分布式 ID 的实现方案
当我们分表的情况下,如何实现全局唯一 ID 也是一个问题,数据库的唯一索引在
分布式 ID 也就是全局唯一 ID 生产方案需要满足以下几个条件:
- 高可用
- 高性能
- 安全性
- 自增性
- 唯一性
1、UUID
UUID(Universally Unique Identifier)是一种128位的数字标识符,通常用于唯一标识信息。UUID 是由一组六组十六进制数字组成,中间带有连字符,例如:550e8400-e29b-41d4-a716-446655440000。由于其长度和算法的特性,UUID 几乎可以被认为是全球唯一的标识符,因此在分布式系统和数据库中经常被用于生成唯一的标识符。UUID 的生成算法保证了在大多数情况下,生成的 UUID 都是唯一的。
UUID 的组成部分包括:
- 时间戳:UUID的前8位包含时间戳的信息。
- 时钟序列:UUID的9~10位包含时钟序列的信息。
- MAC地址:UUID的11~16位包含计算机的MAC地址。
- 随机数:UUID 的后 12 位包含随机数的信息
首先上述的 5 个条件 UUID 不满足自增性,其次我们在设置数据库主键的时候应该尽量选用较短的字符串,因为 MySQL 索引的特性主键 ID 需要越短性能越好。
2、基于单表做自增主键
既然分表的情况下有每个表生成自增主键会有冲突,那我们就可以使用一张表给所有的表生成自增主键,这样就解决了冲突的问题
也就是所有的表在需要主键的时侯,都到这张表中获取一个自增的 ID,
这样做是可以做到唯一,也能实现自增,但是问题是这个单表就变成整个系统的瓶颈,而且也存在单点问题,一旦也挂了,整个数握库就都无法写入了。
而且这种生成的方式也不满足安全性,由于自增主键的步长为 1 或者是某个固定值,那么在作为商城等订单系统的 ID 时,我有自己的 ID 就可以尝试出来别人其他的订单 ID,非常不安全。
3、基于跨表步长的自增主键
例如我们有 10 张表,我们可以规定 table_01 以 1 开始自增,table_02 以 1000,0001 开始自增,步长为 1000,0000,这样就可以解决冲突和单表瓶颈。
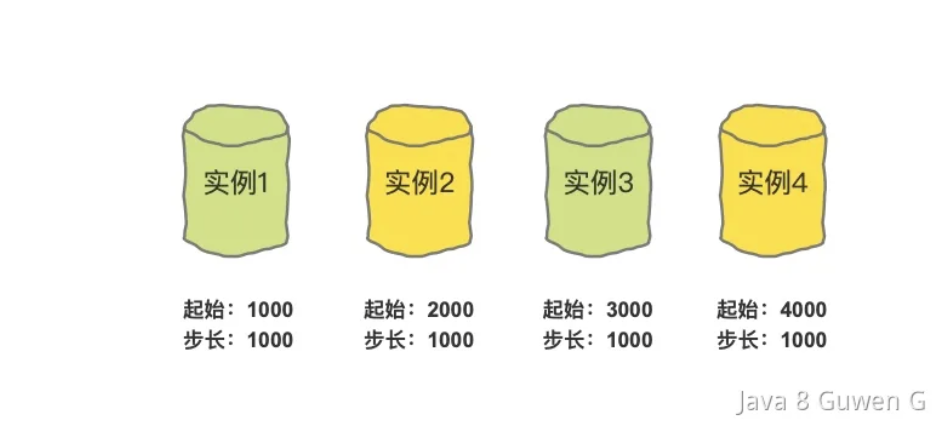
但是这种自增的方案需要项目初期进行项目存储数量的预估,而且一旦到达上限将很难去扩容。而且同样有上述的安全性的问题。
4、雪花算法
雪花算法也是比较常用的一种分布式 ID 的生成方式,它具有全局唯一、递增、高可用的特点。
雪花算法生成的主键主要由 4 部分组成,1 bit 符号位、41 bit 时间戳位、10 bit 工作进程位以及 12 bit 序列号位。
- 时间戳占用 41 bit, 精确到毫秒,总共可以容纳约 69 年的时间。
- 工作进程位占用 10 bit, 其中高位 5 bit 是数据中心 ID, 低位 5 bit 是工作节点 ID, 做多可以容纳 1024个节点。
- 序列号占用 12 bt, 每个节点每毫秒 0 开始不断累加,最多可以累加到 4095,一共可以产生 4096 个 ID。
所以,一个雪花算法可以在同一毫秒内最多可以生成 1024 X 4096=4194304 个唯一的 ID

雪花算法之所以被广泛使用,主要是因为他有以下优点: