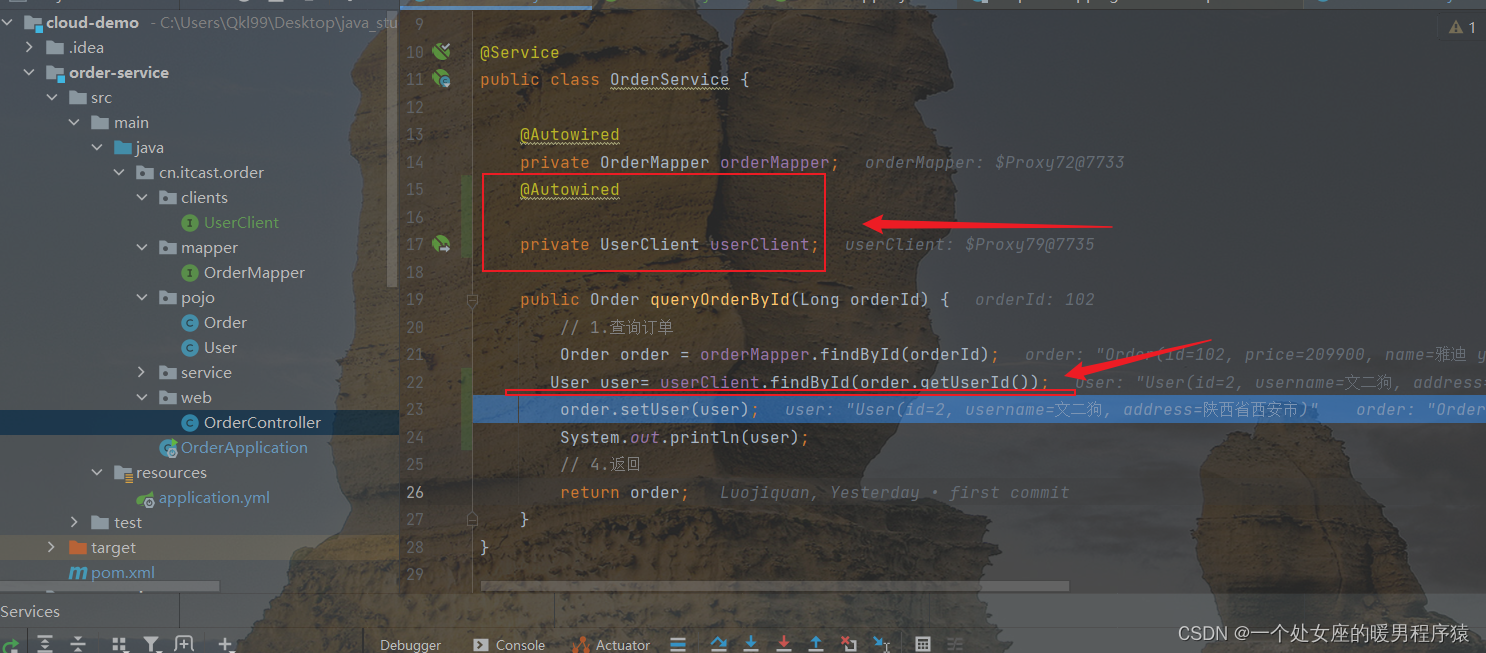
(1)利用Netron查看网络实际情况

上图链接
python生成上图代码如下,其中GETVGGnet是搭建VGG网络的程序GETVGGnet.py,VGGnet是该程序中的搭建网络类。netron是需要pip安装的可视化库,注意do_constant_folding=False可以防止Netron中不显示Batchnorm2D层,禁用参数隐藏。
python">import torch
from torch.autograd import Variable
from GetVGGnet import VGGnet
import netronnet = VGGnet()
x = Variable(torch.FloatTensor(1,3,28,28))
y = net(x)
print(y.data.shape)
onnx_path = "./save_model/VGGnet.onnx"
torch.onnx.export(net, x, onnx_path,do_constant_folding=False)
print(net)
netron.start(onnx_path)
(2)VGG训练测试全过程
此次训练在CPU上进行,迭代次epoch = 10,迭代内轮次batch=300,训练集10000张,测试集2000张。
train loss和train corre分别代表损失和正确率,横轴是不同迭代下每一个伦次的loss&corre累加,一个迭代进行33个轮次,每个迭代最后一个伦次数据不足被网络舍弃,10个迭代总共320次。test loss和test corre是每个一个迭代下所有伦次的正确率平均值。根据图可以看出,训练和测试结果都较好。

训练的损失和正确率在波动,但总体趋势较好。

数据集大小可以在此处修改: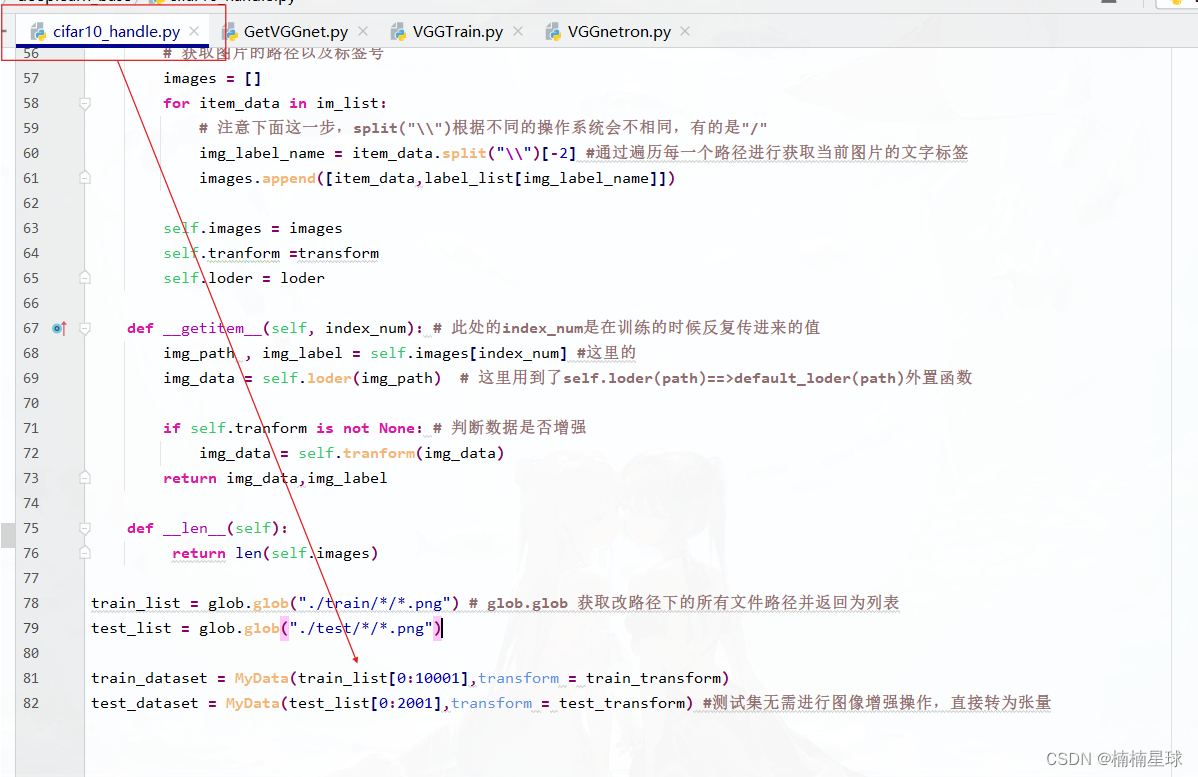
代码:cifar10_handle和GetVGGnet在上几篇文章有说明
python">#!/usr/bin/env python
# -*- coding:utf-8 -*-
"""
@author: 楠楠星球
@time: 2024/5/10 10:15
@file: VGGTrain.py-->test
@project: pythonProject
@# ------------------------------------------(one)--------------------------------------
@# ------------------------------------------(two)--------------------------------------
"""
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from GetVGGnet import VGGnet
from cifar10_handle import train_dataset,test_dataset
import matplotlib.pyplot as pltepoch = 10 #迭代次数
learn_rate = 0.01 #初始学习率net = VGGnet().to(device='cpu') #模型实例化
loss_fun = nn.CrossEntropyLoss() #调用损失函数
train_data_loder = DataLoader(dataset=train_dataset,batch_size=300, #每一次迭代的调用的波次shuffle=True, #这个波次是否打乱数据集num_workers=4, # 线程数drop_last=True) # 最后一个波次数据不足是否舍去test_data_loder = DataLoader(dataset=test_dataset,batch_size=300,shuffle=False,num_workers=4,drop_last=True)# optimizer = torch.optim.Adam(net.parameters(), lr=learn_rate)
optimizer = torch.optim.SGD(net.parameters(), lr=learn_rate, momentum=0.5) #优化器# scheduler = torch.optim.lr_scheduler.StepLR(optijumizer, step_size=5, gamma=0.9) #step_size=1表示每迭代一次更新一下学习率
scheduler = torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma=0.7) #学习率调整器def train(epoch_num,train_net):# ------------------------------------------()--------------------------------------loss_base = []corre_base = []test_loss_base = []test_corre_base =[]for epoch in range(epoch_num):# ------------------------------------------(TRAIN)--------------------------------------train_net.train()for i, data in enumerate(train_data_loder):input_tensor, label = datainput_tensor = input_tensor.to(device='cpu')label = label.to(device='cpu')output_tensor = train_net(input_tensor)loss = loss_fun(output_tensor, label)optimizer.zero_grad()loss.backward()optimizer.step()_, pred = torch.max(output_tensor.data, dim=1)correct = pred.eq(label.data).cpu().sum()print(f"训练中:第{epoch + 1}次迭代的小迭代{i}的损失率为:{1.00 * loss.item()},正确率为:{100.00 * correct / 300}")loss_base.append(loss.item())corre_base.append(100.00 * correct.item() / 300)scheduler.step()# ------------------------------------------(TEST)--------------------------------------sum_test_loss = 0sum_test_corre = 0train_net.eval()for i, test_data in enumerate(test_data_loder):input_tensor, label = test_datainput_tensor = input_tensor.to(device='cpu')label = label.to(device='cpu')output_tensor = train_net(input_tensor)loss = loss_fun(output_tensor, label)_, pred = torch.max(output_tensor.data, dim=1)correct = pred.eq(label.data).cpu().sum()sum_test_loss += loss.item()sum_test_corre += correct.item()test_loss = sum_test_loss * 1.0 / len(test_data_loder)test_corre = sum_test_corre * 100.0 / len(test_data_loder) / 300test_loss_base.append(test_loss)test_corre_base.append(test_corre)print(f"测试中:当前迭代的测试集损失为:{test_loss},正确率为:{test_corre}")return loss_base,corre_base,test_loss_base,test_corre_base# ------------------------------------------()--------------------------------------if __name__ == '__main__':[train_loss,train_corre,test_loss,test_corr] = train(epoch,net)fig, axes = plt.subplots(2, 2)axes[0, 0].plot(list(range(1, len(train_loss)+1 )), train_loss,color ='r')axes[0, 0].set_title('train loss')axes[0, 1].plot(list(range(1, len(train_corre) + 1)), train_corre, color ='r')axes[0, 1].set_title('train corre')axes[1, 0].plot(list(range(1, len(test_loss) + 1)), test_loss,color ='r')axes[1, 0].set_title('test loss')axes[1, 1].plot(list(range(1, len(test_corr) + 1)), test_corr,color ='r')axes[1, 1].set_title('test corre')plt.show()# torch.save(net.state_dict(), './save_model/example1.pt')