springAI
1.springAI基本介绍
springAI是一个AI工程应用框架,其目标是将 Spring 生态系统设计原则(例如可移植性和模块化设计)应用于 AI 领域,并推广使用 POJO 作为 AI 领域应用程序的构建块。
2.特性
灵活的AIP支持chat,text-to-image, and Embedding models。支持同步和stream API。向下可以接入特定的模型。
Chat Models
-
OpenAI
-
Azure Open AI
-
Amazon Bedrock
-
Cohere's Command
-
AI21 Labs' Jurassic-2
-
Meta's LLama 2
-
Amazon's Titan
-
-
Google Vertex AI Palm
-
Google Gemini
-
HuggingFace - access thousands of models, including those from Meta such as Llama2
-
Ollama - run AI models on your local machine
-
MistralAI
Text-to-image Models
-
OpenAI with DALL-E
-
StabilityAI
Transcription (audio to text) Models
-
OpenAI
Embedding Models
-
OpenAI
-
Azure OpenAI
-
Ollama
-
ONNX
-
PostgresML
-
Bedrock Cohere
-
Bedrock Titan
-
Google VertexAI
-
Mistal AI
灵活的提供了多个厂商的向量存储API.
Vector Databases
-
Azure Vector Search
-
Chroma
-
Milvus
-
Neo4j
-
PostgreSQL/PGVector
-
PineCone
-
Redis
-
Weaviate
-
Qdrant
为 AI Models and Vector Stores提供了Spring Boot Auto Configuration and Starters .
支持以下模型:
-
OpenAI
-
Azure OpenAI
-
VertexAI
-
Mistral AI
支持的模型供应商:
-
OpenAI
-
Microsoft,
-
Amazon,
-
Google
-
and Huggingface
提供数据工程ETL框架:
-
核心功能是促进使用向量存储将文档传输到模型提供者。 ETL 框架基于 Java 函数式编程概念,可帮助您将多个步骤链接在一起。
-
支持读取各种格式的文档,包括 PDF、JSON 等。
-
允许进行数据操作以满足需求。涉及分割文档以遵守上下文窗口限制,并使用关键字增强其以提高文档检索效率。
-
处理后的文档存储在矢量数据库中,以便将来检索。
https://github.com/open-webui/open-webui
058 Docker运行Open WebUI拉取镜像_哔哩哔哩_bilibili
3.springAI框架使用搭建
参考文档:
Installation :: Spring Cli
Spring AI
Spring AI :: Spring AI Reference
Getting Started :: Spring AI Reference
Spring AI 中的类:
-
DocumentReader:一个 Java 功能接口,负责从数据源加载 List<Document>。 常见的数据源有 PDF、Markdown 和 JSON。
-
Document:数据源的基于文本的表示形式,还包含用于描述内容的元数据。
-
DocumentTransformer:负责以各种方式处理数据(例如,将文档分割成更小的部分或向文档添加额外的元数据)。
-
DocumentWriter:允许您将文档保存到数据库中(最常见的是在 AI 堆栈中,矢量数据库)。
-
Embedding:将数据表示为 List<Double>,矢量数据库使用它来计算用户查询与相关文档的“相似度”。
在矢量数据库中,查询与传统的关系数据库不同。 他们执行相似性搜索,而不是精确匹配。 当给定向量作为查询时,向量数据库返回与查询向量“相似”的向量。 矢量数据库用于将您的数据与 AI 模型集成。 使用它们的第一步是将数据加载到矢量数据库中。 然后,当用户查询要发送到人工智能模型时,首先检索一组相似的文档。 然后,这些文档将作为用户问题的上下文,并与用户的查询一起发送到人工智能模型。 该技术称为检索增强生成(RAG)。
评估AI模型响应 : 一种方法涉及呈现用户的请求和人工智能模型对模型的响应,查询响应是否与提供的数据一致。
利用矢量数据库中存储的信息作为补充数据可以增强评估过程,有助于确定响应相关性。
Spring AI 项目当前提供了一些非常基本的示例,说明如何以提示的形式评估响应以包含在 JUnit 测试中。
step1 下载安装spring cli工具 https://github.com/spring-projects/spring-cli/releases
step2.创建myai工程
spring boot new --from ai --name myai
step3.创建openAI账户,获取api key并配置其于项目工程
获取apikey
https://platform.openai.com/api-keys
New API

配置api key
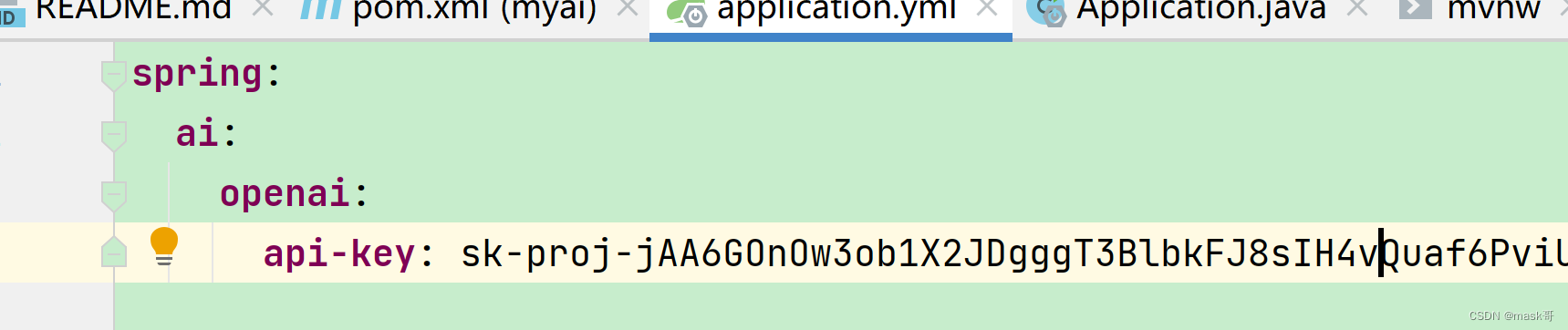
step4.运行myai工程
step5.访问工程:
curl localhost:8080/ai/simple
参考代码:https://github.com/rd-1-2022/ai-openai-helloworld/tree/main
注意:可能因为网络无法访问,需自行解决
Spring AI整合OpenAI和Ollama本地大模型_哔哩哔哩_bilibili


4. springAI API
-
chat completion API(openAI/Ollama/huggingface/google vertexAI)
-
Embeddings API (openAI/ollama/google vertexAI/Transformer(ONNX)) EmbeddingClient 界面旨在与 AI 和机器学习中的嵌入模型直接集成。 其主要功能是将文本转换为数值向量,通常称为嵌入。 这些嵌入对于语义分析和文本分类等各种任务至关重要。
EmbeddingClient 界面的设计围绕两个主要目标:
可移植性:该接口确保了跨各种嵌入模型的轻松适应性。 它允许开发人员以最少的代码更改在不同的嵌入技术或模型之间切换。 这种设计符合 Spring 的模块化和可互换性理念。
简单性:EmbeddingClient 简化了将文本转换为嵌入的过程。 通过提供 embed(String text) 和 embed(Document document) 等简单方法,它消除了处理原始文本数据和嵌入算法的复杂性。 这种设计选择使开发人员(尤其是刚接触 AI 的开发人员)能够更轻松地在应用程序中利用嵌入,而无需深入研究底层机制。
-
image generation api(openAI/stability)
-
transcription API (openAI)
-
