情感分析
情感分析是 NLP 一种应用场景,模型判断输入语句是积极的还是消极的,实际应用适用于评论、客服等多场景。情感分析通过 transformer 架构中的 encoder 层再加上情感分类层进行实现。
安装依赖
需要安装 Poytorch NLP 相关依赖
pip install torchtext==0.6.0
下载预训练的英文模型
import os
import urllib.request
import zipfile
import tarfile#下载fastText官方英语已学习模型(650MB)。
url = "https://dl.fbaipublicfiles.com/fasttext/vectors-english/wiki-news-300d-1M.vec.zip"
save_path = "./data/wiki-news-300d-1M.vec.zip"
if not os.path.exists(save_path):urllib.request.urlretrieve(url, save_path)#解压缩文件夹“data”中的“/维基-news-300d- 1m .vec.zip”zip = zipfile.ZipFile("./data/wiki-news-300d-1M.vec.zip")
zip.extractall("./data/") #解压缩ZIP
zip.close() #关闭ZIP文件准备数据
准备训练数据、测试数据,去掉空格以及标点符号,由于是英文数据,通过空格进行分词。
##保存为tsv格式的文件
import glob
import os
import io
import string#创建训练数据的tsv文件f = open('./data/IMDb_train.tsv', 'w')path = './data/aclImdb/train/pos/'
for fname in glob.glob(os.path.join(path, '*.txt')):with io.open(fname, 'r', encoding="utf-8") as ff:text = ff.readline()#如果包含制表符就删除text = text.replace('\t', " ")text = text+'\t'+'1'+'\t'+'\n'f.write(text)path = './data/aclImdb/train/neg/'
for fname in glob.glob(os.path.join(path, '*.txt')):with io.open(fname, 'r', encoding="utf-8") as ff:text = ff.readline()#如果包含制表符就删除text = text.replace('\t', " ")text = text+'\t'+'0'+'\t'+'\n'f.write(text)f.close()#创建测试数据f = open('./data/IMDb_test.tsv', 'w')path = './data/aclImdb/test/pos/'
for fname in glob.glob(os.path.join(path, '*.txt')):with io.open(fname, 'r', encoding="utf-8") as ff:text = ff.readline()#如果包含制表符就删除text = text.replace('\t', " ")text = text+'\t'+'1'+'\t'+'\n'f.write(text)path = './data/aclImdb/test/neg/'for fname in glob.glob(os.path.join(path, '*.txt')):with io.open(fname, 'r', encoding="utf-8") as ff:text = ff.readline()#如果包含制表符就删除text = text.replace('\t', " ")text = text+'\t'+'0'+'\t'+'\n'f.write(text)f.close()import string
import re#将下列符号替换成空格符(除了句号和逗号之外)。
print("分隔符:", string.punctuation)
# !"#$%&'()*+,-./:;<=>?@[\]^_`{|}~#预处理def preprocessing_text(text):#预处理text = re.sub('<br />', '', text)#将逗号和句号以外的标点符号替换成空格符for p in string.punctuation:if (p == ".") or (p == ","):continueelse:text = text.replace(p, " ")#在句号和逗号前后插入空格符text = text.replace(".", " . ")text = text.replace(",", " , ")return text#用空格将单词隔开(这里的数据是英文的,用空格进行分隔)def tokenizer_punctuation(text):return text.strip().split()#定义用于预处理和分词处理的函数
def tokenizer_with_preprocessing(text):text = preprocessing_text(text)ret = tokenizer_punctuation(text)return ret#确认执行结果
print(tokenizer_with_preprocessing('I like cats.'))创建 Dataloader
创建两种类型的数据,TEXT:输入的评论,LABEL:类型标签
##定义在读取数据时,对读取内容所做的处理
import torchtext# #同时准备文章和标签两种字段
max_length = 256
TEXT = torchtext.data.Field(sequential=True, tokenize=tokenizer_with_preprocessing, use_vocab=True,lower=True, include_lengths=True, batch_first=True, fix_length=max_length, init_token="<cls>", eos_token="<eos>")
LABEL = torchtext.data.Field(sequential=False, use_vocab=False)
#从data文件夹中读取各个tsv文件
