Comate_1">关于Baidu Comate智能代码助手
智能代码助手简介
代码助手可以快速的帮我们补充代码,修改代码,添加注释,翻译中英文,起变量函数名字等操作,十分的友好,这类代码助手现阶段有较多的产品,比如:
本文主要基于Baidu Comate智能代码助手进行高效代码编程体验,let’s go!!!
Comate_12">Baidu Comate智能代码助手简介
Baidu Comate智能代码助手 支持 100 多种语言和多种 IDE(集成开发环境)平台,可以推荐代码、生成代码注释、查找代码缺陷、给出优化方案,还能 深度解读企业与个人私域代码库 等。Baidu Comate智能代码助手,是基于文心大模型,打造的新一代编码辅助工具,具备代码智能、场景丰富、创造价值、广泛应用等多重优势,实现“帮你想、帮你写、帮你改”。 目前,面向个人开发者 已经免费 使用了。
Comate_18">注册Comate
点击Comate官方链接,进入官网,用百度账户登录,点击免费使用。
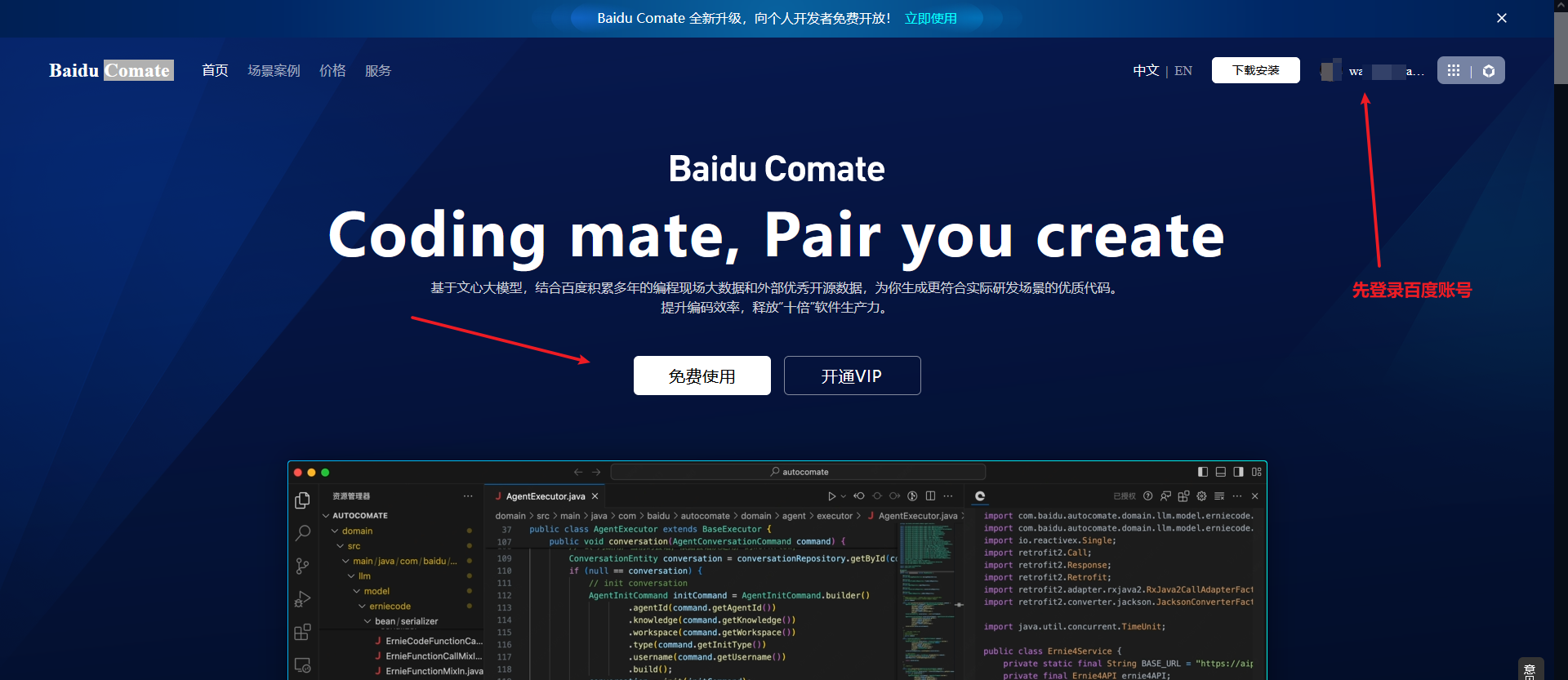
点击免费使用后,进入如下页面:
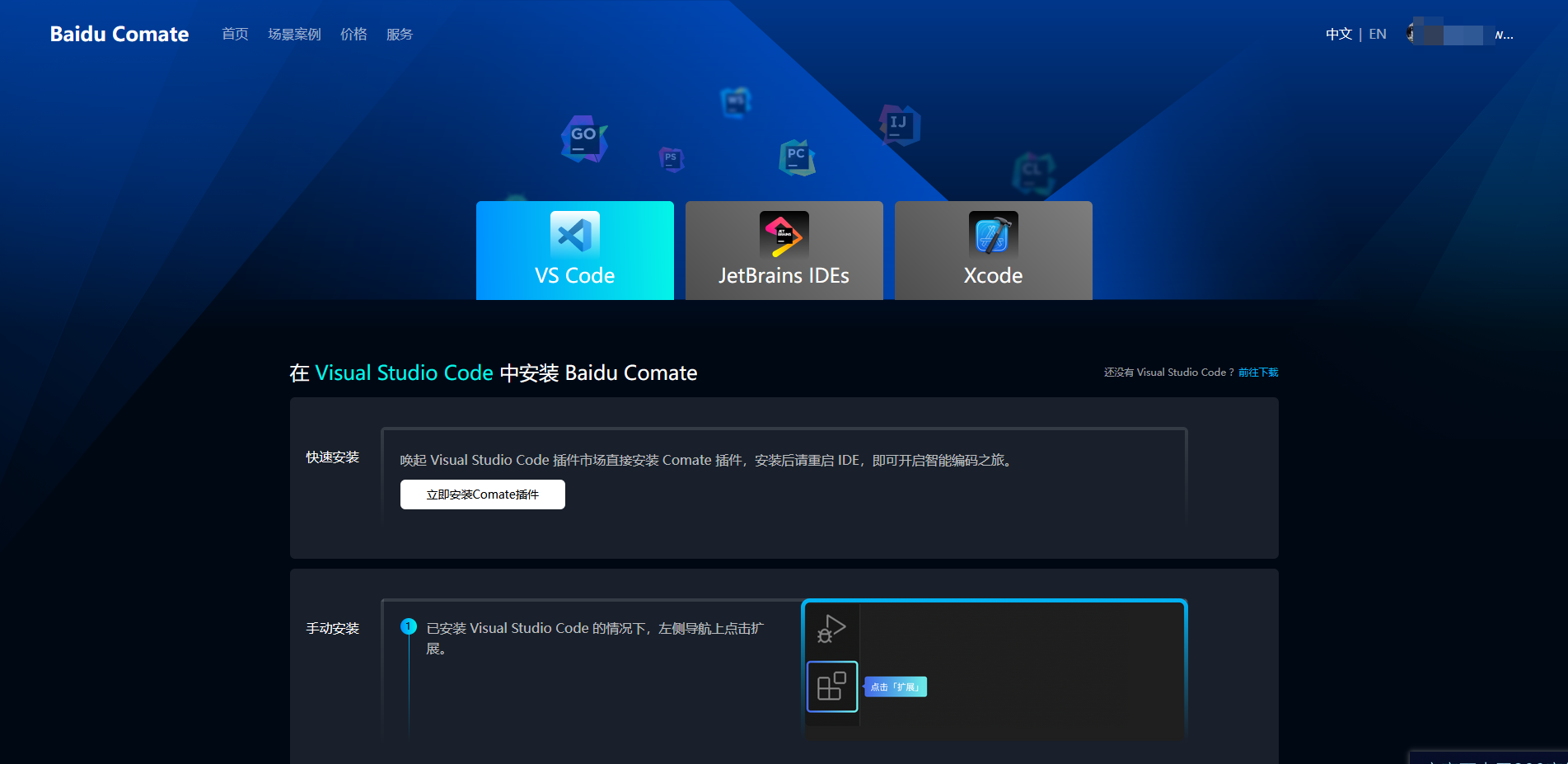
根据具体开发工具,安装对应的插件,比如我使用vscode,选择vscode后,点击安装comate插件。

会打开vscode,点击install
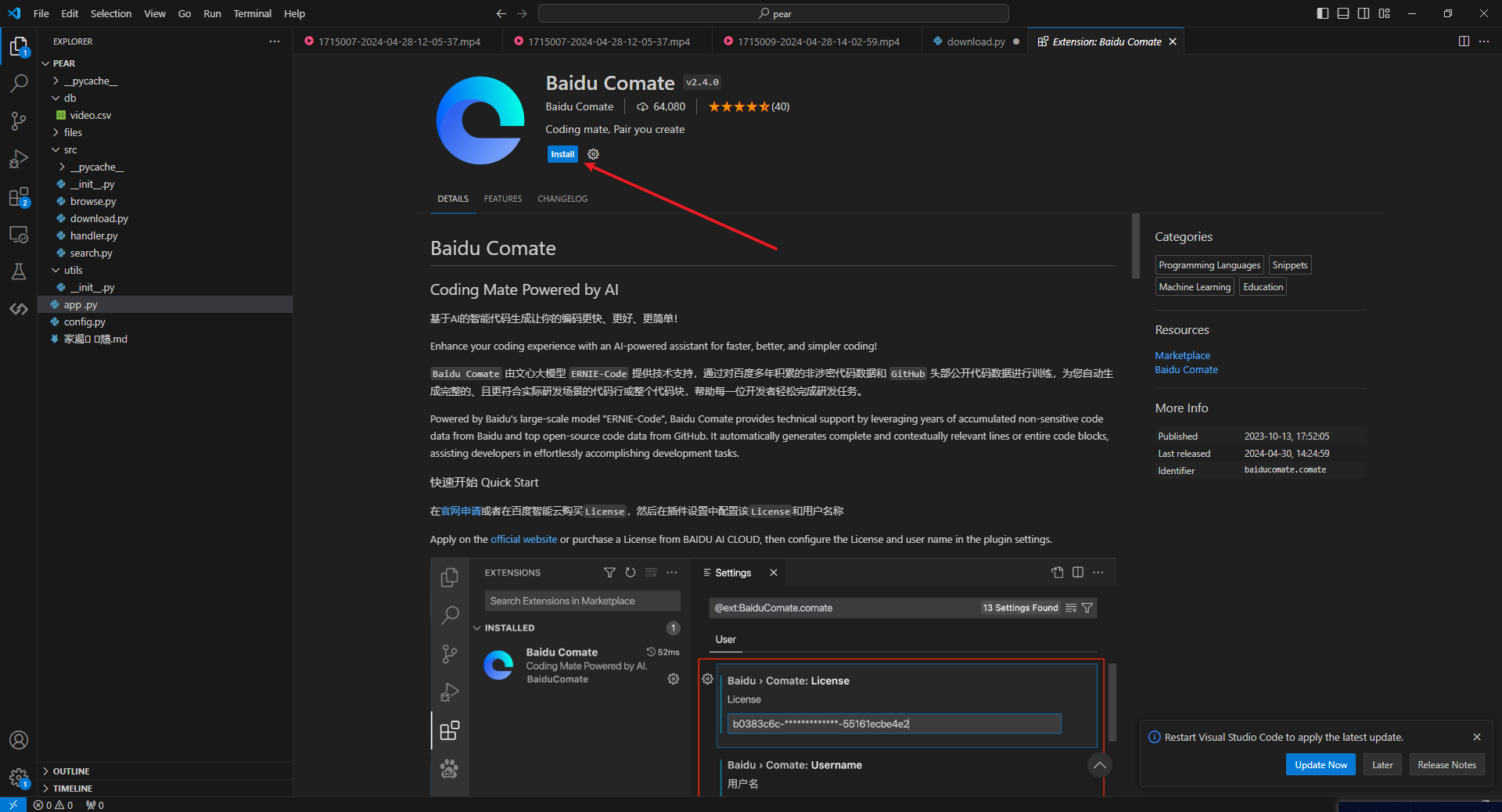
安装完成,右下角会提示登录百度账号
按照要求点击登录,会在浏览器弹出,百度页面,正常登录,点击确认即可。
点击确认后,会提示登录成功

Comate_39">Comate使用案例
注释生成代码
创建一个py文件–Comate代码测试.py
添加如下注释:
# 写一个插入排序的方法
写入
# 写一个插入排序的方法
def b
提示如下:
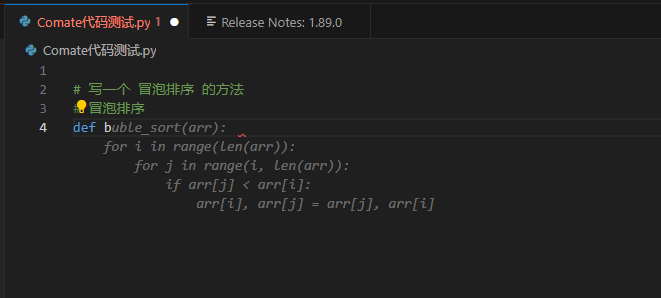
输入 tab键可以全部补全
如果不输入tab键,可以选 ctrl+向下箭头 进行逐行 补全
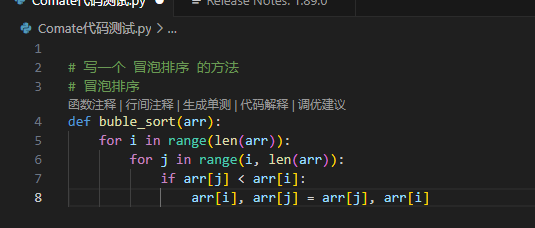
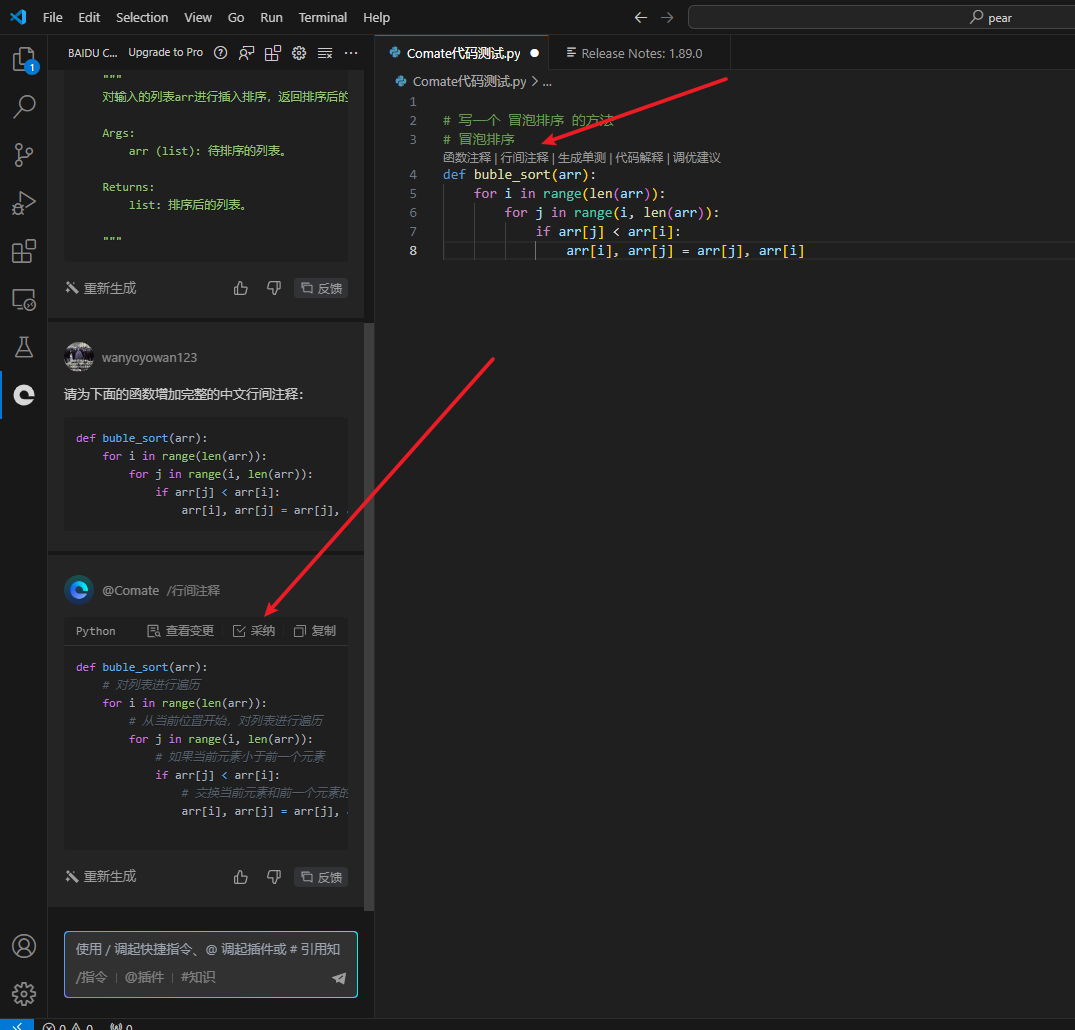
生成行间注释
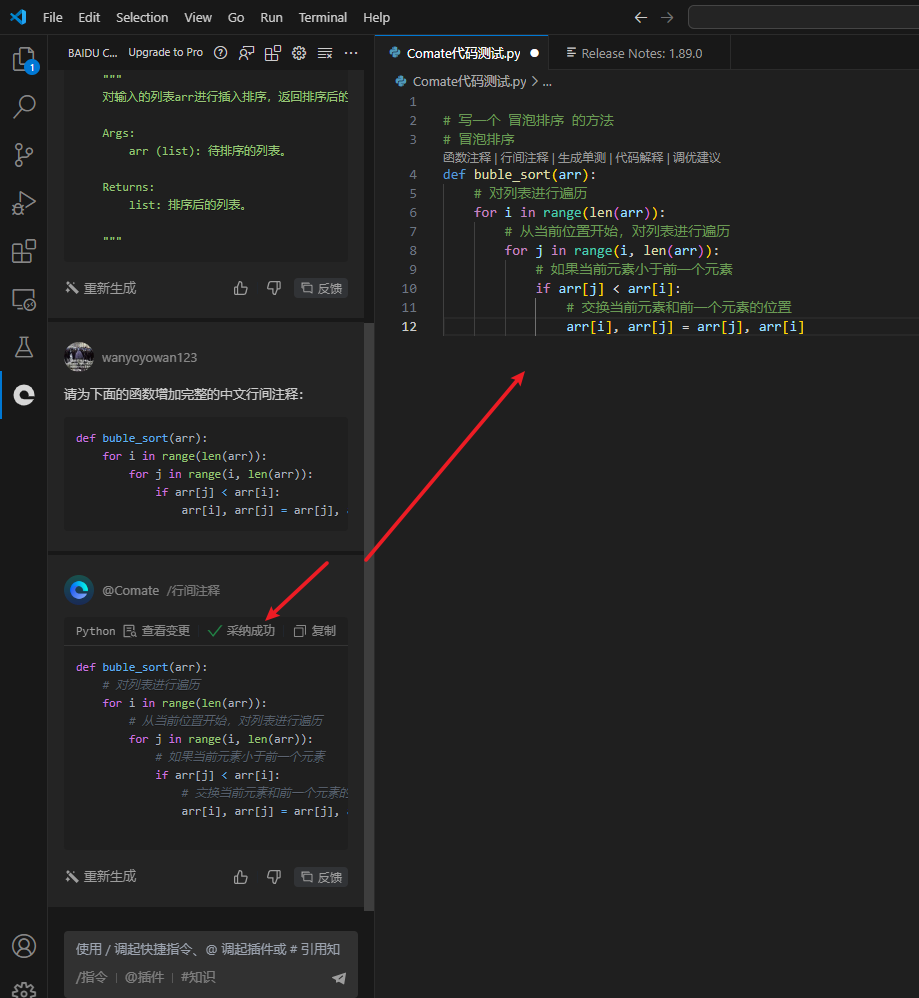
点击上面的行间注释,可以在插件左侧生成行间注释
点击左侧的采纳,会提示采纳成功,并生成完整注释,极大的提示了工作效率
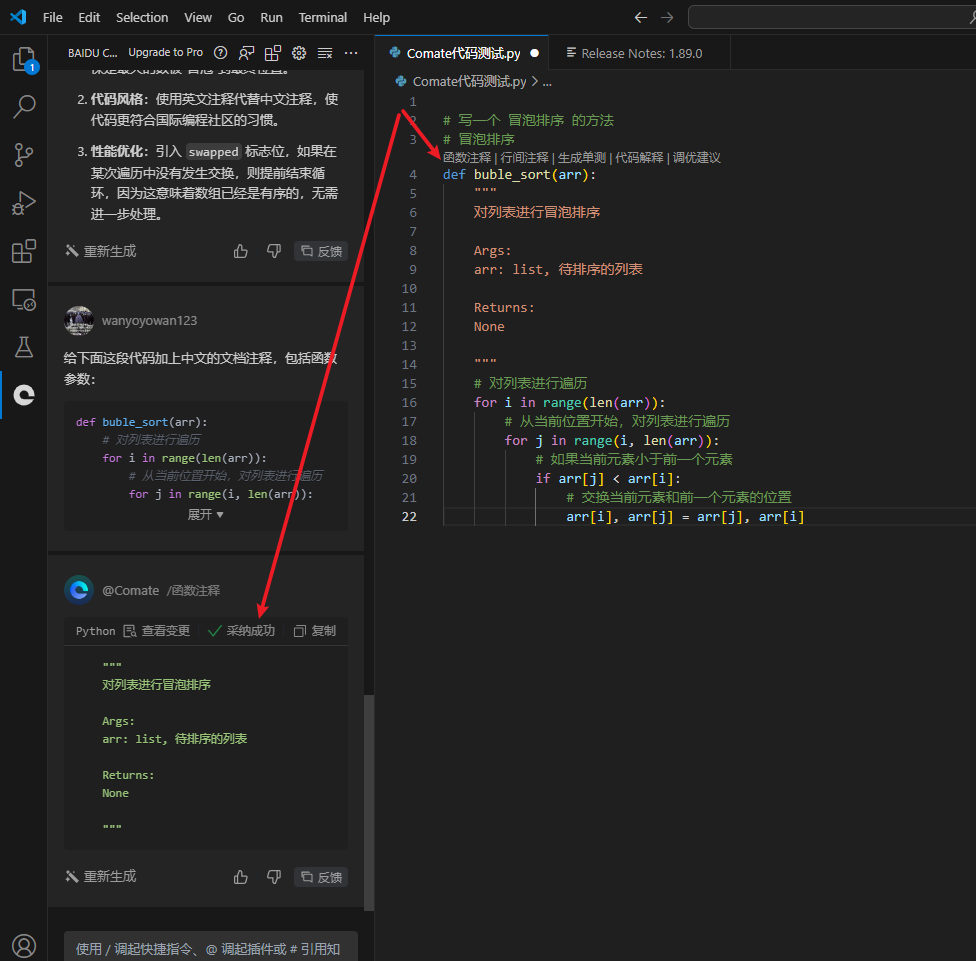
生成函数注释
生成函数注释,与行间注释基本一致
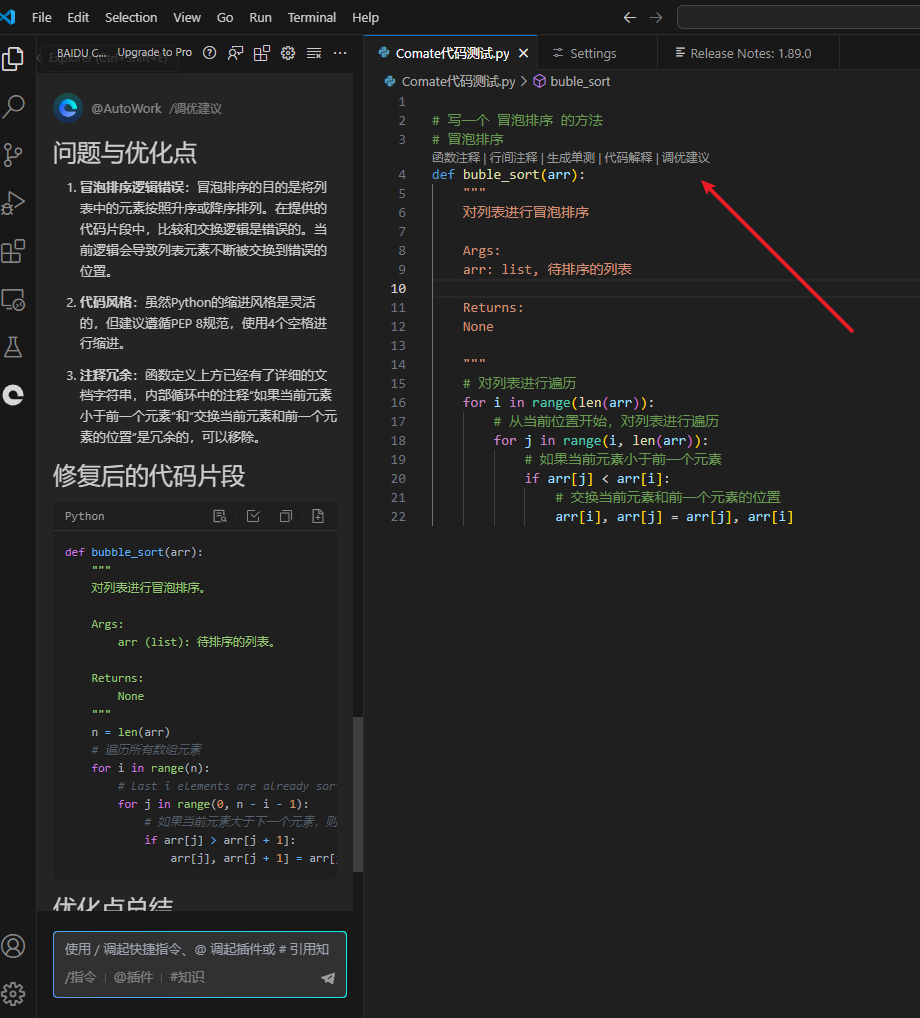
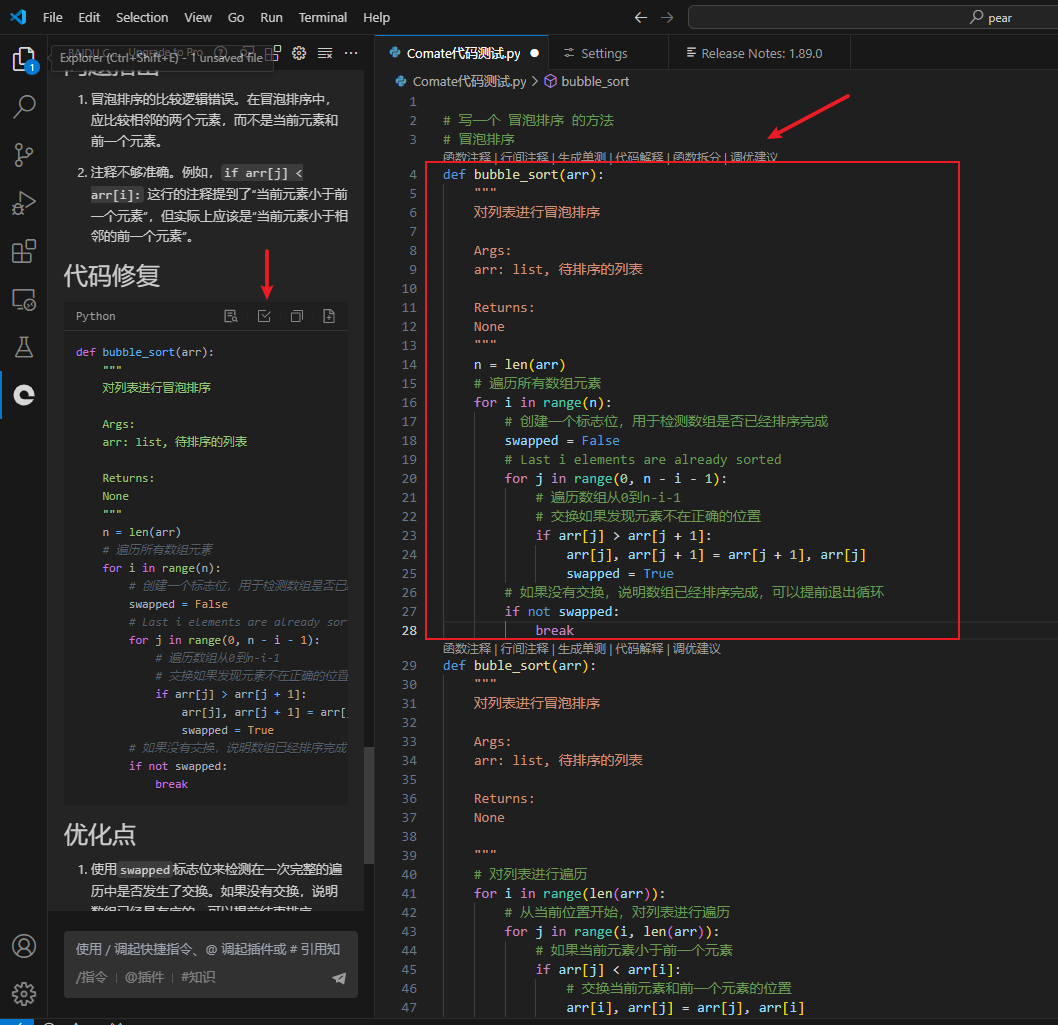
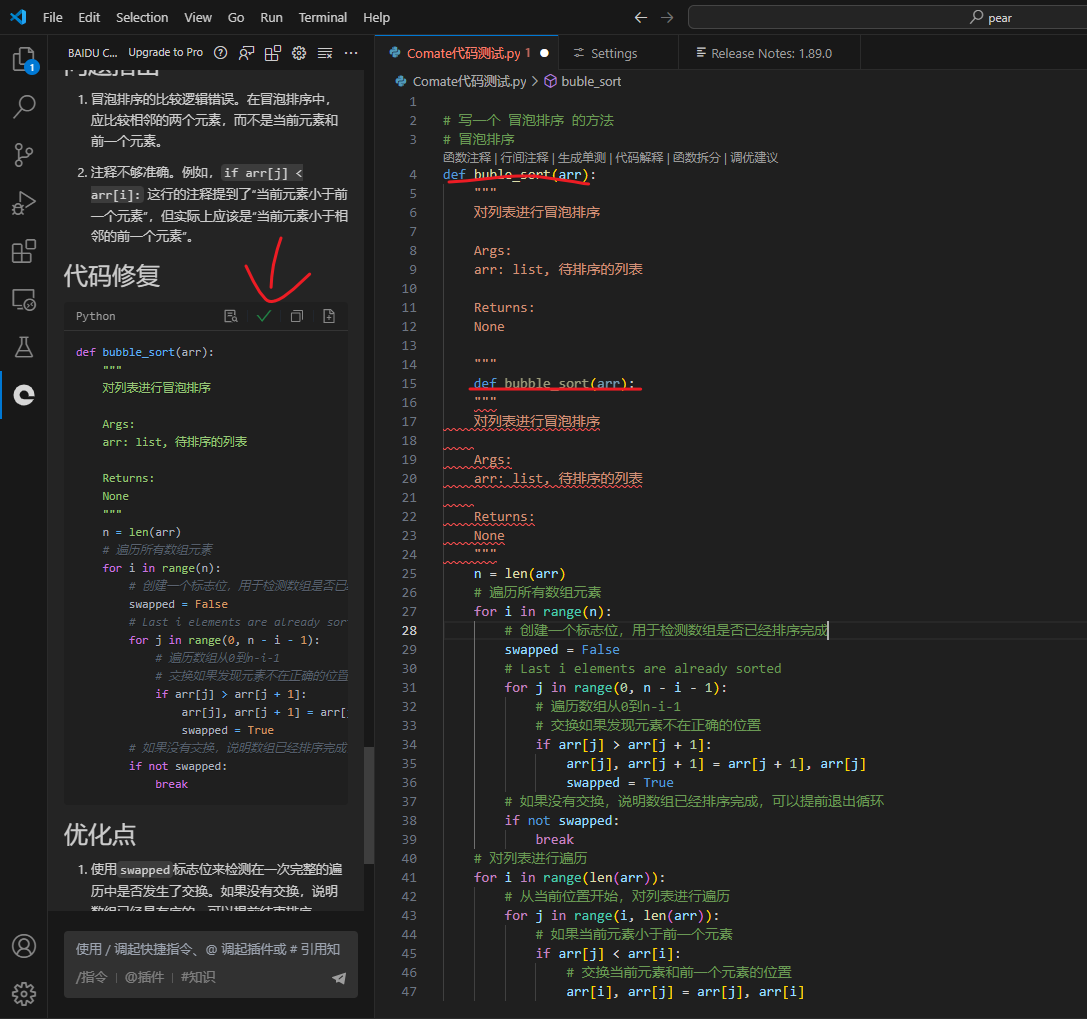
调优建议
点击调优建议
点击接收修复,如下
需要注意的是,这里的代码会生成在光标所在位置,而非替换原有的代码,所以要注意在采纳前,把光标放在合适的位置,不要放在函数中,否则会生成如下代码
对话问答
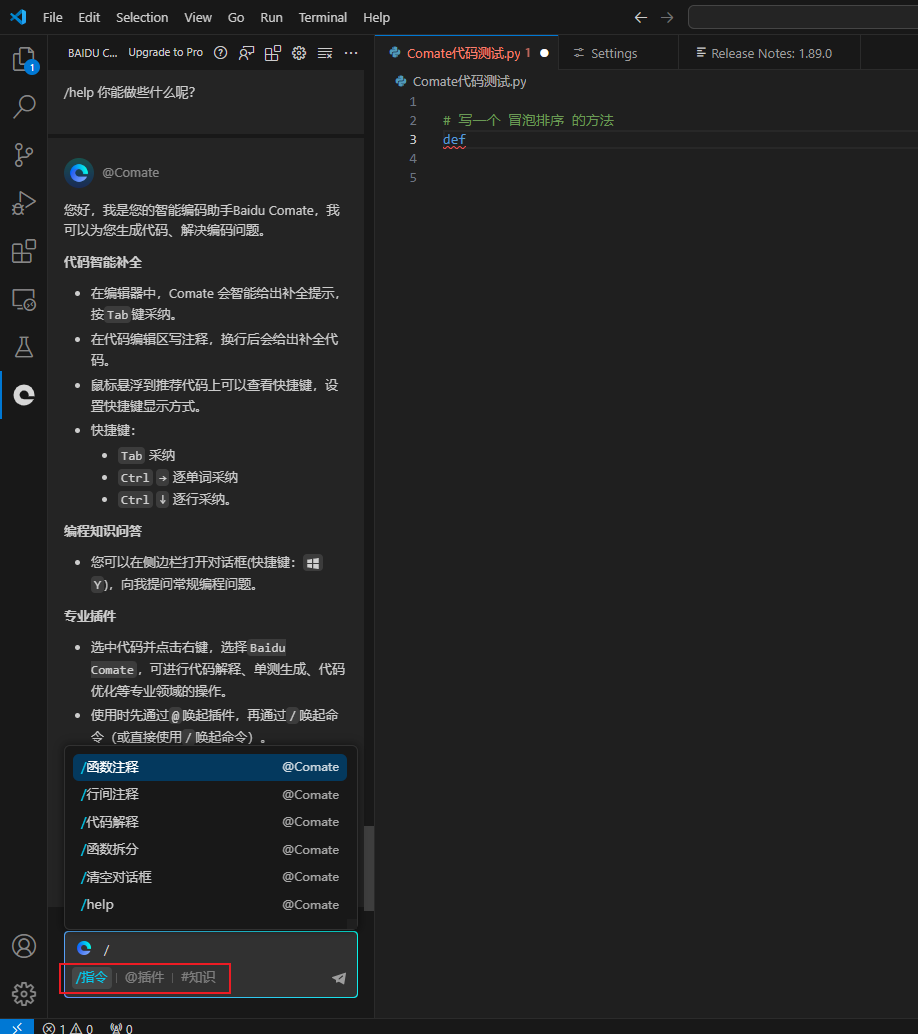
在vscode左侧的comate对话框可以通过
/调取指令
@插件 调取插件
#知识库
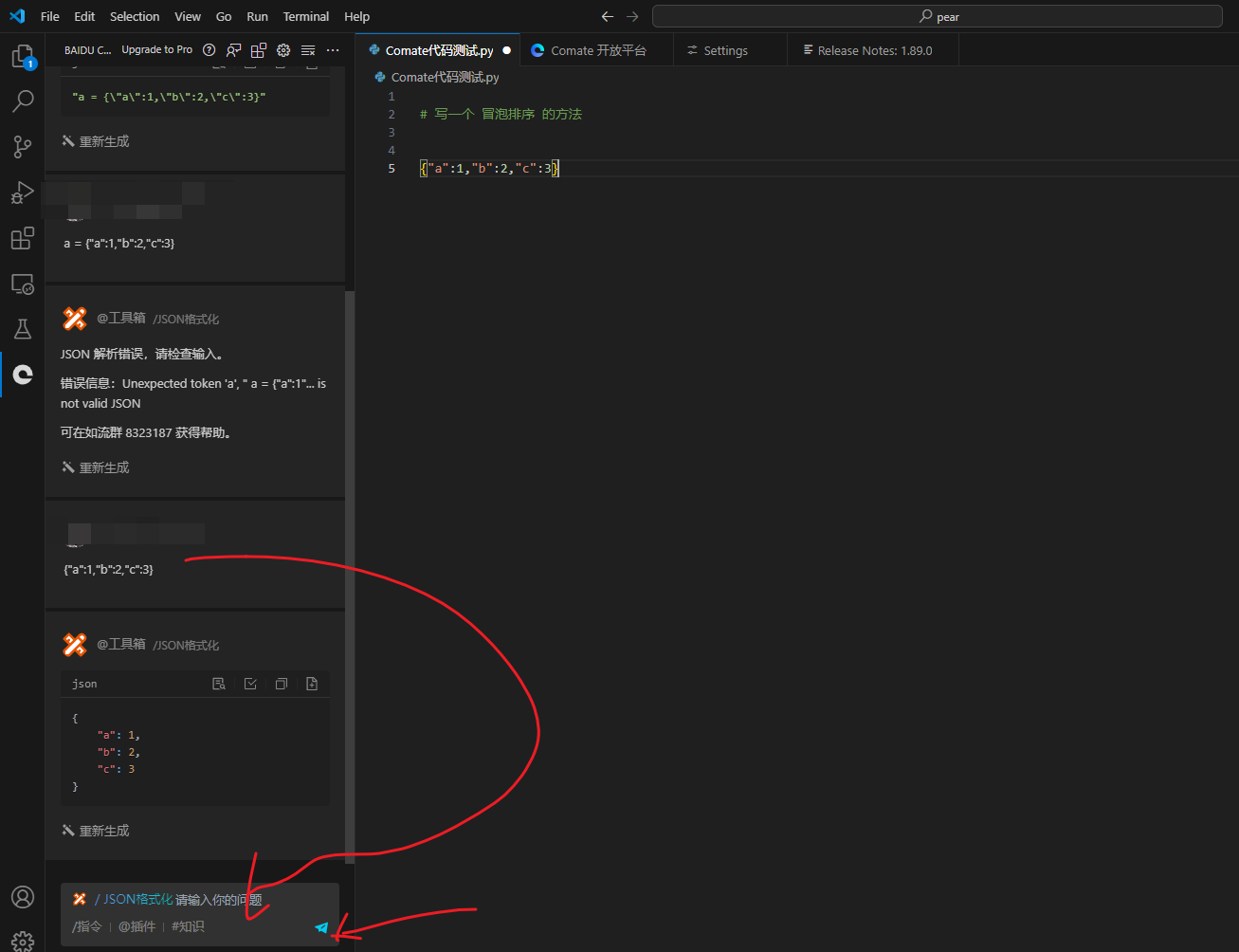
json格式生成
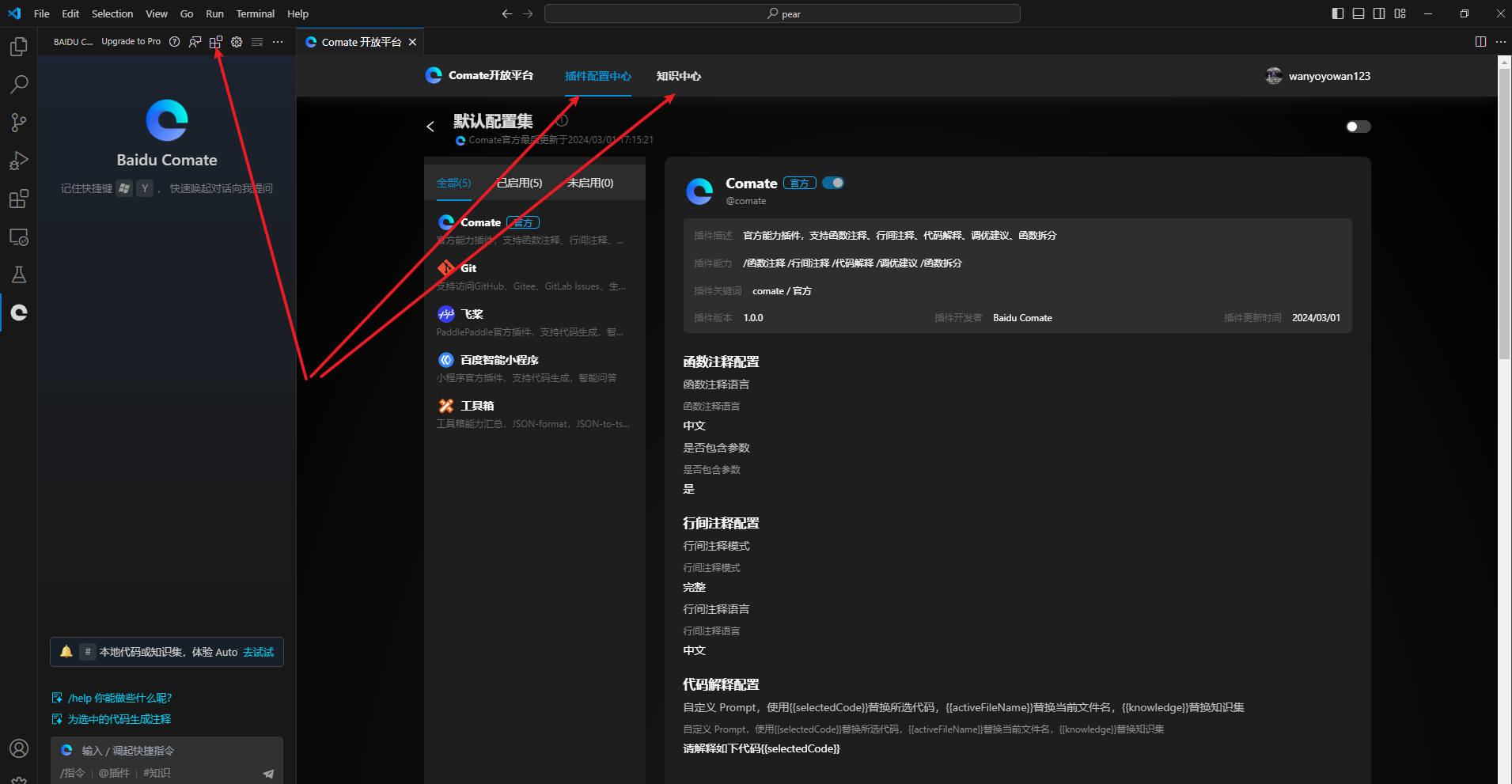
点击comate,的插件配置,可以进入插件配置平台和知识中心。
基于对话问答的@AutoWork插件实现一个分类算法
选择@AutoWork插件,在对话窗口提问
生成一个分类算法的案例
生成如下代码
新建文件,并命名为aa.py,运行结果如下:
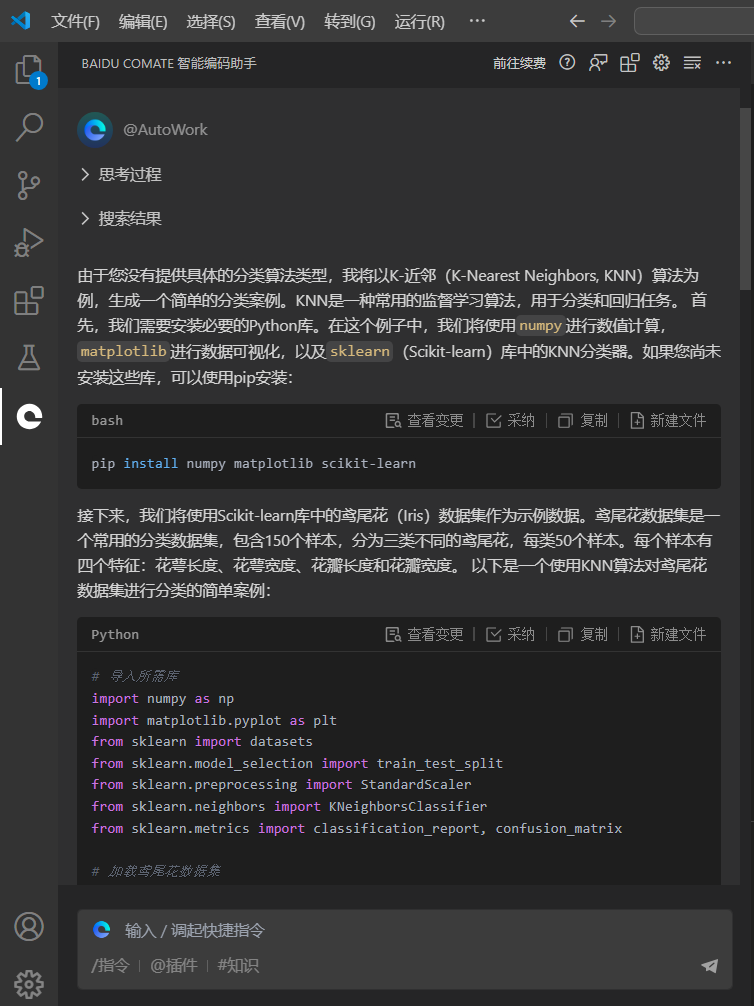
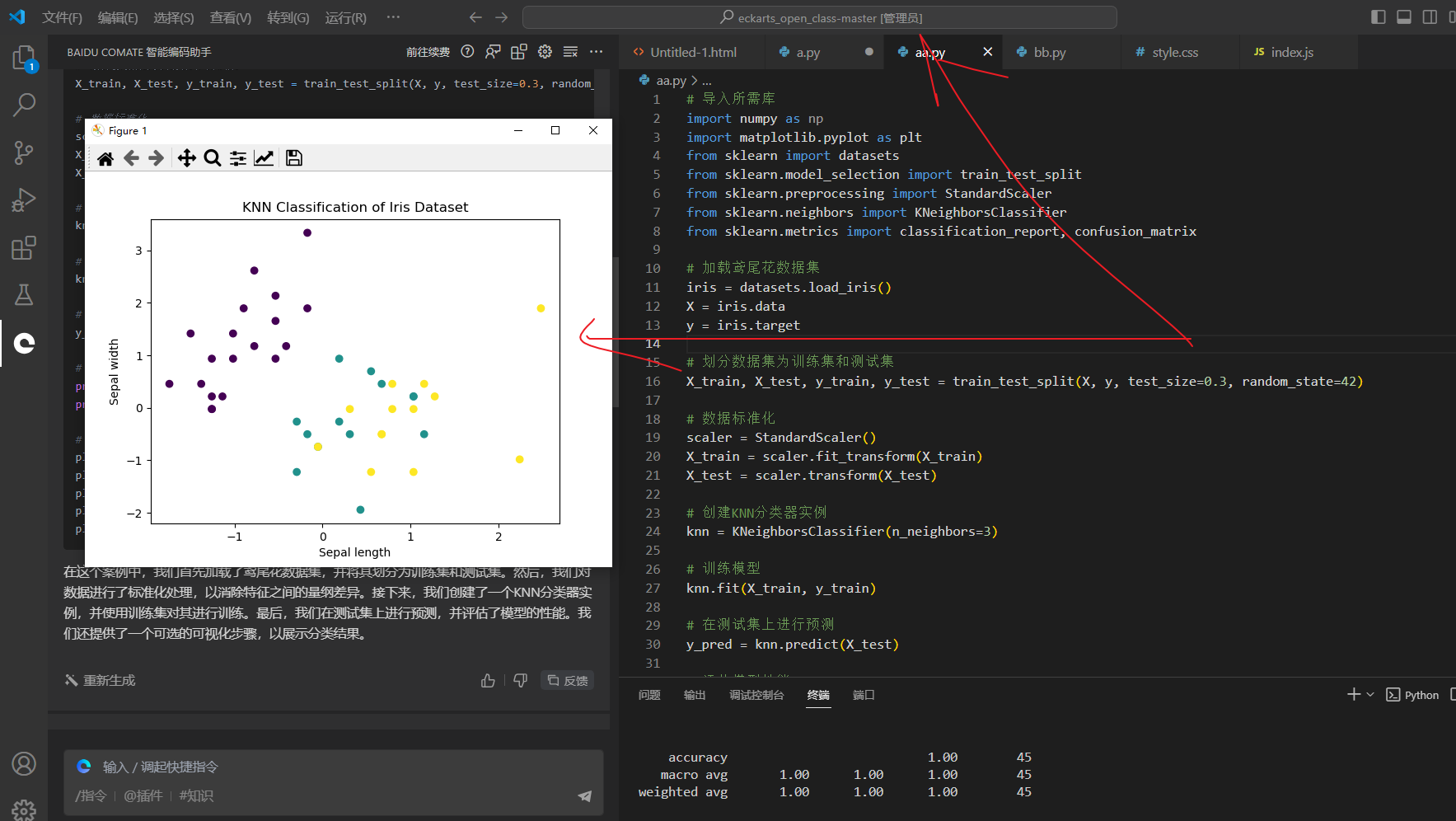
完整代码如下:
# 导入所需库
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import classification_report, confusion_matrix# 加载鸢尾花数据集
iris = datasets.load_iris()
X = iris.data
y = iris.target# 划分数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 数据标准化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)# 创建KNN分类器实例
knn = KNeighborsClassifier(n_neighbors=3)# 训练模型
knn.fit(X_train, y_train)# 在测试集上进行预测
y_pred = knn.predict(X_test)# 评估模型性能
print(confusion_matrix(y_test, y_pred))
print(classification_report(y_test, y_pred))# 可视化结果(可选)
plt.scatter(X_test[:, 0], X_test[:, 1], c=y_pred, cmap='viridis')
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.title('KNN Classification of Iris Dataset')
plt.show()
基于对话问答的默认的comate插件实现一个分类算法
选择默认的comate插件,在对话窗口提问
生成一个分类算法的案例
生成如下代码
选择新建文件
然后保存为合适的文件名bb
右键运行bb代码,如下
代码可以运行,整体还是良好的
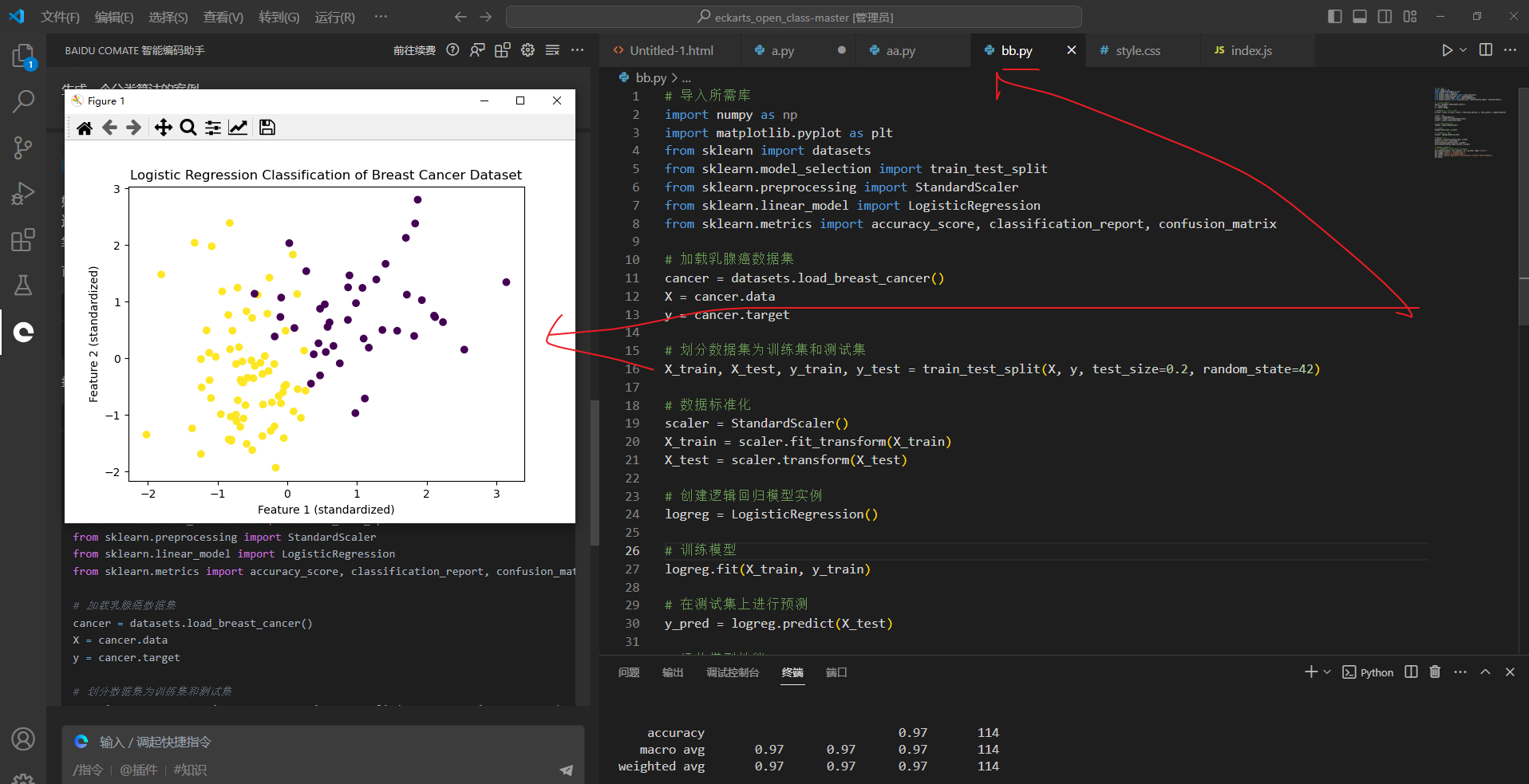
完整代码如下:
# 导入所需库
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix# 加载乳腺癌数据集
cancer = datasets.load_breast_cancer()
X = cancer.data
y = cancer.target# 划分数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 数据标准化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)# 创建逻辑回归模型实例
logreg = LogisticRegression()# 训练模型
logreg.fit(X_train, y_train)# 在测试集上进行预测
y_pred = logreg.predict(X_test)# 评估模型性能
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy}")
print(confusion_matrix(y_test, y_pred))
print(classification_report(y_test, y_pred))# 可视化结果(可选)
# 由于特征数量较多,这里只展示前两个特征
plt.scatter(X_test[:, 0], X_test[:, 1], c=y_pred, cmap='viridis')
plt.xlabel('Feature 1 (standardized)')
plt.ylabel('Feature 2 (standardized)')
plt.title('Logistic Regression Classification of Breast Cancer Dataset')
plt.show()
继续询问是否可以生成指定算法的代码
给出一个xgboost的案例代码
整体还是十分优秀的。
存在的问题及建议
代码函数的命名为中文问题
# 写一个插入排序的方法
def
按tab补全,会显示如下:

创建文件时,默认的文件名与代码中的文件名不匹配
比如说生成style.csss文件,但生成的文件名为代码的首行,可以在代码首行加上注释的文件名更好
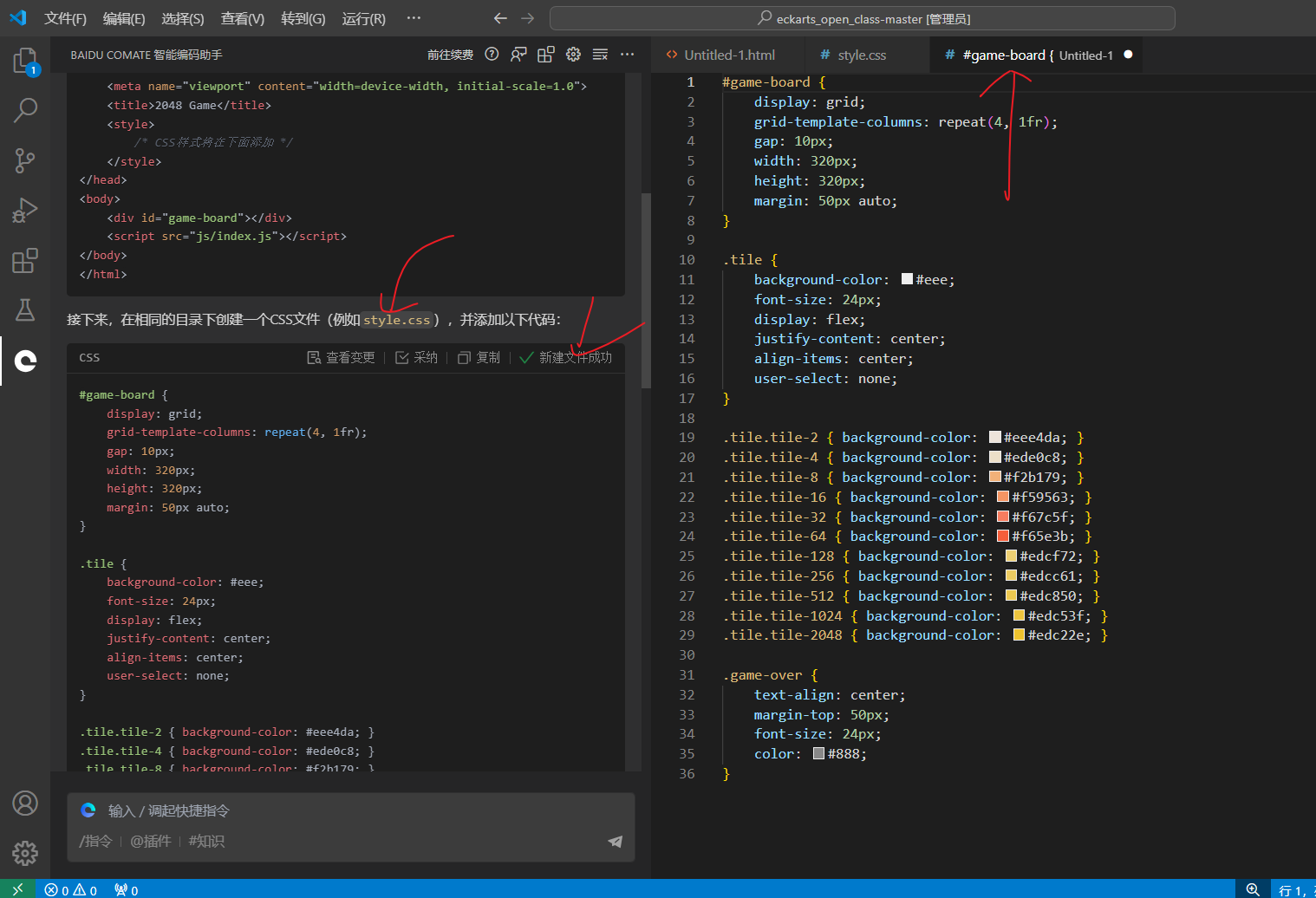
生成一个聚类算法案例,会反复生成重复的代码
生成一个基于sklearn的聚类算法案例
按tab补全或 ctrl+↓ 会反复生成重复的代码
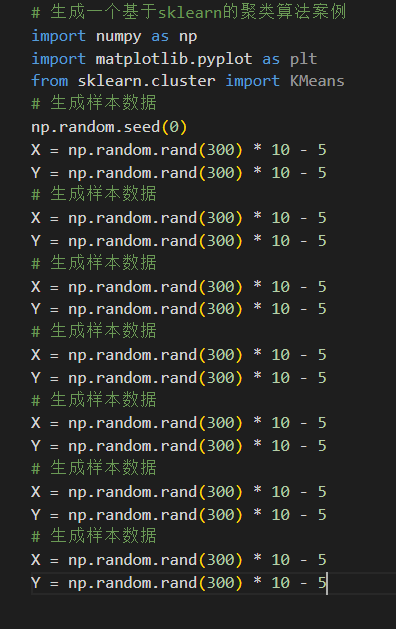
问答时,会带入上一步骤的代码,清除对话框也依然后带入
我询问
如何学习计算机视觉,并给出学习规划
回答的还是可以的
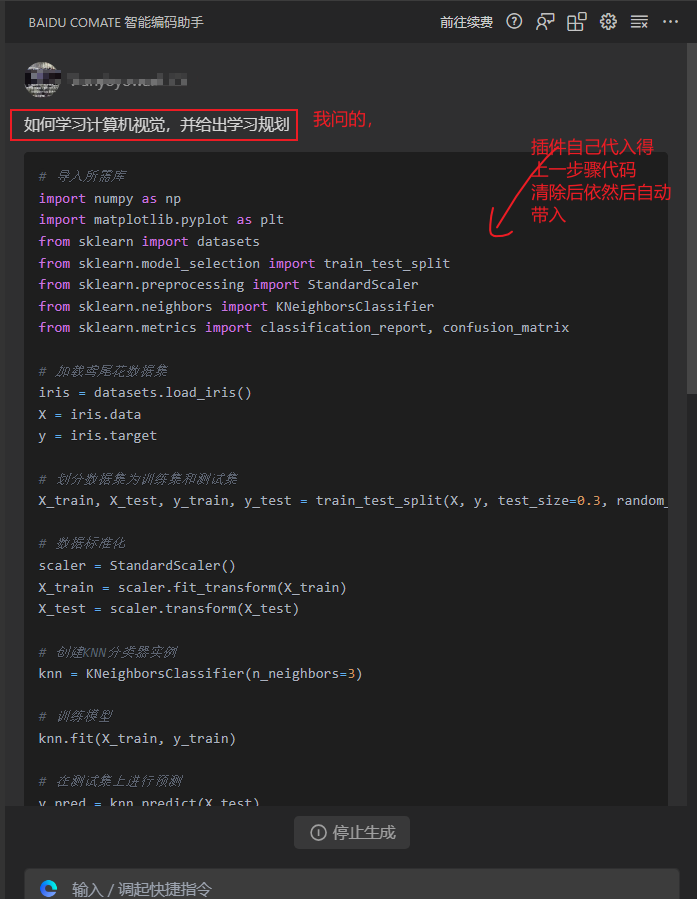

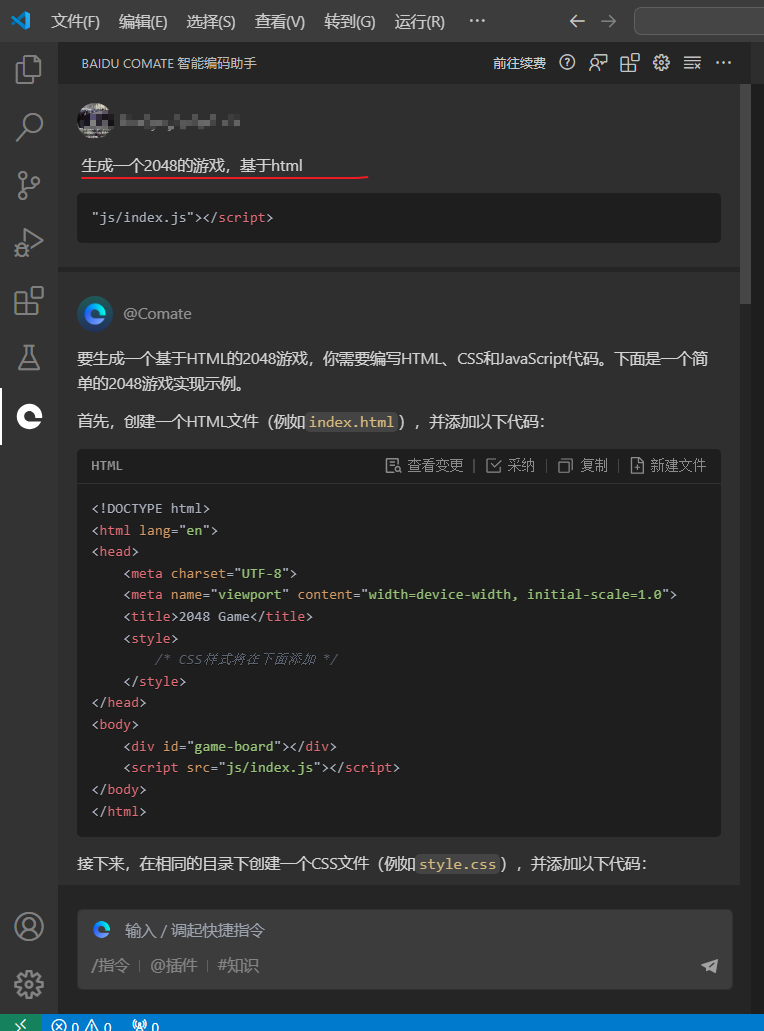
生成一个稍微复杂的完整游戏测试
在对话问答窗口调用comate插件,提问如下:
生成一个2048的游戏,基于html
按照回答,创建文件,和复制代码
创建index.html文件
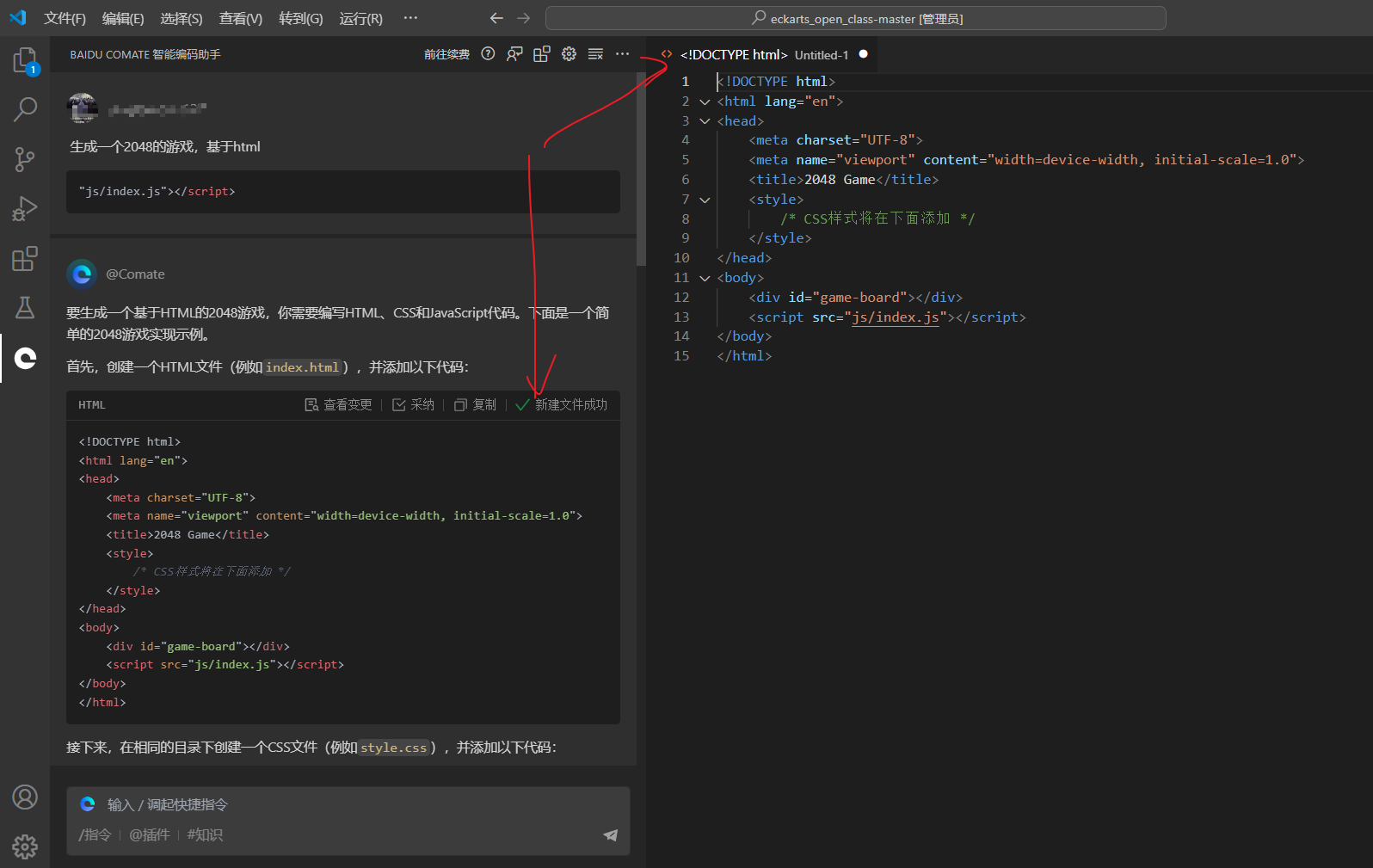
创建style.css文件
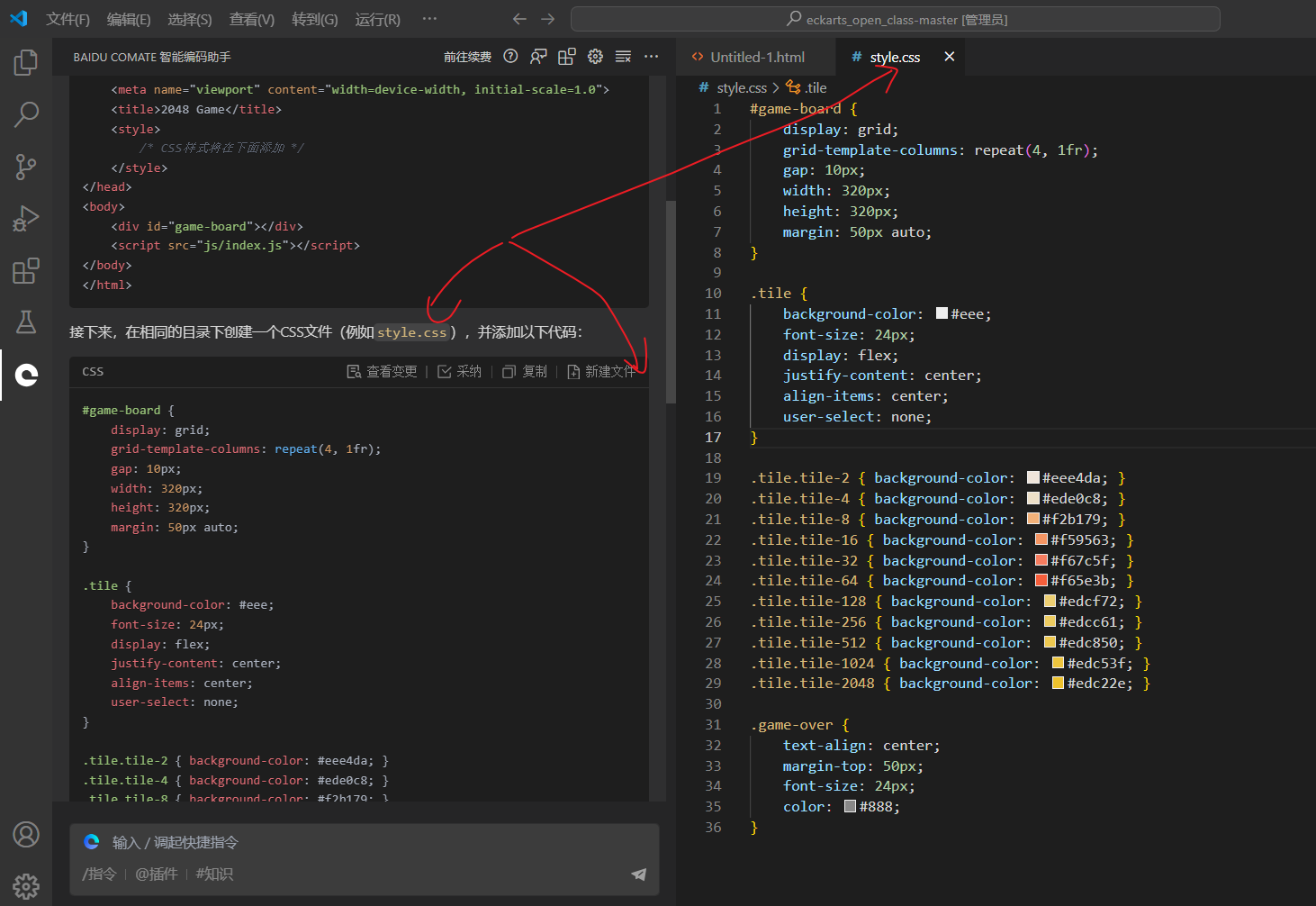
创建index.js文件

又继续提问:
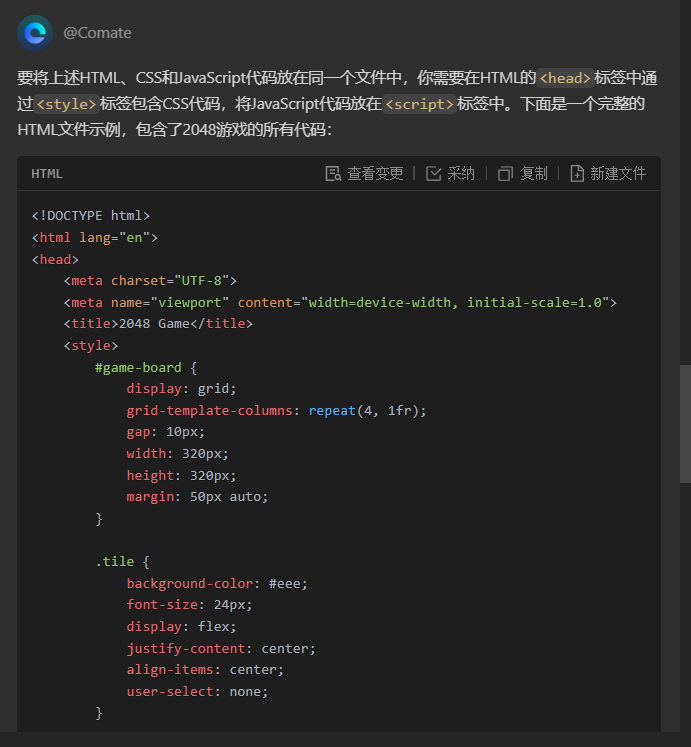
把上面代码放在一个文件中
经过测试,分开的代码和合并的代码都无法直接运行,看来使用的方式不建议直接生成大段的可用的代码,而应该聚焦于局部代码进行优化
总结
适合完善已有代码,添加注释,优化代码等操作,也可以做完整的学习规划,在自动创建文件上,文件名需要自己指定下。
整体可用还是不错的,下面给出对应的链接
Comate官方链接https://comate.baidu.com/zh