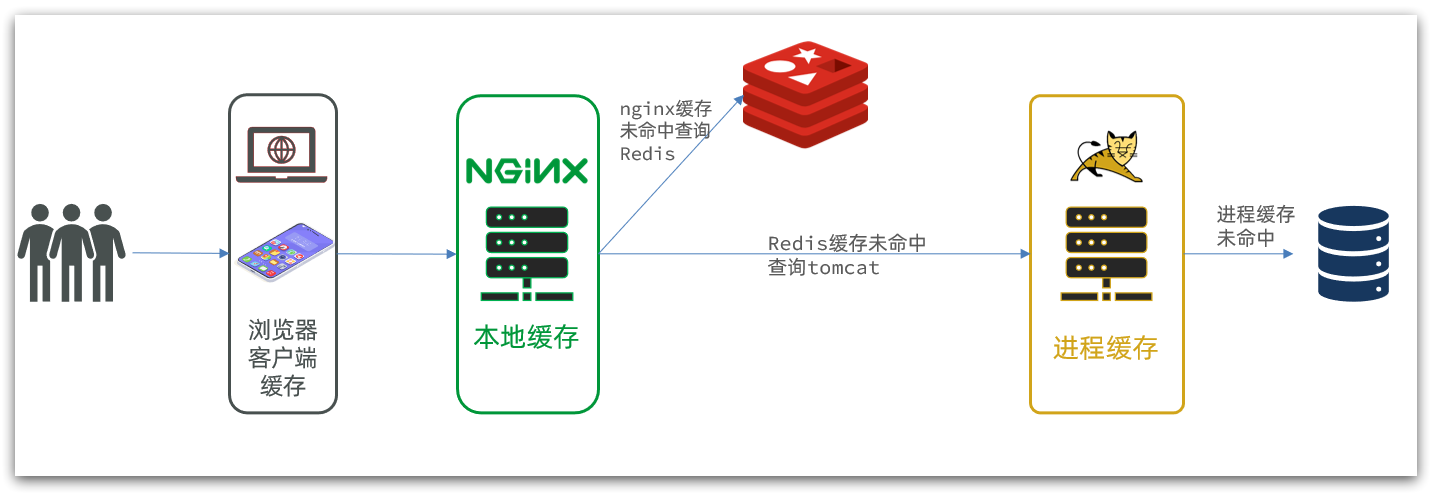
- 1)浏览器访问静态资源时,优先读取浏览器本地缓存;访问非静态资源时,才访问服务端。
- 2)请求到达Nginx后,优先读取Nginx本地缓存。
- 3)如果Nginx本地缓存未命中,则去查询Redis。
- 4)如果Redis查询未命中,则将请求发送到Tomcat,并优先查询JVM进程缓存。
- 5)如果JVM进程缓存未命中,则查询数据库。
在以上多级缓存架构中,Nginx服务已经不再是一个反向代理服务器,而是一个需要编写本地缓存查询、Redis查询、Tomcat查询业务逻辑的业务服务器。
进一步优化,业务Nginx服务也会搭建集群来提高并发,还有专门的Nginx服务来做反向代理,同时Tomcat服务也会部署成集群模式,如图:
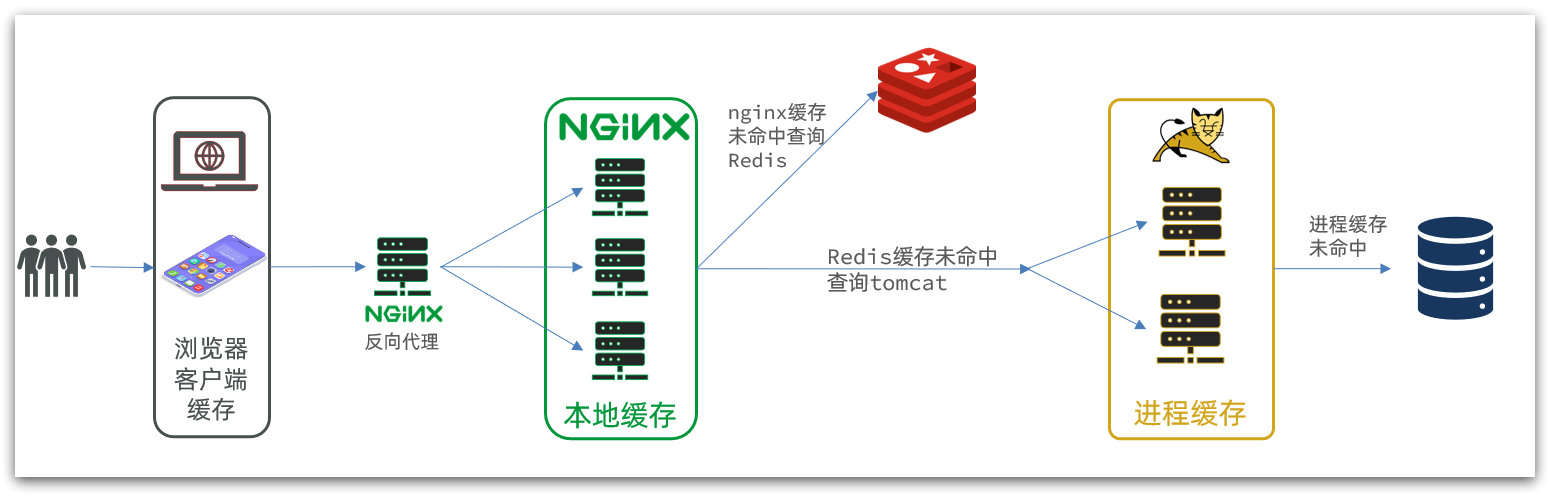
综上,多级缓存的关键有两个:
6.2 搭建测试项目
6.2.1 项目介绍
这里继续沿用【第4章 Redis实战】系列文章中编写的测试项目,代码下载地址见文末。↓↓↓
该项目的结构如下:
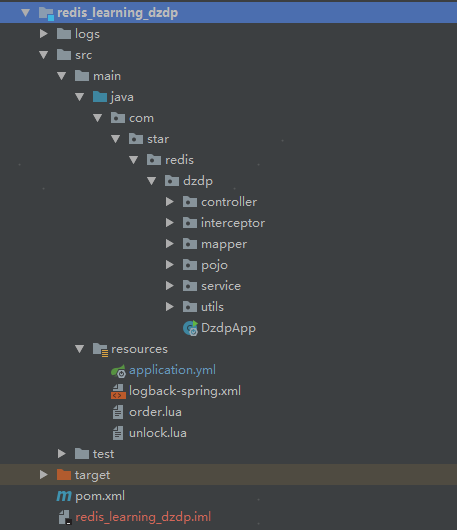
其中的业务包括:
- 获取验证码;用户登录;用户签到;用户签到统计。
- 查询商户列表;根据ID查询商户详情;新增商户;修改商户;图片上传。
- 新增探店笔记;根据ID查询笔记详情;点赞/取消点赞功能;查询点赞排行榜;查询关注用户的探店笔记列表。
- 关注或者取消关注功能;查询共同关注好友。
- 添加普通优惠券;添加秒杀优惠券;秒杀下单。
6.2.2 新增商品表
在数据库创建一个商品表tb_item并初始化几条数据:
DROP TABLE IF EXISTS `tb_item`;
CREATE TABLE `tb_item` (`id` BIGINT(20) NOT NULL AUTO_INCREMENT COMMENT '商品id',`title` VARCHAR(264) NOT NULL COMMENT '商品标题',`name` VARCHAR(128) NOT NULL DEFAULT '' COMMENT '商品名称',`price` BIGINT(20) NOT NULL COMMENT '价格(分)',`image` VARCHAR(200) NULL DEFAULT NULL COMMENT '商品图片',`category` VARCHAR(200) NULL DEFAULT NULL COMMENT '类目名称',`brand` VARCHAR(100) NULL DEFAULT NULL COMMENT '品牌名称',`spec` VARCHAR(200) NULL DEFAULT NULL COMMENT '规格',`status` INT(1) NOT NULL DEFAULT 1 COMMENT '商品状态 1-正常,2-下架,3-删除',`create_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',`update_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',PRIMARY KEY (`id`) USING BTREE,INDEX `status`(`status`) USING BTREE,INDEX `updated`(`update_time`) USING BTREE
) CHARACTER SET = utf8 COLLATE = utf8_general_ci COMMENT = '商品表';INSERT INTO `tb_item` VALUES (1, 'RIMOWA 21寸托运箱拉杆箱 SALSA AIR系列果绿色 820.70.36.4', 'SALSA AIR', 16900, 'https://m.360buyimg.com/mobilecms/s720x720_jfs/t6934/364/1195375010/84676/e9f2c55f/597ece38N0ddcbc77.jpg!q70.jpg.webp', '拉杆箱', 'RIMOWA', '{\"颜色\": \"红色\", \"尺码\": \"26寸\"}', 1, '2019-05-01 00:00:00', '2019-05-01 00:00:00');
INSERT INTO `tb_item` VALUES (2, '安佳脱脂牛奶 新西兰进口轻欣脱脂250ml*24整箱装*2', '脱脂牛奶', 68600, 'https://m.360buyimg.com/mobilecms/s720x720_jfs/t25552/261/1180671662/383855/33da8faa/5b8cf792Neda8550c.jpg!q70.jpg.webp', '牛奶', '安佳', '{\"数量\": 24}', 1, '2019-05-01 00:00:00', '2019-05-01 00:00:00');
INSERT INTO `tb_item` VALUES (3, '唐狮新品牛仔裤女学生韩版宽松裤子 A款/中牛仔蓝(无绒款) 26', '韩版牛仔裤', 84600, 'https://m.360buyimg.com/mobilecms/s720x720_jfs/t26989/116/124520860/644643/173643ea/5b860864N6bfd95db.jpg!q70.jpg.webp', '牛仔裤', '唐狮', '{\"颜色\": \"蓝色\", \"尺码\": \"26\"}', 1, '2019-05-01 00:00:00', '2019-05-01 00:00:00');
INSERT INTO `tb_item` VALUES (4, '森马(senma)休闲鞋女2019春季新款韩版系带板鞋学生百搭平底女鞋 黄色 36', '休闲板鞋', 10400, 'https://m.360buyimg.com/mobilecms/s720x720_jfs/t1/29976/8/2947/65074/5c22dad6Ef54f0505/0b5fe8c5d9bf6c47.jpg!q70.jpg.webp', '休闲鞋', '森马', '{\"颜色\": \"白色\", \"尺码\": \"36\"}', 1, '2019-05-01 00:00:00', '2019-05-01 00:00:00');
INSERT INTO `tb_item` VALUES (5, '花王(Merries)拉拉裤 M58片 中号尿不湿(6-11kg)(日本原装进口)', '拉拉裤', 38900, 'https://m.360buyimg.com/mobilecms/s720x720_jfs/t24370/119/1282321183/267273/b4be9a80/5b595759N7d92f931.jpg!q70.jpg.webp', '拉拉裤', '花王', '{\"型号\": \"XL\"}', 1, '2019-05-01 00:00:00', '2019-05-01 00:00:00');
再创建一个商品库存表tb_item_stock并初始化几条数据:
DROP TABLE IF EXISTS `tb_item_stock`;
CREATE TABLE `tb_item_stock` (`item_id` BIGINT(20) NOT NULL COMMENT '商品id,关联tb_item表',`stock` INT(10) NOT NULL DEFAULT 9999 COMMENT '商品库存',`sold` INT(10) NOT NULL DEFAULT 0 COMMENT '商品销量',PRIMARY KEY (`item_id`) USING BTREE
) CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci COMMENT = '商品库存表';INSERT INTO `tb_item_stock` VALUES (1, 99996, 3219);
INSERT INTO `tb_item_stock` VALUES (2, 99999, 54981);
INSERT INTO `tb_item_stock` VALUES (3, 99999, 189);
INSERT INTO `tb_item_stock` VALUES (4, 99999, 974);
INSERT INTO `tb_item_stock` VALUES (5, 99999, 18649);
6.2.3 编写商品相关代码
首先创建tb_item、tb_item_stock表对应的实体类:
java">// com.star.redis.dzdp.pojo.Item/**** 商品* @author hsgx* @since 2024/4/12 10:01*/
@Data
