exist和in的区别
exists 用于对外表记录做筛选。 exists 会遍历外表,将外查询表的每一行,代入内查询进行判断。
当 exists 里的条件语句能够返回记录行时,条件就为真,返回外表当前记录。反之如果 exists 里的条件语句不能返回记录行,条件为假,则外表当前记录被丢弃。
select a.* from A a where exists(select 1 from B b where a.id=b.id)in 是先把后边的语句查出来放到临时表中,然后遍历临时表,将临时表的每一行,代入外查询去查找。
select * from A where id in(select id from B)总结
子查询的表比较大的时候,使用 exists 可以有效减少总的循环次数来提升速度;
当外查询的表比较大的时候,使用 in 可以有效减少对外查询表循环遍历来提升速度。
Join 的算法(NLJ、BNL、BKA)
Nested-Loop Join
在NLJ算法中,MySQL首先选择一个表(通常是小型表)作为驱动表,并迭代该表中的每一行。然后,MySQL在第二个表中搜索匹配条件的行,这个搜索过程通常使用索引来完成。一旦找到匹配的行,MySQL将这些行组合在一起,并将它们作为结果集返回。
工作流程如图:

例如,下面这个语句:
select * from t1 straight_join t2 on (t1.a=t2.a);在这个语句里,假设t1 是驱动表,t2是被驱动表。我们来看一下这条语句的explain结果。

可以看到,在这条语句里,被驱动表t2的字段a上有索引,join过程用上了这个索引,因此这个语句的执行流程是这样的:
- 从表t1中读入一行数据 R;
- 从数据行R中,取出a字段到表t2里去查找;
- 取出表t2中满足条件的行,跟R组成一行,作为结果集的一部分;
- 重复执行步骤1到3,直到表t1的末尾循环结束。
这个过程就跟我们写程序时的嵌套查询类似,并且可以用上被驱动表的索引,所以我们称之为“Index Nested-Loop Join”,简称NLJ。
Nested-Loop Join
NLJ是使用上了索引的情况,如果查询条件没有使用到索引MySQL会选择使用另一个叫作“Block Nested-Loop Join”的算法,简称BNL。
Block Nested Loop Join(BNL)算法与NLJ算法不同的是,BNL算法使用一个类似于缓存的机制,将表数据分成多个块,然后逐个处理这些块,以减少内存和CPU的消耗。
例如,下面这个语句:
select * from t1 straight_join t2 on (t1.a=t2.b);字段b上是没有建立索引的。
这时候,被驱动表上没有可用的索引,算法的流程是这样的:
- 把表t1的数据读入线程内存join_buffer中,由于我们这个语句中写的是select *,因此是把整个表t1放入了内存;
- 扫描表t2,把表t2中的每一行取出来,跟join_buffer中的数据做对比,满足join条件的,作为结果集的一部分返回。
这条SQL语句的explain结果如下所示:

可以看到,在这个过程中,对表t1和t2都做了一次全表扫描,因此总的扫描行数是1100。由于join_buffer是以无序数组的方式组织的,因此对表t2中的每一行,都要做100次判断,总共需要在内存中做的判断次数是:100*1000=10万次。
虽然Block Nested-Loop Join算法是全表扫描。但是是在内存中进行的判断操作,速度上会快很多。但是性能仍然不如NLJ。
join_buffer的大小是由参数join_buffer_size设定的,默认值是256k。如果放不下表t1的所有数据话,策略很简单,就是分段放。
- 顺序读取数据行放入join_buffer中,直到join_buffer满了。
- 扫描被驱动表跟join_buffer中的数据做对比,满足join条件的,作为结果集的一部分返回。
- 清空join_buffer,重复上述步骤。
虽然分成多次放入join_buffer,但是判断等值条件的次数还是不变的,依然是10万次。
MRR & BKA
MySQL在5.6版本后引入了Batched Key Acess(BKA)算法了。这个BKA算法,其实就是对NLJ算法的优化,BKA算法正是基于MRR。
NLJ算法执行的逻辑是:从驱动表t1,一行行地取出a的值,再到被驱动表t2去做join。也就是说,对于表t2来说,每次都是匹配一个值。这时,MRR的优势就用不上了。
我们可以从表t1里一次性地多拿些行出来,,先放到一个临时内存,一起传给表t2。这个临时内存不是别人,就是join_buffer。
通过上一篇文章,我们知道join_buffer 在BNL算法里的作用,是暂存驱动表的数据。但是在NLJ算法里并没有用。那么,我们刚好就可以复用join_buffer到BKA算法中。
NLJ算法优化后的BKA算法的流程,如图所示:

图中,我在join_buffer中放入的数据是P1~P100,表示的是只会取查询需要的字段。当然,如果join buffer放不下P1~P100的所有数据,就会把这100行数据分成多段执行上图的流程。
如果要使用BKA优化算法的话,你需要在执行SQL语句之前,先设置
set optimizer_switch='mrr=on,mrr_cost_based=off,batched_key_access=on';其中,前两个参数的作用是要启用MRR。这么做的原因是,BKA算法的优化要依赖于MRR。
对于BNL,我们可以通过建立索引转为BKA。对于一些列建立索引代价太大,不好建立索引的情况,我们可以使用临时表去优化。
例如,对于这个语句:
select * from t1 join t2 on (t1.b=t2.b) where t2.b>=1 and t2.b<=2000;使用临时表的大致思路是:
- 把表t2中满足条件的数据放在临时表tmp_t中;
- 为了让join使用BKA算法,给临时表tmp_t的字段b加上索引;
- 让表t1和tmp_t做join操作。
这样可以大大减少扫描的行数,提升性能。
join查询为什么要小表驱动大表
mysql的join实现原理是,以驱动表的数据为基础,“嵌套循环”去被驱动表匹配记录,
select * from a join b on a.bid = b.id假设 a表10000数据,b表20数据
这里有2个过程,b 表数据最少,查询引擎优化选择b为驱动表,
- 循环b表的20条数据,
- 去a表的10000数据去匹配,这个匹配的过程是B+树的查找过程,比循环取数要快的多。
小驱动的方式
for 20条数据 匹配10000数据(根据on a.bid=b.id的连接条件,进行B+树查找)查找次数 20+ log10000
如果使用大表驱动,则查找过程是这样的
for 10000条数据 匹配20条数据(根据on a.bid=b.id的连接条件,进行B+树查找)
查找次数 10000+ log20
可以看出来
小表驱动大表:20+ log10000
大表驱动小表:10000+ log20
显然小表驱动大表查询效率要高很多。
参考:
https://www.cnblogs.com/booksea/p/17380941.html
https://www.cnblogs.com/hellotin/p/14227664.html
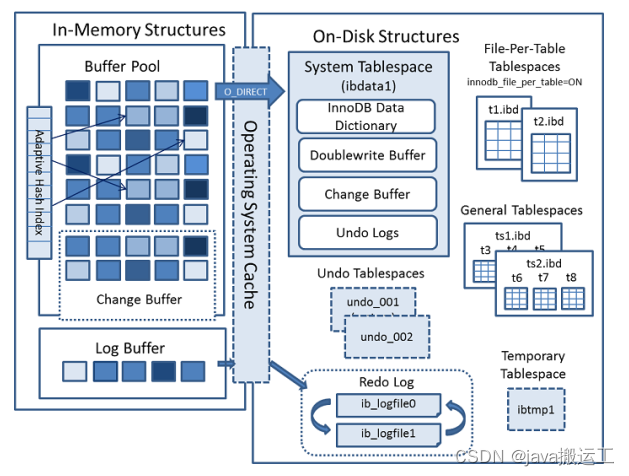
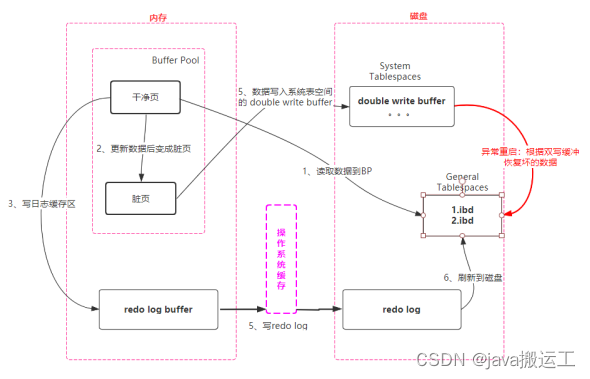
MySQL单个实例buffer数据和磁盘数据是如何保证强一致性的
InnoDB的页大小默认为16K,可以使用参数innodb_page_size设置, 可设置的值有: 64KB,
32KB,16KB(默认),8KB和4KB。并且在数据校验时也针对页进行计算,即他们是一个整个对待,包括把数据持久化到磁盘的操作。而计算机的硬件和操作系统在极端情况下(比如断电、系统崩溃)时,刚写入了4K或8K数据,那么就不能保证该操作的原子性,称为部分页面写问题(Partial Write Page)。
此时就引入了双写缓存区的机制,当发生极端情况时,可以从系统表空间的Double Write Buffer【磁盘上】进行恢复,下面是InnoDB的架构图、双写和恢复流程图。为了方便对比,将组件放在了相同的位置: