目录
关联式容器
键值对
set%E4%BB%8B%E7%BB%8D%EF%BC%9A%C2%A0-toc" style="margin-left:0px;">set介绍:
set%E7%9A%84%E6%A8%A1%E6%9D%BF%E5%8F%82%E6%95%B0%E5%88%97%E8%A1%A8%C2%A0-toc" style="margin-left:40px;">set的模板参数列表
set%E7%9A%84%E5%8F%8C%E5%90%91%E8%BF%AD%E4%BB%A3%E5%99%A8%EF%BC%9A-toc" style="margin-left:80px;"> set的双向迭代器:
set%E7%9A%84%E7%89%B9%E6%80%A7%EF%BC%9A-toc" style="margin-left:80px;">insert的使用和set的特性:
set%E7%9A%84%E5%88%A0%E9%99%A4%EF%BC%9A-toc" style="margin-left:80px;"> set的删除:
set%E7%9A%84find%EF%BC%9A%C2%A0-toc" style="margin-left:80px;">set的find:
lower_bound 、 upper_bound:
set%EF%BC%9A-toc" style="margin-left:80px;"> multiset:
map%E4%BB%8B%E7%BB%8D%EF%BC%9A%C2%A0-toc" style="margin-left:0px;">map介绍:
pair< const Key , T>
和搜索二叉树的KV模型对比:
插入操作
遍历操作
注意事项:
使用范围for进行遍历:
写法1:
写法2:
构造操作:
operator[]
operator[]的使用
operator[]的多种写法
查找操作
使用find进行查找
使用operator[]进行查找
count
map-toc" style="margin-left:120px;">使用second排序操作 和 multimap
关联式容器
关联式容器也是用来存储数据的,与序列式容器不同的是,其里面存储的是结构的 键值对,在数据检索时比序列式容器效率更高。
键值对
用来表示具有一一对应关系的一种结构,该结构中一般只包含两个成员变量key和value,key代 表键值,value表示与key对应的信息。
set%E4%BB%8B%E7%BB%8D%EF%BC%9A%C2%A0">set介绍:
1. set是按照一定次序存储元素的容器
2. 在set中,元素的value也标识它(value就是key,类型为T),并且每个value必须是唯一的。 set中的元素不能在容器中修改(元素总是const),但是可以从容器中插入或删除它们。
3. 在内部,set中的元素总是按照其内部比较对象(类型比较)所指示的特定严格弱排序准则进行 排序。
4. set容器通过key访问单个元素的速度通常比unordered_set容器慢,但它们允许根据顺序对 子集进行直接迭代。
5. set在底层是用二叉搜索树(红黑树)实现的。
6.与map/multimap不同,map/multimap中存储的是真正的键值对,set中只放 value,但在底层实际存放的是由构成的键值对。
7. set中插入元素时,只需要插入value即可,不需要构造键值对。
8. set中的元素不可以重复(因此可以使用set进行去重)。
9. 使用set的迭代器遍历set中的元素,可以得到有序序列
10. set中的元素默认按照小于来比较
11. set中查找某个元素,时间复杂度为:$log_2 n$
12. set中的元素不允许修改(为什么?)
set%E7%9A%84%E6%A8%A1%E6%9D%BF%E5%8F%82%E6%95%B0%E5%88%97%E8%A1%A8%C2%A0">set的模板参数列表


set%E7%9A%84%E5%8F%8C%E5%90%91%E8%BF%AD%E4%BB%A3%E5%99%A8%EF%BC%9A"> set的双向迭代器:

set%E7%9A%84%E7%89%B9%E6%80%A7%EF%BC%9A">insert的使用和set的特性:
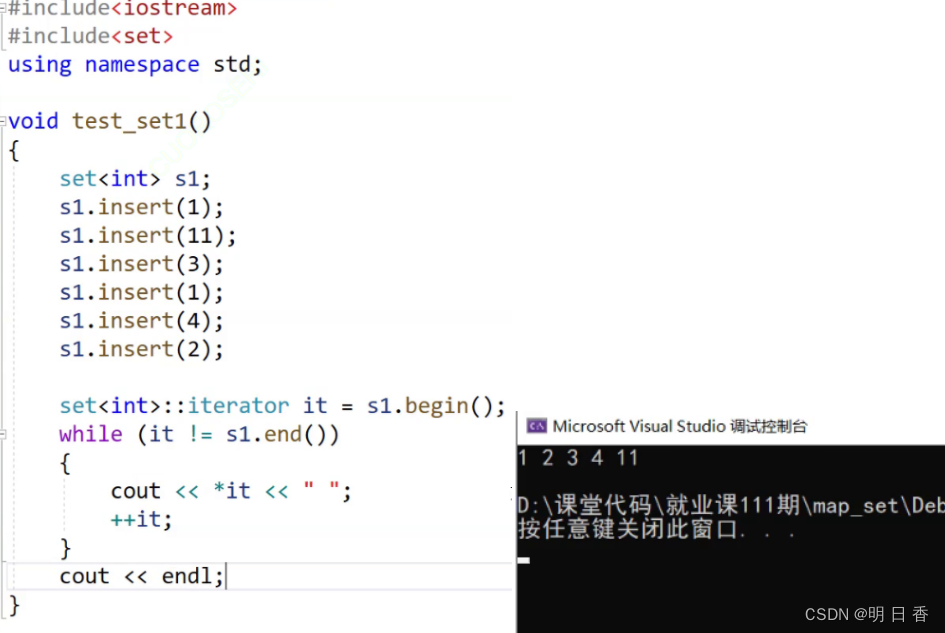
可以看出,当我们遍历set的迭代器时,遍历set内部的内容可以发现,set内部存储的形式是一个搜索二叉树,当遍历set时遍历出的结果是一个搜索二叉树中序遍历的结果,且set和搜索二叉树一样,具有去重功能和具有不允许修改内部数值的功能,因为修改内部的数据内容会导致set内部的存储结构失效。
set%E7%9A%84%E5%88%A0%E9%99%A4%EF%BC%9A"> set的删除:
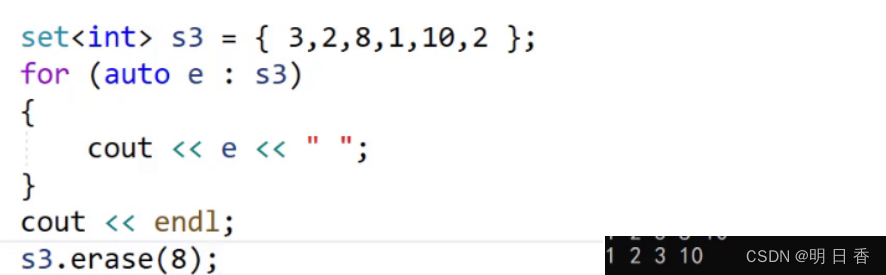
set%E7%9A%84find%EF%BC%9A%C2%A0">set的find:
find是找到后返回该节点的迭代器
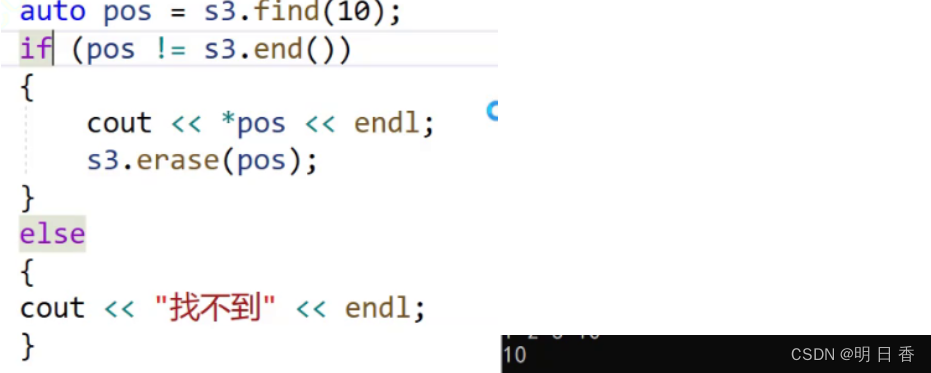
lower_bound 、 upper_bound:

lower是找大于等于后面要找的值,而upper是要找大于要找的数值。
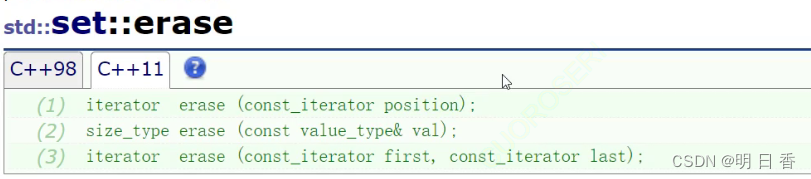
在这里因为lower找的是大于等于后面数值,然后返回那个数值节点的 迭代器,upper也是如此,这里upper是第一个比60大的数值的节点的迭代器,然后使用erase进行删除把者之间的数值进行删除,[30,70)不删除70
set%EF%BC%9A"> multiset:

multiset其实是set的一种分支,和set相比,它不具备set的去重功能,但是内部的底层和set一样是一个搜索二叉树,但这个二叉树是允许重复的元素出现。

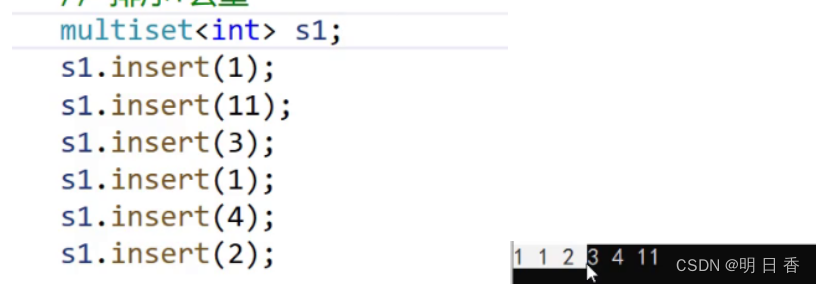
这里如果按照搜索二叉树是不能有等于的,且大于在右小于在左边,这里就是左右都可以随便插入,当然相等的数值也不一定是连续的,因为底层还是树,所以需要寻找空位进行插入
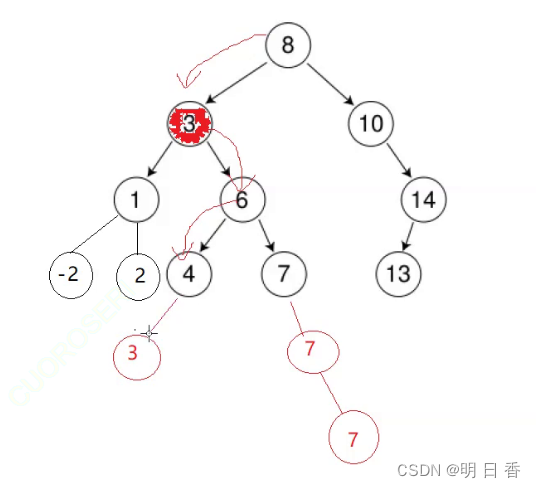
但是如果要是find寻找重复的数值,那么multiset的find找的是中序排序后的第一个,也就是:查找X,查找到X的节点后,那么这个节点的左子树没有X节点,那么他就是中序的第一个X节点,如果左子树有X这个节点,那么接着往左子树方向继续查找X节点。
map%E4%BB%8B%E7%BB%8D%EF%BC%9A%C2%A0">map介绍:
1. map是关联容器,它按照特定的次序(按照key来比较)存储由键值key和值value组合而成的元 素。
2. 在map中,键值key通常用于排序和惟一地标识元素,而值value中存储与此键值key关联的 内容。键值key和值value的类型可能不同,并且在map的内部,key与value通过成员类型 value_type绑定在一起,为其取别名称为pair: typedef pair value_type;
3. 在内部,map中的元素总是按照键值key进行比较排序的。
4. map中通过键值访问单个元素的速度通常比unordered_map容器慢,但map允许根据顺序 对元素进行直接迭代(即对map中的元素进行迭代时,可以得到一个有序的序列)。
5. map支持下标访问符,即在[]中放入key,就可以找到与key对应的value。
6. map通常被实现为二叉搜索树(更准确的说:平衡二叉搜索树(红黑树))。

- key: 键值对中key的类型
- T: 键值对中value的类型
- Compare: 比较器的类型,map中的元素是按照key来比较的,缺省情况下按照小于来比 较,一般情况下(内置类型元素)该参数不需要传递,如果无法比较时(自定义类型),需要用户 自己显式传递比较规则(一般情况下按照函数指针或者仿函数来传递)
- Alloc:通过空间配置器来申请底层空间,不需要用户传递,除非用户不想使用标准库提供的 空间配置器
- 注意:在使用map时,需要包含头文件。
pair< const Key , T>
pair<const Key , T> 是一个内部类函数也是一个类模板

和搜索二叉树的KV模型对比:

就是把搜索二叉树的K和V存入了一个类模板结构中 ,而pair这个类模板的内部中的 first表示键 Key,second表示值 Value
插入操作

对于map的inser操作t在有了pair后,实际上就是插入一个pair

dict.insert({"String","字符串"})是一种隐式类型转化,但是需要注意这种隐式类型转化要和构造函数中的initializer_list<value_type>进行区分:

如上图代码所示,上图代码是一个构造函数。

遍历操作
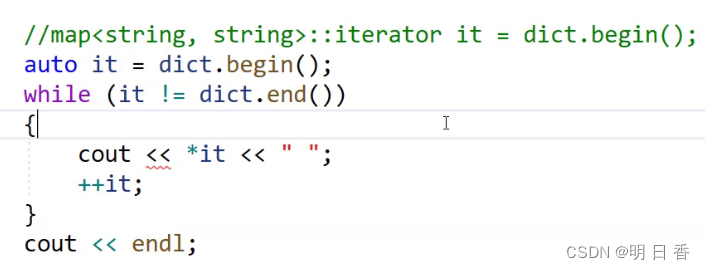
可以看到图上代码中的<<出现了问题,这其实和pair有关,因为pair内部其实是两个数值,所以迭代器并不知道应该返回谁,且pair并不支持流插入操作,所以需要进行深入的操作:
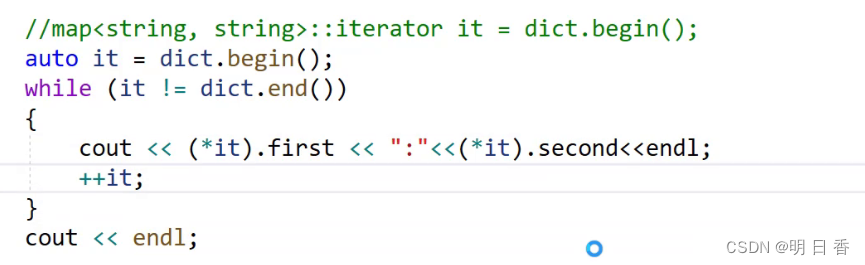
前文说过,pair内部的Key 和 Value数值是使用first和second来替代的。
简化写法1:
![]()
简化写法2:可以省略箭头,和list的operator->的箭头省略操作一样

可以看出如果我们要实现map底层代码中的的迭代器,那么将会较为的困难。
注意事项:
在遍历map的时候,pair的first是不允许进行修改的,而second却可以进行修改:
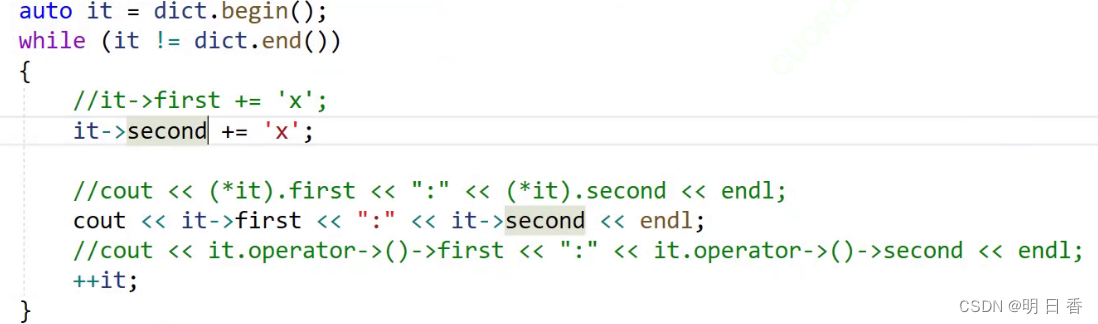
firs是key相对于树的节点和各类节点之间具有关系,所以是不能进行修改的,因为map是靠key进行排序的!
使用范围for进行遍历:
写法1:

写法2:

写法2是建立在当前编译器的C++版本处在C++17,而在此之前的写法是C++11版本的
构造操作:

operator[]
map的operator[]和之前的operator[]不同,以前[]内部是一个下标,就例如vector的operator[] []内部的参数是下标,而map的operator[]的[]内部是一个key,内部是一个key然后返回一个key对应的value

如下图所示, operator[]的内部和insert有关,主要是利用了map的insert的性质:

所以插入是否成功关键在于返回的pair内部的second,且无论插入是否成功key所在节点的迭代器都会被返回,而如果插入的是同一个key但是value不一样,那么就算插入了也是无效,因为编译器不会更改value的数据。

operator[]的使用
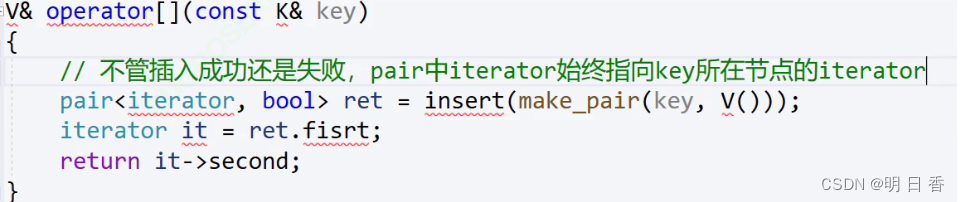
- 从这里看出insert是一个查找的功能
- 所以为什么[]内部是放置key的就是为了传递key让后让insert去查找这个key是否在map中是否存在,如果存在则返回false,而后通过pair获取key所在的节点的迭代器(ret.frist)然后再通过这个迭代器来获取这个迭代器所对应的second也就是value
- 图中的it->second是一个简写
operator[]的多种写法

注意插入+修改 和 修改,如果有[]内部的key数值,那么就变成修改,没有就变成插入功能
查找操作
使用find进行查找

这个函数表达的是 水果的名字表示为frist 也就是 Key ,而水果出现的次数则是second 也就是Value。
使用find查找string arr[]内部的所有数据是否又在map中出现过,如果有,find会返回一个该数据在map中的节点位置,以迭代器的形式进行返回,如果没有会返回一个end, 那么当返回值不等于end时则会让map中的这个数据的value次数加1。
而代码会在,没有出现这个数据是,进行插入操作,同时插入这个数据也要把这个数据出现的次数1也需要进行插入。
使用operator[]进行查找
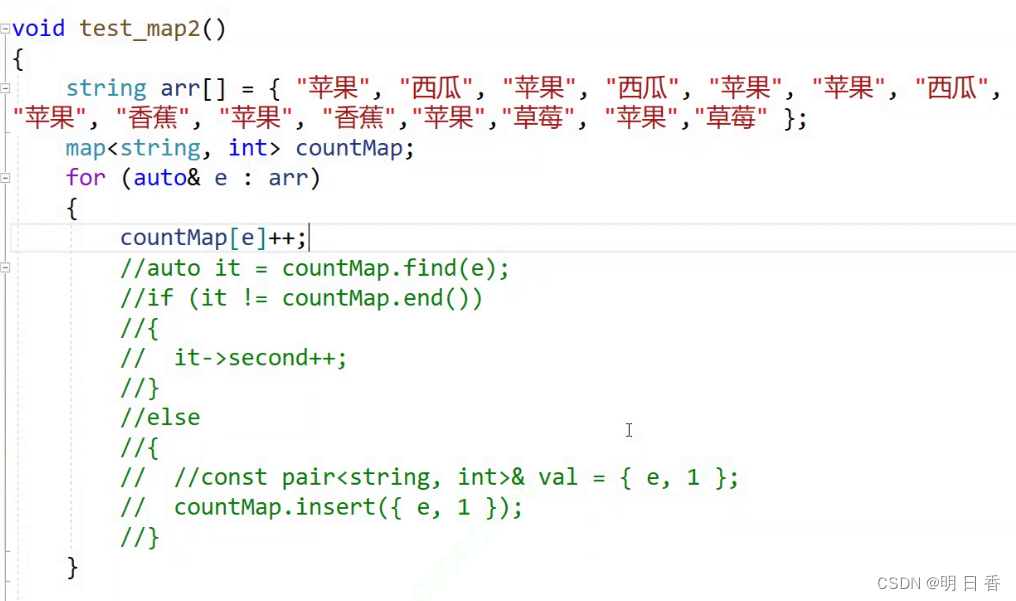
- 在这里的countMap[e]++内部的e是一个key表示arr[]内部的数据,如果arr内部的数据没有在countMap中出现,那么则会进行插入+修改操作
- 例如苹果没有出现则会插入苹果,而苹果出现的次数在插入的过程中会被初始化成0,而在++后变成了1
- 而·如果苹果存在与countMap中后[]会进行查找并且返回,而又因为countMap的scond内部存储的是次数,而[]无论查找成功还是失败都会返回,因为这里查找成功后返回了second然后因为++scond则开始+1
- 所以苹果次数会变成2
count
给一个key然后返回这个key在map内部的个数,可以进行判断key是否存在:

如上代码所示,输入一个str字符串,看是否在map中是否存在,如果存在则输出在,不存在则输出不在。
map">使用second排序操作 和 multimap
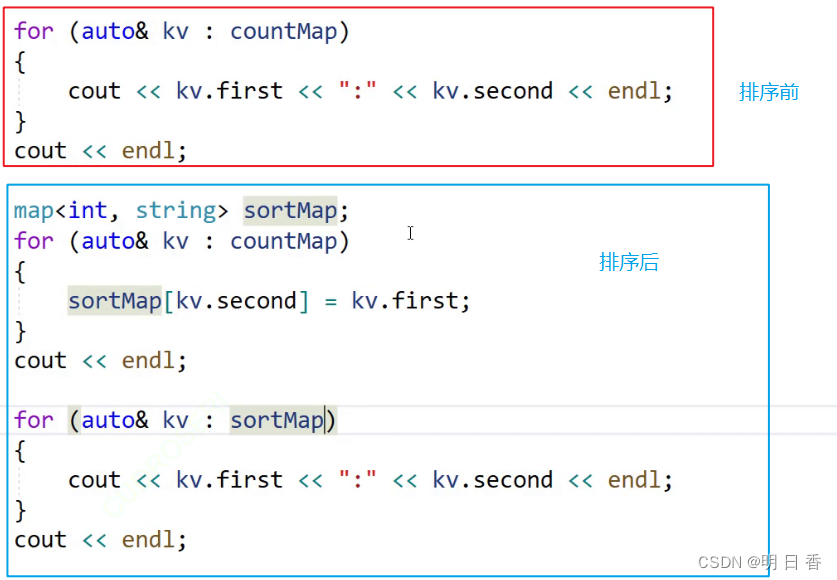
使用另一个map,将次数和字符串进行颠倒,使用遍历赋值的方法,如上图所示,原先的string变成了second的位置,而原先的int变成了frist的位置

- 进行对比发现,少了一个草莓,原因是草莓和香蕉的frist重复了,且香蕉是后面进行遍历赋值的,而且使用了[]导致了后面变成了key=2的value=草莓被修改成了key=2 value=香蕉
- 因为使用了[]然后查找到了之后被修改了,这是因为[]具有修改的操作
- 而如果使用了insert则会导致香蕉插入失败,因为insert是不具有修改功能的,所以因为key都等于2,所以当轮到香蕉时,算是找到了所以无法进行修改
所以想要进行second排序则需要使用 multimap,这是因为multimap允许冗余,也就是允许map的key重复,而map不允许key重复

这个是查找多个重复的key的 ,最后返回的是第一个重复的key的迭代器,和最后一个重复key的迭代器的前一个位置 的函数