优化算法
mini-batch梯度下降法
- 当一个数据集其数据量非常大的时候,比如上百万上千万的数据集,如果采用普通的梯度下降法,那么运算速度会非常慢,因为如果使用梯度下降法在每一次迭代的时候,都需要将这整个上百万的数据给执行一遍
- 所以我们可以将我们的大的数据分成一个一个小一点的数据集,然后分批次处理,比如我们有100万个数据,那么我们可以将其分成1000份,每份1000个数据,这里的一份就是所谓的一个mini-batch
- 然后我们用循环来遍历这1000个子集,针对每一次的子集做一次梯度下降,更新W和b的值。然后对下一个子集继续执行上述操作,这样在遍历完所有的mini-batch后,就相当于我们做了1000次迭代,将所有样本都遍历一遍的行为叫一个epoch
- 在批量梯度下降法中,我们运行一次epoch就相当于运行了一次梯度下降迭代,但是在mini-batch中,我们运行一次epoch相当于运行了1000次迭代,速度当然迥然不同,很明显后者更快
- 我们来看到mini- batch的代价曲线
-
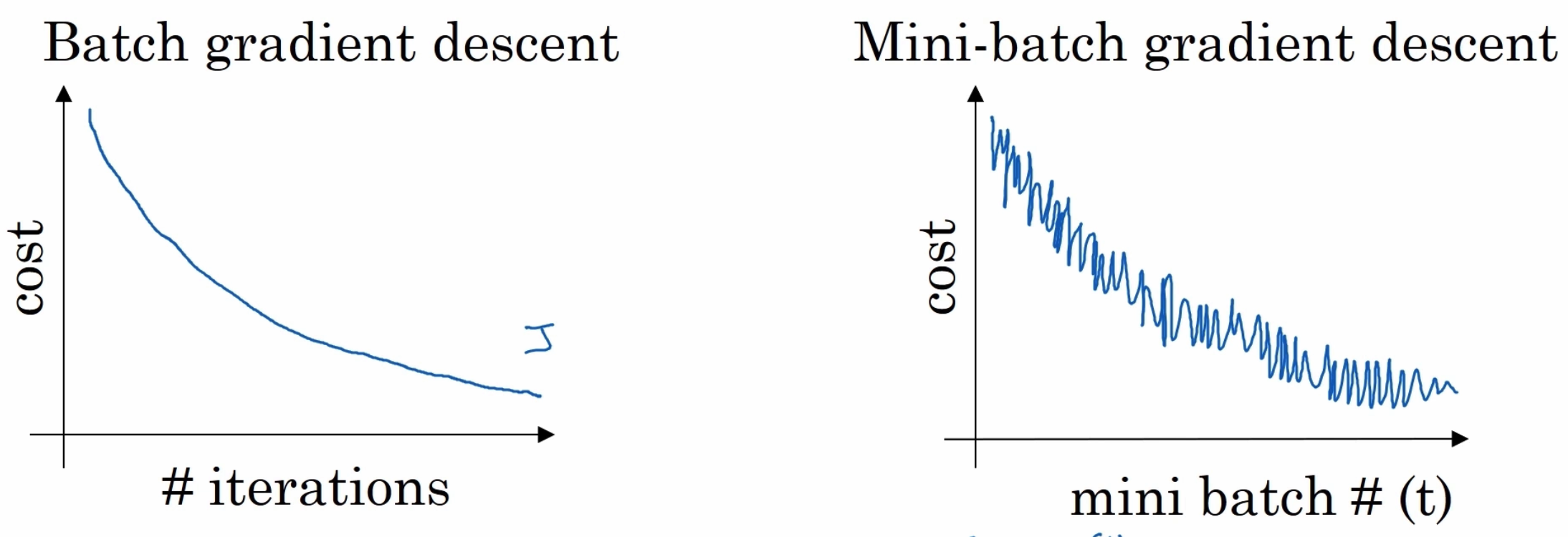
- 左边的是批量梯度下降的代价曲线,右边则是mini batch代价曲线曲线
- 可以很明显的看出,左边的代价曲线很顺滑的进行了下降,这表明每一次迭代我们的预测值的误差在一次次缩小
- 而右边的代价曲线从整体而言也是呈下降趋势的,但是在细节之处可以看出多了很多噪声,因为mini batch梯度下降法是采用分批次下降的,每份mini batch的质量都可能不一样,所以在每次运行的时候,可能某段数据质量高,从而预测的特别好,所以在那一段是下降的,而某段数据质量低,预测的效果不好,所以在那段是上升的,但没关系,因为总体而言是呈下降趋势的
- 在mini batch这有一个超参数,也就是每份的大小,在刚刚拿个例子当中,我们设定的每份大小为1000,也就是一份有1000个数据,当每份大小设置成样本总数m的时候,那么这就是一个批量梯度下降,因为一次运行所有的样本。
- 而如果设置的每份大小是1,则就是随机梯度下降法了
- 随机梯度下降法有一个缺点就是你失去了向量化的优势,因为每次迭代只会运行一个样本,所以效率会变低很多
- 所以最好的办法就是让mini batch获得一个最合适的值
如何选择合适的mini batch值?
- 数据集 < 2000:批量梯度下降法
- 因为如果数据集小于2000的话,就没有使用的mini batch的必要了,因为数据量很少,可以直接使用批量下降,运行速度也很快,而且也可以避免噪声所带来的影响
- 数据集 > 2000:mini batch选择一个2的幂数值
- 因为和计算机的存储机制有关,采用2的幂数值会运行的更快一点,例如64,128,256等等
- 应该选取能一次性存放进CPU或GPU的数值
指数加权平均
- 指数加权平均是根据权重来计算近似平均值的
- 举个例子
- 比如我们现在有100天的温度值,要求这100天的平均温度值
- 24,25,24,26,34,28,33,33,34,35…32
- 我们可以使用平均值公式来计算, 24 + 25 + . . . + 32 100 \frac{24+25+...+32}{100} 10024+25+...+32
- 但是这种方法对于非常大的数据量来说,需要的内存空间就比较大,因为你需要一次性将所有的数据都存入内存当中再计算平均值
- 而指数加权平均就是一种求近似平均的方法
- 公式为: v t = β v t − 1 + ( 1 − β ) θ t v_t=\beta v_{t-1}+(1-\beta)\theta_t vt=βvt−1+(1−β)θt
- 其中 v t v_t vt为到t时刻的平均值,在上面的例子来说就到第t天的温度平均值, θ t \theta_t θt为t时刻的温度,其中的 β \beta β为超参数
- 本质就是以指数式递减加权的移动平均。各数值的加权而随时间而指数式递减,越近期的数据加权越重,但较旧的数据也给予一定的加权
- 我们来如下计算步骤
-
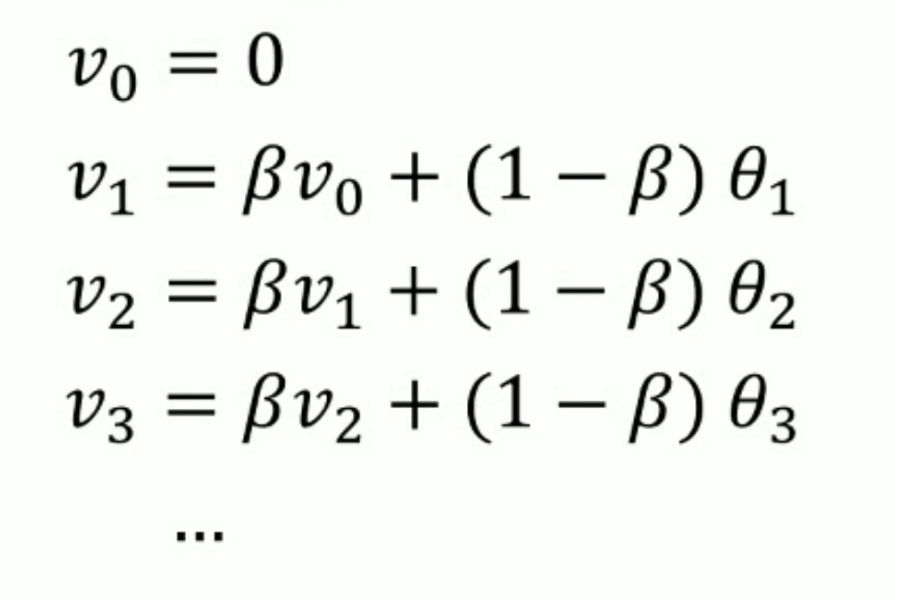
- 可以看出,指数加权平均的求解过程实际上是一个递推的过程,这样就会有一个优势
- 在于每当我要求从0到某一时刻(n)的平均值的时候,我并不需要像普通求解平均值的作为,保留所有的时刻值,类和然后除以n
- 而是只需要保留0-(n-1)时刻的平均值和n时刻的温度值即可。也就是每次只需要保留常数值,然后进行运算即可,这对于深度学习中的海量数据来说,是一个很好的减少内存和空间的做法
偏差修正
- 由于一开始v0都是初始化为0,导致在初始计算时会计算差别很大,如上述每月温度,假设beta为0.9,则第一天的温度为: v 1 = 0.9 ∗ 0 + ( 1 − 0.9 ) 24 = 2.4 v_1=0.9*0+(1-0.9)24=2.4 v1=0.9∗0+(1−0.9)24=2.4可以明显看出,这与第一天温度相差非常大,于是为了弥补这一误差,所以采用如下公式来更新 v t v_t vt的值 v t = v t 1 − β t = β v t − 1 + ( 1 − β ) θ t 1 − β t v_t=\frac{v_t}{1-\beta^t}=\frac{\beta v_{t-1}+(1-\beta)\theta_t}{1-\beta^t} vt=1−βtvt=1−βtβvt−1+(1−β)θt通过该公式重新计算 v 1 v_1 v1的值: v 1 = 0.9 ∗ 0 + ( 1 − 0.9 ) ∗ 24 1 − 0. 9 1 = 24 v_1=\frac{0.9*0+(1-0.9)*24}{1-0.9^1}=24 v1=1−0.910.9∗0+(1−0.9)∗24=24
- 可以看出,经过偏差修正后的数值回归到了一个正常的水平,并且随着 t t t的数值越大, β t \beta^t βt会越来越趋向于0,整个分母则会越来越趋向于1,于是偏差修正也会越来越无效。
动量梯度下降法
- 动量梯度下降法就是采用了指数加权平均之后的梯度下降法
如何计算
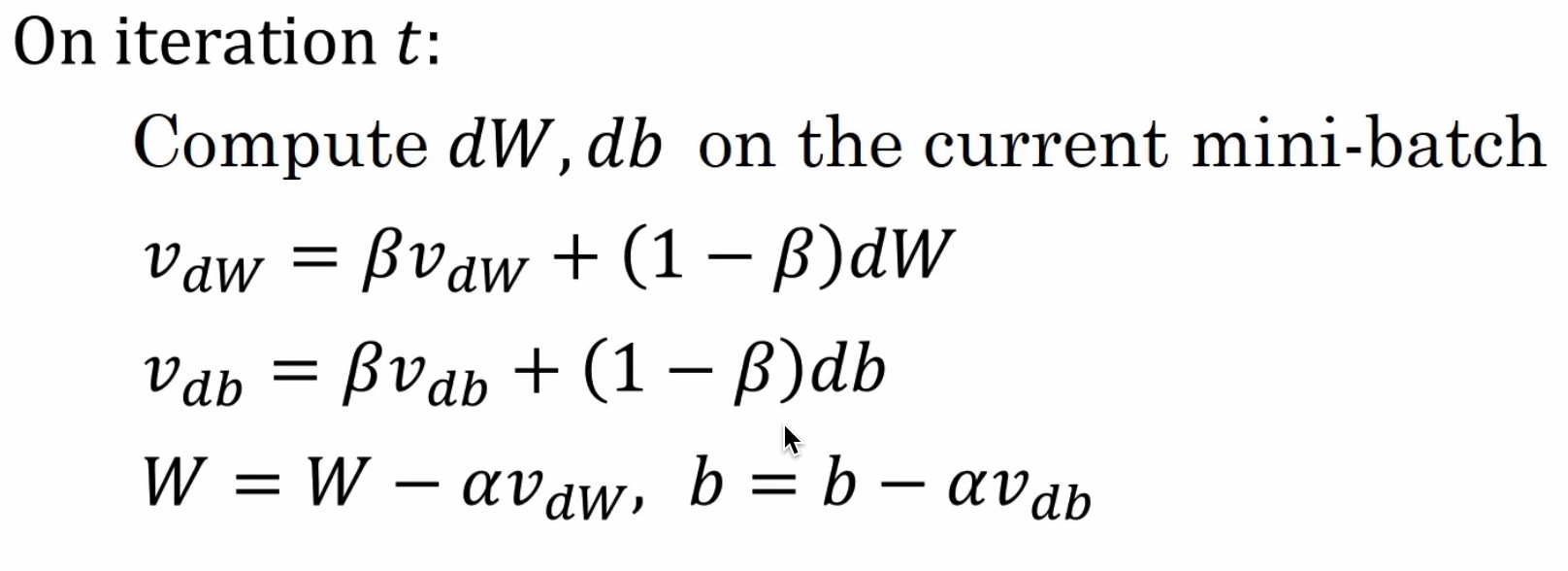
RMSprop
如何计算
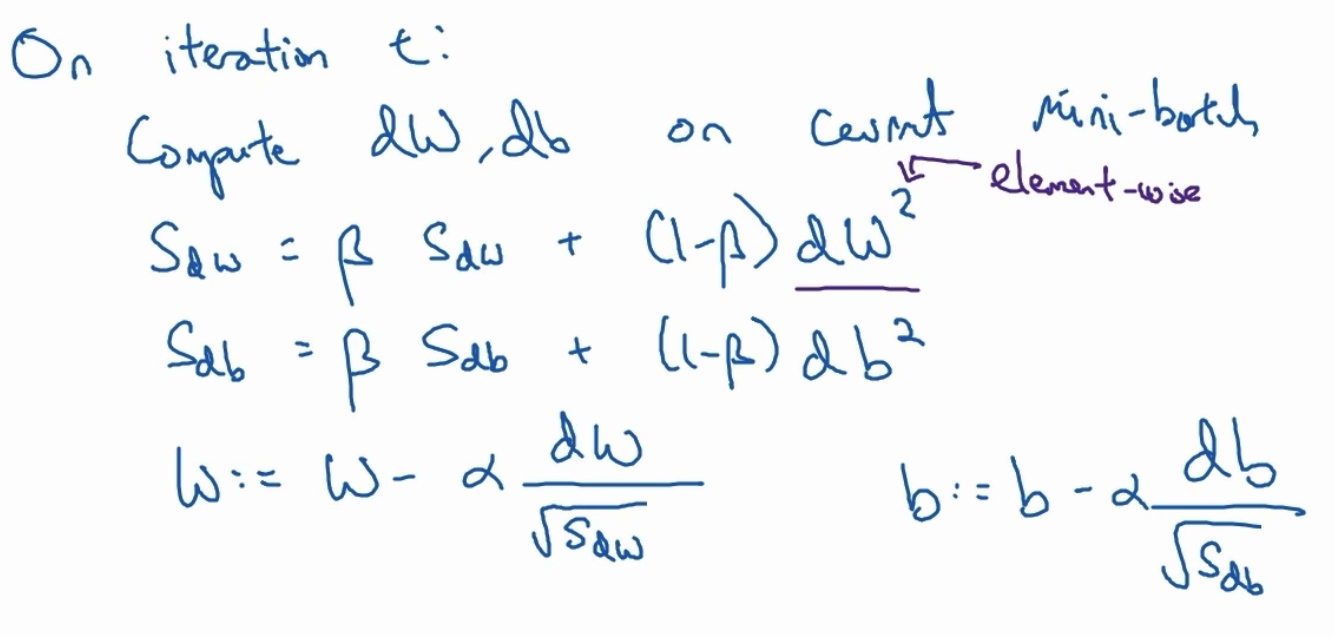
Adam
- Adam是由动量梯度下降法和RMSprop组合而成
计算方法
- 对于所有的迭代下来说
- v d w = β 1 v d w + ( 1 − β 1 ) d w , v d b = β 1 v d b + ( 1 − β 1 ) d b v_{dw}=\beta_1v_{dw}+(1-\beta_1)dw,v_{db}=\beta_1v_{db}+(1-\beta_1)db vdw=β1vdw+(1−β1)dw,vdb=β1vdb+(1−β1)db
- s d w = β 2 s d w + ( 1 − β 2 ) d w 2 , s d b = β 2 s d b + ( 1 − β 2 ) d b 2 s_{dw}=\beta_2s_{dw}+(1-\beta_2)dw^2,s_{db}=\beta_2s_{db}+(1-\beta_2)db^2 sdw=β2sdw+(1−β2)dw2,sdb=β2sdb+(1−β2)db2
- v d w c o r r e n t e d = v d w 1 − β 1 t , v d b c o r r e n t e d = v d b 1 − β 1 t v_{dw}^{corrented}=\frac{v_{dw}}{1-\beta_1^t},v_{db}^{corrented}=\frac{v_{db}}{1-\beta_1^t} vdwcorrented=1−β1tvdw,vdbcorrented=1−β1tvdb