vector databases(Neo4j/PGvector/Redis);
-
Function Calling
大型语言模型(LLM)在训练后被冻结,导致知识过时,并且无法访问或修改外部数据。
Function Calling 机制解决了知识过时问题,允许注册自定义用户函数,将大型语言模型连接到外部系统的 API。 这些系统可以为llm提供实时数据并代表他们执行数据处理操作。
-
Multimodality API(多模态 api) 多模态是指模型同时理解和处理多种类型模式的的信息数据能力,包括:文本、图像、音频;
多模式大语言模型(LLM)特征使模型能够结合其他模态(图像、音频、视频)来处理和生成文本响应;
springAI多模态API提供了所有必要的统一抽象和代码封装来支持多模态LLM
-
Prompts
角色: system Role /User Role/ Assitant Role/Function Role
提示技术:
-
Text Summarization: 文本总结
-
Question Answering: 问题问答
-
Text Classification: 文本分类
-
Conversation: 交互式自然对话
-
Code Generation: 代码生成
高级技术:
-
-
输出解析(Output Parsers)
OutputParser 接口允许您获取结构化输出,例如将输出映射到 Java 类或 AI 模型基于字符串的输出的值数组。
output Parser接口实现:BeanOutputParser(java bean 与json)、MapOutputParser(json转map)、ListOutputParser(输出为逗号分隔的list)
-
ETL Pipeline
Extract,Transform,Load->ETL
Retrieval Augmented Generation (RAG):检索增强生成
ETL 框架充当检索增强生成 (RAG) 用例中数据处理的支柱。
ETL 管道编排从原始数据源到结构化向量存储的流向,确保数据采用最佳格式供 AI 模型检索。
RAG 用例是文本,通过从数据体中检索相关信息来增强生成模型的功能,从而提高生成输出的质量和相关性。
ETL pipeline的三个主要组件:
-
DocumentReader实现了Supplier<List<Document>>接口 -
DocumentTransformer实现了Function<List<Document>, List<Document>>接口 -
DocumentWriter实现了Consumer<List<Document>>接口 Document 类包含文本和元数据,是通过 DocumentReader 从 PDF、文本文件和其他文档类型创建的。

ETL 类型:
-
PagePdfDocumentReader实现了DocumentReader -
TokenTextSplitter实现了DocumentTransformer -
VectorStore接口ofDocumentWriter接口
将数据基本加载到向量数据库中以与检索增强生成(RAG)模式一起使用,代码如下: vectorStore.accept(tokenTextSplitter.apply(pdfReader.get()));
-
-
-
测试评估(evaluation testing)
-
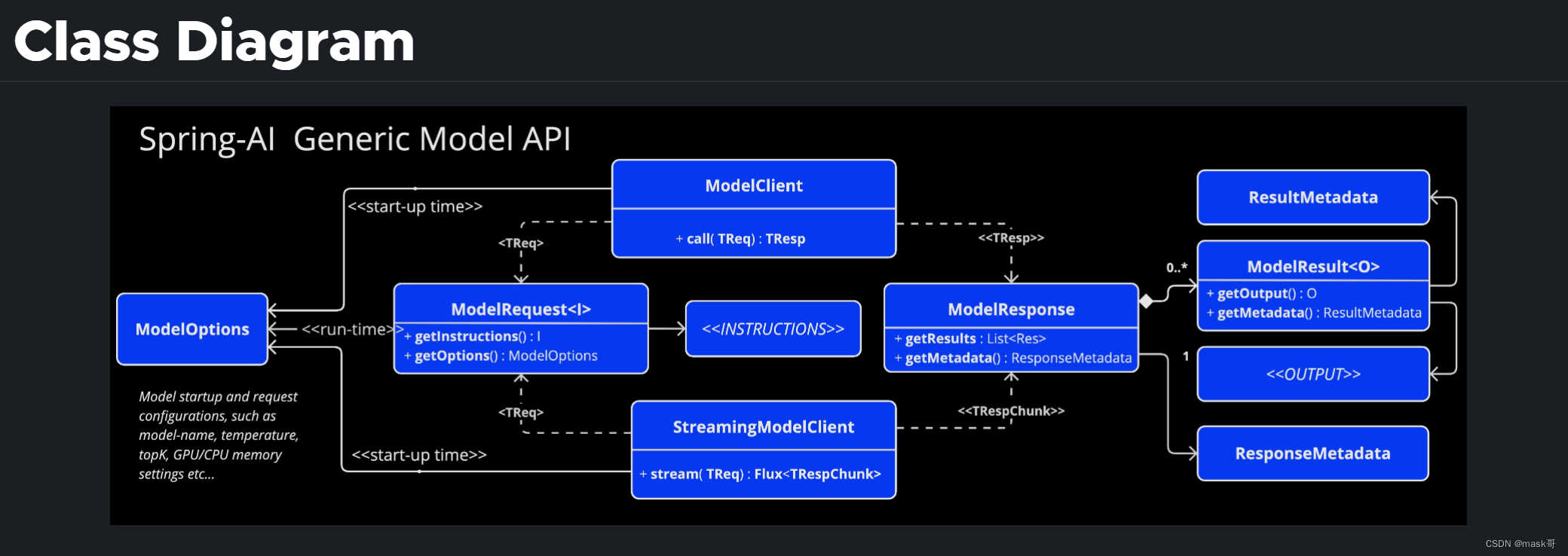
通用模型api(Generic Model API)
为了给所有 AI 模型客户端提供基础,创建了通用模型 API。 这使得通过遵循通用模式可以轻松地为 Spring AI 提供新的 AI 模型支持。 以下部分为此 API介绍: