个人博客链接
注:部分内容参考自GPT生成的内容
[Security 22] 关于”二进制函数相似性检测“的调研(个人阅读笔记)
论文:《How Machine Learning Is Solving the Binary Function Similarity Problem》(Usenix Security 2022)
仓库:https://github.com/Cisco-Talos/binary_function_similarity
动机
二进制函数相似性问题在系统安全研究领域扮演着重要角色,现有技术演变很快。但还没有研究能解答一些重要的研究问题,如:使用相同的数据集和相同的指标对不同的方法进行评估时,它们的比较结果如何?与简单的模糊哈希算法相比,新型机器学习解决方案的主要贡献是什么?不同特征集的作用是什么?不同的方法对不同的任务是否更有效?不同的方法对不同的任务是否更有效?跨架构比较是否比单一架构更难解决?在设计新技术的未来方向上,是否有任何特定的研究方向看起来更有前景?
要回答这些问题,有以下挑战:
- 现有研究难以复现或复制先前的结果
- 研究结果的不透明性:不同的解决方案通常针对不同的目标定制,使用不同的相似性概念和操作粒度。
- 研究方向的不确定性:该领域的研究方向和原因不清晰,研究方法多样且分散
另外,论文在第二章从度量函数相似性的方法和特征表示方法两方面探讨了二进制函数相似性问题
实现的方法
这篇论文挑选方法的标准:
- 可扩展性和实际应用性
- 关注有代表性的方法,而不是具体的论文
- 覆盖不同社区:安全、程序语言和机器学习,也考虑工业界
- 优先考虑最新趋势
挑选出的方法,根据研究团队和功能相似性,划分如下:
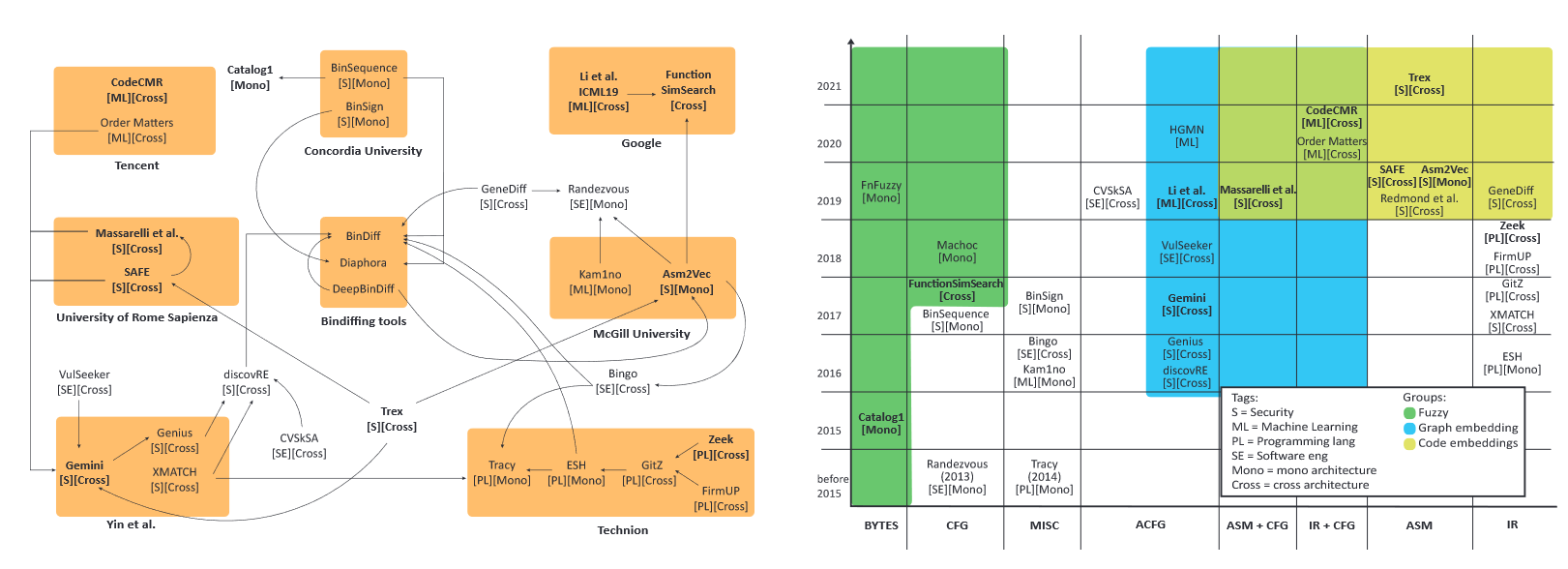
作者从中有些许发现:
-
有些论文通过比较得到的结论是错误的,比如将跨架构、基于比对函数的方法与单一架构、比对二进制文件的方法进行比较。
-
不同领域的论文通常都很封闭,很少与其他领域的论文进行比较。
-
一个明显的趋势:随着时间的推移,解决方案的复杂性和机器学习的使用不断增加
从以上挑选的方法中,作者挑选了十个具有可扩展性、代表性和最新性的最先进方法,准备进行评估。方法包括:
- Bytes fuzzy hashing: Catalog1
- CFG fuzzy hashing: FunctionSimSearch
- Attributed CFG and GNN: Gemini
- Attributed CFG, GNN, and GMN: Li et al. 2019
- IR, data flow analysis and neural network: Zeek
- Assembly code embedding: Asm2Vec
- Assembly code embedding and self-attentive encoder: SAFE
- Assembly code embedding, CFG and GNN: Massarelli et al., 2019
- CodeCMR/BinaryAI
- Trex
以统一的方式实现了评估的各个阶段,包括:
-
二进制分析(IDA Pro 7.3)
-
特征提取(a set of Python scripts using the IDA Pro APIs, Capstone , and NetworkX )
-
机器学习的实现(Tensorflow 1.14, with the only exception of Trex , which was built on top of Fairseq)
创建了两个新数据集:旨在捕捉现实世界软件的复杂性和可变性,同时涵盖二进制函数相似性的不同挑战:(i) 多种编译器系列和版本,(ii) 多种编译器优化,(iii) 多种体系结构和位宽,以及 (iv) 不同性质的软件(命令行实用程序与图形用户界面应用程序)。
确定了六种不同的评估任务:XO、XC、XC+XB、XA、XA+XO、XM。
O:Optimizations,C:Compiler and Compiler Versions,B:Bitness,A:Architecture,M:Mixed
结果与讨论
-
对Catalog1和FunctionSimSearch进行了Fuzzy-hashing Comparison:它们在面对多变量变化的任务时,表现有限。
-
Machine-learning Models Comparison:
论文直接提供的结论如下:
- 一种机器学习模型,来自 Li 等人的 GNN[40]在六个评估任务中优于所有其他变体,实现了与可扩展性较差的 GMN 版本类似的性能。
- 其他基于嵌入的模型[45, 49, 60, 76]显示出较低但相似的准确性。
- Zeek[67]采用直接比较方法,其在处理大型函数时的AUC表现更好。
- Asm2Vec[14]模型在多个任务中的表现并不优于其他模型。
此外还在4.5节进行了多方面的讨论。
-
Vulnerability Discovery Use Case
-
使用操作码特征的GMN模型表现最佳,但其可扩展性受限。
-
同时,特定配置下的FSS模型也意外地显示了良好的实用性能,但这种性能并不一定适用于所有配置。
-
表6包含了Netgear R7000固件中易受攻击函数的实际排名结果,显示即使MRR10值很高,实际排名可能仍然很低。
-
最后,在5 Discussion部分中,作者回答了开头提出的几个重要的研究问题,比如:
-
机器学习解决方案与模糊散列方法相比的主要贡献:机器学习模型即使在多个编译变量同时改变时也能达到高准确率,并且能够从大型训练数据集中受益,这些数据集是基于由编译选项定义的可靠基准。
-
不同特征集的作用:
- 使用基本块特征(例如,ACFG)提供更好的结果,但在精心手工设计的特征和更简单的特征(如基本块操作码的词袋)之间差异很小。
- 令人惊讶的是,指令嵌入[45]并没有提高GNN模型的性能,但作者认为需要进行广泛测试来评估其他可能的组合。
-
不同方法在不同任务中的表现:
- 大多数机器学习模型在所有评估任务中表现相似,无论是在相同架构还是跨架构中。
- 不需要针对特定任务进行训练,因为使用最通用的任务数据(XM)就能达到接近每个任务最佳的性能。但这对于模糊散列方法并不适用。
-
哪些研究方向更有前途:深度学习模型、GNN与汇编指令编码器的结合、结合中间表示和数据流信息、训练策略和损失函数等补充方面。
更多讨论详见论文
结论
本文进行了首次对超过五年来解决二进制函数相似性问题的研究工作的测量研究。作者识别了该研究领域中的一些挑战,以及这些挑战如何使得有意义的比较变得困难,甚至几乎不可能。本文工作旨在弥合这一差距,并帮助社区在这一研究领域获得更清晰的认识。作者希望通过发布所有的实现、数据集和原始结果,社区将拥有一个起点,以开始构建新的方法,并将其与一个共同的框架进行比较,以更好地辨别哪些新颖的方面实际上改进了现有技术状态,以及哪些方面只是看似如此。
附:部分概念解释
一些评估标准
- ROC曲线(Receiver Operating Characteristic Curve):
- ROC曲线是一个图形工具,用于评估二元分类器的性能。
- 它过将**真阳性率(True Positive Rate,TPR)和假阳性率(False Positive Rate,FPR)**作为横纵坐标来描绘分类器在不同阈值下的性能。
- ROC曲线下的面积(AUC)用于量化分类器的整体性能。AUC值越接近1,表明分类器的性能越好。
- top-n:
- top-n通常用于信息检索和推荐系统中,指的是从一系列项目中选择“最好”的n个项目。
- 例如,在推荐系统中,如果你想推荐5个最相关的项目,那么这就是一个top-5的任务。
- 在评估时,通常会查看这些top-n项目中有多少是真正相关或准确的。
- MRR10(Mean Reciprocal Rank at 10):
- MRR是一种评估信息检索系统效果的指标,特别是当查询返回一个项目列表时。
- MRR10指的是在前10个返回项目中找到第一个正确答案的倒数的平均值。
- 例如,如果正确的答案在返回列表的第一个位置,其倒数排名是1;如果在第二个位置,其倒数排名是1/2,依此类推。计算所有查询的这个倒数排名的平均值即得到MRR10。
- 召回率 (Recall@K):
- 这个度量标准关注的是模型能够在前K个结果中检索到多少相关项目。
- 例如,如果一个模型能够在前10个返回的项目中找到所有相关项目,则Recall@10将是100%。
pipeline
- Pipeline:
- 在计算机科学中,pipeline通常指的是一系列数据处理步骤或任务,这些步骤按照特定的顺序组织,每个步骤的输出成为下一个步骤的输入。
- 在软件工程和数据科学的背景下,pipeline涉及到从原始数据提取、处理、分析到最终产出的整个过程。例如,一个机器学习pipeline可能包括数据清洗、特征提取、模型训练和预测评估等步骤。
- Non-trivial Pipelines:
- “Non-trivial”这个词用来描述那些不简单、复杂或需求高的任务或过程。
- 当文本中提到“non-trivial pipelines”,它指的是那些在设计和实现上具有一定复杂性和挑战性的数据处理流程。这些pipeline可能包含多个步骤,每个步骤都需要特别的注意,可能涉及复杂的算法或大量的数据处理。
- 在二进制函数相似性问题的背景下,non-trivial pipelines可能包括诸如确定函数边界、反汇编代码、提取控制流图等复杂步骤。这些步骤在技术上可能很复杂,需要深入理解底层的计算机架构和编程原理。
“配对选择”(Pair Selection)
- 配对选择是指如何选择正负样本对(即相似和不相似的函数对)进行模型训练和评估。
- 这一方面对于适当的评估至关重要,因为它直接影响到训练任务的难度和评估结果的有效性。
“词袋”(Bag of Words)
词袋模型将文本(如句子或文档)转换为一个词的集合,忽略了文本中词的顺序和语法结构。