@EqualsAndHashCode(callSuper = false)
@TableName("tb_item")
public class Item implements Serializable {private static final long serialVersionUID = 1L;@TableId(value = "id", type = IdType.AUTO)private Long id;private String title;private String name;private Double price;private String image;private String category;private String brand;private String spec;private Integer status;private Date crateTime;private Date updateTime;}
java">// com.star.redis.dzdp.pojo.ItemStock/**** 商品库存表* @author hsgx* @since 2024/4/12 10:05*/
@Data
@EqualsAndHashCode(callSuper = false)
@TableName("tb_item_stock")
public class ItemStock {private static final long serialVersionUID = 1L;@TableId(value = "item_id", type = IdType.AUTO)private Long itemId;private Integer stock;private Integer sold;}
然后创建商品Item实体对应的ItemController类-IItemService接口-ItemServiceImpl实现类-ItemMapper接口,创建商品库存ItemStock实体对应的IItemStockService接口-ItemStockServiceImpl实现类-ItemStockMapper接口,均使用MyBatis-Plus来实现。
接下来在ItemController类中实现两个接口,其接口文档和代码如下:
| 项目 | 说明 |
|---|---|
| 功能 | 根据ID查询商品信息 |
| 请求方法 | GET |
| 请求路径 | /item/{id} |
| 请求方法 | id:Long,商品ID |
| 请求方法 | Item:商品信息 |
| 项目 | 说明 |
|---|---|
| 功能 | 根据ID查询商品库存信息 |
| 请求方法 | GET |
| 请求路径 | /item/stock/{id} |
| 请求方法 | id:Long,商品ID |
| 请求方法 | Item:商品库存信息 |
java">// com.star.redis.dzdp.controller.ItemController@Slf4j
@RestController
@RequestMapping("/item")
public class ItemController {@Resourceprivate IItemService itemService;/*** 根据ID查询商品信息* @author hsgx* @since 2024/4/12 10:17* @param id* @return com.star.redis.dzdp.pojo.Item*/@GetMapping("/{id}")public Item queryById(@PathVariable("id") Long id) {return itemService.getById(id);}/*** 根据ID查询商品库存信息* @author xiaowd* @since 2024/4/12 14:22* @param id* @return com.star.redis.dzdp.pojo.ItemStock*/@GetMapping("/stock/{id}")public ItemStock queryStockById(@PathVariable("id") Long id) {return itemStockService.getById(id);}}
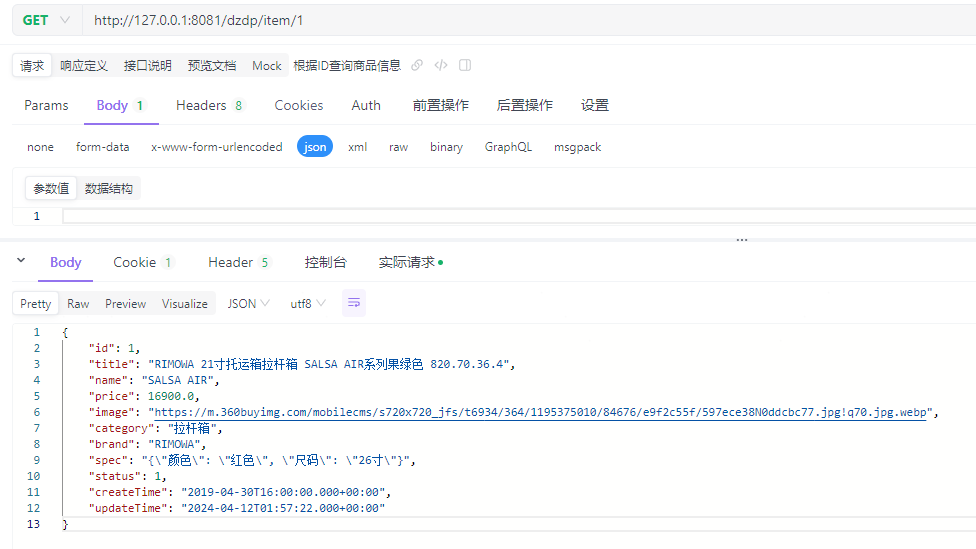
6.2.4 启动服务并测试

6.2.5 导入商品查询页面,配置反向代理
这里已经准备好了一个Nginx反向代理服务器和静态资源,下载地址见文末。↓↓↓

将该文件夹拷贝到一个非中文目录下,然后修改conf/nginx.conf文件以配置反向代理:
# nginx-1.18.0/conf/nginx.conf#user nobody;
worker_processes 1;events {worker_connections 1024;
}http {include mime.types;default_type application/octet-stream;sendfile on;#tcp_nopush on;keepalive_timeout 65;server {listen 8082;server_name localhost;location /api {proxy_pass http://127.0.0.1:8081/dzdp;}location / {root html;index index.html index.htm;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}
}
打开cmd窗口,执行start nginx.exe命令运行服务。然后在浏览器访问http://localhost:8082/item.html?id=1,显示如下页面:
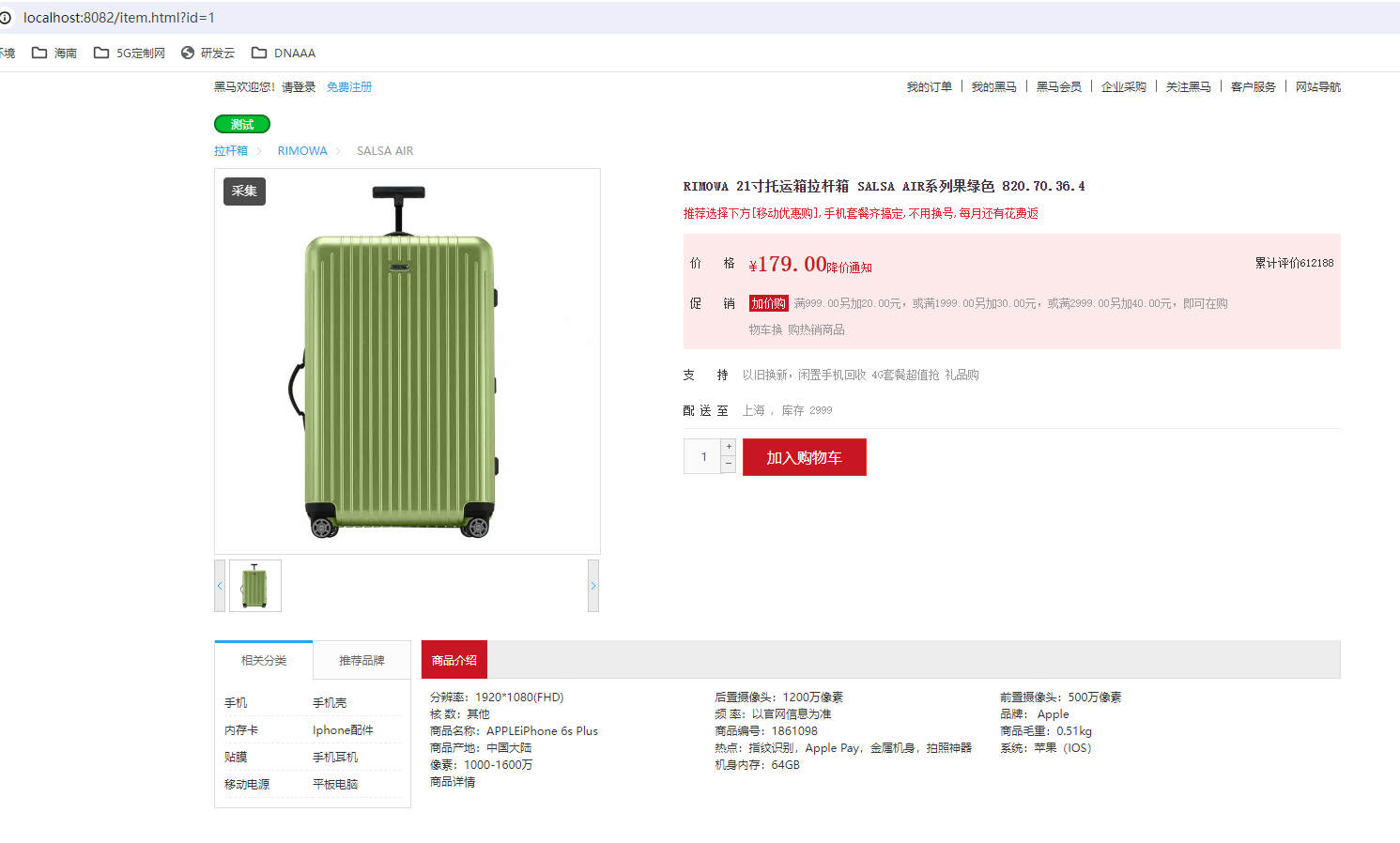
在上述页面中打开控制台,可以看到ajax向后台发起请求,并成功拿到数据:
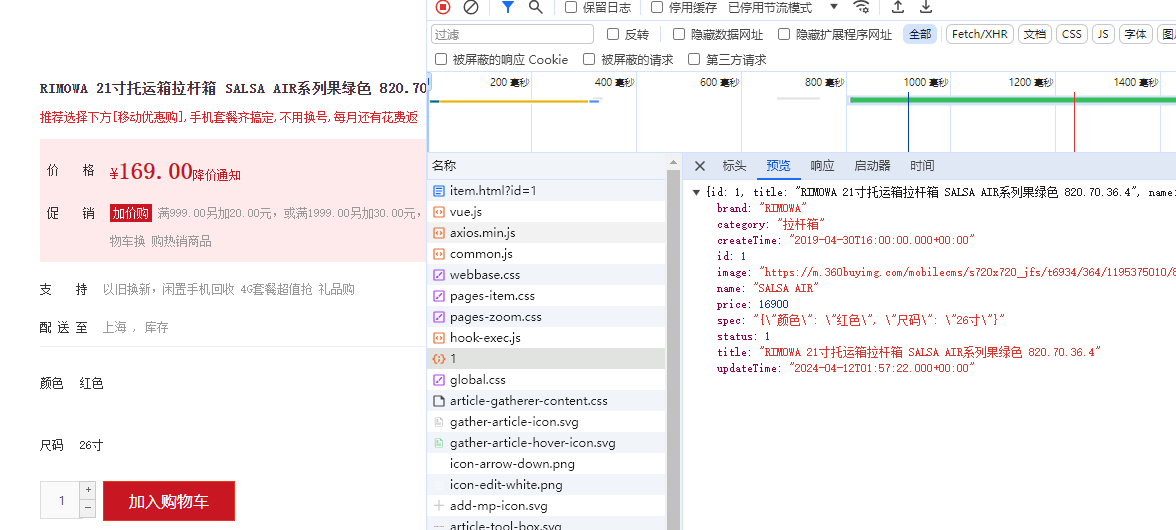
至此,测试项目搭建完毕。
6.3 JVM进程缓存
6.3.1 Caffeine
缓存一般可以分为两类:
-
分布式缓存,例如Redis:
-
进程本地缓存,例如HashMap、GuavaCache:
- 优点:读取本地内存,没有网络开销,速度更快
- 缺点:存储容量有限、可靠性较低、无法共享
- 场景:性能要求较高,缓存数据量较小
Caffeine是一个基于Java8开发的,提供了近乎最佳命中率的高性能的本地缓存库。目前Spring内部使用的缓存就是Caffeine。
Caffeine的GitHub地址:https://github.com/ben-manes/caffeine
要使用Caffeine,首先要引入Caffeine的依赖:
<dependency><groupId>com.github.ben-manes.caffeine</groupId><artifactId>caffeine</artifactId><version>2.7.0</version>
</dependency>
下面是Caffeine的基本API的使用案例:
java">@Test
public void testCaffeine() {// 构建cache对象Cache<String, String> cache = Caffeine.newBuilder().build();// 存数据cache.put("name", "Jack");// 取数据String name = cache.getIfPresent("name");System.out.println("name = " + name);// 取数据:先查缓存,如果未命中则执行Lambda表达式// 参数1:缓存的key// 参数2:Lambda表达式的参数即缓存的keyString age = cache.get("age", key -> {return "25";});System.out.println("age = " + age);
}
运行以上代码,结果如下:
name = Jack
age = 25
Caffeine提供了三种缓存清除策略:
- 基于容量:设置缓存的数量上限
java">// 构建cache对象
Cache<String, String> cache = Caffeine.newBuilder().maximumSize(2) //设置缓存数量上限为2.build();
- 基于时间:设置缓存的有效时间
java">Cache<String, String> cache = Caffeine.newBuilder()// 设置缓存有效期为10秒,从最后一次写入开始计时.expireAfterWrite(Duration.ofSeconds(10)).build();
在默认情况下,当一个缓存元素过期时,Caffeine不会立即将其清除。而是在一次读或写操作后,或者在空闲时间完成对失效数据的清除。
6.3.2 实现JVM进程缓存
6.3.2.1 需求分析
利用Caffeine实现以下需求:
6.3.2.2 代码实现
首先定义两个Caffeine缓存对象,分别保存商品信息、商品库存的缓存数据:
java">// com.star.redis.dzdp.config.CaffeineConfig/**** Caffeine缓存配置* @author hsgx* @since 2024/4/12 14:29*/
@Configuration
public class CaffeineConfig {@Beanpublic Cache<Long, Item> itemCache() {return Caffeine.newBuilder().initialCapacity(1000).maximumSize(10000).build();}@Beanpublic Cache<Long, ItemStock> itemStockCache() {return Caffeine.newBuilder().initialCapacity(1000).maximumSize(10000).build();}
}
接着修改ItemController类的queryById()方法和queryStockById()方法:
java">@Resource
private Cache<Long, Item> itemCache;
@Resource
private Cache<Long, ItemStock> itemStockCache;@GetMapping("/{id}")
public Item queryById(@PathVariable("id") Long id) {//return itemService.getById(id);// 添加缓存return itemCache.get(id, key -> {return itemService.getById(id);});
}@GetMapping("/stock/{id}")
public ItemStock queryStockById(@PathVariable("id") Long id) {//return itemStockService.getById(id);// 添加缓存return itemStockCache.get(id, key -> {return itemStockService.getById(id);});
}
…
本节完,下一节将正式进入多级缓存的实现。
本节所涉及的代码和资源可从git仓库下载:https://gitee.com/weidag/redis_learning.git
更多内容请查阅分类专栏:Redis从入门到精通
感兴趣的读者还可以查阅我的另外几个专栏:
- SpringBoot源码解读与原理分析(已完结)
- MyBatis3源码深度解析(已完结)
- 再探Java为面试赋能(持续更新中…)