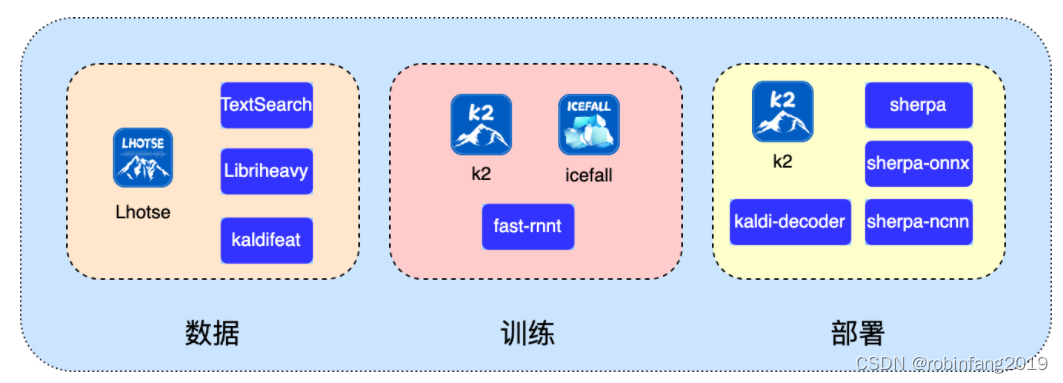
【第5期】ControlNet
欢迎来到SD的终极教程,这是我们的第五节课
这套课程分为六节课,会系统性的介绍sd的全部功能,让你打下坚实牢靠的基础
1.SD入门
2.关键词
3.Lora模型
4.图生图
5.controlnet
6.知识补充
在SD里面,想要生成出来的图片最大程度的符合我们脑海里的画面
有三个最关键的因素
1.关键词
2.Lora
3.ControlNet
关键词和Lora我们已经讲过了,这节课我们就讲SD里最强大的功能——ControlNet
目录
一、Controlnet有什么用
1.给老照片上色
2.给线稿上色
3.控制人物姿势
4.让照片动起来
5.有趣玩法
二、controlnet是什么
三、安装controlnet
四、controlnet的具体使用流程
1.SD基础设置
01.选大模型
02.写关键词
03.参数设置
2.controlnet的使用
五、controlnet的分类讲解
1.姿势约束
01.控制身体姿势
02.控制人物姿势和手指
03.控制人物表情
04.全方面控制人物姿势
05.自由编辑火柴人
安装插件的方法:
插件的使用方法:
06.小结
2.线条约束
01.lineart
①动漫照片
②素描照片
③写实照片
④黑白线稿
02.canny
03.softedge
04.mlsd
05.scribble
06.小结
3.空间深度约束——depth
4.物品种类约束——seg
小结
5.风格约束
01.shuffle
02.reference
①让照片动起来
②还原角色
03.Normal
04.t2ia
05.IP-Adapter
6.重绘
01.Inpaint
①消除图片信息
②给人物换衣服
02.Recolor
①给黑白老照片上色
②给人物头发、衣服换颜色
7.特效——ip2p
8.加照片细节——tile
01.恢复画质
02.给图片加工
03.真人变动漫
04.动漫变真人
05.光影艺术字
六、结尾
一、Controlnet有什么用
1.给老照片上色


2.给线稿上色


3.控制人物姿势


4.让照片动起来


5.有趣玩法
可以生成酷炫的赛博机车照、真人漫改



制作二次元头像


生成创意字
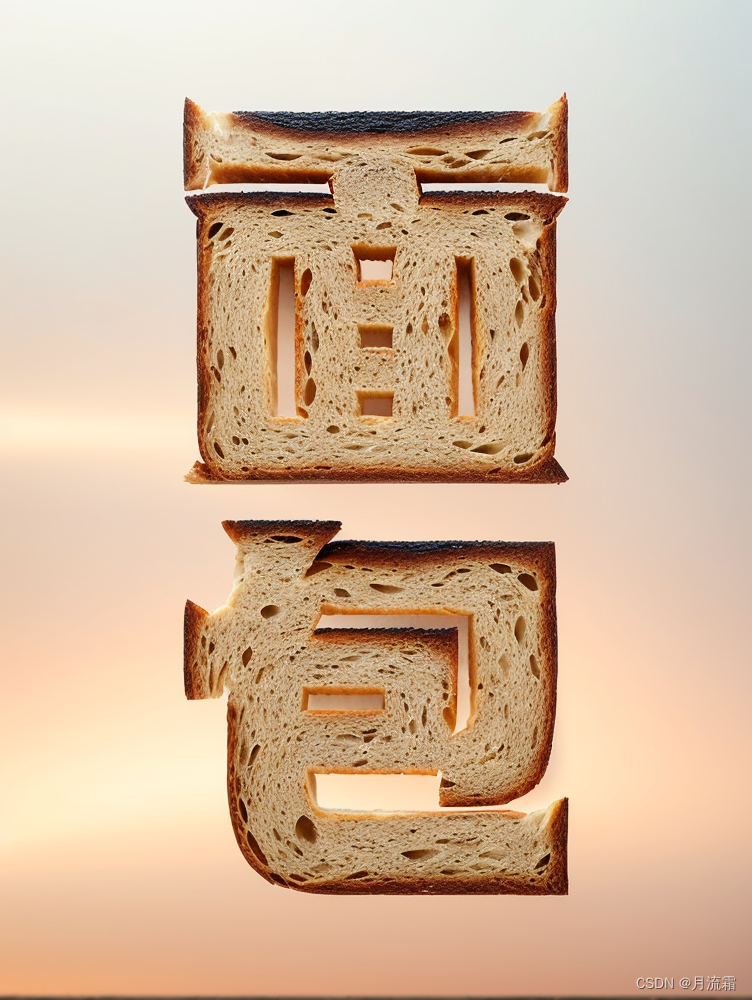

controlnet好玩的地方还有很多很多,例如恢复照片画质、制作艺术二维码等等等等
二、controlnet是什么
AI绘画最终要实现的目标——让出的图与我们脑海里想象的画面一致
但目前现状是:随机性太强
很多时候能不能出来一个好看的画面,只能通过大量的「抽卡」实现,以数量去对冲概率
这种情况下,如果能用好控制出图的三个最关键因素,能让「出图与我们想象的画面一致」概率更高
1.提示词
2.Lora
3.ControlNet
提示词的作用是奠定整个图的大致画面
Lora的作用是让图片主体符合我们的需求
ControNet的作用是精细化控制整体图片的元素——主体、背景、风格、形式等
提示词的用法我在SD的教程里讲过,这个更多的是需要平时的积累,用AB测试去知道每个词对图片产生的影响,从而养成提示词思维
而我们这篇文章主要讲的是ControlNet的用法,把17种模型都给你演示一遍,让你知道每一种模型有什么用,应该怎么用,从而真正掌握ControlNet
ControlNet就是你提供一张图片,然后选择一种采集方式,去生成一张新的图片
比如这张照片

可以选择采集图片中人物的骨架,从而在新的图片中,生成出一样姿势的人


也可以选择采集图片中的线稿,从而在新的图片中,生成一样线稿的画面


又或者选择采集图片中已有的风格,从而在新的图片中,生成一样风格的画面

用的时候不必拘束于哪一种模型更好,更重要的是你脑海里想要什么样的画面
多去尝试,也可以结合其他模型一起用,最终把图片变成你想要的画面就可以了
接下来文章会分为三个部分,会详细介绍controlnet的全部内容
1.安装controlnet
2.controlnet的具体使用流程
3.controlnet的分类讲解
三、安装controlnet
一般通过整合包安装的Stable Diffusion,都已经装了有ControlNet这个插件
我们只要更新插件,然后下载对应的模型就可以了
打开sd的启动页面
点击左边的版本管理,打开扩展页面
找到controlnet那一栏,点击更新就好了

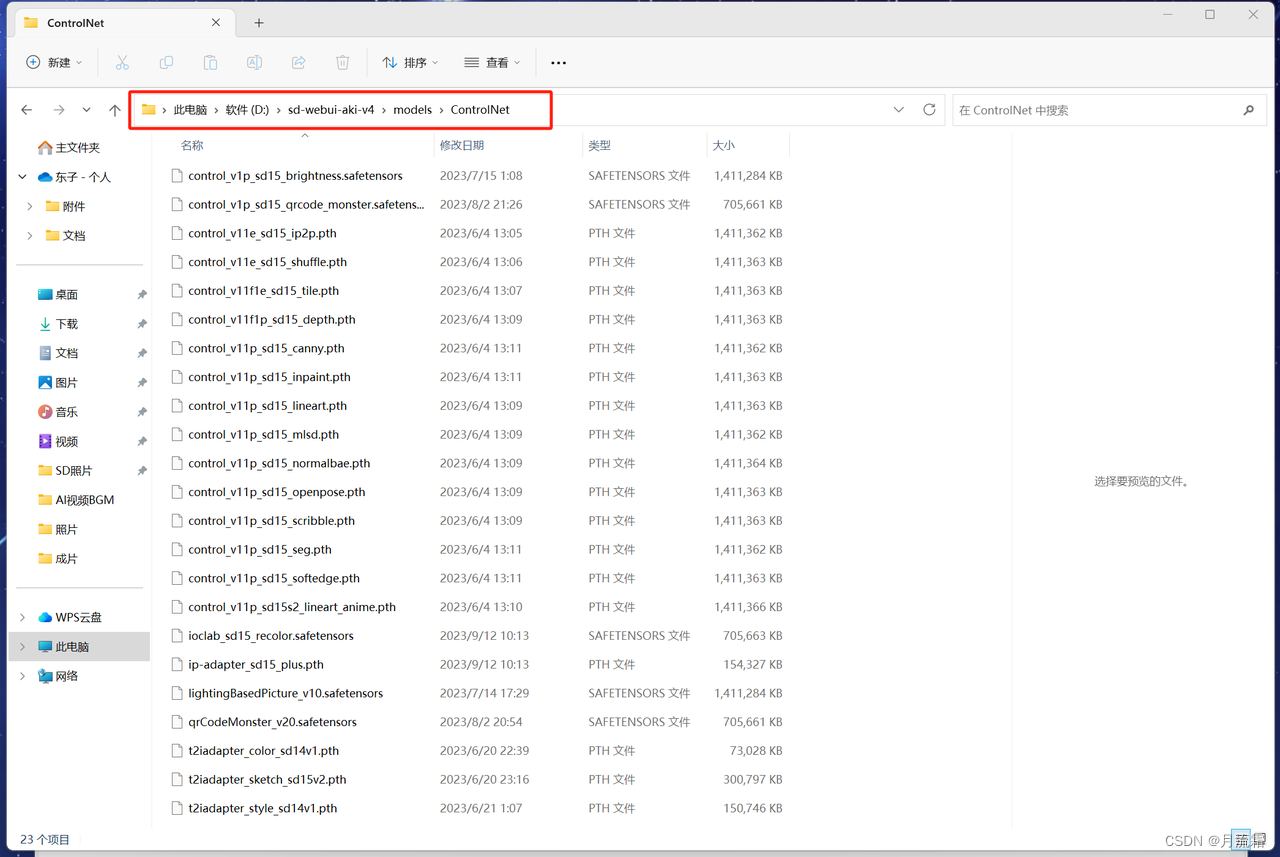
接下来就是下载controlnet模型
17种模型我已经全部打包好放在网盘了
大家只要下载下来,放在对应的文件夹就可以
存放位置:SD文件夹>models>controlnet
四、controlnet的具体使用流程
Controlnet里面总共有17个模型,理论上来说就可以有17种用法
甚至可以两个或者多个Controlnet一起用,这样就有更多的玩法了
但不管怎样,它们的具体操作步骤都是差不多的
接下来我们先讲解controlnet的统一操作方法
再讲解controlnet的每一个模型的功能
就以指定人物姿势为例子,
看看怎么让我们生成出来的照片,摆出来这个同款芭蕾舞姿势

这里我们可以分为两个步骤:
-
1.SD基础设置
-
2.controlnet的设置
1.SD基础设置
SD的基础设置就是我们前面课程所讲的内容
包括选大模型、写关键词、参数设置、如果是想生成好看的真人图片,还可以加上Lora
01.选大模型
首先是选一个大模型,我这里选的是一个写实的大模型

02.写关键词
关键词就是按照我们第二节课的关键词模板去写,再加上Lora模型
再把通用的负面关键词也复制进来

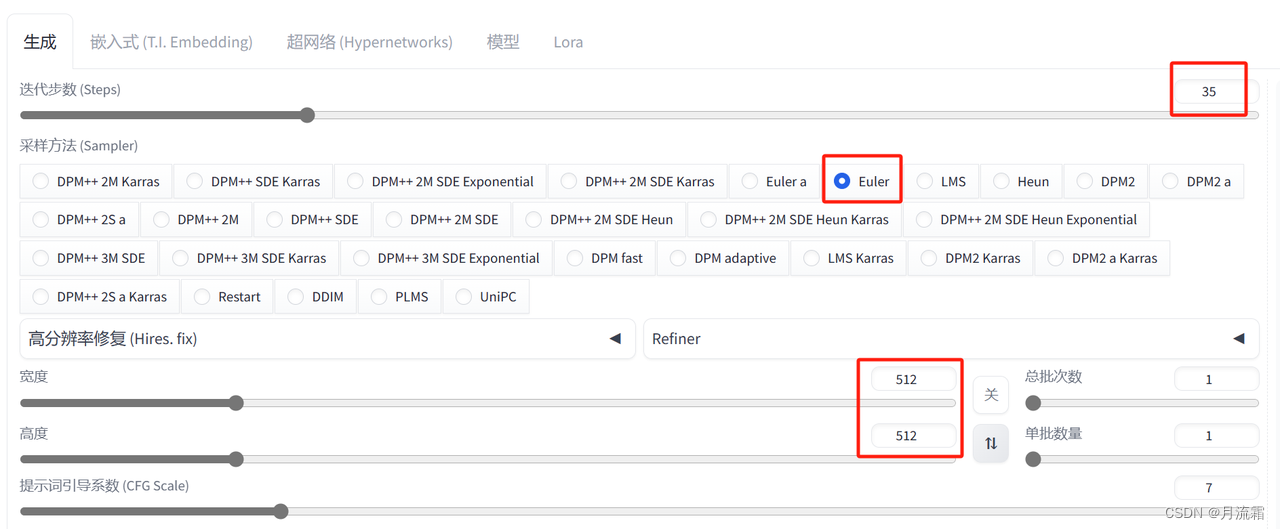
03.参数设置
迭代步数35步
采样方法:Euler
宽度和高度可以先不管,我们等一下再处理
这样SD的基础设置就完成了,接下来就到controlnet的设置
2.controlnet的使用
controlnet的使用方法就只有两步
-
上传图片
-
选模型
滑到SD最下面打开controlnet的面板,在空白的地方上传参考照片
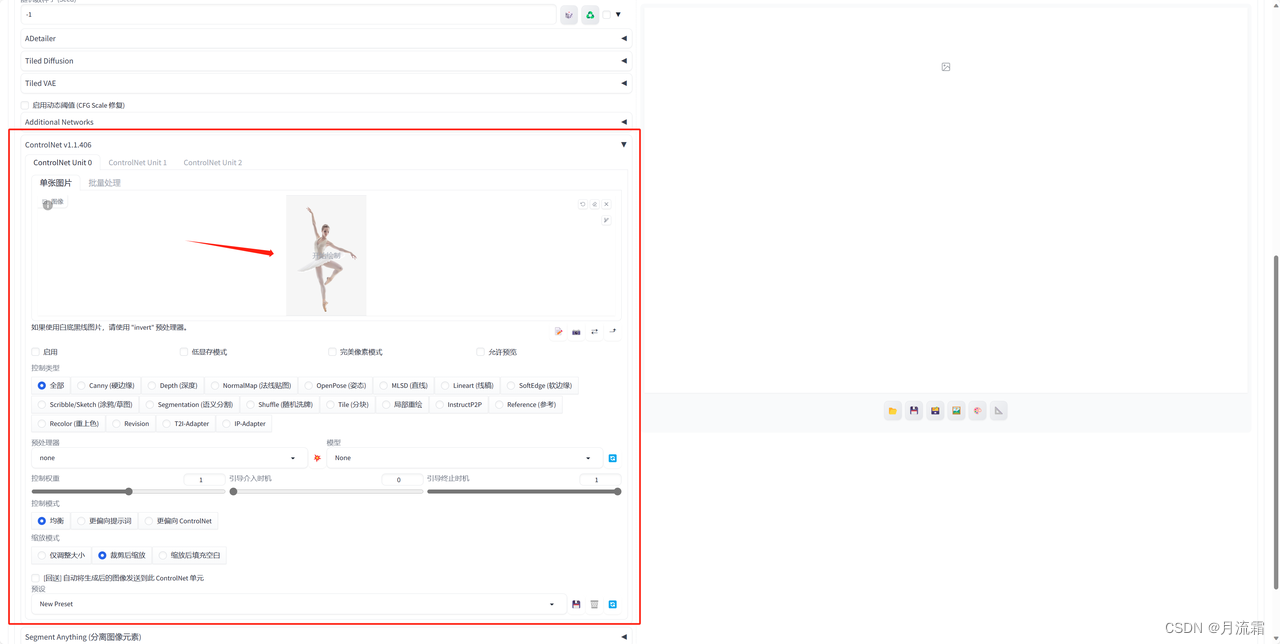
把这里的 启用 和 完美像素模式 打开
如果电脑配置比较低,还可以打开这个低显存模式
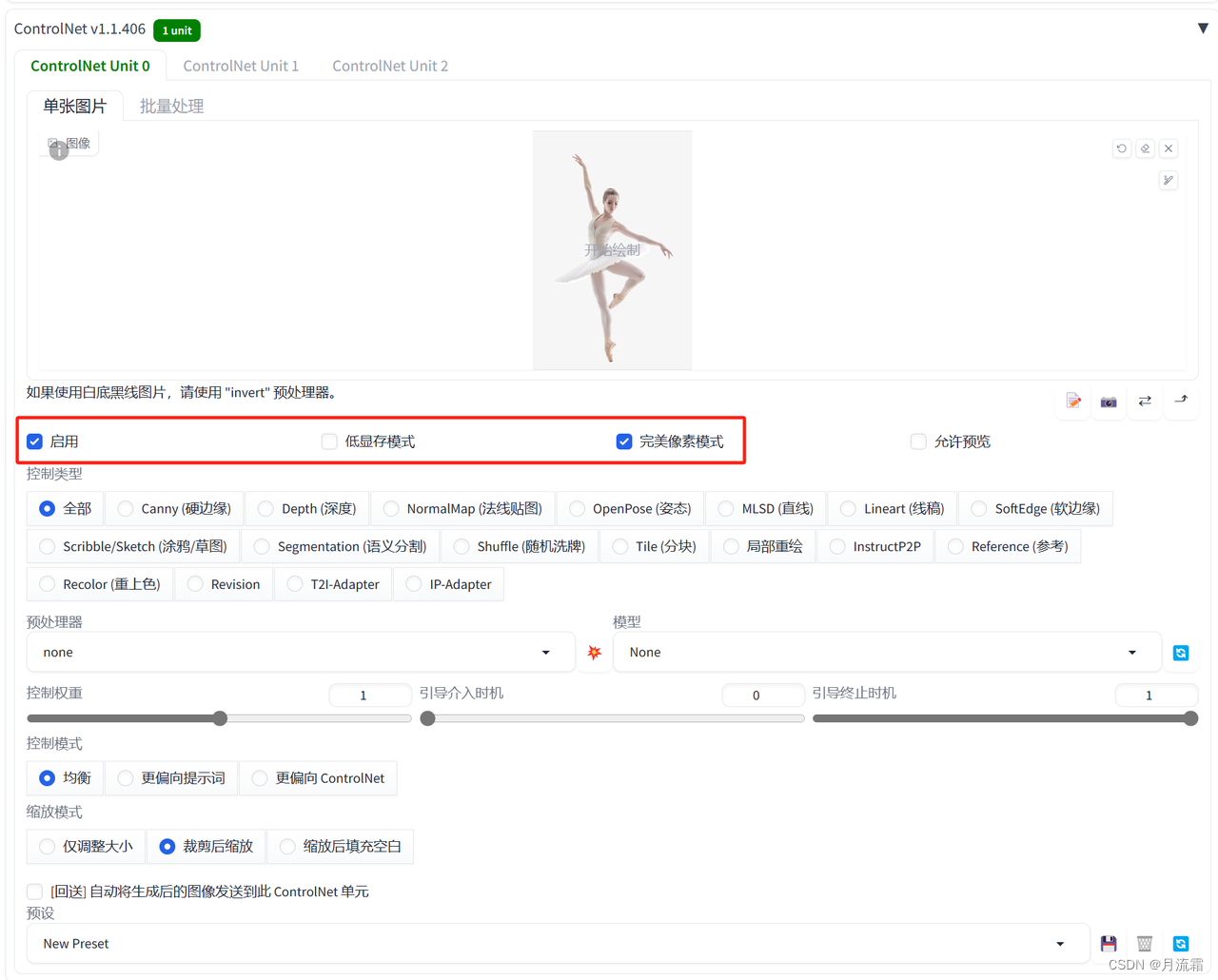
然后点击右边这个向上的小按钮,这样照片的尺寸就会自动同步到宽度和高度
如果发现同步过来的数值太大或者太小,我们可以按比例把这个数字除以2或者乘2

再往下看到控制类型,意思就是 我们要控制生成图片的什么地方
现在我们要控制的是人物的姿势
那就选openpose
下面就会自动加载预处理器和模型

简单来说,预处理器是用来识别我们上传的参考照片的,不同的预处理器识别出来的东西就不一样
模型就是将预处理器处理之后的结果加载到我们要生成的照片上面
点击爆炸按钮💥,就可以看到预处理之后的人物姿势线条
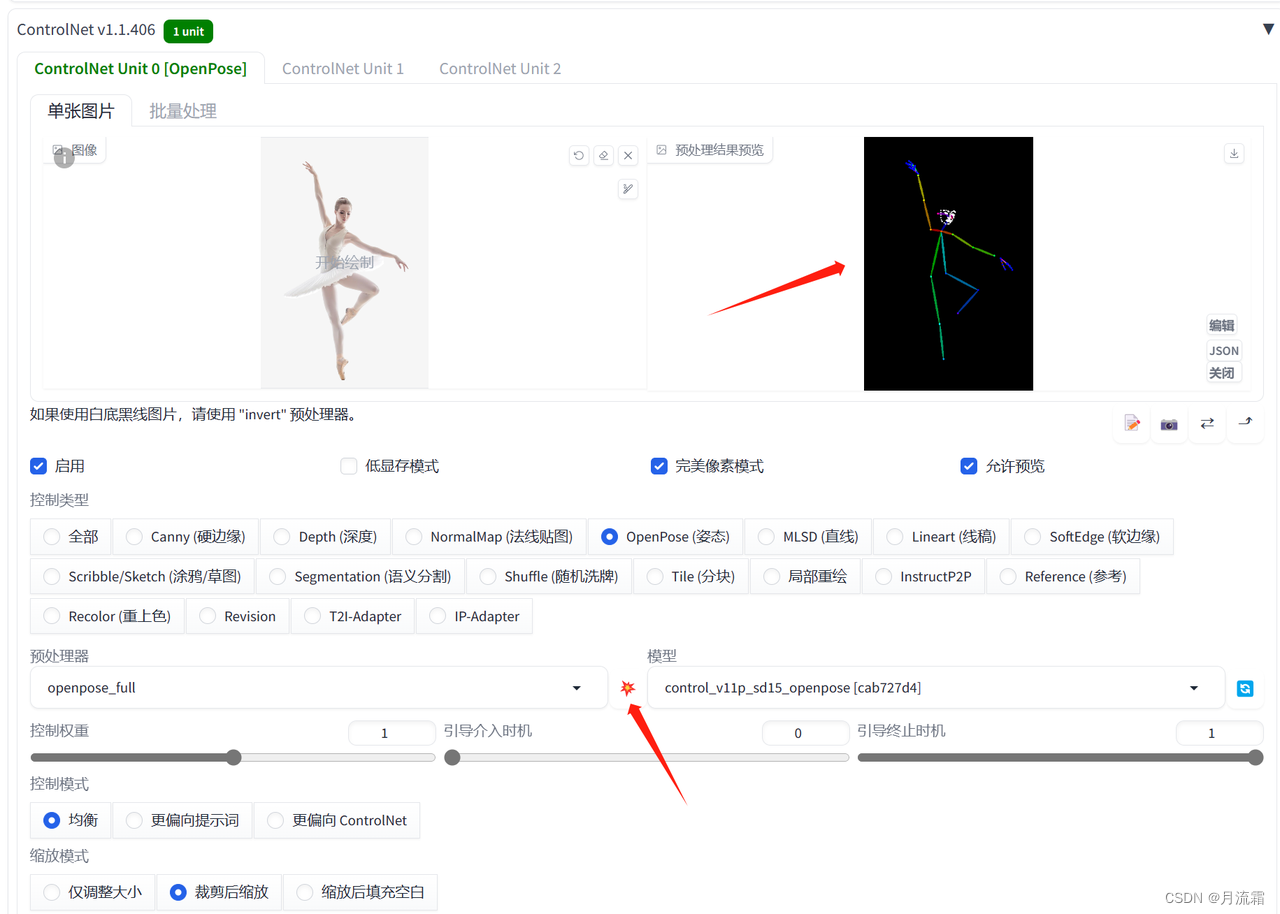
最后点击生成就可以了,小姐姐就会摆出和我们参考图一样的姿势


controlnet的不同功能的实现其实就是上传不一样的照片,然后选用不一样的预处理器和模型
一般情况下,预处理器和模型名字一样,是配套使用的
controlnet是辅助我们生成想要的照片的一个工具
我们的大模型和关键词也非常关键
要换照片风格一定要记得换大模型
接下来我们就看一下每一种预处理器和模型都有什么用
五、controlnet的分类讲解
我把17种模型,按照对照片的不同约束类型,分成了以下几类
有对人物姿势进行约束的,也有对照片里的线条进行约束的,还有对照片风格进行约束等等
现在我们就按照分类顺序,看看17种模型具体能干些什么
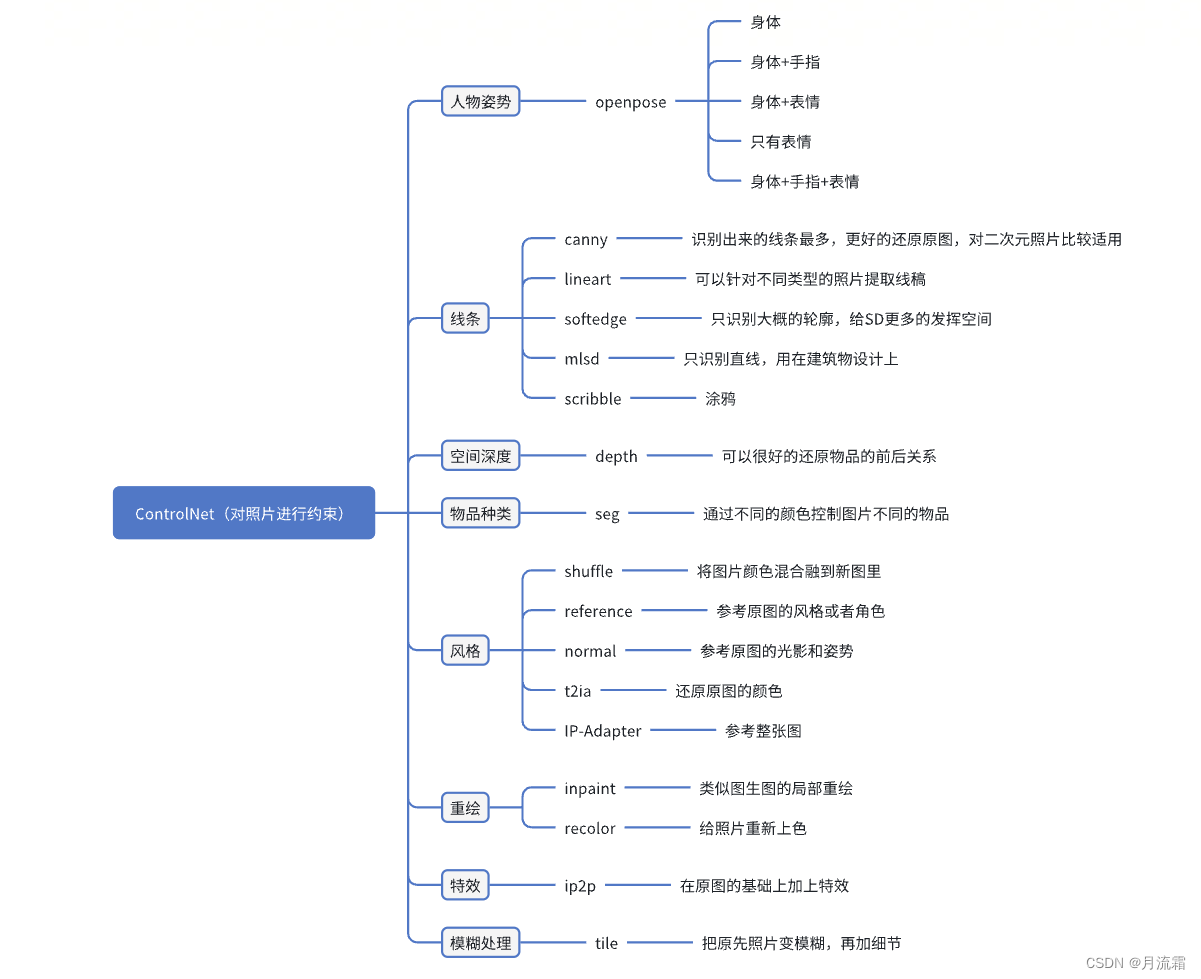
1.姿势约束
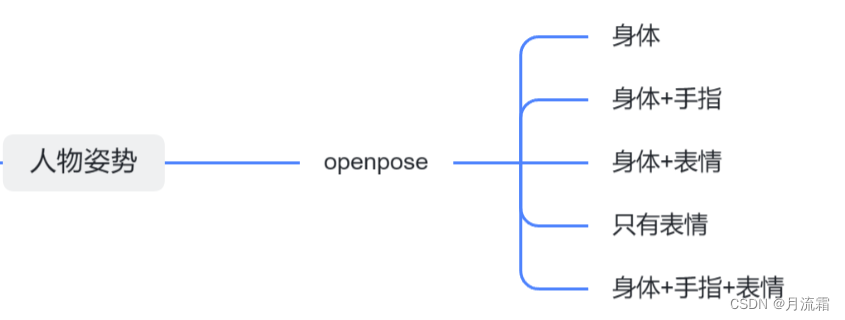
这一节讲的是openpose模型,主要控制生成照片人物的姿势
这里的姿势有身体姿势、表情、手指形态三个
可以只控制某一个或者两个,也可以三个一起控制
身体姿势
身体姿势+脸部表情
只有脸部表情
身体姿势+手指+表情
身体姿势+手指

01.控制身体姿势
一般情况下,在SD里面生成一张照片,照片人物的动作都是随机的
但controlnet可以让生成出来的人物摆出任何你想要的姿势


首先我们正常设置大模型和关键词
然后打开controlnet,上传自己想要生成的姿势照片
controlnet的模型选择:
预处理器:openpose 模型:openpose
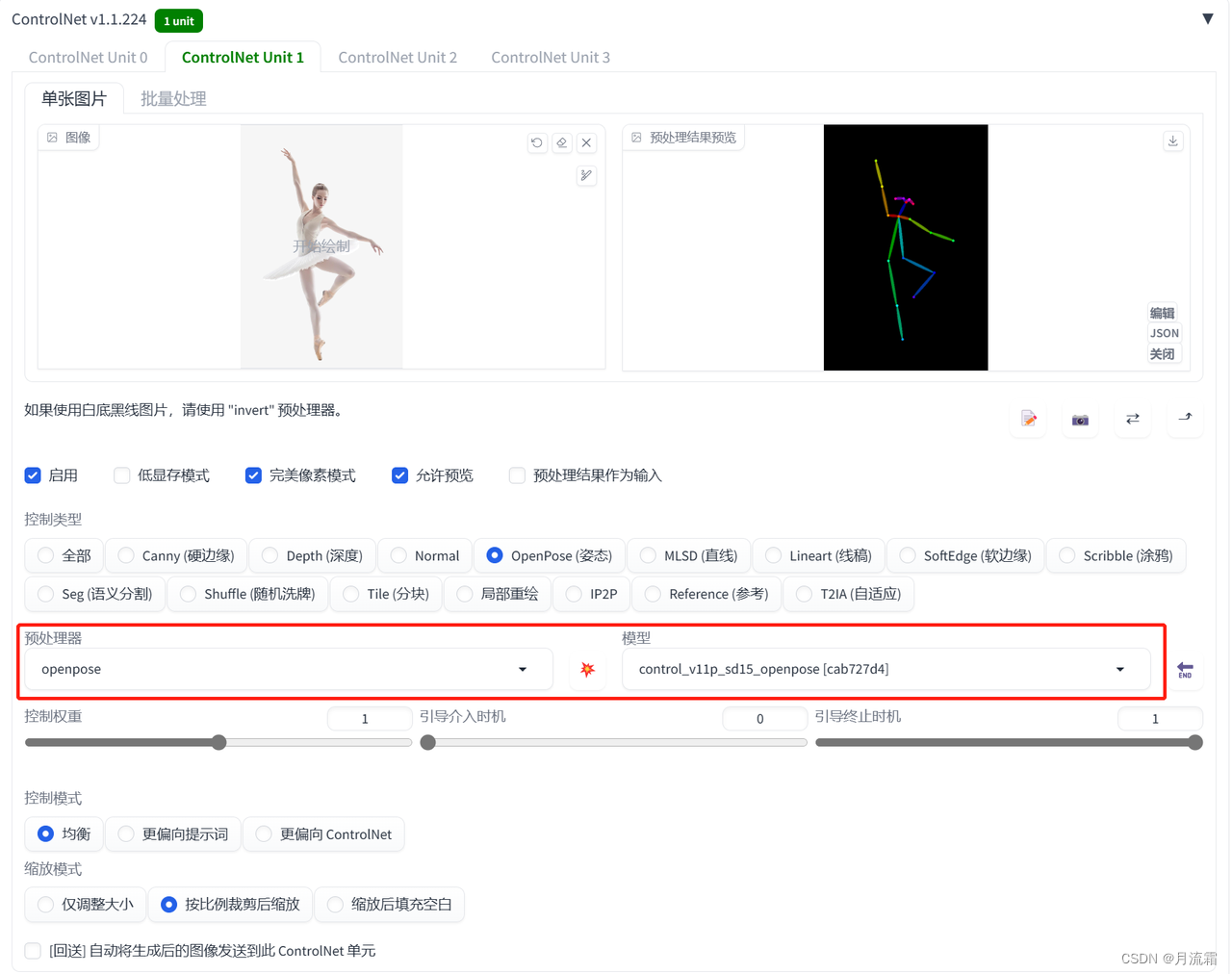
点击预处理的爆炸按钮就可以看到,模特的姿势被提取成了一个火柴人
里面的小圆点就是人体的重要关节节点

看看生成出来的照片,模特的姿势就几乎完全复刻出来了

02.控制人物姿势和手指
除了识别人物整体的姿势以外,还可以识别手指的骨骼
这样在一定程度下就可以避免生成多手指或者缺少手指的照片


具体的操作跟前面是一样的
只是预处理器的选择不同
controlnet的模型选择:
预处理器:openpose_hand 模型:openpose
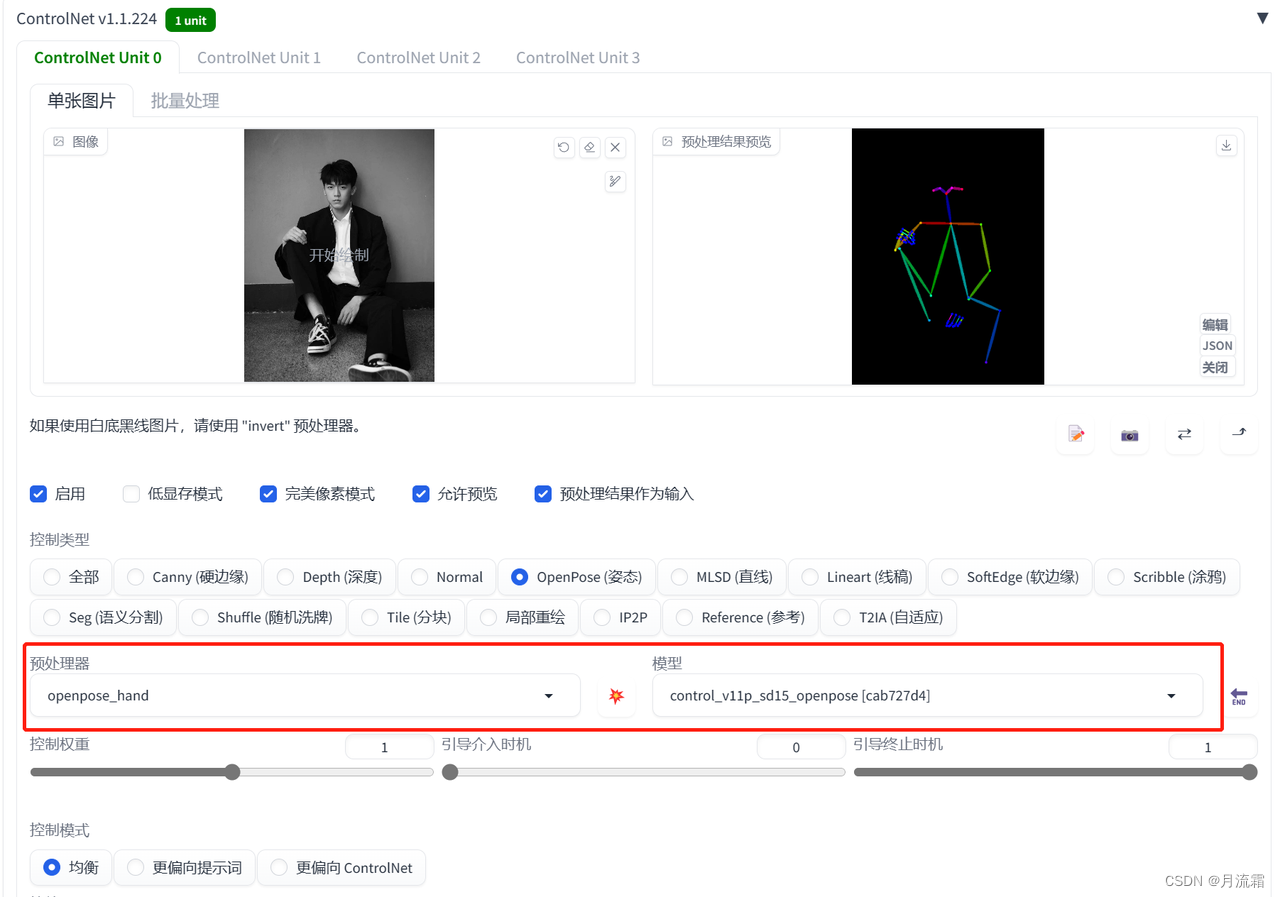
看看SD预处理之后的火柴人,在人体整体姿势的基础上,还多了线条和节点表示手指
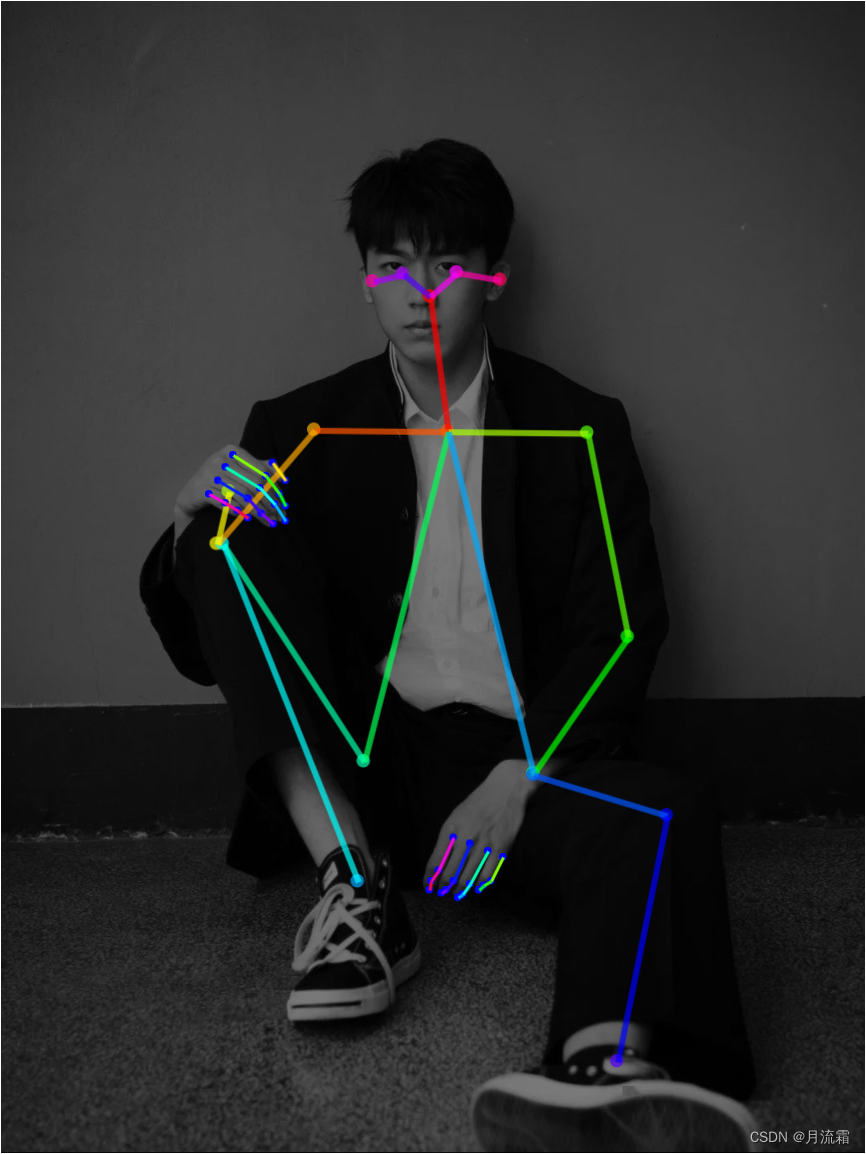
03.控制人物表情
openpose除了控制人物的姿势,还可以控制人物的表情
但是用controlnet复刻人物表情比较适合放特写的大头照
这样识别出来的五官才会更加精确
相对应的也只能生成出来大头照


这里我们又换了一个预处理器
controlnet的模型选择:
预处理器:openpose_faceonly 模型:openpose
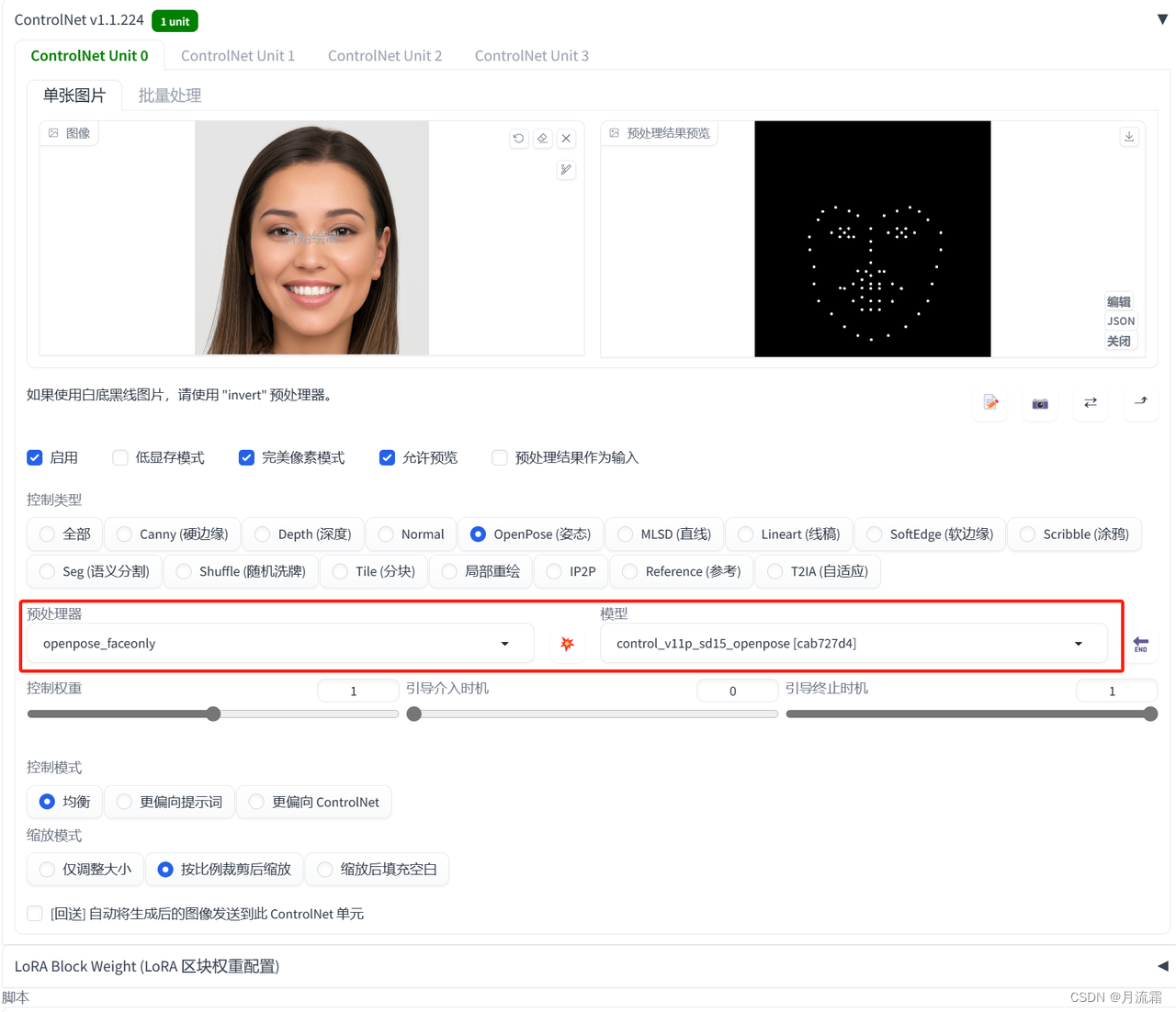
预处理之后就是把模特的脸型五官用点描出来

看看生成出来的照片,脸型和五官在一定程度上都还原了
但是,如果你生成的照片用了Lora
再用controlnet控制表情可能会导致生成出来的照片跟Lora的人不太像
因为生成出来的照片的人物五官和脸型都被controlnet影响了

04.全方面控制人物姿势
这里我们是把人物的整体姿势、手指、表情都复刻了


controlnet的模型选择:
预处理器:openpose_full 模型:openpose
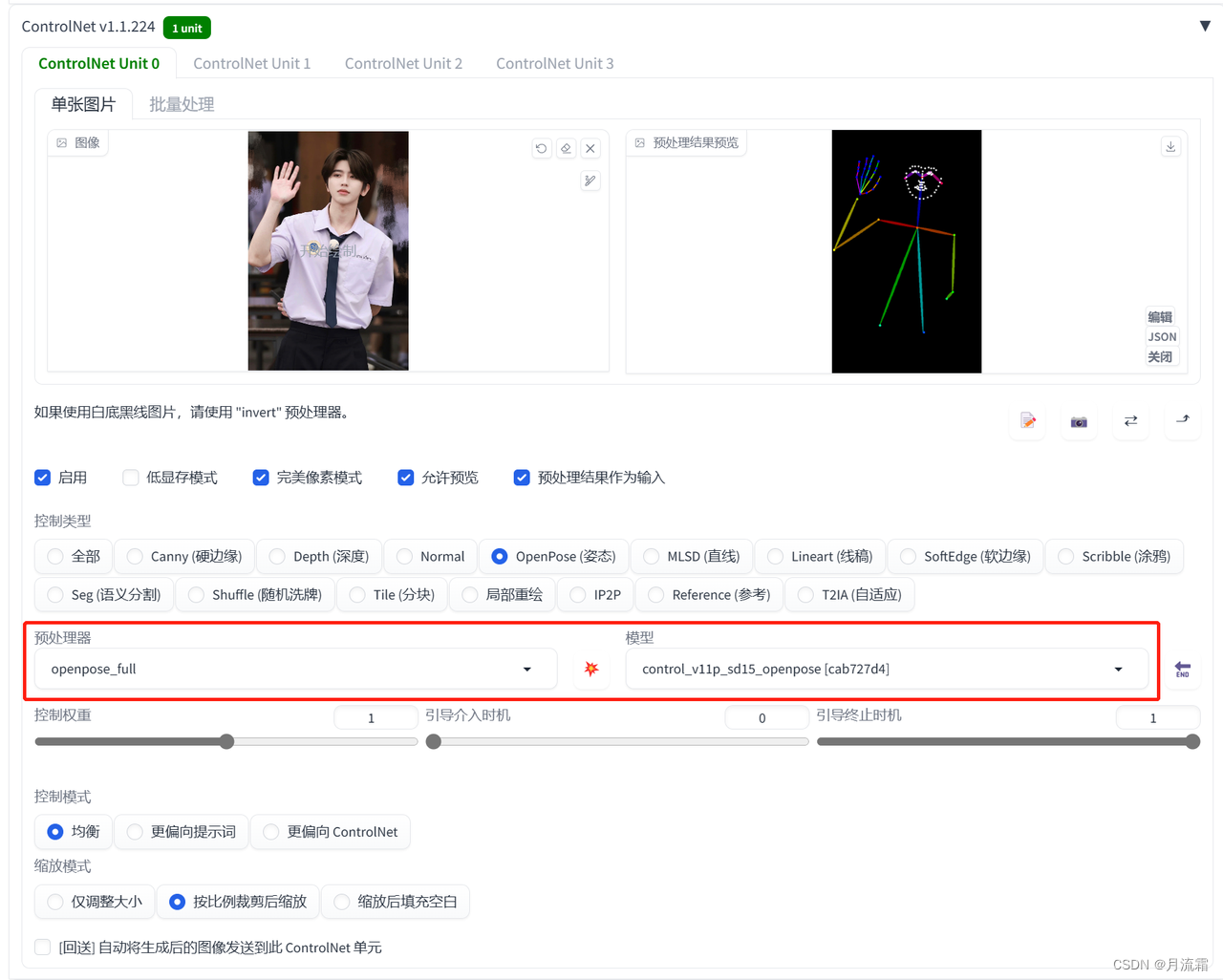
看看处理后的照片就会有我们上面说到的所有东西
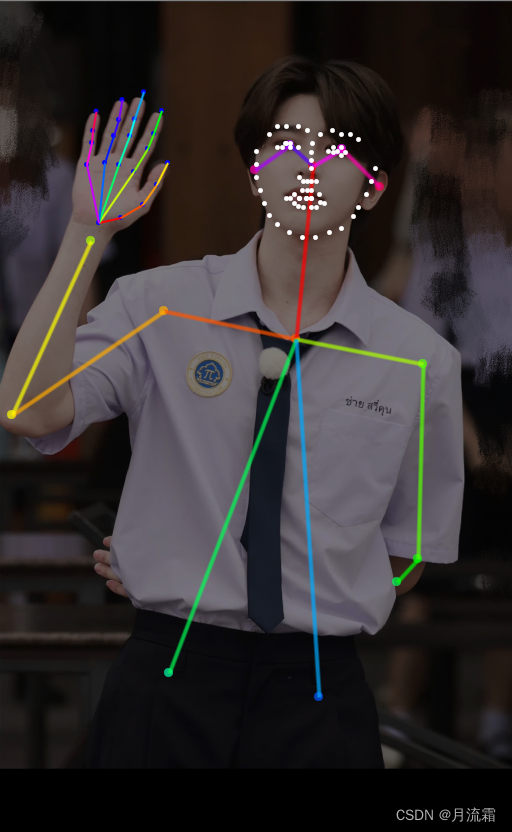
05.自由编辑火柴人
有时候预处理器处理出来的火柴人可能会不太准确
又或者我们需要更加细致的去调节
这时候我们可以再安装一个插件,这样我们就可以自己去调节预处理之后的火柴人
安装插件的方法:
①在“扩展”里点击“可下载”页面
②点击“加载扩展列表”
③在搜索框里输入“openpose”
④安装“sd-webui-openpose-editor”
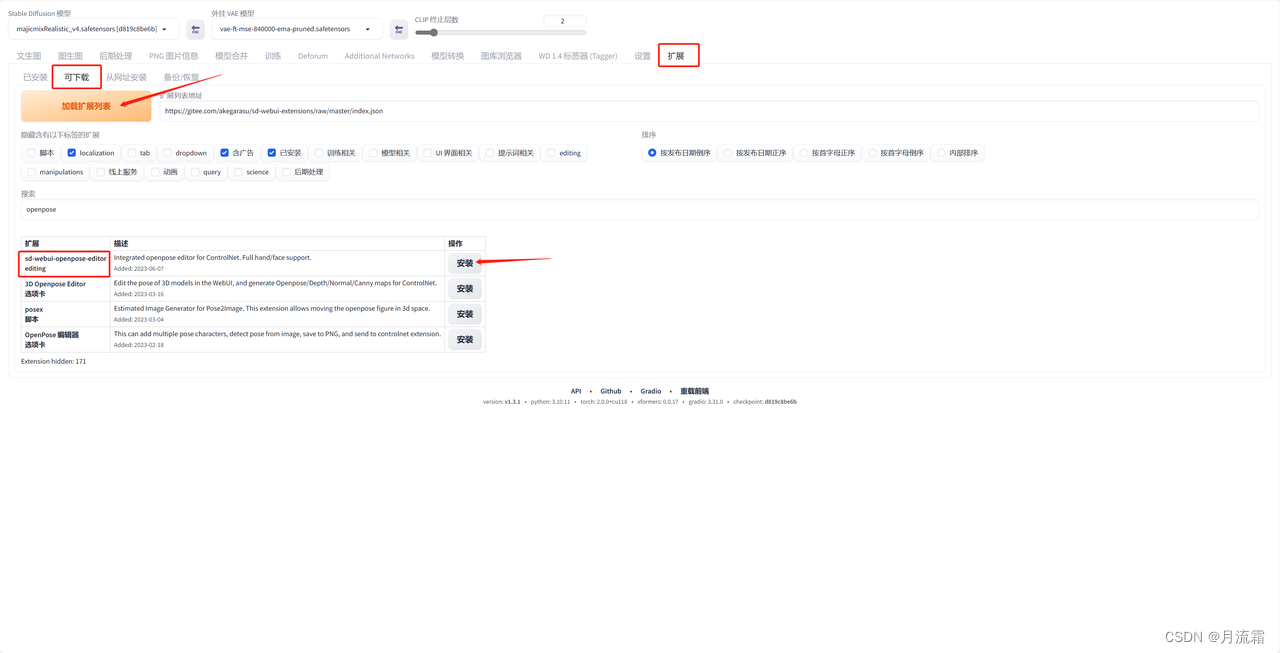
⑤点击“已安装”页面
⑥点击“应用更改并重载前端”按钮

这样插件就安装好啦!
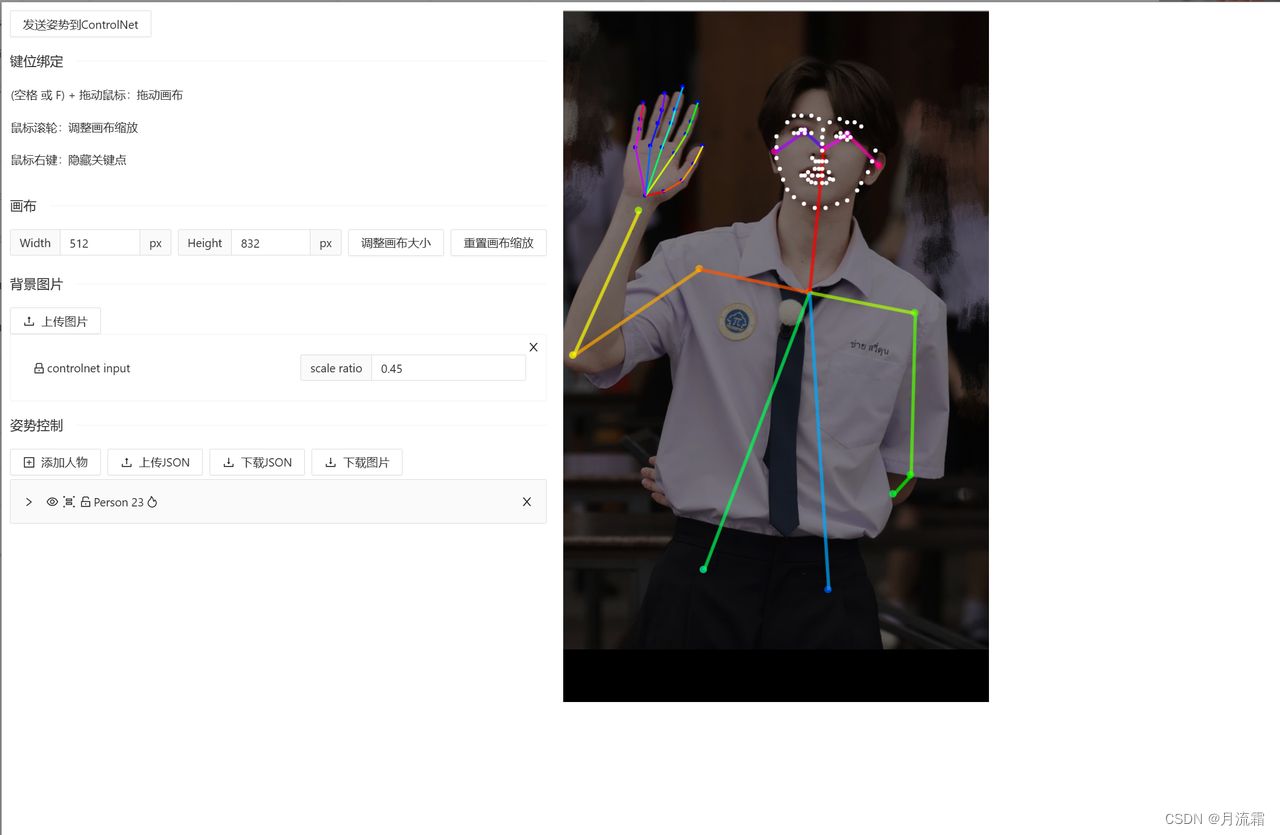
插件的使用方法:
接着我们回到controlnet里面
点击预处理后的图像旁边的“编辑”按钮,就可以自行去编辑火柴人的节点
如果打开编辑按钮是空白的,那就先点击一下预处理之后的图片,再去编辑
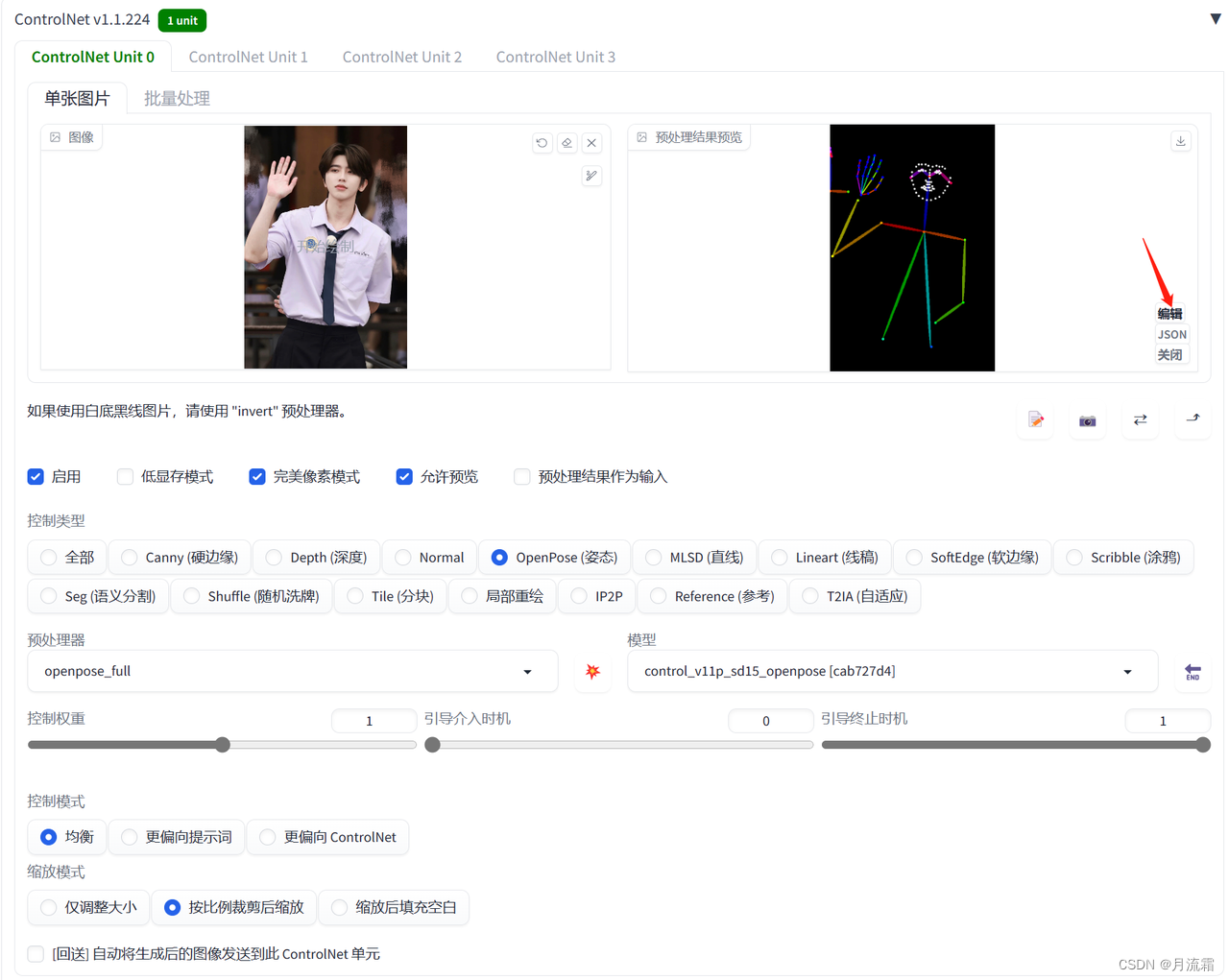
把鼠标放到圆形节点上面,就可以调整位置
调整好了之后,点击左上角的“发送姿势到controlnet”就可以啦

这样通过自己的调节,把腿的节点拉长,就可以生成一个大长腿美女了


06.小结
识别人体姿势有五个预处理器,在这里有一些我自己选预处理器的小技巧
在日常使用中,如果原图的手指骨骼比较清晰,可以用识别到手指的预处理器
如果识别出来的手指线条比较乱,自己调整也没调整好,那就只识别身体姿势
不然生成出来的照片手指反而更乱了
控制表情的最好用在生成近景特写图片,这样识别出来的才比较准确
2.线条约束
这一节会讲到lineart、canny、softedge、scribble、mlsd五种模型
它们都是用来提取画面的线稿,再用线稿生成新的照片

01.lineart
lineart是一个专门提取线稿的模型,可以针对不同类型的图片进行不同的处理
点击选择“Lineart”,预处理器和模型就会自动切换
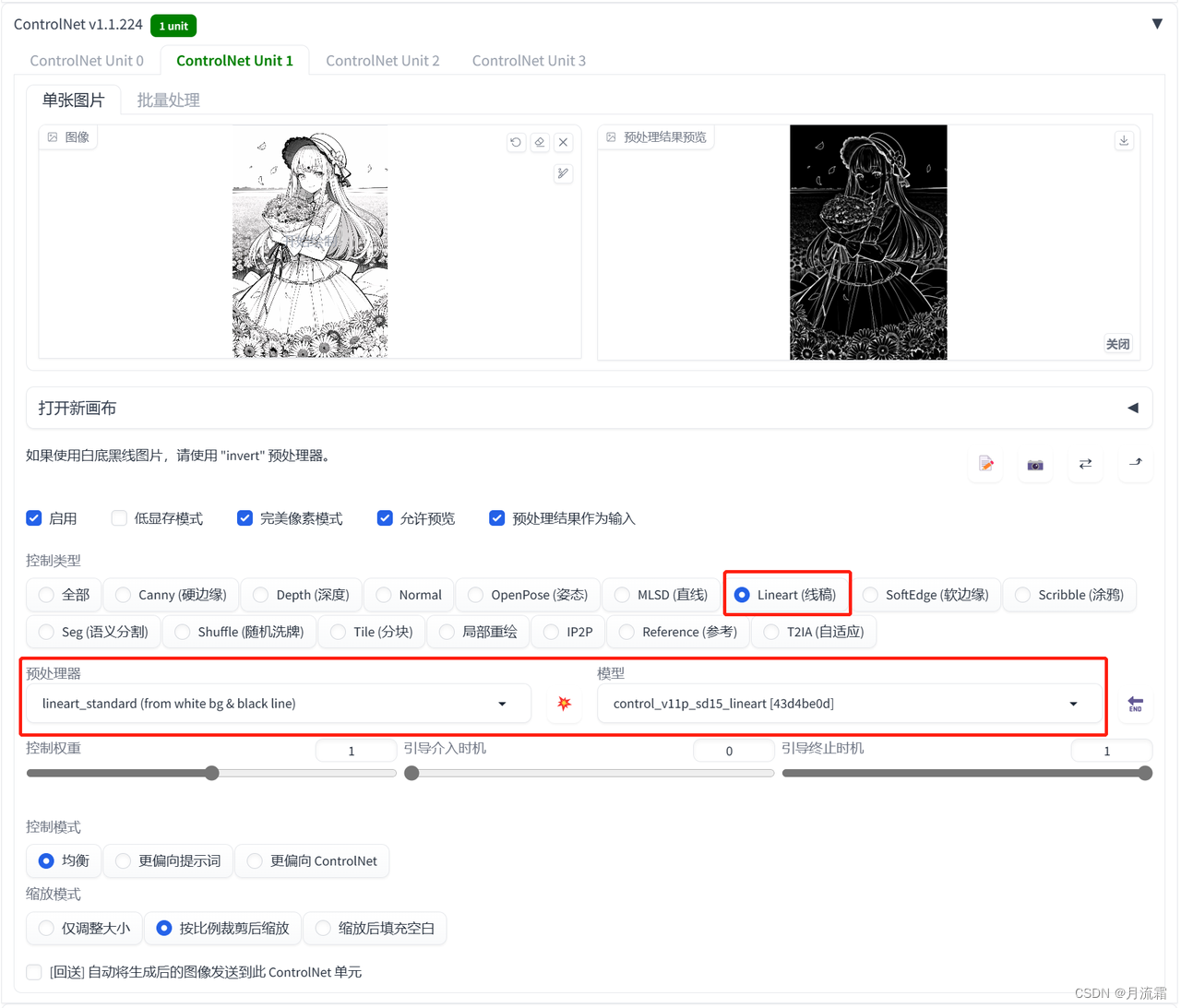
点开预处理器
里面的各种模型可以识别不同图片的线稿
动漫:lineart_anime 或 lineart_anime_denoise
素描:lineart_coarse
写实:lineart_realistic
黑白线稿:lineart_standard

①动漫照片
提取动漫的线稿,再重新上色


首先处理动漫照片记得要换二次元的大模型
然后关键词可以写一些质量词,然后描述一下照片里面有什么东西
另外需要注意的是,图片的分辨率大小要设置的和原先的比例一样
不然照片会自动裁剪放大
controlnet的模型选择:
预处理器:lineart_anime 或 lineart_anime_denoise 模型:lineart
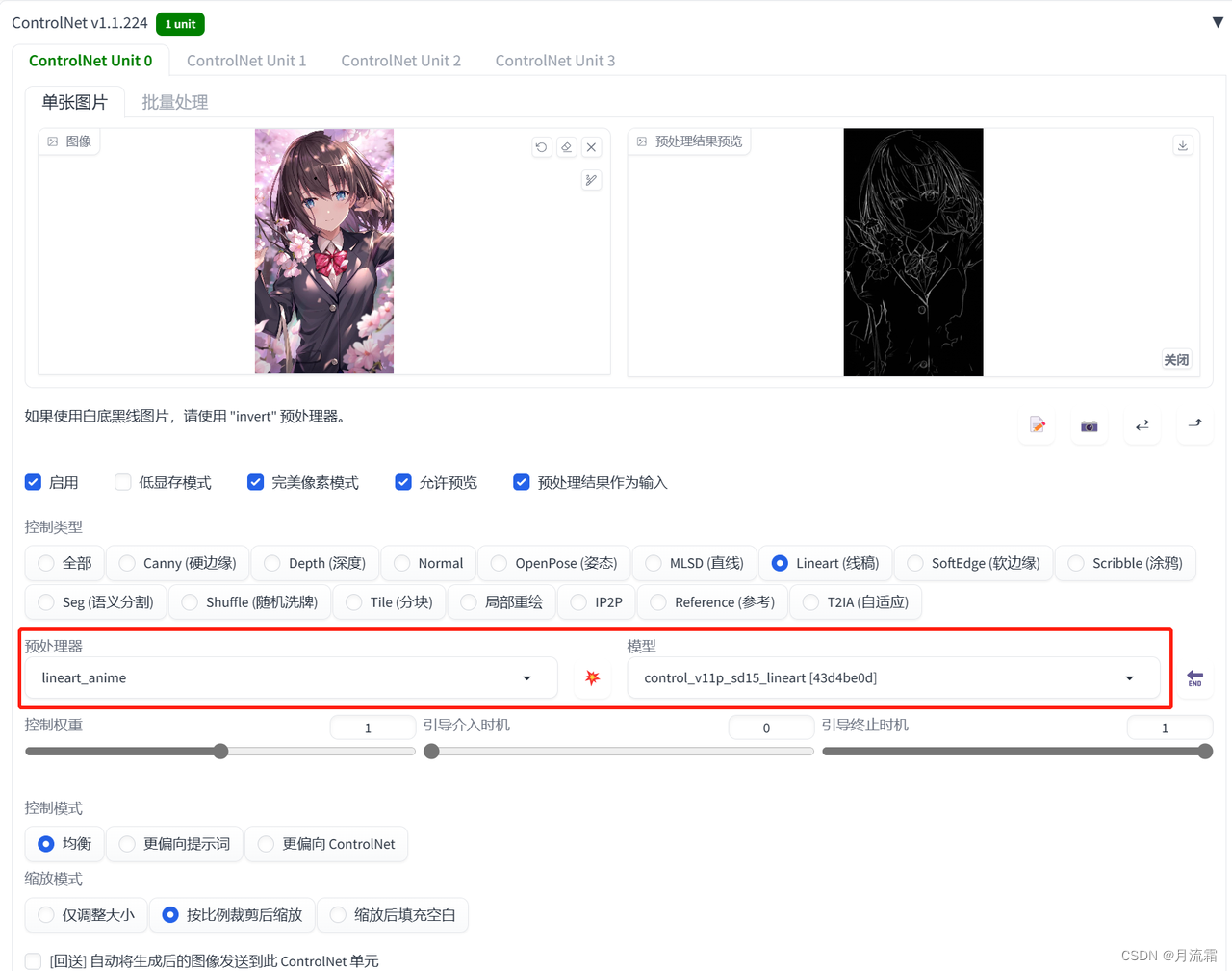
可以看一下两个预处理器出来的效果,选一个自己比较喜欢的就可以
lineart_anime


lineart_anime_denoise


②素描照片


controlnet的模型选择:
预处理器:lineart_coarse 模型:lineart
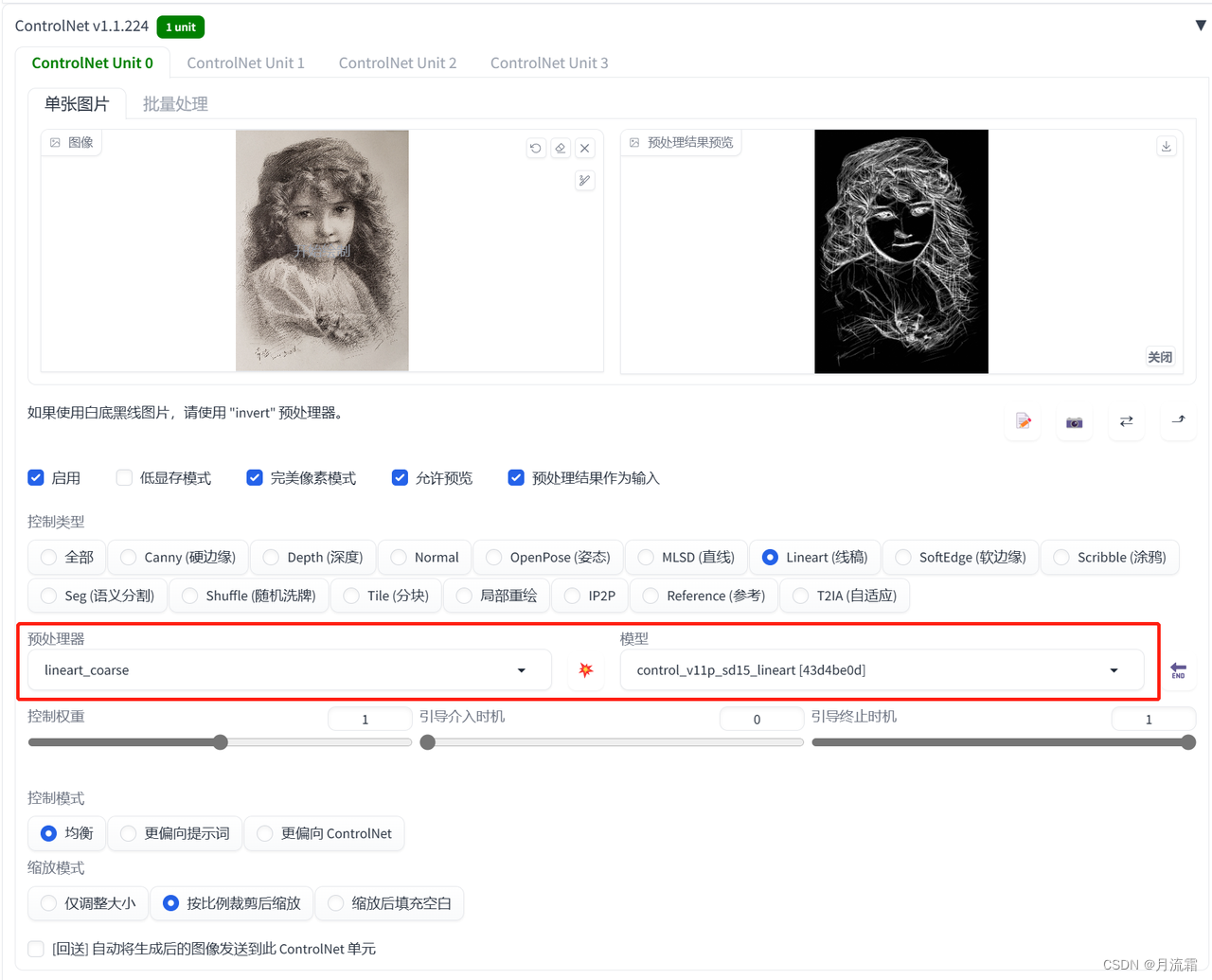
③写实照片
可以上传自己的照片,提取出线稿,然后生成自己的二次元头像


要生成二次元照片,一定要先换成合适的大模型
controlnet的模型选择:
预处理器:lineart_realistic 模型:lineart
因为真人照片换成二次元在五官比例上会不太匹配
这时候我们就要适当把controlnet的权重降低到0.6左右

还可以将真实的照片转换成真实的照片,生成一个长的很像的人


④黑白线稿



controlnet的模型选择:
预处理器:lineart_standard 模型:lineart
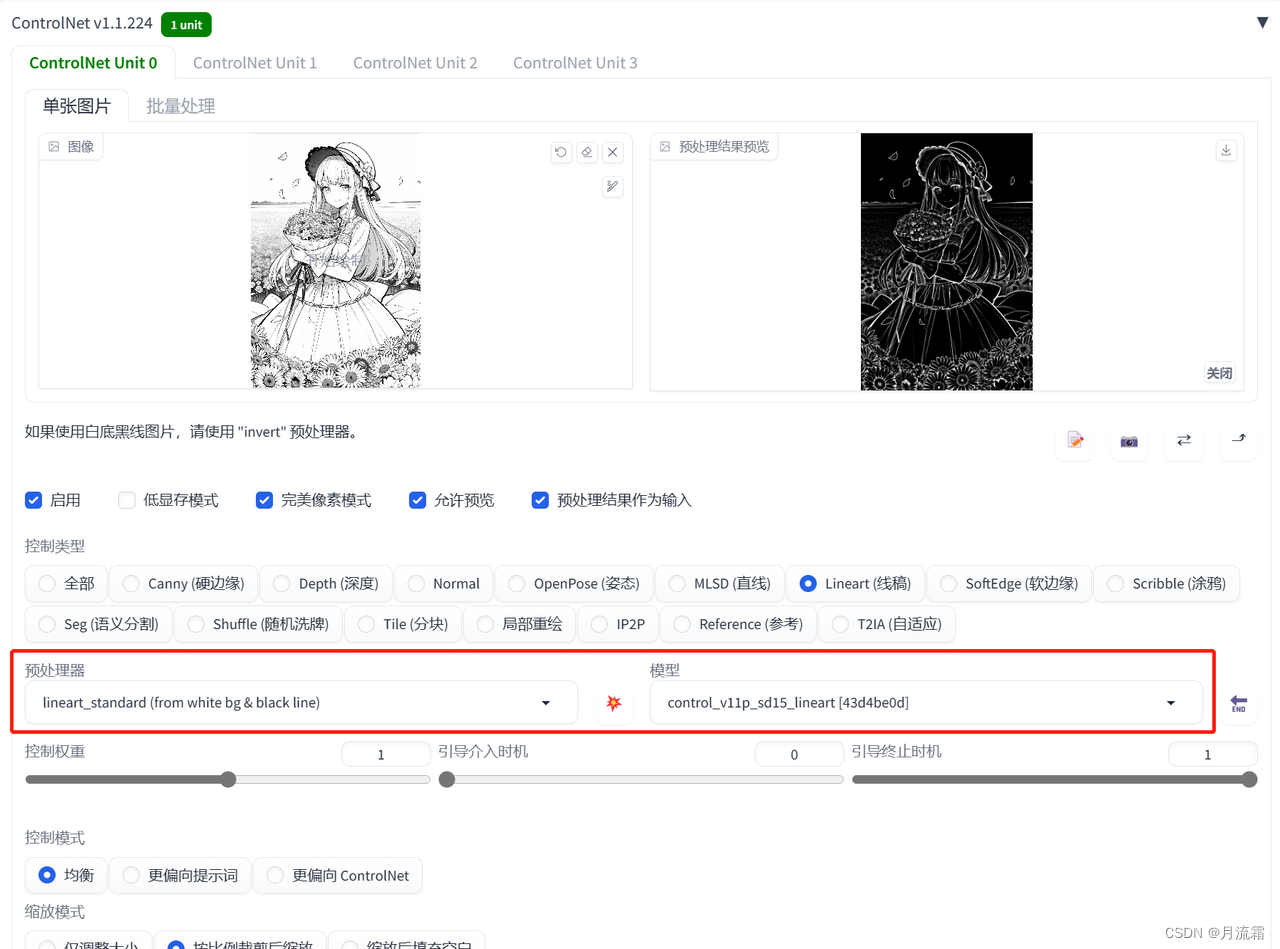
02.canny
canny可以识别到画面的最多的线条,这样就可以最大程度的还原照片
但是比较适合二次元照片


controlnet的模型选择:
预处理器:canny 模型:canny



03.softedge
softedge只能识别图片大概的轮廓细节,线条比较柔和,这样给SD发挥的空间就比较大


controlnet的模型选择:
预处理器:softedge_pidient 模型:softedge
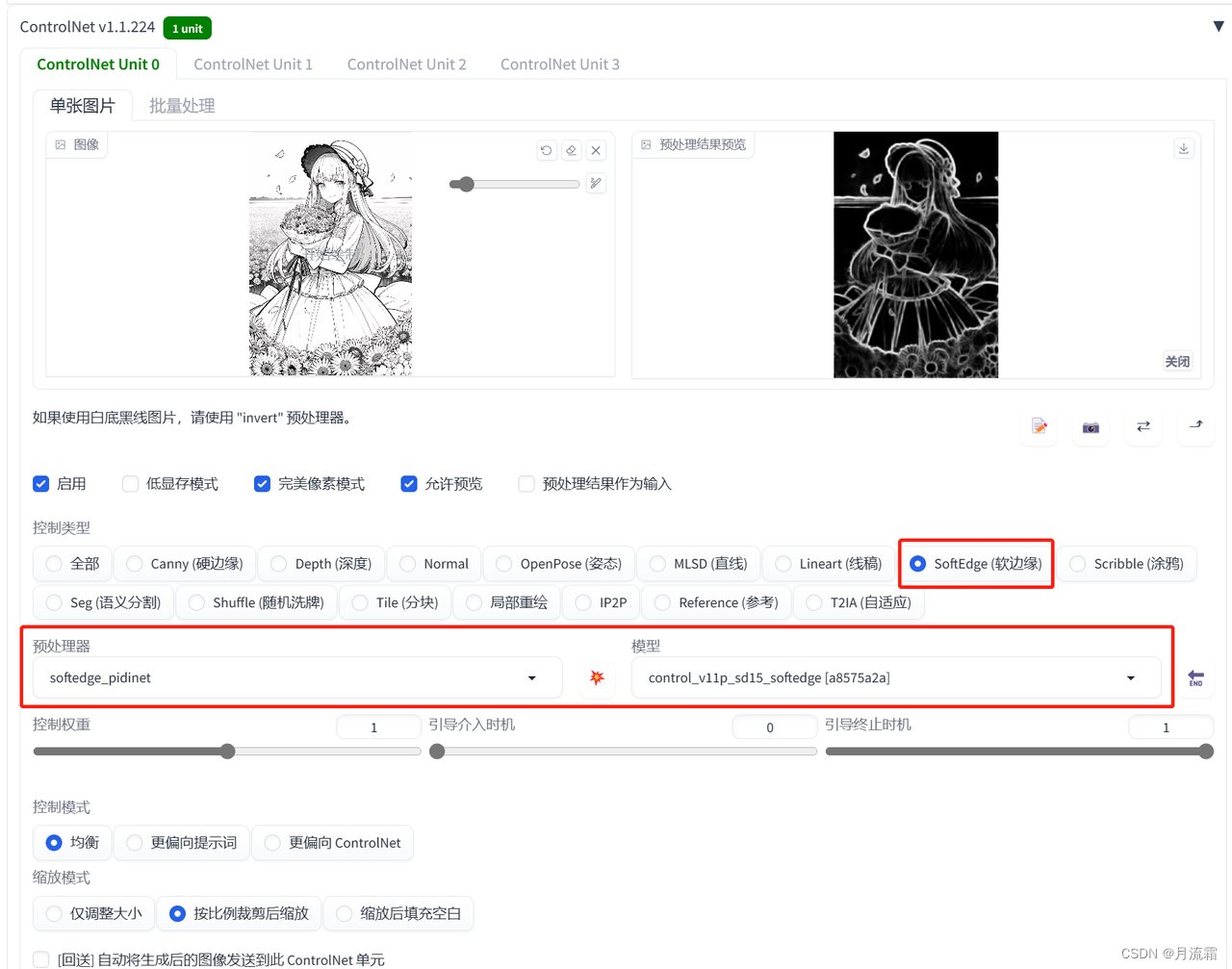


04.mlsd
这个模型只能识别直线,所以只适合拿来做房子的设计


controlnet的模型选择:
预处理器:mlsd 模型:mlsd
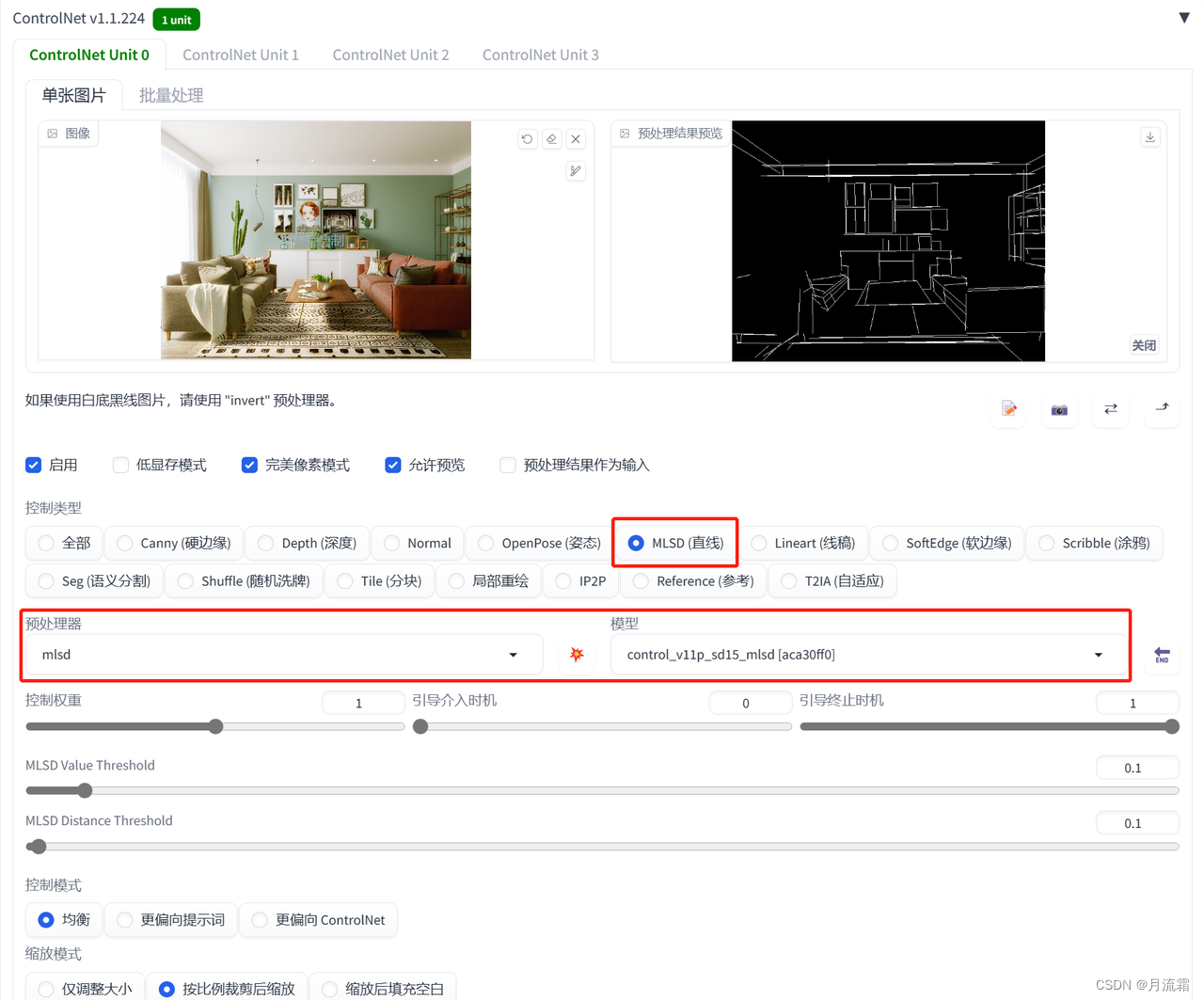
看看预处理出来的图,都只有直线
绿色植物和瓶子这些有弧度的线条都会被忽略掉

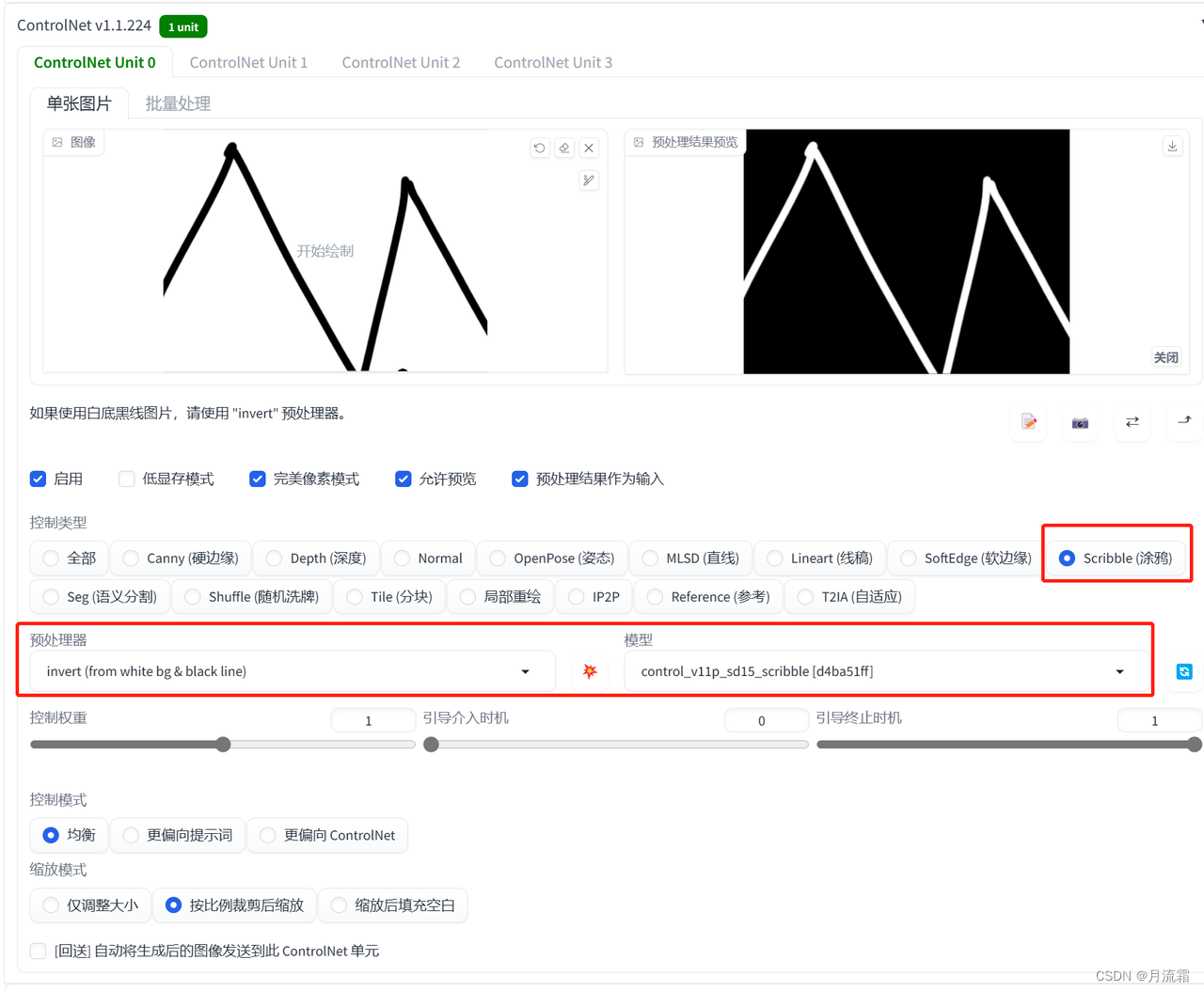
05.scribble
这一个功能和图生图的涂鸦功能一样
可以将自己随便画的东西放进去,通过输入关键词得到有着一样线条的照片

controlnet的模型选择:
预处理器:invert 模型:scribble
06.小结
识别线稿的模型有很多,如果你不知道什么情况下用哪个好,可以参考一下我的选择
1.想最大程度还原照片:canny
2.只想控制构图,给SD更多可以变化的地方:softedge、scribble
3.真人、素描等照片:lineart
4.建筑物装修:mlsd
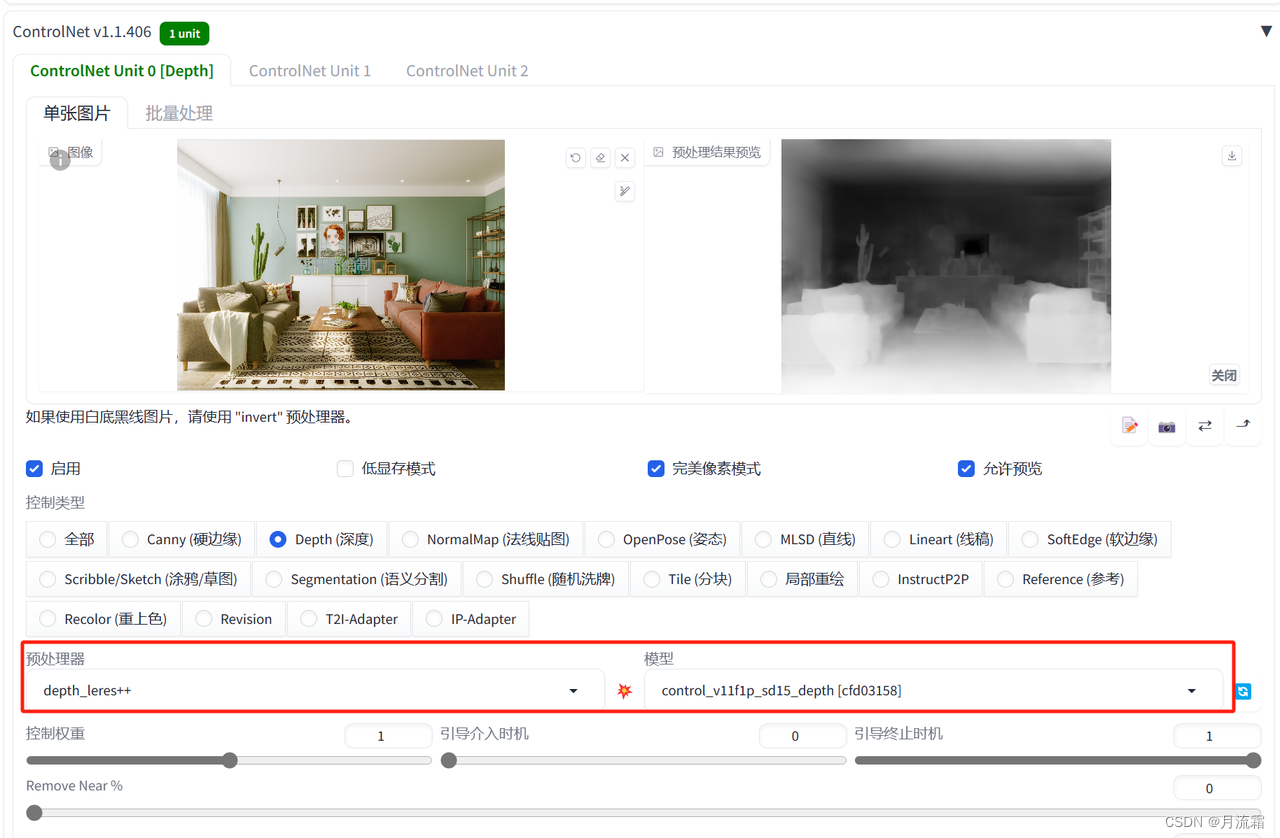
3.空间深度约束——depth
能够很好的复刻房子线条,而且物品的距离镜头的前后顺序比较清晰


controlnet的模型选择:
预处理器:depth_leres++ 模型:depth
4.物品种类约束——seg
segmentation,语义分割模型
它可以将照片上不同种类的东西,用不同的颜色表示出来
这样我们新生成的图片里的元素就会跟原图一模一样


controlnet的模型选择:
预处理器:seg_ofade20k 模型:seg
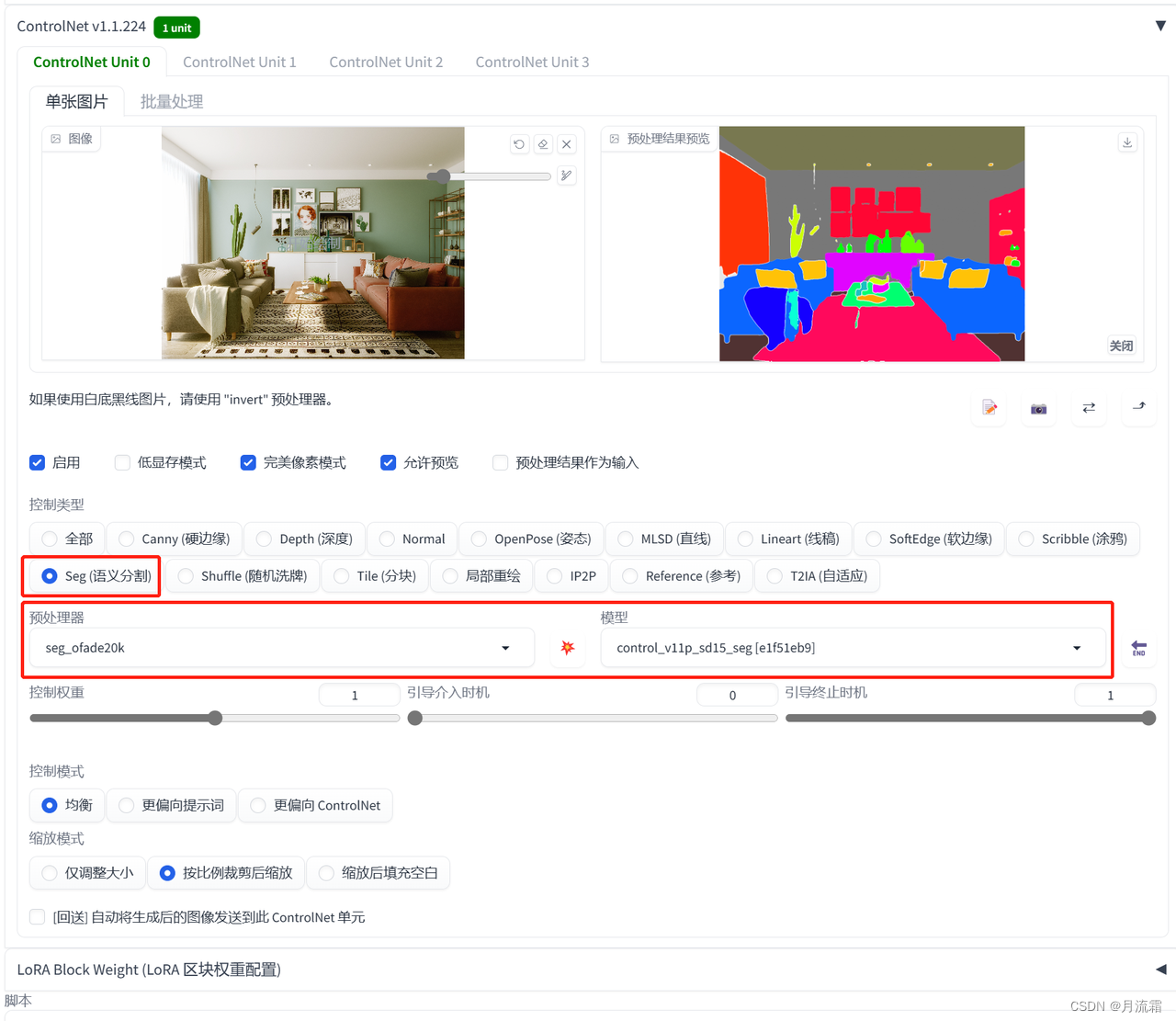
可以把seg色块图下载下来,自己到ps或者其他修图软件改照片物体的颜色
这样SD就会根据颜色生成出来特定的某样东西
网盘链接里有一份文档,可以看到不同的颜色代表什么物品


例如我可以在ps上面用代表人的颜色画上人的形状
这样生成的照片就在原来的基础上多了一个人


小结
看到这里建筑物装修已经有三种模型可以处理了
1.只还原整体的结构:mlsd
2.还原物品的先后关系:depth
3.比较好的还原原图有的物品,想自己后期编辑色块,改变室内装修结构:seg
depth和seg除了用在建筑上,还可以用在人物照片
5.风格约束
这一节会讲到shuffle、reference、normal、t2ia、IP-Adapter五个模型

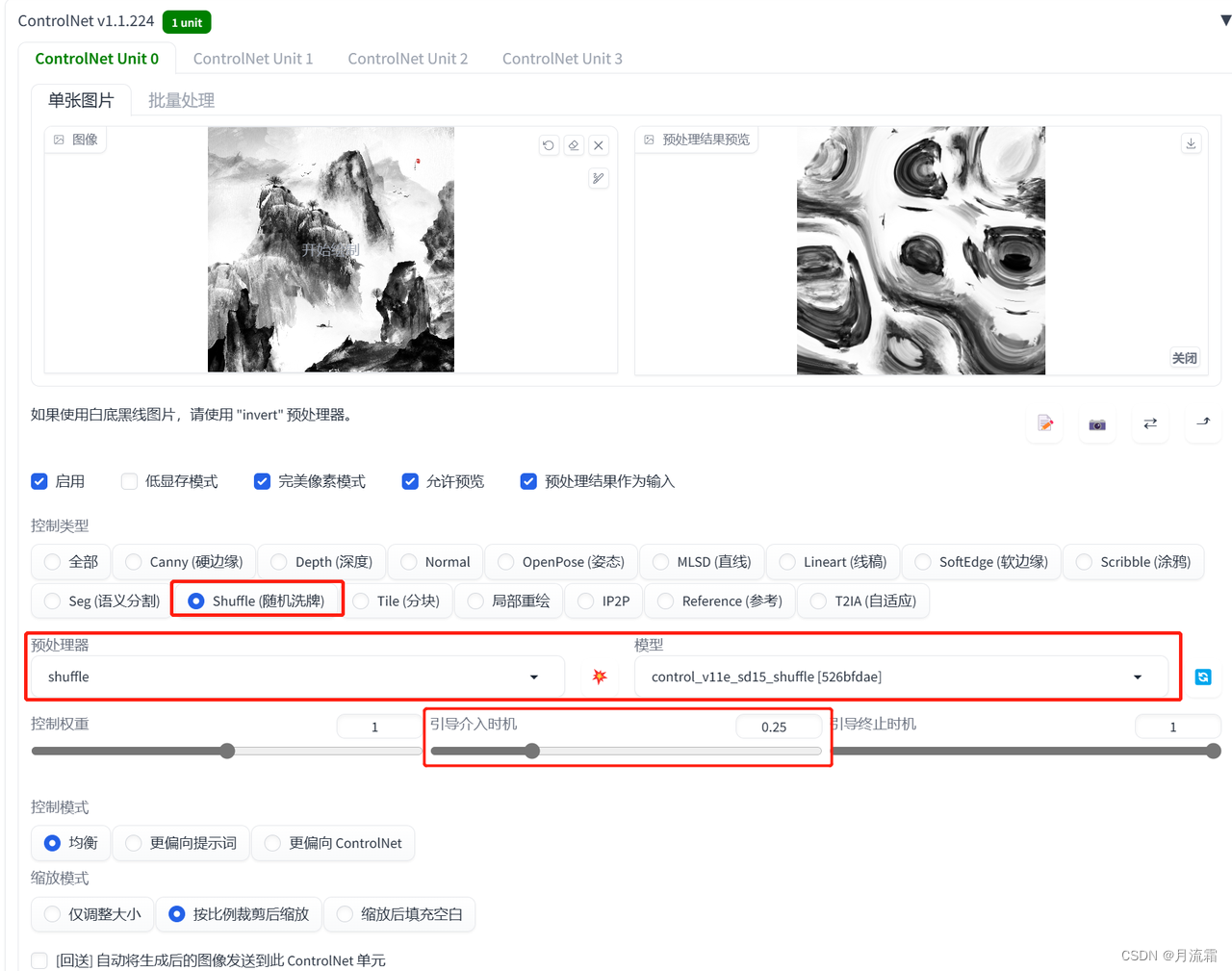
01.shuffle
shuffle是将参考图的颜色融合到一起,然后用融合后的颜色生成新的图片
下面第一张是原图,其他三张分别是由水墨画、油画、赛博朋克风格的图片转移过来的画风




controlnet的模型选择:
预处理器:shuffle 模型:shuffle
用shuffle可能会影响自己原图的形状,可以稍微调整一下“引导介入时机”的参数
设置在0.2~0.3之间就差不多
先生成出来大体的形状再去改变画风
或者用两个controlnet:一个固定线稿,一个影响画风
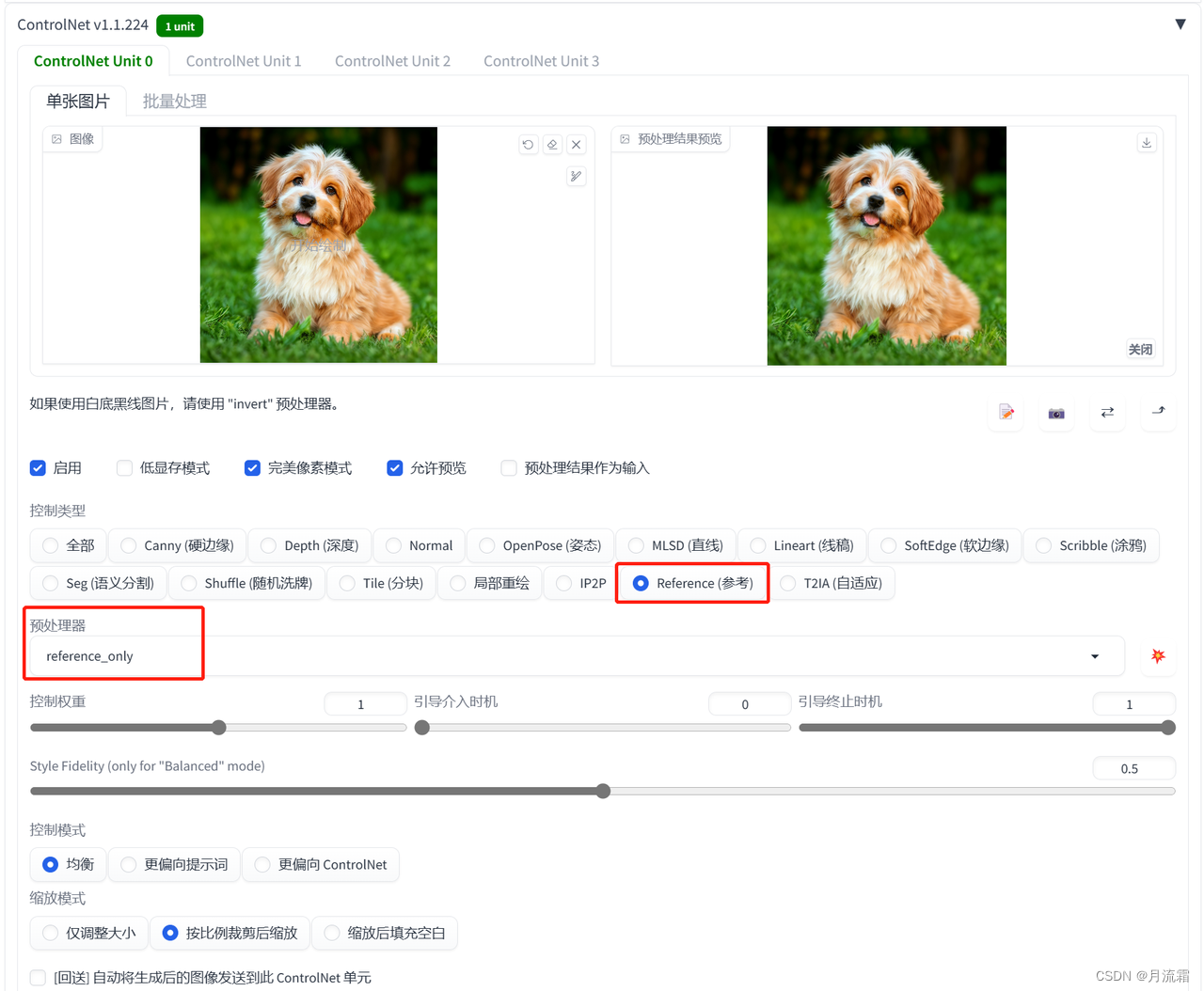
02.reference
可以很好的还原原图的角色
①让照片动起来
让坐着的小狗跑起来


选择写实的大模型
然后在关键词里面输入:一只狗在草地上快乐地奔跑
controlnet的模型选择:
预处理器:reference 不用模型
②还原角色
给SD一张人物角色图,它会根据人物的五官、发型还原这个人物


具体操作方法和上面是一样的
关键词还可以加上情绪的描述,或者不一样的服装发型


03.Normal
这个模型可以参考原图的明暗关系,并且还原原图的姿势


controlnet的模型选择:
预处理器:normal_bae 模型:normalbae

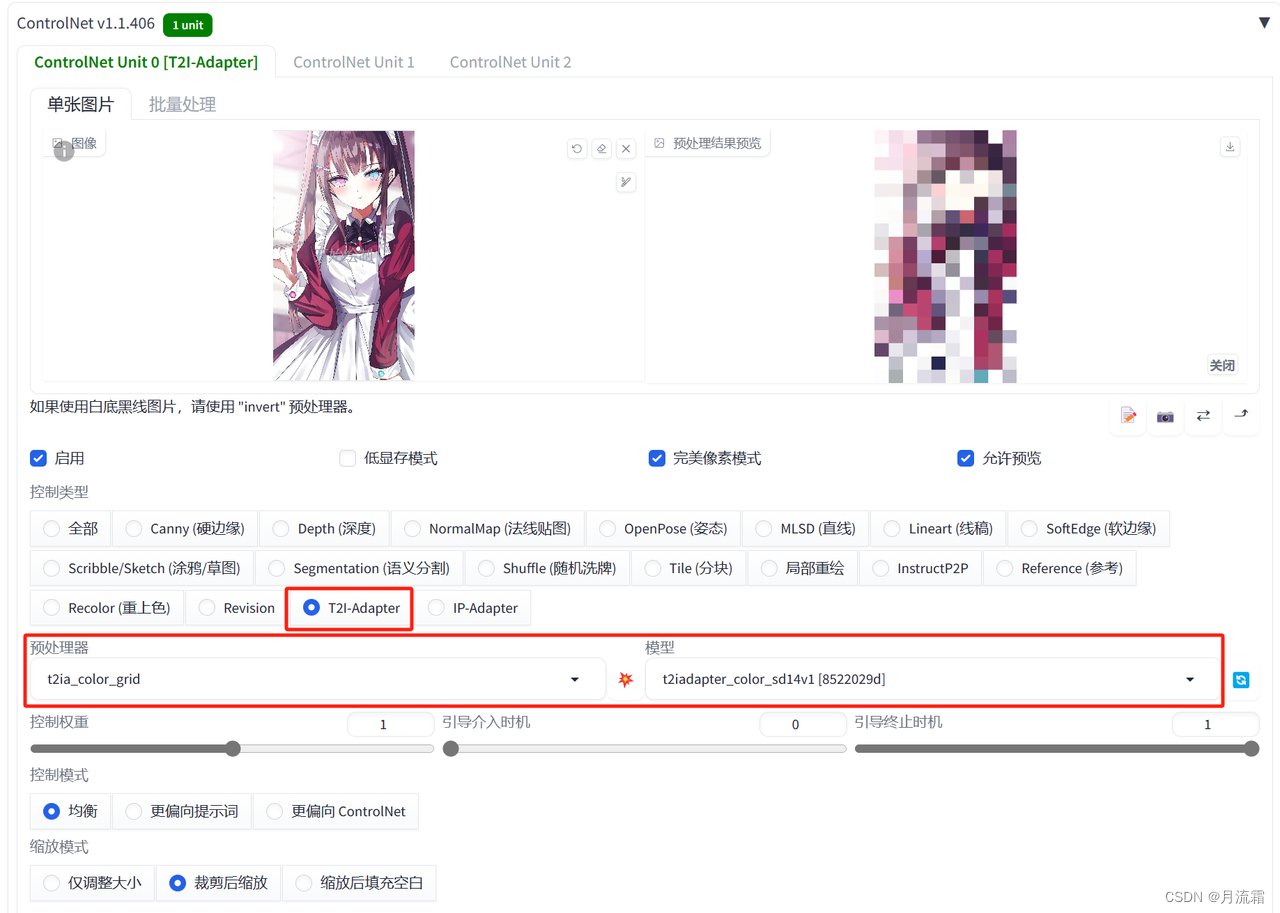
04.t2ia
t2ia这个模型比较特殊,不同的预处理器要用到不同的模型
它的主要功能有3个
1.将原图的颜色模糊成马赛克再重新生成图片
2.提取素描的线稿,生成真人照片(这个不好用,直接用lineart就行)
3.参考原图风格,生成相似风格的照片
参考原图的颜色,将原图模糊成马赛克,再生成图片


controlnet的模型选择:
预处理器:t2ia_color_grid 模型:t2iadapter_color
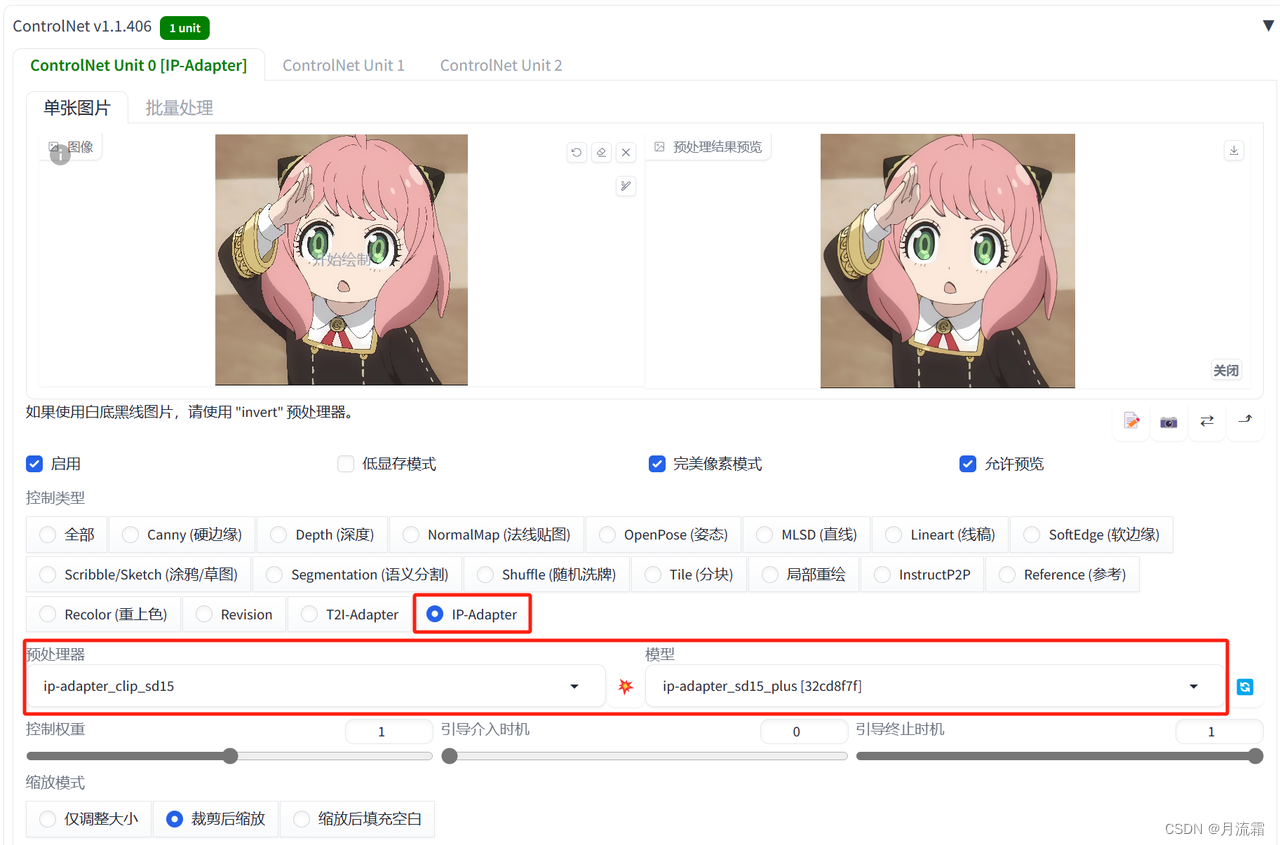
05.IP-Adapter
参考原图的全部内容
不管是风格、还是人物形象,都可以得到还原


controlnet的模型选择:
预处理器:ip-adpter_clip 模型:ip-adpter_sd15
6.重绘
重绘分为inpaint和recolor
01.Inpaint
和图生图里的局部重绘差不多,但是inpaint可以将重绘的地方跟原图融合的更好一点
①消除图片信息



关键词填写照片背景的描述词
controlnet的模型选择:
预处理器:inpaint_global_harmonious 模型:inpaint
inpaint_global_harmonious预处理器是整张图进行重绘
重绘之后整体融合比较好,但是重绘之后的图片色调会改变
inpaint_only只重绘涂黑的地方
为了重绘之后的图片更像原图,可以把控制权重拉满
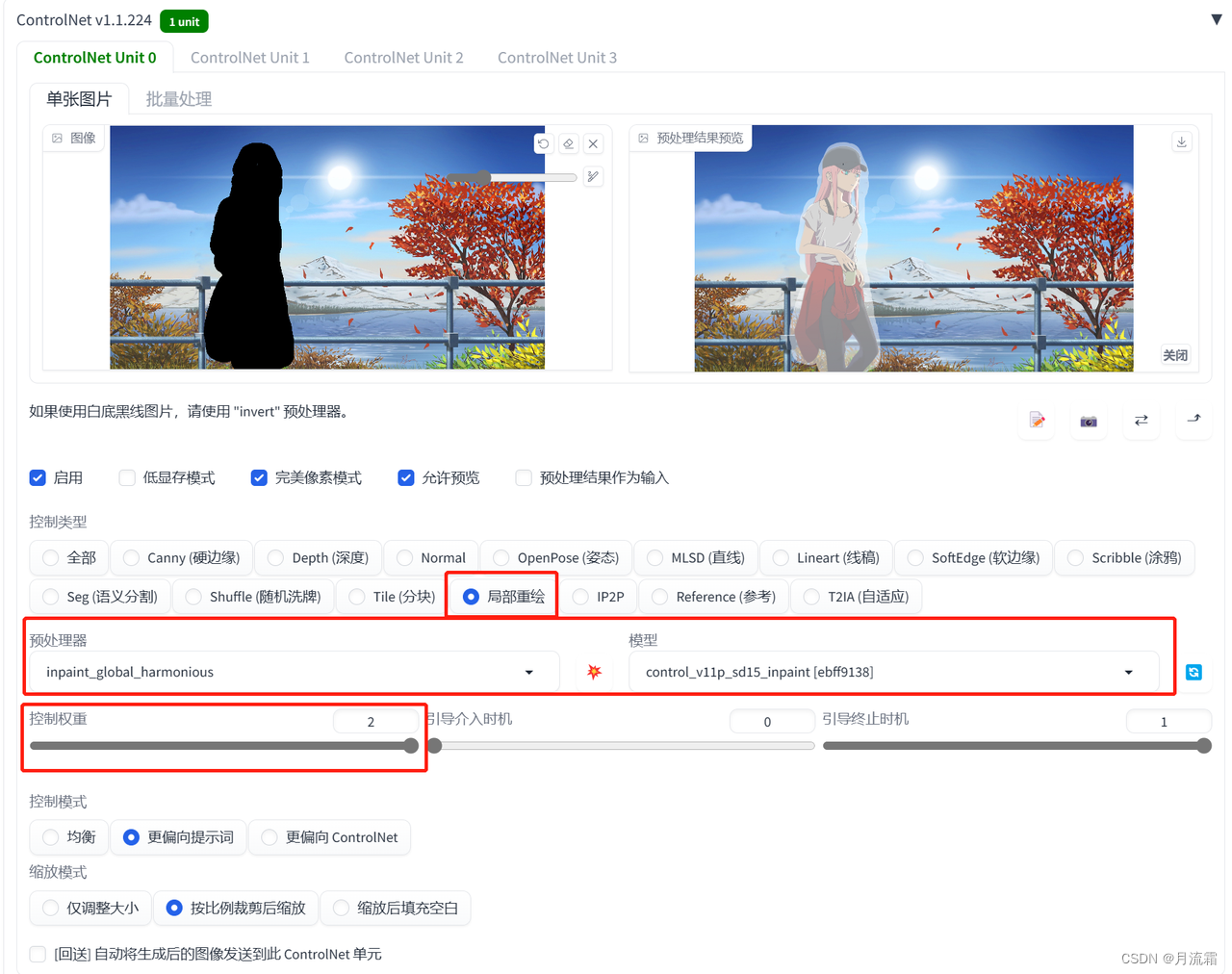
可以看看在图生图局部重绘出来的效果,是不如inpaint的
这张图是我跑了十几张图之后选的比较好的一张

②给人物换衣服


操作方法和上面一样,只是关键词的描述不一样
02.Recolor
recolor模型可以给照片重新上色
①给黑白老照片上色


controlnet的模型选择:
预处理器:recolor_luminance 模型:ioclad_sd15_recolor

②给人物头发、衣服换颜色


只要在关键词里面输入对应的“绿色头发”就可以了
controlnet的模型选择:
预处理器:recolor_luminance 模型:ioclad_sd15_recolor
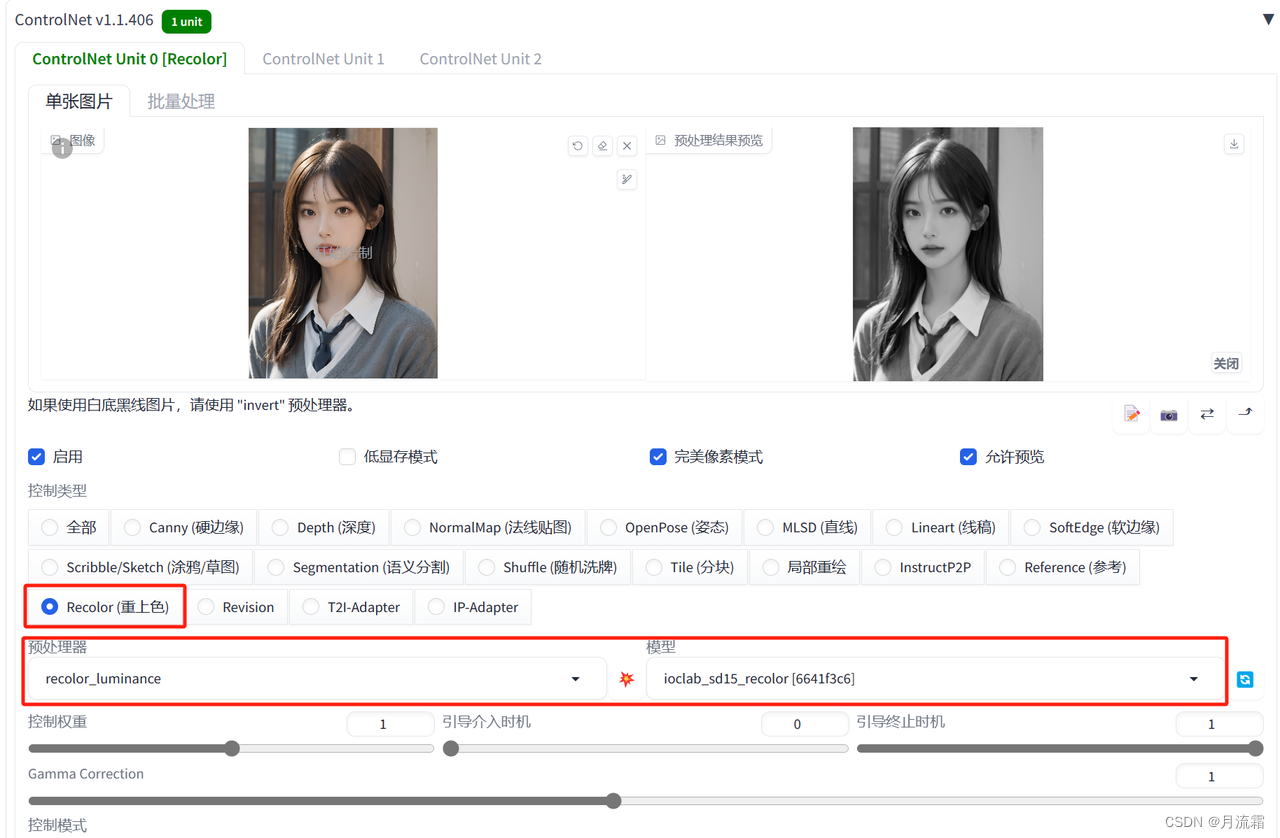
这里需要注意一下,我们要换颜色的地方最好是 深色换深色,浅色换浅色
比如黑色的头发可以换成棕色、绿色,但是最好不要换成白色这种浅颜色,不然出来的效果就没那么好
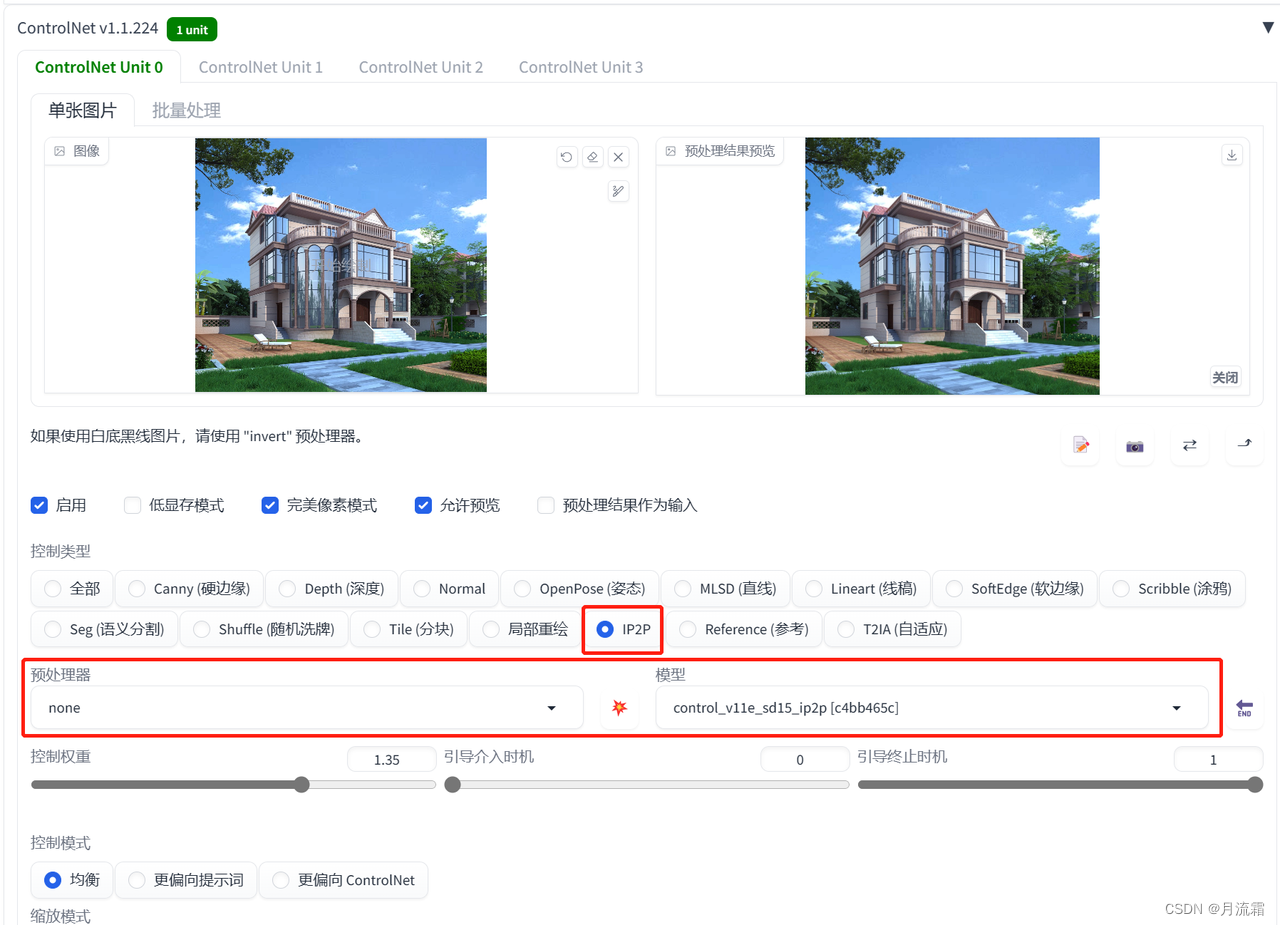
7.特效——ip2p
给照片加特效
这个功能目前来说没有太多的实际用处,只能拿来玩一下
比如让房子变成冬天、让房子着火



这里需要输入的关键词比较特殊
需要在关键词里面输入:make it.... (让它变成...)
比如让它变成冬天,就输入:make it winter
controlnet的模型选择:
预处理器:无 模型:ip2p
8.加照片细节——tile
tile模型的玩法非常多
01.恢复画质


controlnet的模型选择:
预处理器:tile_resample 模型:tile
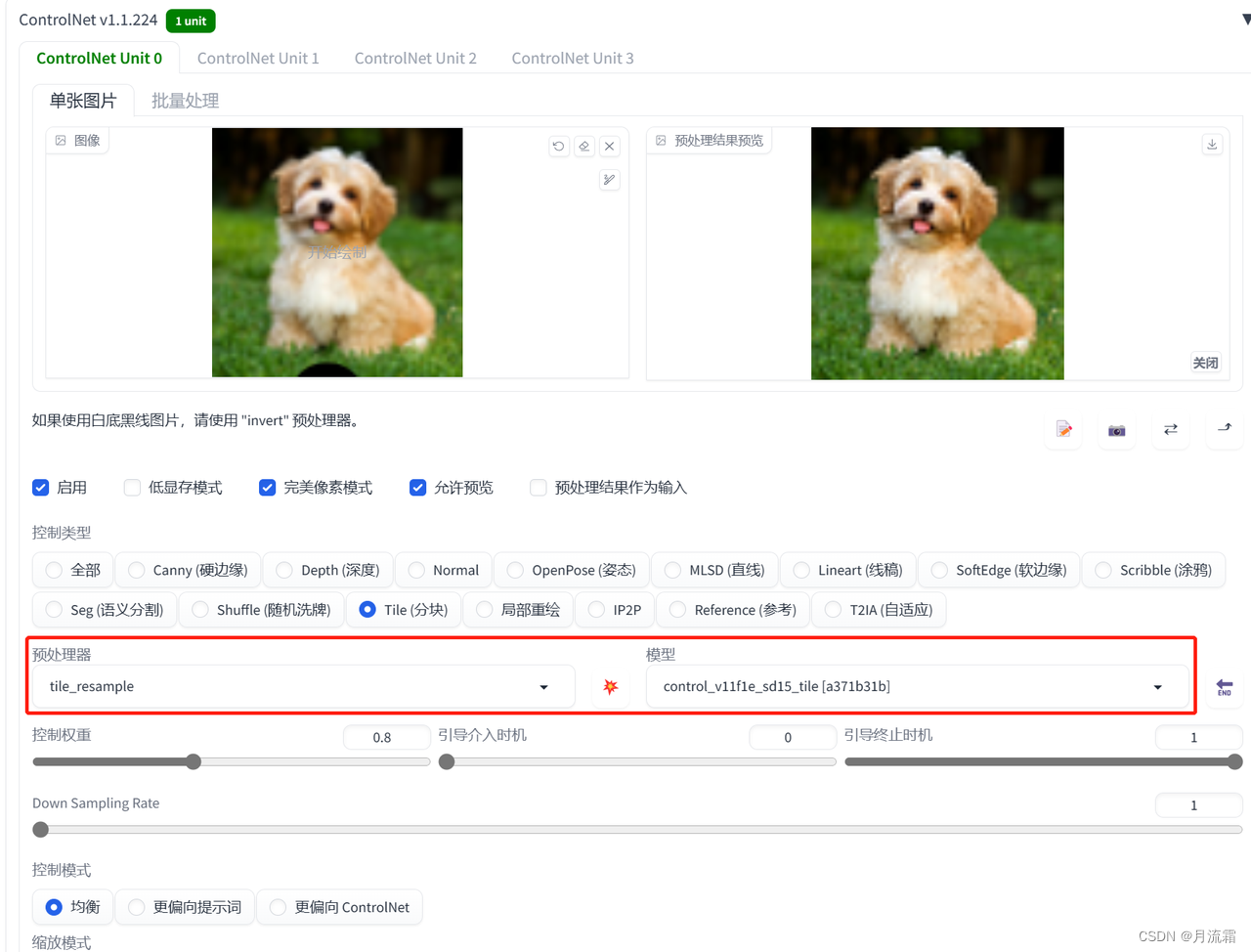
但是这个恢复画质的方法可能不太适合真人
因为tile模型的工作原理是先忽略掉照片的一些细节,再加上一些细节
这些SD自己加上去的细节可能会导致生成出来的照片不像原图


02.给图片加工
生成炫酷的赛博机车图


03.真人变动漫


04.动漫变真人




05.光影艺术字

六、结尾
目前用SD很多时候还是在“抽卡”
只是controlnet可以帮助我们提高成功的概率
并不是说用上controlnet就一定能出来自己满意的照片
模型关键词还有一些参数一样要反复的调整
但随着AI技术的不断迭代升级,未来还会有新的模型、更新的技术
最终AI绘画或许就可以实现——让出的图与我们脑海里想象的画面一致