train_val_ds, test_ds = torchtext.data.TabularDataset.splits(path='./data/', train='IMDb_train.tsv',test='IMDb_test.tsv', format='tsv',fields=[('Text', TEXT), ('Label', LABEL)])#确认执行结果
print('训练和验证数据的数量', len(train_val_ds))
print('第一个训练和验证的数据', vars(train_val_ds[0]))
切分训练数据和验证数据,20000 条训练集、5000 条验证:
import random
#使用torchtext.data.Dataset的split函数将Dataset切分为训练数据和验证数据train_ds, val_ds = train_val_ds.split(split_ratio=0.8, random_state=random.seed(1234))#确认执行结果
print('训练数据的数量', len(train_ds))
print('验证数据的数量', len(val_ds))
print('第一个训练数据', vars(train_ds[0]))载入已经选练好的 fasttext 模型,并根据模型创建词汇表
#使用torchtext读取作为单词向量from torchtext.vocab import Vectorsenglish_fasttext_vectors = Vectors(name='data/wiki-news-300d-1M.vec')#确认单词向量中的内容
print("1个单词向量的维数:", english_fasttext_vectors.dim)
print("单词数量:", len(english_fasttext_vectors.itos))#单词数量
TEXT.build_vocab(train_ds, vectors=english_fasttext_vectors, min_freq=10)创建 dataloader
# DataLoaderを作成します(torchtextの文脈では単純にiteraterと呼ばれています)
train_dl = torchtext.data.Iterator(train_ds, batch_size=24, train=True)val_dl = torchtext.data.Iterator(val_ds, batch_size=24, train=False, sort=False)test_dl = torchtext.data.Iterator(test_ds, batch_size=24, train=False, sort=False)# 動作確認 検証データのデータセットで確認
batch = next(iter(val_dl))
print(batch.Text)
print(batch.Label)创建分类任务
创建 Transformer 模型
import math
import numpy as np
import randomimport torch
import torch.nn as nn
import torch.nn.functional as F
import torchtext# Setup seeds
torch.manual_seed(1234)
np.random.seed(1234)
random.seed(1234)class Embedder(nn.Module):'''将id代表的单词转换为向量'''def __init__(self, text_embedding_vectors):super(Embedder, self).__init__()self.embeddings = nn.Embedding.from_pretrained(embeddings=text_embedding_vectors, freeze=True)#指定freeze=True,可以防止反向传播造成的更新,保证数据不发生变化def forward(self, x):x_vec = self.embeddings(x)return x_vec#确认代码的执行结果#确认代码的执行结果
from utils.dataloader import get_IMDb_DataLoaders_and_TEXT
train_dl, val_dl, test_dl, TEXT = get_IMDb_DataLoaders_and_TEXT(max_length=256, batch_size=24)#准备小批次
batch = next(iter(train_dl))#构建模型
net1 = Embedder(TEXT.vocab.vectors)#输入和输出
x = batch.Text[0]
x1 = net1(x) #将单词转换为向量print("输入的张量尺寸:", x.shape)
print("输出的张量尺寸:", x1.shape)## 定义 positionencoder
class PositionalEncoder(nn.Module):'''添加用于表示输入单词的位置的向量信息'''def __init__(self, d_model=300, max_seq_len=256):super().__init__()self.d_model = d_model #单词向量的维度#创建根据单词的顺序(pos)和填入向量的维度的位置(i)确定的值的表pepe = torch.zeros(max_seq_len, d_model)#如果GPU可用,则发送到GPU中,这里暂且省略此操作。在实际进行学习时可以使用# device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")# pe = pe.to(device)for pos in range(max_seq_len):for i in range(0, d_model, 2):pe[pos, i] = math.sin(pos / (10000 ** ((2 * i)/d_model)))pe[pos, i + 1] = math.cos(pos /(10000 ** ((2 * (i + 1))/d_model)))#将作为小批量维度的维度添加到pe的开头self.pe = pe.unsqueeze(0)#关闭梯度的计算self.pe.requires_grad = Falsedef forward(self, x):#将输入x与Positonal Encoding相加#x比pe要小,因此需要将其放大ret = math.sqrt(self.d_model)*x + self.pereturn ret#创建Attention
class Attention(nn.Module):'''实际上,Transformer中使用的是多头Attention这里为了便于读者理解,采用的是单一Attention结构'''def __init__(self, d_model=300):super().__init__()#在Self-Attention GAN中使用的是1dConv,这次在全连接层中对特征量进行变换self.q_linear = nn.Linear(d_model, d_model)self.v_linear = nn.Linear(d_model, d_model)self.k_linear = nn.Linear(d_model, d_model)#输出时使用的全连接层self.out = nn.Linear(d_model, d_model)#用于调整Attention大小的变量self.d_k = d_modeldef forward(self, q, k, v, mask):#在全连接层中进行特征量变换k = self.k_linear(k)q = self.q_linear(q)v = self.v_linear(v)#计算Attention的值#直接与各个值相加得到的结果太大,因此除以root(d_k)来调整weights = torch.matmul(q, k.transpose(1, 2)) / math.sqrt(self.d_k)#在这里计算maskmask = mask.unsqueeze(1)weights = weights.masked_fill(mask == 0, -1e9)#使用softmax进行归一化处理normlized_weights = F.softmax(weights, dim=-1)#将Attention与Value相乘output = torch.matmul(normlized_weights, v)#使用全连接层进行特征量变换output = self.out(output)return output, normlized_weights#创建feedforward 网络
class FeedForward(nn.Module):def __init__(self, d_model, d_ff=1024, dropout=0.1):'''负责将来自Attention层的输出通过两个全连接层进行特征量变换的组件'''super().__init__()self.linear_1 = nn.Linear(d_model, d_ff)self.dropout = nn.Dropout(dropout)self.linear_2 = nn.Linear(d_ff, d_model)def forward(self, x):x = self.linear_1(x)x = self.dropout(F.relu(x))x = self.linear_2(x)return x#创建 Transformer
class TransformerBlock(nn.Module):def __init__(self, d_model, dropout=0.1):super().__init__()# LayerNormalization層层# https://pytorch.org/docs/stable/nn.html?highlight=layernormself.norm_1 = nn.LayerNorm(d_model)self.norm_2 = nn.LayerNorm(d_model)# Attention层self.attn = Attention(d_model)#Attention后面的两个全连接层self.ff = FeedForward(d_model)# Dropoutself.dropout_1 = nn.Dropout(dropout)self.dropout_2 = nn.Dropout(dropout)def forward(self, x, mask):#归一化与Attentionx_normlized = self.norm_1(x)output, normlized_weights = self.attn(x_normlized, x_normlized, x_normlized, mask)x2 = x + self.dropout_1(output)#归一化与全连接层x_normlized2 = self.norm_2(x2)output = x2 + self.dropout_2(self.ff(x_normlized2))return output, normlized_weights## 创建分类
class ClassificationHead(nn.Module):'''使用Transformer_Block的输出结果,最终实现分类处理'''def __init__(self, d_model=300, output_dim=2):super().__init__()#使用Transformer_Block的输出结果,最终实现分类处理self.linear = nn.Linear(d_model, output_dim) #output_dim是正面/负面这两个维度#权重的初始化处理nn.init.normal_(self.linear.weight, std=0.02)nn.init.normal_(self.linear.bias, 0)def forward(self, x):x0 = x[:, 0, :] #取出每个小批次的每个文章的开头的单词的特征量(300 维)out = self.linear(x0)return out
## 整合代码放到 TransformerClassificationclass TransformerClassification(nn.Module):'''#最终的Transformer模型的类'''def __init__(self, text_embedding_vectors, d_model=300, max_seq_len=256, output_dim=2):super().__init__()#构建模型self.net1 = Embedder(text_embedding_vectors)self.net2 = PositionalEncoder(d_model=d_model, max_seq_len=max_seq_len)self.net3_1 = TransformerBlock(d_model=d_model)self.net3_2 = TransformerBlock(d_model=d_model)self.net4 = ClassificationHead(output_dim=output_dim, d_model=d_model)def forward(self, x, mask):x1 = self.net1(x) #将单词转换为向量x2 = self.net2(x1) #对Positon信息进行加法运算x3_1, normlized_weights_1 = self.net3_1(x2, mask) #使用Self−Attention进行特征量变换x3_2, normlized_weights_2 = self.net3_2(x3_1, mask) #使用Self−Attention进行特征量变换x4 = self.net4(x3_2) #使用最终输出的第0个单词,输出分类0~1的标量return x4, normlized_weights_1, normlized_weights_2
训练并验证
#导入软件包
import numpy as np
import randomimport torch
import torch.nn as nn
import torch.optim as optimimport torchtext# 设定随机数的种子,
torch.manual_seed(1234)
np.random.seed(1234)
random.seed(1234)from utils.dataloader import get_IMDb_DataLoaders_and_TEXT#载入数据
train_dl, val_dl, test_dl, TEXT = get_IMDb_DataLoaders_and_TEXT(max_length=256, batch_size=64)#集中保存到字典对象中
dataloaders_dict = {"train": train_dl, "val": val_dl}from utils.transformer import TransformerClassification#构建模型
net = TransformerClassification(text_embedding_vectors=TEXT.vocab.vectors, d_model=300, max_seq_len=256, output_dim=2)#定义网络的初始化操作def weights_init(m):classname = m.__class__.__name__if classname.find('Linear') != -1:#Liner层的初始化nn.init.kaiming_normal_(m.weight)if m.bias is not None:nn.init.constant_(m.bias, 0.0)#设置为训练模式
net.train()#执行TransformerBlock模块的初始化操作
net.net3_1.apply(weights_init)
net.net3_2.apply(weights_init)print('网络设置完毕')#设置损失函数
criterion = nn.CrossEntropyLoss()#设置最优化算法
learning_rate = 2e-5
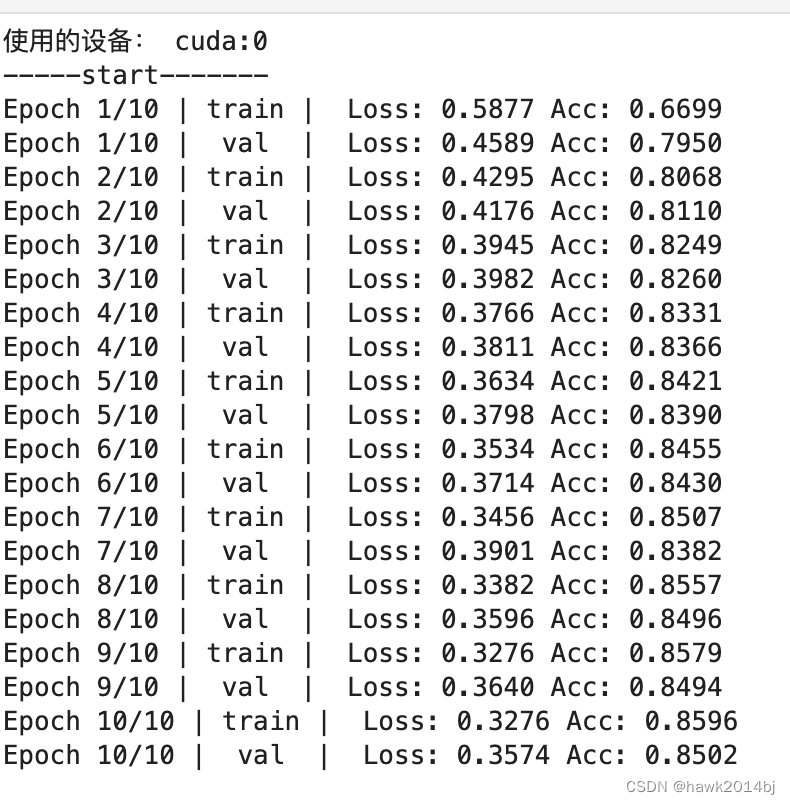
optimizer = optim.Adam(net.parameters(), lr=learning_rate)#创建用于训练模型的函数def train_model(net, dataloaders_dict, criterion, optimizer, num_epochs):#确认是否能够使用GPUdevice = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")print("使用的设备:", device)print('-----start-------')#将网络载入GPU中net.to(device)#如果网络结构比较固定,则开启硬件加速torch.backends.cudnn.benchmark = True#epoch循环for epoch in range(num_epochs):#以epoch为单位进行训练和验证的循环for phase in ['train', 'val']:if phase == 'train':net.train() #将模型设为训练模式else:net.eval() #将模型设为训练模式epoch_loss = 0.0 #epoch的损失和epoch_corrects = 0 #epoch的准确率#从数据加载器中读取小批次数据的循环for batch in (dataloaders_dict[phase]):#batch是Text和Lable的字典对象#如果GPU可以使用,则将数据输送到GPU中inputs = batch.Text[0].to(device) # 文章labels = batch.Label.to(device) # 标签#初始化optimizeroptimizer.zero_grad()#初始化optimizerwith torch.set_grad_enabled(phase == 'train'):# mask作成input_pad = 1 #在单词ID中'<pad>': 1input_mask = (inputs != input_pad)#输入Transformer中outputs, _, _ = net(inputs, input_mask)loss = criterion(outputs, labels) #计算损失值_, preds = torch.max(outputs, 1) #对标签进行预测#训练时进行反向传播if phase == 'train':loss.backward()optimizer.step()#计算结果epoch_loss += loss.item() * inputs.size(0) # lossの合計を更新#更新正确答案的合计数量epoch_corrects += torch.sum(preds == labels.data)#每轮epoch的loss和准确率epoch_loss = epoch_loss / len(dataloaders_dict[phase].dataset)epoch_acc = epoch_corrects.double() / len(dataloaders_dict[phase].dataset)print('Epoch {}/{} | {:^5} | Loss: {:.4f} Acc: {:.4f}'.format(epoch+1, num_epochs,phase, epoch_loss, epoch_acc))return net#执行学习和验证
num_epochs = 10
net_trained = train_model(net, dataloaders_dict,criterion, optimizer, num_epochs=num_epochs)