哈希桶方法
由于直接定值法实现哈希表有着明显的弊端——如果多个节点的hash值相同会往后堆积,所以衍生出哈希桶方法
我们的哈希表设置成一个结点指针数组,每个哈希值对应的是一串链表,形状就像一个一个的桶我们就会把hash值相同的节点放到一起,不会出现往后堆积的问题,而且还能一定程度解决频繁扩容的问题
节点定义
由于哈希桶是一个一个的链表,所以节点我们需要一个_next指针来形成链表
template<class Val_type>
struct HashNode
{HashNode<Val_type>* _next;Val_type _data;HashNode(const Val_type& data):_next(nullptr), _data(data){}
};成员/成员函数
构造函数:这里默认先开十个节点的数组
析构函数:我们需要将每个桶中的每个节点都释放掉,所以需要一个一个的遍历,一个节点接着一个节点的释放就可以了(最后滞空)
成员:需要一个vector<Node*> 用来控制整个哈希表,用一个_n 来维护整个哈希表节点的个数(插入节点++ 删除节点--)
template<class Key_type, class Val_type, class KeyOfT, class Hash>
class __Hashiterator
{typedef HashNode<Val_type> Node;
public:HashTable(){_table.resize(10,nullptr);//开十个空间_n = 0;}~HashTable(){for (size_t i = 0; i < _table.size(); i++){Node* cur = _table[i];while (cur){Node* next = cur->next;//标记下一个节点delete cur;//直接deletecur = next;}_table[i] = nullptr;}}
private:vector<Node*> _table;size_t _n;
};插入
首先看看能不能在表中找到该元素,如果表中有要插入的元素,不再进行插入!
Hash仿函数:用来计算哈希值
KeyOfT仿函数:用来取出Val_type中的key值
扩容:如果节点数与桶的数量相同则需要扩容
①开一个新表,容量扩成原来的二倍
②遍历旧表,一个一个的将节点插入新表中的对应桶中
③将新表与旧表交换(这样 一但出函数作用域,就表就会销毁,新表代替掉旧表)
插入节点:这里直接头插就可以了(方便快捷,时间O(1))。
①:
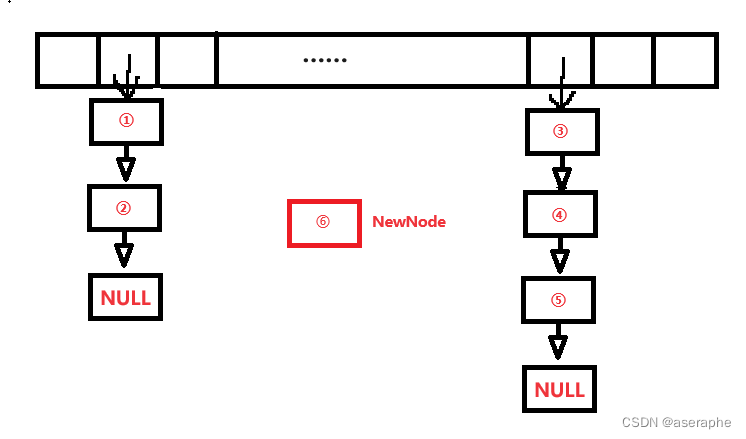
②
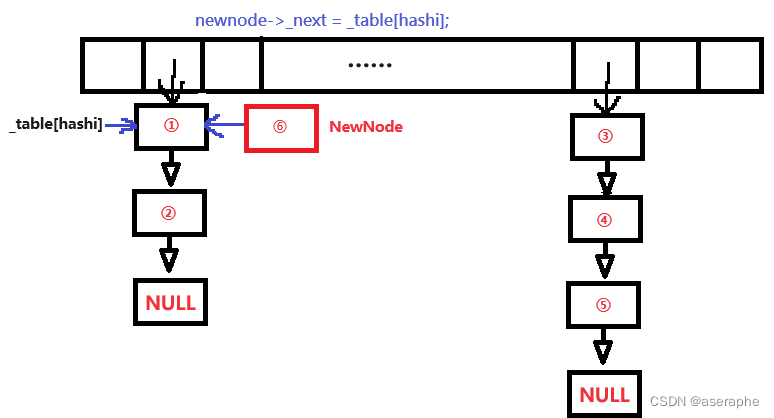
③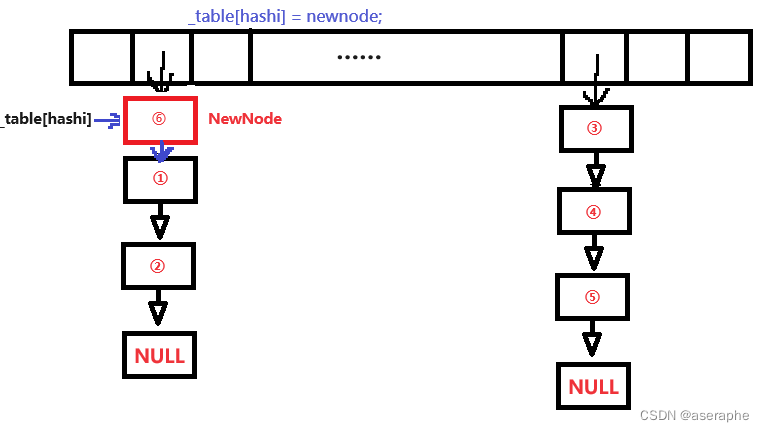
bool insert(const Val_type& val)
{KeyOfT kot;if (Find(kot(val)))return false;Hash hs;if (_n == _table.size())//扩容{vector<Node*>newTable(_table.size() * 2, nullptr);for (size_t i = 0; i < _table.size(); i++){Node* cur = _table[i];//转移hash桶while (cur){Node* next = cur->_next;size_t hashi = hs(kot(cur->_data)) % _table.size();cur->_next = newTable[hashi];newTable[hashi] = cur;cur = next;}_table[i] = nullptr;}_table.swap(newTable);}size_t hashi = hs(kot(val)) % _table.size();Node* newnode = new Node(val);//开新节点//头插newnode->_next = _table[hashi];_table[hashi] = newnode;++_n;return true;
}搜索
①确定要找的节点的哈希值
②到该桶里找到该节点
③返回节点
Node* Find(const Val_type& val)
{KeyOfT kot;Hash hs;size_t hashi = hs(kot(val)) % _table.size();Node* cur = _table[hashi];while (cur){if (kot(cur->_data) == val)return cur;cur = cur->_next;}return false;
}删除
①找到对应的桶
②在桶中找到该节点
③删除该节点
bool erase(const Val_type& val)
{KeyOfT kot;Hash hs;size_t hashi = hs(kot(val)) % _table.size();Node* prev = nullptr;Node* cur = _table[hashi];while (cur)//找到该节点{if (kot(cur->_data) == val)//如果找到{if (prev)//桶中有多个节点{prev->_next = cur->_next;}else//要删除的节点是桶中的第一个节点{_table[hashi] = cur->_next;}delete cur;cur = nullptr;--_n;return true;}prev = cur;cur = cur->_next;}return false;
}迭代器
①我们的迭代器需要知道是哪一个hash表中的迭代器,所以需要一个_ht 来记录指向我们迭代的哈希表
②需要维护一个节点指针
template<class Key_type, class Val_type, class KeyOfT, class Hash>
class __Hashiterator
{typedef HashNode<Val_type> Node;typedef __Hashiterator<Key_type,Val_type,KeyOfT,Hash> self;Node* _node;HashTable<Key_type, Val_type, KeyOfT, Hash> _ht;__Hashiterator(Node* node, HashTable<Key_type, Val_type, KeyOfT, Hash>* ht):_node(node),_ht(ht){}
};重载: 这里主要分析一下operator++
分情况:如果下一个节点是空,就需要去下一个右节点的桶中找节点
如果下一个节点不是空,转移到下一个节点就可以了
Val_type& operator*()
{return _node->_data;
}self& operator++()
{if (_node->next)//当前位置后边还有节点{return _node = _node->_next;}else//换桶{KeyOfT kot;Hash hs;size_t hashi = hs(kot(_node->_data)) % _ht->_table.size();//找下一个桶hashi++;while (hashi < _ht->_table.size()){if (_ht->_table[hashi])//当前桶里有节点,访问这个桶,没节点继续找到有节点的桶{_node = _ht->_table[hashi];break;}}if (hashi == _ht->_table.size())//后边没有桶了{_node = nullptr;}}return *this;
}bool operator!=(const self& s)
{return _node != s._node;
}bool operator== (const self& s)
{return _node == s._node;
}begin/end
如果容器没有begin函数和end函数,就不能支持C++11 中的范围for功能
begin只要找到第一个不为空的桶就可以了
iterator begin()
{for (size_t i = 0; i < _table.size(); i++){if (_table[i] != nullptr){return iterator(_table[i], this);}}return end();//如果全部都是空桶
}iterator end()
{return iterator(nullptr, this);
}
![正点原子[第二期]Linux之ARM(MX6U)裸机篇学习笔记-12-蜂鸣器](https://img-blog.csdnimg.cn/direct/72cfe6557d7d46efa1d2f9325911bfbc.png)