DeepVisionary 每日深度学习前沿科技推送&顶会论文分享,与你一起了解前沿深度学习信息!
Mamba3D革新3D点云分析:超越Transformer,提升本地特征提取效率与性能!
引言:3D点云分析的重要性与挑战
3D点云数据是现代许多应用领域中不可或缺的一部分,包括自动驾驶、虚拟现实(VR/AR)、机器人技术等。这些数据通常由3D扫描设备捕获,能够详细地描述物体的空间形状和外观。与传统的2D图像相比,3D点云能提供更加丰富和精确的空间信息,这使得它们在处理和分析三维物体时显示出独特的优势。
然而,点云数据的处理和分析也面临着一系列挑战。首先,点云数据通常是无序的,即点的存储顺序并不反映任何形式的实际空间关系,这与传统的像素排列的2D图像不同。其次,点云数据的复杂几何结构使得从中提取有用信息变得更加困难。此外,随着输入数据量的增加,许多基于深度学习的模型,尤其是基于Transformer的模型,会遇到计算复杂度急剧增加的问题。这些模型在处理大规模点云数据时,往往需要巨大的计算资源,且效率低下。
为了克服这些挑战,研究人员一直在探索更高效的模型架构。最近,基于状态空间模型(State Space Model, SSM)的Mamba模型显示出了处理长序列数据的潜力,其计算复杂度为线性,相比于Transformer模型具有明显优势。本文介绍的Mamba3D模型,是专为点云数据设计的,它不仅继承了Mamba模型的高效性,还通过引入局部规范池化(Local Norm Pooling, LNP)和双向SSM(Bidirectional-SSM)等技术,显著提高了对点云数据的处理能力和准确性。
论文标题: Enhancing Local Features for 3D Point Cloud Analysis via State Space Model
机构: Huazhong University of Science and Technology
论文链接: https://arxiv.org/pdf/2404.14966.pdf
项目地址: 未提供
通过对Mamba3D模型的深入分析和实验验证,我们展示了其在多个点云处理任务上相较于现有技术的优越性,特别是在从头开始训练时,在ScanObjectNN和ModelNet40分类任务上达到了新的状态艺术水平(State of the Art, SoTA),证明了其作为点云分析新基准的潜力。
Mamba3D模型概述
Mamba3D是一种专为3D点云学习设计的状态空间模型,它在处理无序点云数据时展现出卓越的性能和高效率。与传统的Transformer模型相比,Mamba3D通过其线性复杂度优势,能够处理更大规模的数据集,同时保持较低的参数数量和计算成本。
Mamba3D的设计灵感来源于Mamba模型,该模型是基于状态空间模型(SSM)的一种高效实现。Mamba模型通过引入选择机制,有效压缩上下文信息,使其能够处理长序列数据。然而,直接将Mamba模型应用于点云任务时,由于其递归/扫描模式导致的序列依赖性以及缺乏对局部几何特征的显式提取,其性能并不理想。
针对这些问题,Mamba3D引入了局部规范池化(Local Norm Pooling, LNP)块和双向SSM(Bidirectional-SSM, bi-SSM)技术,专门针对无序点的特点进行优化。这些技术的结合不仅提高了模型对局部几何特征的捕捉能力,还增强了全局特征的提取效率,使得Mamba3D在多个点云处理任务中取得了领先的性能。
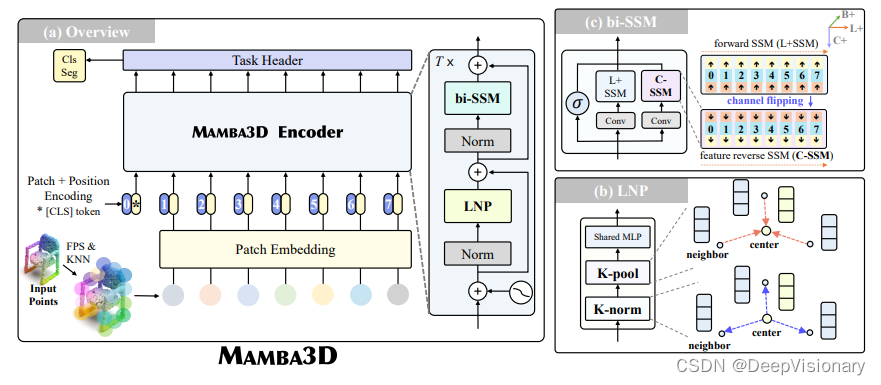
Mamba3D的关键技术
1. 局部规范池化(LNP)
局部规范池化(LNP)是Mamba3D中的一个关键技术,它通过K-范数和K-池化操作来进行特征的传播和聚合。LNP块的设计简单但高效,只使用了0.3M的参数。在LNP块中,首先通过K最近邻(KNN)构建局部图,然后通过K-范数操作对邻居点的特征进行标准化和融合,最后通过K-池化操作将信息聚合回中心点,从而更新中心点的特征表示。
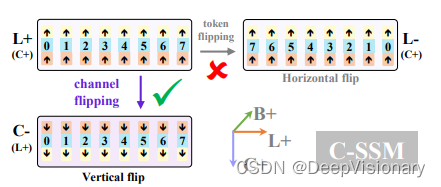
2. 双向状态空间模型(bi-SSM)
为了更好地捕捉全局特征,Mamba3D引入了双向状态空间模型(bi-SSM),包括一个正向的SSM(L+SSM)和一个新颖的反向SSM(C-SSM),后者在特征通道上操作。这种设计考虑到点云数据的无序性,通过对特征通道而非点令牌序列进行建模,减少了伪序依赖性,从而更有效地利用全局特征。
通过这些关键技术的应用,Mamba3D不仅在从头开始训练时表现出色,还能够配合多种预训练策略,进一步提升模型的性能和可扩展性。在多个基准测试中,Mamba3D均显示出优于当前最先进模型的性能,证明了其在处理大规模点云数据时的有效性和高效率。
预训练策略详解
在Mamba3D的开发过程中,预训练策略扮演了重要的角色,以提升模型在下游任务中的表现。本文详细介绍了两种预训练策略:Point-BERT和Point-MAE。
Point-BERT预训练策略:首先,我们随机遮盖55%至85%的输入点嵌入,这一遮盖比例高于Point-BERT原始的25%至45%。增加遮盖比例不仅可以加速训练过程,还能推动Mamba3D在有限输入下的特征学习能力。然后,Mamba3D编码器处理可见和遮盖的嵌入,生成一个标记序列。同时,我们直接使用Point-BERT预训练的dVAE权重来预测点嵌入的标记序列,作为标记指导。最后,我们计算编码器输出的标记序列与dVAE输出的标记序列之间的L1损失,作为损失函数。
Point-MAE预训练策略:遵循Point-MAE的方法,我们采用遮盖点建模方法,并直接重建被遮盖的点。我们使用一个编码器-解码器架构,其中编码器仅处理可见的标记并生成它们的编码。与Point-MAE不同的是,我们的解码器采用与编码器不同的架构,仅包含双向SSM(bi-SSM)块而不包含LNP块,这有助于加速收敛而不损失性能。编码的可见标记和被遮盖的标记被送入解码器以预测被遮盖的点。损失是使用Chamfer Distance计算输出和真实点之间的差异。在下游任务中,我们仅使用预训练的编码器来提取特征,并附加任务头进行微调。
实验验证与性能分析
为了全面评估Mamba3D的性能和表征学习能力,我们通过从头开始训练我们的模型以及使用两种不同的预训练策略进行了广泛的实验。
实验设置:我们在ScanObjectNN和ModelNet40数据集上进行了对象分类实验。ScanObjectNN数据集包含约15K个从真实世界扫描的带有杂乱背景的对象。我们使用其三个变体:OBJ_BG、OBJ_ONLY和PB_T50_RS,并采用旋转作为数据增强。ModelNet40数据集包括约12K个合成3D CAD模型,我们使用1024个点作为输入,并应用缩放和平移进行数据增强。
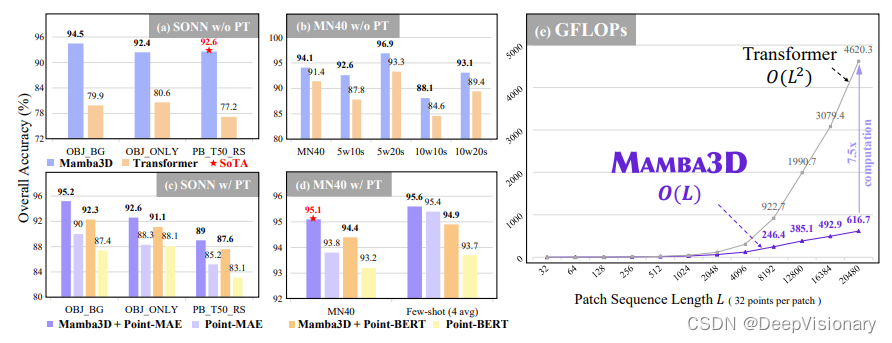
性能分析:在从头开始训练时,Mamba3D在ScanObjectNN的PB_T50_RS变体上达到了91.81%的整体准确率(OA),并在投票后达到92.64%,超过了SoTA模型DeLA的90.4%。与Transformer相比,Mamba3D的OA提高了+15.40%,参数和FLOPs分别减少了24%和19%。在ModelNet40数据集上,Mamba3D比Transformer高出+2.7%。使用Point-BERT预训练策略后,Mamba3D在ScanObjectNN上超过Point-BERT +4.51%,在ModelNet40上超过+1.2%。使用Point-MAE策略,Mamba3D在ModelNet40上达到了95.1%的OA,为单模态预训练模型设定了新的SoTA。在ScanObjectNN数据集上,Mamba3D比使用OcCo的Transformer高出+10.2%,比Point-MAE高出+3.8%。
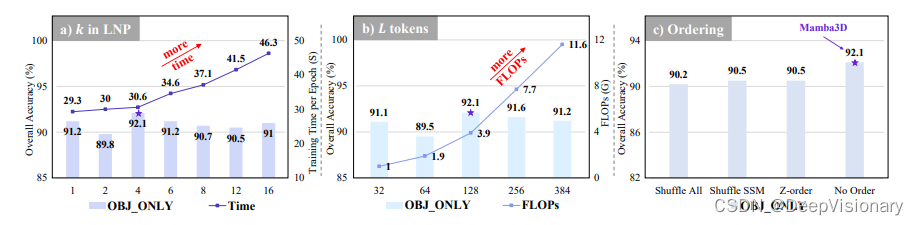
这些结果突出显示了Mamba3D在各种设置中的优越性,超越了现有的专用架构和基于Transformer或Mamba的模型,实现了多个SoTA,展示了其跨不同设置的强大实力。
模型的局限性与未来方向
尽管Mamba3D在多个3D点云任务中取得了优异的表现,但仍存在一些局限性和未来的发展方向。首先,Mamba3D的预训练效果并不如Transformer模型稳健,这可能是由于其循环模型特性不适合处理掩码点建模任务。未来的研究可以探索更适合Mamba3D的预训练策略,以进一步提升模型的泛化能力和效率。
其次,虽然Mamba3D通过双向状态空间模型(bi-SSM)和局部规范池化(LNP)块有效地处理了无序点云数据,但如何更好地整合和优化这些结构以处理更大规模的数据集,仍是一个值得探讨的问题。此外,Mamba3D在处理特定任务时可能还需要针对性的调整和优化,以适应不同的应用场景。
最后,随着3D点云数据的应用越来越广泛,如何设计更加高效且能够处理超大规模点云数据的模型,也是未来研究的一个重要方向。这包括但不限于改进模型的计算效率、减少参数数量、以及提高模型的可扩展性和鲁棒性。
总结
Mamba3D作为一种基于状态空间模型的新型点云学习架构,通过引入局部规范池化(LNP)和双向状态空间模型(bi-SSM),有效地提升了对3D点云的局部和全局特征提取能力。相较于基于Transformer的模型,Mamba3D不仅在多个标准数据集上设定了新的最佳表现,还显著降低了模型的参数量和计算复杂度。
通过广泛的实验验证,Mamba3D展示了其在从头开始训练以及使用预训练策略时的优越性能。尤其是在模型净化和部分分割任务中,Mamba3D都表现出了卓越的性能和高效的信息处理能力。未来,我们期望Mamba3D能够在处理大规模点云模型方面取得更进一步的突破,并在多种3D点云应用场景中发挥重要作用。同时,针对现有模型的局限性,我们将探索更加有效的预训练策略和模型优化方法,以充分利用Mamba3D在线性复杂度下的性能优势。
关注DeepVisionary 了解更多深度学习前沿科技信息&顶会论文分享!