- s d w c o r r e n t e d = s d w 1 − β 2 t , s d b c o r r e n t e d = s d b 1 − β 2 t s_{dw}^{corrented}=\frac{s_{dw}}{1-\beta_2^t},s_{db}^{corrented}=\frac{s_{db}}{1-\beta_2^t} sdwcorrented=1−β2tsdw,sdbcorrented=1−β2tsdb
- w : = w − α v d w c o r r e n t e d s d w c o r r e n t e d + ε , b : = b − α v d b c o r r e n t e d s d b c o r r e n t e d + ε w:=w-\alpha\frac{v_{dw}^{corrented}}{\sqrt{s_{dw}^{corrented}+\varepsilon}},b:=b-\alpha\frac{v_{db}^{corrented}}{\sqrt{s_{db}^{corrented}+\varepsilon}} w:=w−αsdwcorrented+εvdwcorrented,b:=b−αsdbcorrented+εvdbcorrented
超参数建议
- alpha:需要我们自己来确定
- beta1:一般选做0.9,也可以自己尝试其他的值
- beta2:论文作者所推荐的值为0.999,也可以自行调整
- epsilon:论文作者推荐为10e-8,也可以自行调整
学习率衰减
为什么要使用学习率衰减?
- 在使用mini-batch梯度下降法的时候,因为我们的小批量梯度下降法会产生噪声(小批量梯度下降法每个批次的质量都不一样,所以会产生噪声),所以当我们使用一个固定的学习率的时候,刚开始的时候可能会正常的梯度下降,但是一旦快靠近我们的极小值点的时候,由于学习率是固定的,一旦设大了,则会一直围绕着我们的极小值点周围转,而不会正真的靠近,如下图所示
-
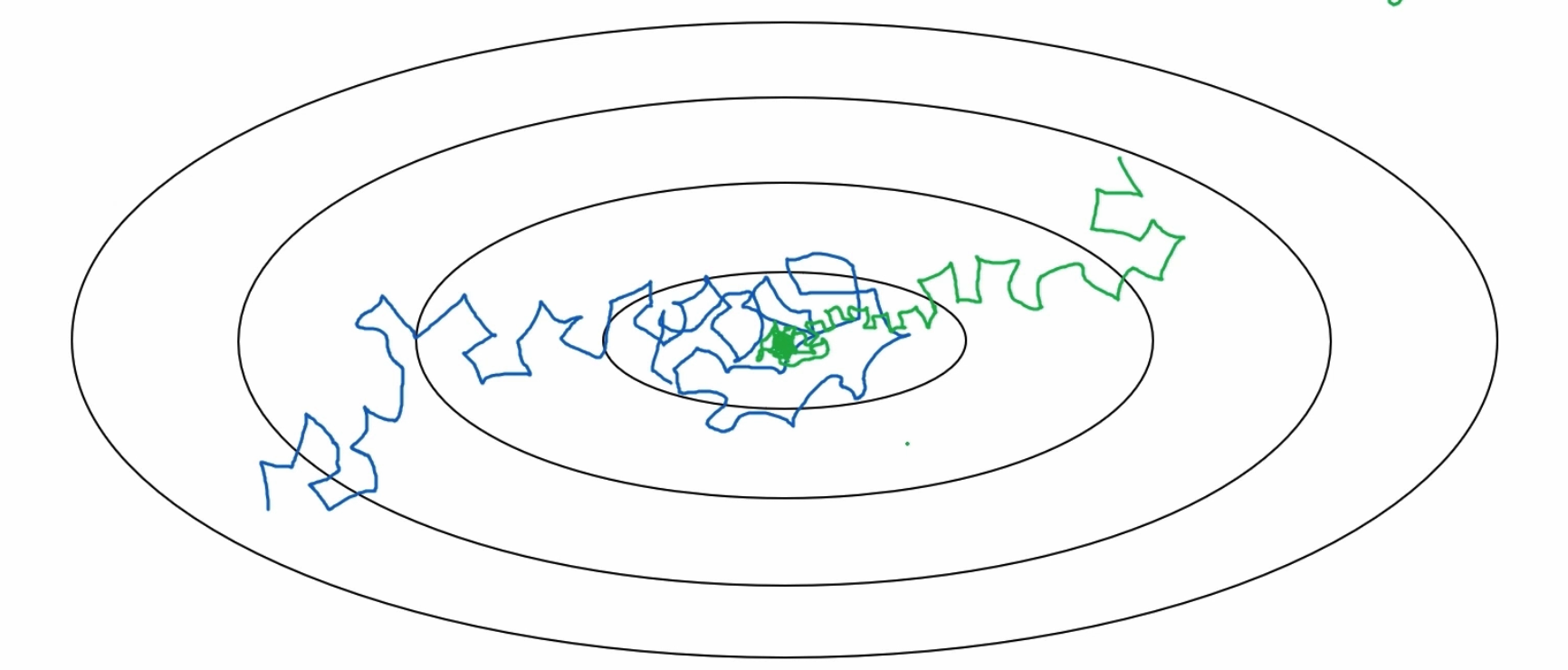
- 而如果我们将学习率一开始就设置成一个固定小的一个值,那么需要迭代的次数就会非常多,大大降低了算法的效率,从而浪费资源。
- 所以我们希望我们的学习率能够自动的根据梯度下降的情况,来衰减自己的大小,从而减少上述情况发生
学习率衰退方法
- 这里有一个常用的公式: α = 1 1 + d e c a y R a t e ∗ e p o c h N u m α 0 \alpha=\frac{1}{1+decayRate * epochNum}\alpha_0 α=1+decayRate∗epochNum1α0
- 参数意义如下:
- decayRate:衰退率,一个超参数,可以自行调整
- epochNum:当前迭代的第几次
- alpha0:初始学习率值
- 假如初始学习率为0.2,衰退率为1,则每轮迭代的值如下
- α = 1 1 + 1 ∗ 1 0.2 = 0.1 \alpha=\frac{1}{1+1 * 1}0.2=0.1 α=1+1∗110.2=0.1
- α = 1 1 + 1 ∗ 2 0.2 = 0.06 \alpha=\frac{1}{1+1 * 2}0.2=0.06 α=1+1∗210.2=0.06
- α = 1 1 + 1 ∗ 3 0.2 = 0.05 \alpha=\frac{1}{1+1 * 3}0.2=0.05 α=1+1∗310.2=0.05
- …
- 参数意义如下:
- 指数衰退学习率公式: α = 0.9 5 e p o c h N u m α 0 \alpha=0.95^{epochNum}\alpha0 α=0.95epochNumα0
- 参数意义同上
- 常用公式三: α = k e p o c h N u m α 0 \alpha=\frac{k}{\sqrt{epochNum}}\alpha0 α=epochNumkα0
- 参数意义:
- k:常数超参数,可自行调整
- 参数意义: